2. 엑셀로 데이터 분석 맛보기
1) 성적과 다른 요소들의 상관관계?
💡우선 엑셀을 통해서, 데이터 분석을 한다는 것이 무엇인지 함꼐 살펴보자.
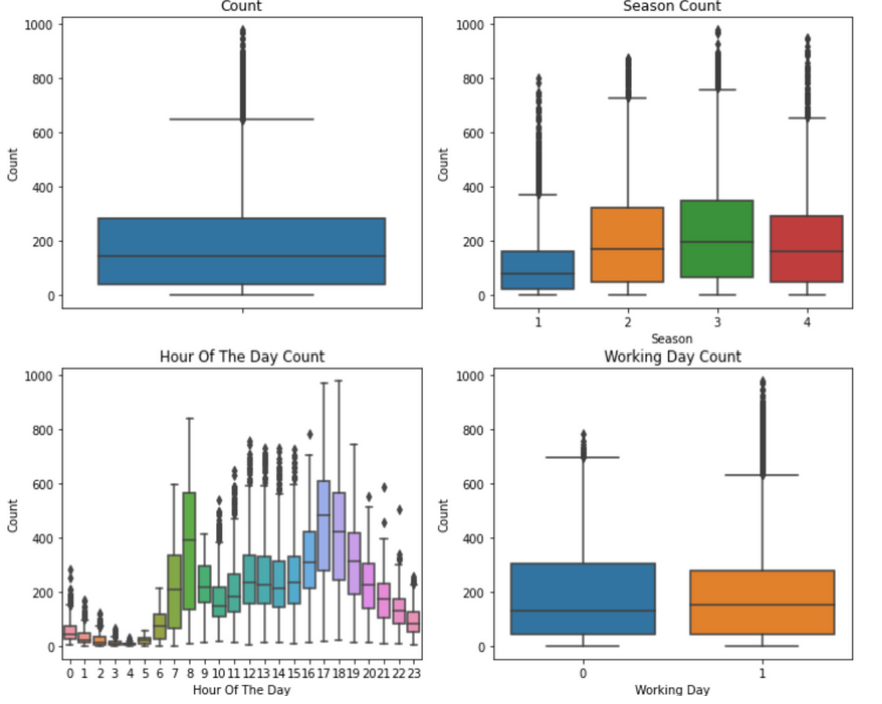
< 학생 성적 데이터 >
- 성적과 다른 요소들의 상관관계 ?
-> 가설 : 성적과 다른 요소들(공부 시간, 노는 시간 등)의 관계
- 가장 먼저 해야할 것 : 어떤 데이터를 통해서 분석할 수 있을지 생각.
- 필요한 데이터 무엇인지 찾기.
ex) 데이터 출처
성적이 높을수록 경
종속 변수: 다른 요인들에 의해 결정 되는 변수 ex)성적독립 변수: 종속 변수가 결정되도록 영향을 주는 변수 ex)공부 시간
- 분석 하기
- 정의한 데이터만으로 원하는 분석 결과가 도출되면 이상적이지만 실제로는 유동적으로 데이터 정의가 변경되기도 함.
✔ 캐글 사이트 설명
: 데이터셋 제공, 데이터셋을 이용해서 분석한 결과를 제출하면 얼마나 정확하게 분석했는데 예측했는지 제출하면 경쟁하고 그런 시스템을 제공하는 사이트
2) 데이터 가공
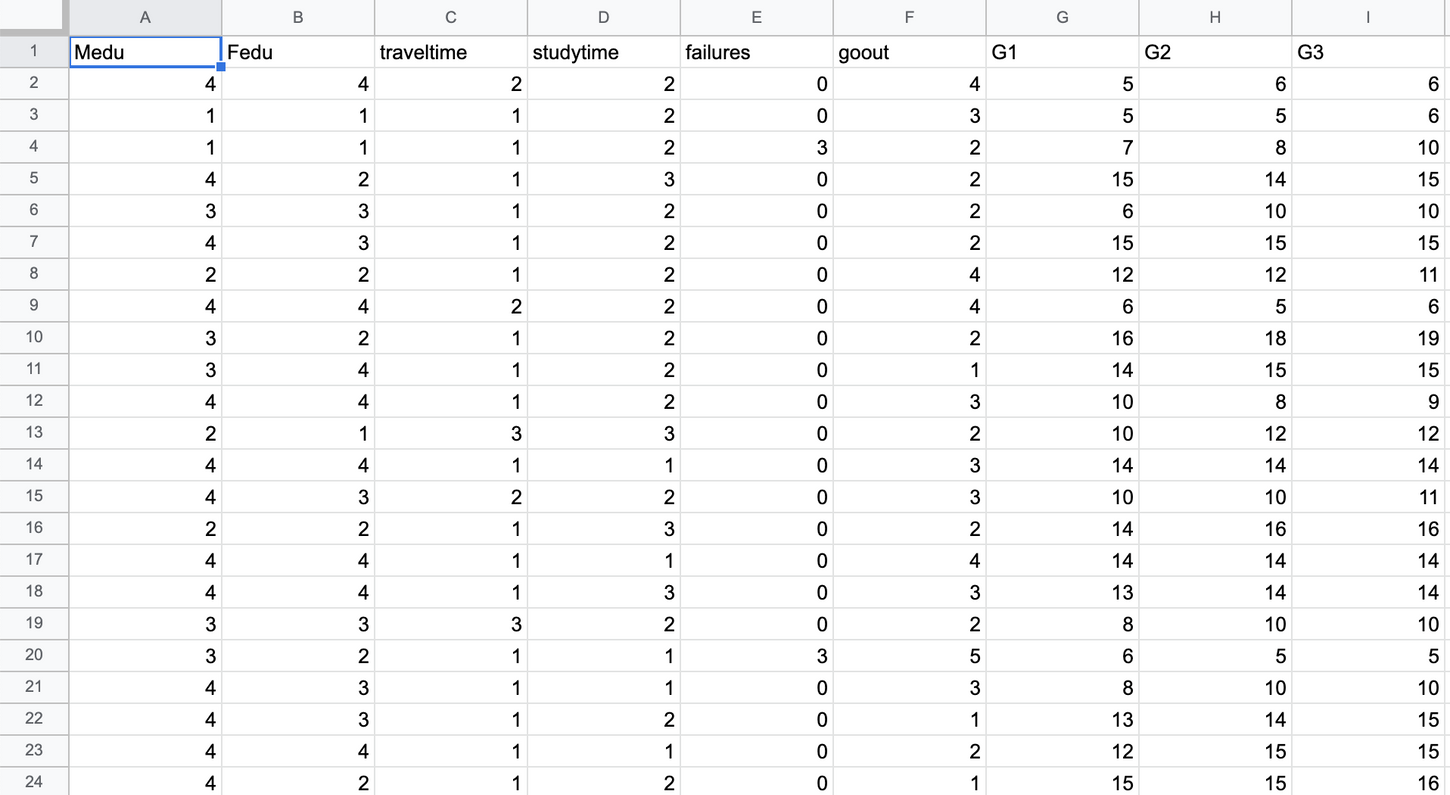
각 열들은 다음과 같은 의미를 가집니다.
Medu: 어머니의 교육 수준 (각 숫자의 뜻: 0 - 없음, 1 - 초등 교육, 2 - 중등 교육, 3 - 고등 교육, 4 - 그 이상)Fedu: 아버지의 교육 수준 (각 숫자의 뜻: 0 - 없음, 1 - 초등 교육, 2 - 중등 교육, 3 - 고등 교육, 4 - 그 이상)traveltime: 등교 시간 (각 숫자의 뜻: 1 - 15분 미만, 2 - 15 ~ 30분, 3 - 30분 ~ 1시간, 4 - 1시간 초과)studytime: 주별 공부 시간 (각 숫자의 뜻: 1 - 2시간 미만, 2 - 2 ~ 5시간, 3 - 5 ~ 10시간, 4 - 10시간 초과)failures: 이전에 F를 받은 횟수goout: 친구와 놀러다니는 정도 (각 숫자의 뜻: 1 - 매우 낮음 ~ 5 - 매우 높음)G1: 첫번째 시험의 점수G2: 두번째 시험의 점수G3: 최종 시험의 점수
👨🏫가공된 파일이다. 왜냐하면 원본 파일 데이터에는 No,Yes 같은 문자열 형태의 데이터가 있는데 가공할려면 다른 과정을 살펴야 함.
-
부가기능→부가기능 설치하기버튼을 눌러주세요. -
부가기능을 검색할 수 있는 창이 표시됩니다. 여기다가
'analysis toolpak'이라고 검색해주세요! -
제일 왼쪽의 빨간색 썸네일을 가진 도구를 설치할 예정입니다. 클릭해주세요.이제 설치를 진행해주시면 됩니다.
-
설치를 하셨다면, 이제 부가기능에
xlminer analysis toolpak이라는 부분이 표시가 되는데, 클릭해서start 버튼을 눌러주세요. -
그러면 화면 오른쪽에 아래와 같은 버튼들이 표시가 됩니다. 여기서
Correlation 버튼을 누르고, 아래와 같이 작성해주세요. (상관관계라는 뜻)
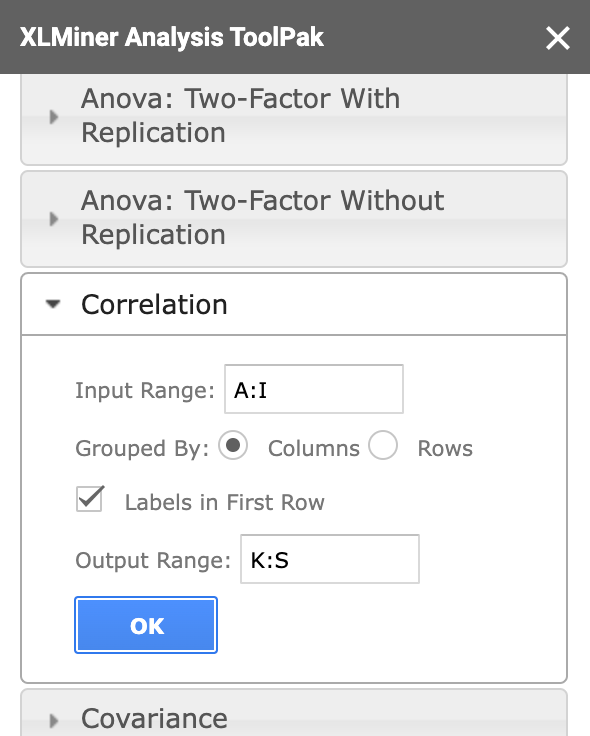
Input Range: A:I 는 현재 시트 상에서 A열부터 I열까지를 분석한다는 뜻이고,Output Range: K:S 는 그 분석한 결과를 K열부터 S열까지 표시를 하겠다는 뜻입니다.
(Labels in First Row 는 꼭 체크해주세요! - 첫번째 행에는 어떤 데이터인지에 대한 설명이기 때문에 체크해야 두번째 행부터 데이터 들어가 있다고 인식하고 분석함)
그러면 아래와 같은 표가 하나 표시됩니다.
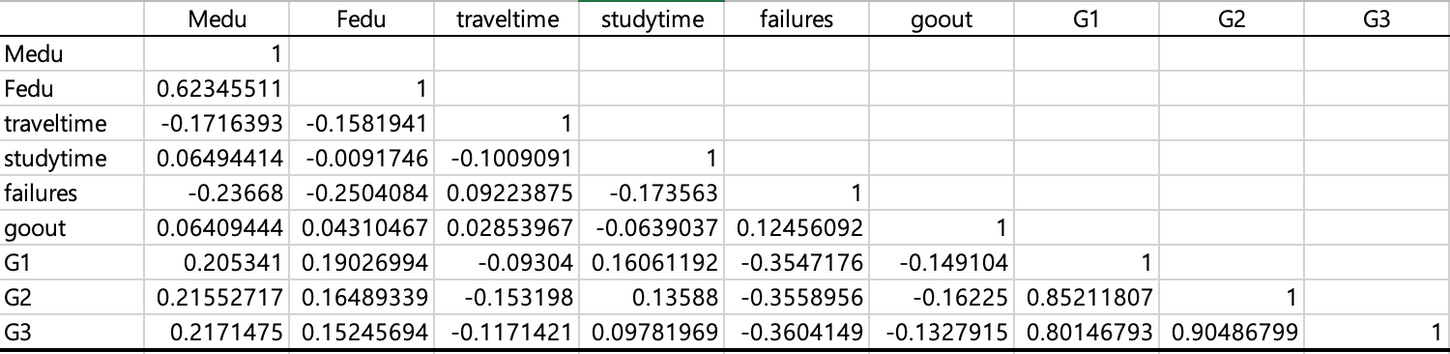
윗부분 지워주세요 - 다른요인들과 최종성적만 알면 되서.
제일 아래 최종성적(G3) 부분을 유심히 봐주세요!

G3(최종성적)과 얼마나 많은 상관관계를 가지는지 나타냄.
3) 상관관계 분석
- 수치들은 각 변수와의 상관계수이다.(성적과의 연관 정도) - ✔ 3주차에 자세히
- 1에 가까울수록 요인이 증가할때 증가할 확률,
음수라면 -1에 가까울수록 증가할때 요인이 감소할 확률. - 인과관계랑 다르다. 수치들이 나란히 표시가 되어있는데, 이 수치들은 각 변수와의
상관계수에 해당합니다.
나중에 더 자세히 살펴보겠지만, 상관계수는 쉽게 말하자면 성적(G3)과의 연관 정도라고 표현할 수 있습니다. (인과관계와는 다릅니다!)
반면에 0에 가까울 수록 해당 변수의 변화는 성적(G3)에 영향이 없습니다.
상관관계(Correlation)란 ? 변수 간의 관계
- 양의 상관관계 ( + )
- 음의 상관관계 ( - )
- 변수들과 성적이 어떤 상관관계가 있는지 우선 분석해 봐야 한다.
해당 표를 보고 알 수 있는 사실은
아버지의 교육 수준, 어머니의 교육 수준, 공부 시간, 첫번째 시험의 성적, 두번째 시험의 성적은 모두 증가할 때 최종 성적도 증가할 확률이 높지만,
등교에 걸리는 시간, 이전에 F를 받은 횟수, 친구와 놀러다니는 정도는 증가할 때 최종 성적은 감소할 확률이 높다는 것입니다.
(일반적인 사람들의 인식 혹은 직관과 어느 정도 일치하는 것을 확인할 수 있습니다.)
4) 엑셀의 한계
👨🏫 눈으로, 수치로 확인할수 있었으나. 더 나아갈려면 바로 예측을 배볼수 있다. 공부시간, 교육수준 이렇다 했을때, 그 학생의 성적은 얼마일까? 할때가 4주차에서 배울 회귀분석이다. 조금 더 복잡하기도 하고 정확도를 높이기 위한 과정을 거치게 된다.
- 만약 공부시간, 부모의 교육수준에 따른 최종 시험 성적 💛예측시 ->
회귀분석사용 - 회귀분석 과정에서 정확도를 높이기 위해 정규화, 이상치 탐지 등 과정을 거침
- 엑셀은 지원하지 않는다. 엑셀은 예측을 위한 도구가 존재하나,
선형 회귀 등등 지원 안하고, 정확도 평가 수단에도 한계. 다른종류의 회귀 분석을 하기 위해서는 파이썬을 써야만 한다. 다양한 시각화를 해보고 그것을 토대로 다양한 머신러닝 알고리즘을 활용해보고. - 파이썬을 통한 다양한 그래프를 통해 데이터 분석 (더 높은 정확도의 예측모델 구현하기 위함) 데이터 분석을 위해서 파이썬이라는 강력한 언어를 배울 필요가 있다.
예시)