👨🏫 범주형 변수를 더미형 변수로 치환하기.
ex) 범주형 변수가 계절 1,2,3,4 이면 기계한테 1,2,3,4라고 알려주면 정확하게 분석하기 힘들어서 계절이 대여량에 미치는 영향을 분석해줘 라고 하는 것 보다 '봄' 이라는 계절이 대여량에 미치는 영향을 분석해줘 라고 이렇게 각각 물어보는 것이 훨씬 더 정확한 결과를 낳을수 있다. 계절이라고 뭉뚱그려서 만들어 놓지 말고 봄,여름,가을,겨울이라고 나눠서 열을 만들어 놓자. 그래서 봄에 해당하는지 안하는지 식으로 열을 만들어 놓자는 것이 더미형 변수로 바꾸는 과정이다.
3) 범주형 변수(Categorical Variable)
데이터를 회귀 모델의 입력으로 사용할 때, 범주형 변수들(Categorical variable)에 대해서는 범주형 변수임을 알려주는 전처리를 해줄 필요가 있습니다.
범주형 변수(Categorical Variable): 몇 개의 범주(경우의 수)가 있어 중 하나에 속하게 되는 변수로 범주가 정해지면 이들 사이에 중간값 같은 게 갑자기 생길 수 없고, 머신 러닝 입장에서는 이 열의 값은 무조건 이들 중 하나구나로 판단하고 학습하는 변수들입니다.
ex) 성별 - 남/녀 계절 - 봄, 여름, 가을, 겨울 학점 - A, B, C, D, E 년도 - 2011, 2012 혈액형 - A형, B형, AB형, O형
그러면 반대로 범주형 변수가 아닌 변수, 수치형 변수로는 어떤 것들이 있을까요?수치형 변수(Numerical Variable): 무게와 같이 양적인 수로 이루어진 변수
ex) 몸무게, 키, 온도, 습도, 인구 등...
현재 다루고 있는 자전거 대여 데이터에서 범주형 변수에 해당하는 열들은 다음과 같습니다.
- 'year', 'month', 'day', 'hour', 'holiday', 'workingday', 'season', 'weather'
결론적으로는 회귀를 하기 전 범주형 변수를 더미 변수(Dummy Variable)로 바꾸어주는 전처리를 적용해줍니다. 더미 변수가 무엇인지 임의로 year, season열에 대해서만 더미 변수로 변환하는 전처리를 진행하여 이해해봅시다.
- [코드스니펫] - 더미변수 설명 참조 블로그
https://kkokkilkon.tistory.com/37
x_features[['year', 'season']]
year는 2011, 2012 두 가지 값을 가지고, season은 1, 2, 3, 4 네 가지 값 중 하나를 가지는 둘 다 전형적인 범주형 변수들입니다. 이를 더미 변수로 변환하면 다음과 같습니다.
pd.get_dummies(데이터프레임의 이름, columns = ['열의 이름1', '열의 이름2']
x_features_dummy_test = pd.get_dummies(x_features[['year', 'season']], columns = ['year', 'season'])
x_features_dummy_test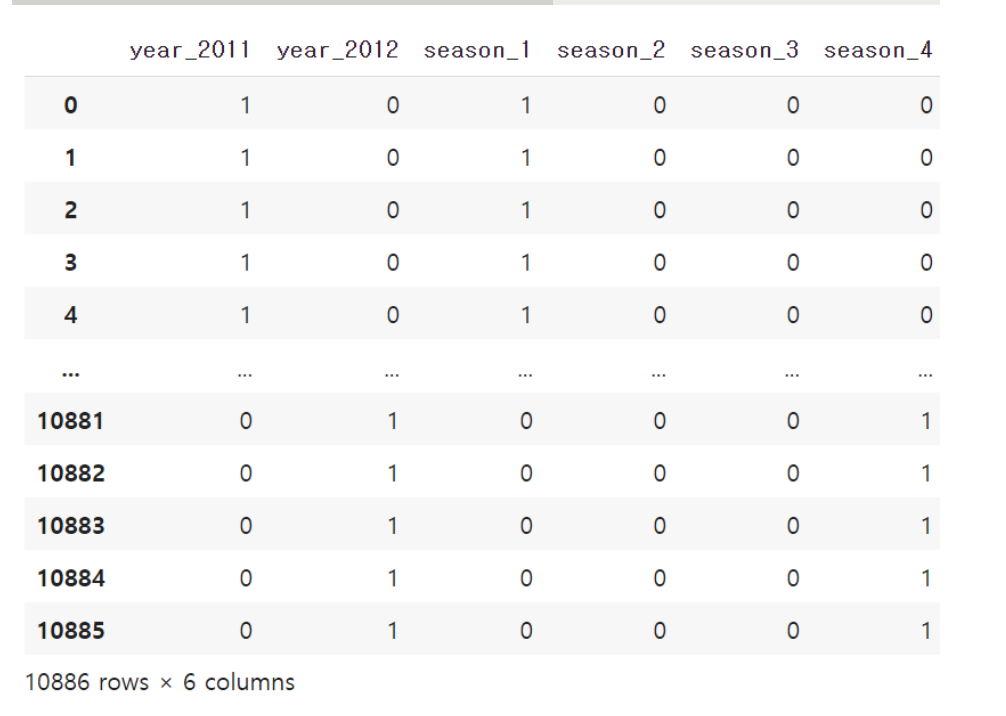
우선, year는 두 가지 값을 가지므로 year_2011과 year_2012 두 개의 열로 변환됩니다. 그리고 2011년인 경우에는 year_2011에 1의 값을 가지고 year_2012는 0의 값을 가지도록 합니다. 비슷하게 season의 경우에는 총 네 가지 종류의 값을 가지고 있었으므로 열이 4개가 됩니다. 가령, 봄인 경우는 season_1의 값이 1이고, 나머지는 전부 0의 값을 가지도록 합니다. 가을인 경우는 어떨까요? 이 경우에는 season_3의 값이 1을 가지고, season_1, season_2, season_4의 경우에는 전부 0의 값을 가지게 됩니다. 이와 같이 데이터를 변환하면 더미형 변수가 되었다고 이야기 합니다.
이렇게 해주므로서 모델이 범주형 데이터와 수치형 데이터를 구분할 수 있게 되어 회귀 분석을 하는데 좀 더 좋은 성능을 기대해볼 수 있습니다.
이제 모든 범주형 변수에 대해서 더미 변수로 변환합니다.
x_features_dummy = pd.get_dummies(x_features,
columns = ['year', 'month', 'day', 'hour', 'holiday', 'workingday', 'season', 'weather'])범주형 변수가 전부 더미형 변수가 되면서 무려 73개의 열을 가지는 데이터로 변환됩니다.
데이터에 변경이 있었으므로 다시 훈련 데이터와 테스트 데이터를 분할합니다.
x_train, x_test, y_train, y_test = train_test_split(x_features_dummy, y_log_transform,
test_size=.3, random_state = 777)
모델을 학습하고, 성능을 확인합니다.
lr = LinearRegression()
lr.fit(x_train, y_train)
pred = lr.predict(x_test)
# 로그 변환 된건 다시 expm1 이용
y_test_exp = np.expm1(y_test)
pred_exp = np.expm1(pred)
calculate_model_score(y_test_exp, pred_exp)결과
RMSLE: 0.600, RMSE: 96.837👨🏫 그냥 로그화를 한거 보다 훨씬 낮아짐. 훨씬 더 좋은 예측모델이 된 것이다.
범주형 변수를 더미형 변수로 바꾸는 작업을 진행해보았다.
4) 각 특성(features) 별 가중치의 시각화
👨🏫 가중치를 시각화 한다는 의미? : 가장 영향을 많이 주는 특성을 찾는다.
우선 zip 함수를 통해서, 더미 특성들과 해당 특성들의 가중치 값을 묶어봅시다.
이후에 sort_values 를 통해서 높은 가중치를 가진 특성이 위로 올라오도록 정렬을 해줍시다!
👨🏫 이렇게 만든다.
DataFrame을 만들고lr.coef_가중치만 출력하는 이것을 쓰고,x_features_dummy.columns그리고 더미, x값에 들어있는 그 열의 이름들을 가지고 와서 = x1이 무엇인지.(x1이랑 x1의 가중치를 가져오는 것과 똑같)- 이렇게
zip()함수로 묶어서 가져온다.columns이름은 []로- 아래는 내림차순으로 정리한다는 말.
coefs = pd.DataFrame(zip(x_features_dummy.columns, lr.coef_), columns = ['feature', 'coefficients'])
coefs = coefs.sort_values(by=['coefficients'], ascending=False).reset_index(drop=True)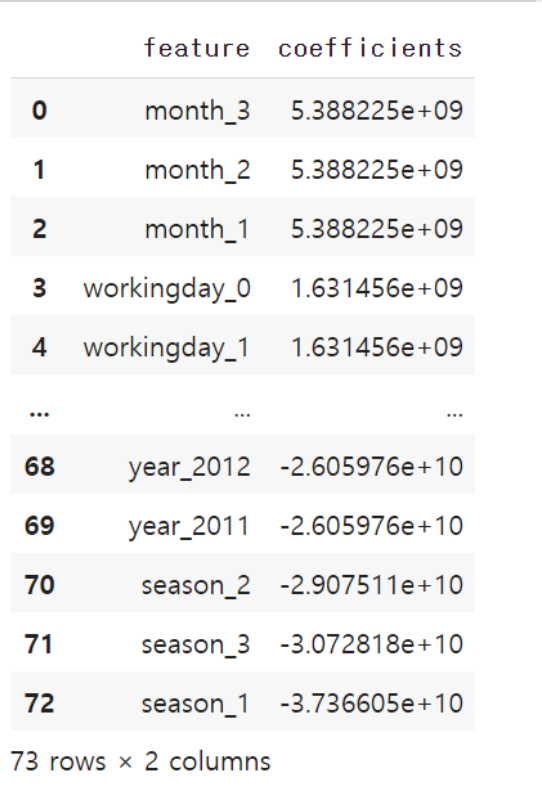
👇👇[:20] 을 해주면, 상위 20개까지의 데이터만 가지고 옵니다.
이를 이용해서 x 에는 가중치값, y 에는 feature 이름을 넣어서 시각화를 해보겠습니다!
👨🏫
.values만 해야 그 값만 가져옴.- y에는 특성의 이름이 들어감
- x에는 가중치 그 값만 들어감
import seaborn as sns
sns.barplot(x=coefs['coefficients'][:20].values, y=coefs['feature'][:20].values)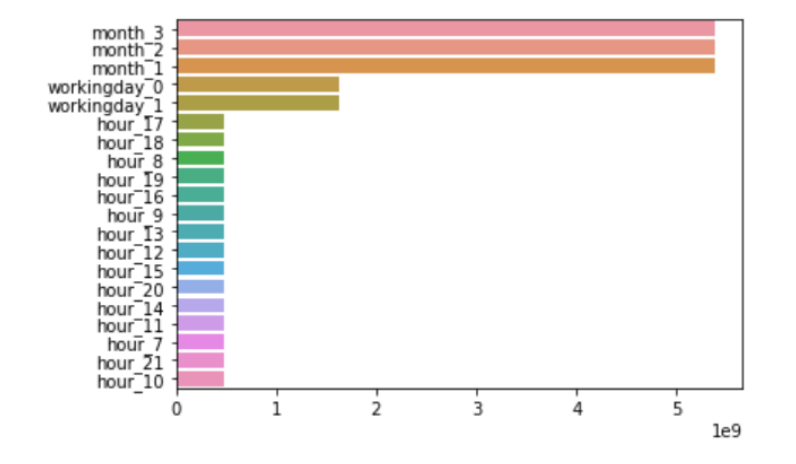
표를 보면 month라는 이 특성 자체가 굉장히 큰 영향을 주고있다는 사실을 파악할 수 있다.
이렇게 시각화를 해 보아서 어떤 특성들이 얼마나 대여량에 영향을 주는지 눈으로 파악해 볼 수 있다.
그 다음시간에는 여기서 조금 더 정확도를 높이는 방법에 대해 공부하겠다.
