👨🏫 이번 시간에는 정확도를 더 높이기 위한 방법을 같이 탐구해볼 것.
두가지 방법이 있는데
- 1) 정규화 하는 방법- 규제로써 말고 정규분포화 할때 했던 방법
- 2) 이상치 탐지 및 제거 - 짧게 살펴봤었는데 이상치가 있으면 데이터 예측에 안좋은 영향을 끼칠수 있으니 제거해 보겠다.
1) 데이터 정규화 (정규분포화) 의 다른 방법
정규화 방법에는 Log 변환 외에도 다음과 같은 정규화 방법이 존재합니다.
[코드스니펫] 앞서 진행한 데이터 불러오는 과정 ~ 열 생성/삭제 과정 요약
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge, LinearRegression
# 앞서 진행한 데이터 불러오는 과정 ~ 필요한 열 생성 과정 요약
# 데이터 불러오기
train = pd.read_csv('https://raw.githubusercontent.com/jesford/bike-sharing/master/train.csv', parse_dates=["datetime"])
# year, month, day, hour 열 생성
train["year"] = train["datetime"].dt.year
train["month"] = train["datetime"].dt.month
train["day"] = train["datetime"].dt.day
train["hour"] = train["datetime"].dt.hour
# 불필요한 열 삭제
drop_columns = ['datetime', 'casual', 'registered']
train.drop(drop_columns, axis=1, inplace=True)사이킷런에서는 다양한 종류의 스케일러를 제공하고 있습니다.

다양한 데이터 정규화 방법이 있는데, 그 중 Standard Scaler는 데이터의 평균이 0이고 표준편차가 1인 정규분포를 가진 값으로 변환하는 방법입니다.
Standard Scaler를 통해서 count 열을 정규화해봅시다.
from sklearn.preprocessing import StandardScaler
# 스탠다드 스케일러를 통해 count 열을 스케일링.
scaler = StandardScaler()
count_scaled = scaler.fit_transform(train['count'].values.reshape(-1, 1))
# 변환된 count열을 count_scaled이라고 명명 후 데이터프레임의 맨 앞 컬럼으로 입력
train.insert(0, 'count_scaled', count_scaled)
train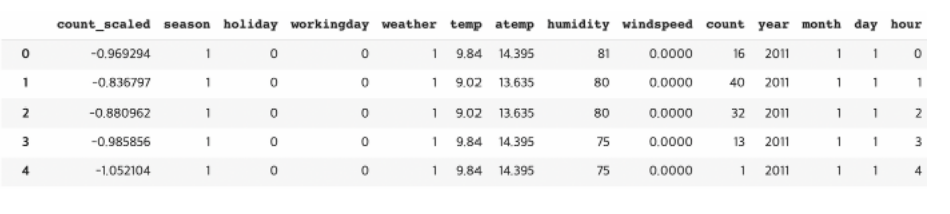
열이 너무 많아서 출력 결과는 중략하였습니다. count 열의 값이 스케일링되었습니다.
👨🏫 앞에 정규화된 count 대여량 값이 이렇게 들어가 있다.
뒤의 원래 대어량과 비교했을때 완전히 다르다. 1같은거는 거의 마이너스에 가깝고, 336 이런것들은 거의 1에 가까운 모습 보이는 것을 확인할 수 있다.
-> 이게 정규화 된것이다. 라고 보면 됨.
👨🏫
StandardScaler()를 사용하겠다 라고 객체를 만들어 주고, 대여량 부분을 정규화 해주겠다는 것이니깐scaler.fit_transform()해서 여기에scaler.를 이용해서train[]이라는 데이터 안에 count 대여량 이 부분을 변환을 시켜주겠다. 정규화를 시켜주겠다는 뜻..values.reshape(-1, 1)이것도 해줘야 에러가 안남.reshape()란, 그냥values()로 출력하면 가로로 그 값들이 출력되는데, 데이터가 나열되는 방향, 모양을 바꾼다고 생각하면 된다. 그래서 세로로만 데이터만scaler에 들어갈 수 있다.reshape()안한 경우train['count'].values >>>>>결과: 가로로 그 값들이 출력된다. array([ 16, 40, 32, ...., 168, 129, 88])
reshape()해주면train['count'].values.reshape(-1, 1) >>>>>결과: 세로로 열들이 행들이 분포하는 것을 확인가능 array([ 16], [ 40], [ 32], ...., [168], [129], [ 88])
- 여기에서
count_scaled하면count_scaled >>>>>>>>>>>>>>>>>결과 : 정규화가 된 그 대여량 값이 표시됨. array([-0.9692938], [-0.83679677], [-0.88096245], ...., [-0.13014594], [-0.13014594], [-0.57180271])
시각화
count_scaled 열을 시각화 해보기. 히스토그램으로.
시각화 하니 범위 자체가 굉장히 달라짐.
값의 범위가 -1에서 약 5 정도로 큰 폭으로 준 것을 알 수 있습니다.
👨🏫 5이하로 다 설명이 된다. - 정규화의 역할
이번에는 count 열을 스케일링. 즉, 정규화한 값을 기준으로 모델을 학습하여 평가합니다.
plt.figure(figsize=(8, 4))
sns.distplot(train['count_scaled'])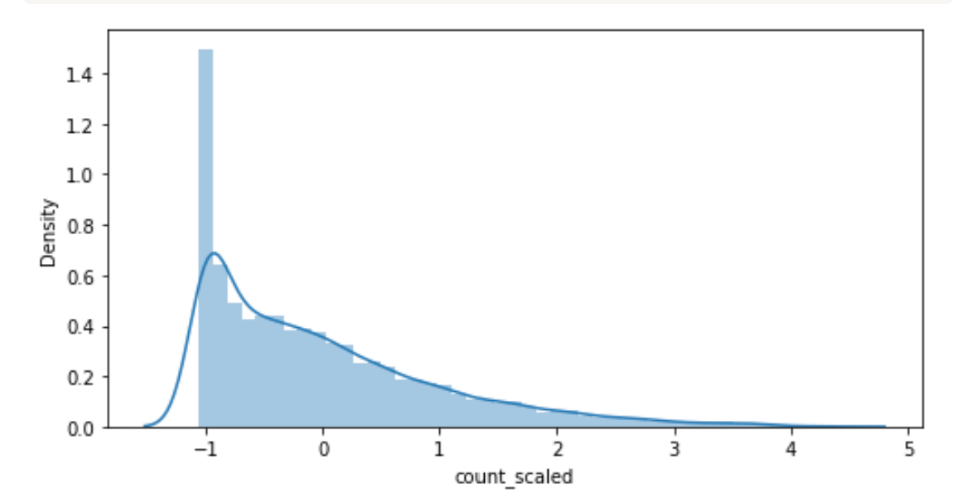
👨🏫 만약에 그냥 count를 출력해 보면, 분포의 형태자체는 달라지지 않았지만, 정규화를 해줌으로써 밑의 값의 밑의 값의 범위가 확 줄어든 것을 확인 해 볼수 있습니다.
plt.figure(figsize=(8, 4)) sns.distplot(train['count'])
이제 토대로 학습을 하면 됨. 학습하는 과정은 지금까지 했던 것과 동일하다.
- 원래는
count를 y타겟으로 넣었었는데 이제는count_scaled넣는다는 것이 차이이다.
우선 x, y 를 분리해줍시다. y에는 count_scaled 가 들어가고, x에는 count/count_scaled 를 제외한 값이 들어가도록 코드를 작성했습니다. 뺀것이 원하는 예측값이어서.
y_target = train['count_scaled']
x_features = train.drop(['count','count_scaled'], axis=1, inplace=False)범주형 변수를 더미변수로 변형해서 활용하는 것이었다.
# 범주형 변수 활용
x_features_dummy = pd.get_dummies(x_features,
columns = ['year', 'month', 'day', 'hour', 'holiday', 'workingday', 'season', 'weather'])훈련 데이터와 테스트 데이터를 7:3으로 분리합니다.
x_train, x_test, y_train, y_test = train_test_split(x_features_dummy, y_target, test_size = .3)모델을 학습합니다.
lr = LinearRegression()
lr.fit(x_train, y_train)모델을 평가합니다
print(lr.score(x_test, y_test))
print(lr.score(x_train, y_train))
>>>>>>>>>>>>>>>>>>>>>> 결과
0.6835369051528181
0.6982715591424863훈련 데이터 정확도가 미세하게 증가한 것을 알 수 있습니다. 그러나 효과적이라고는 볼 수 없을 것 같습니다.
👨🏫
정확도를 보면 이전꺼와 비교했을때 큰 차이는 안난다. 범위 자체가 엄청나게 비이상적으로 넓지 않아서 StandardScaler로 정규화를 해줘도 큰 차이를 나타내지는 못한다.
- ex) 그러나 2주차때 한 줄거리로 장르 예측하기 할때 warning 떴었는데 그 warning을
StandardScaler로 없애줄수 있다.
그러니깐 데이터들 범위가 너무 크면 학습을 하면서 도저히 최적화 못시키겠다며 학습에 오랜 시간이 걸리는 경우도 있고, 아예 최적화가 안되는 경우가 있다. 👉StandardScaler를 쓰면 조금 더 빠르게 학습할 수도 있고 조금 더 빠르게 최적화를 할 수 있다 라는 것 기억하기. StandardScaler는 데이터 범위가 엄청 늘어났을 때 쓰면 유용하고, 데이터 수 자체가 너무 많아졌을때 써도 학습이 빨라진다는 점에서 유용하다.
2) 이상치 제거하기
이상치 데이터(Outlier, 아웃라이어)는 전체 데이터의 일반적인 패턴과는 다른 양상을 보이는 데이터입니다. 일반적이지 않은 패턴이기 때문에 머신 러닝 예측 성능에 영향을 줄 수 있는 요소가 됩니다. 여전히 많은 데이터 사이언티스트들이 이상치 탐지를 위한 연구를 진행해오고 있습니다.
👨🏫 의미있는 데이터들의 어떤 분포 범위에서 너무 벗어나는 값들 너무 높거나 너무 낮은 값들을 그런 것들은 이상치로 분류를 해서 빼면 오히려 데이터 분석에 정확도가 올라갈 수 있다.
이상치 탐지 방법 중에서는 IQR(Inter Qunatile Range) 방법이 있습니다. IQR은 데이터의 사분위 값(Quantile)의 편차를 이용합니다. 사분위란 무엇일까요?
사분위는 전체 데이터들을 오름차순으로 정렬하고, 정확히 4등분(25%, 50%, 75%, 100%)으로 나눕니다. 여기서 75% 지점의 값과 25% 지점의 값의 차이를 IQR이라고 합니다. 이 IQR에 1.5를 곱해서 75% 지점의 값에 더하면 최댓값, 25% 지점의 값에서 빼면 최솟값으로 결정합니다. 이 때, 결정된 최댓값보다 크거나 최솟값보다 작은 값을 이상치 라고 간주합니다. 이 1.5라는 값은 사용자의 판단에 따라서 다른 값을 사용할 수도 있지만, 일반적으로는 1.5를 사용합니다.다음은 boxplot이라고 불리는 차트를 보여줍니다.

이제 이상치를 제거할 특성을 골라야 합니다. 모든 특성에 대해서 이상치를 제거하는 것은 시간적으로도 비효율적이고, 효과적이지도 않습니다. 레이블과 상관도가 높은 특성을 위주로 이상치를 제거하는 것이 좋습니다. 이러한 특성을 고르기 위해서 상관 분석을 진행해봅시다.
👨🏫 다시 불러와서 진행해야 한다.
[코드스니펫] 앞서 진행한 데이터 불러오는 과정 ~ 열 생성/삭제 과정 요약
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge, LinearRegression
# 앞서 진행한 데이터 불러오는 과정 ~ 필요한 열 생성 과정 요약
# 데이터 불러오기
train = pd.read_csv('https://raw.githubusercontent.com/jesford/bike-sharing/master/train.csv', parse_dates=["datetime"])
# year, month, day, hour 열 생성
train["year"] = train["datetime"].dt.year
train["month"] = train["datetime"].dt.month
train["day"] = train["datetime"].dt.day
train["hour"] = train["datetime"].dt.hour
# 불필요한 열 삭제
drop_columns = ['datetime', 'casual', 'registered']
train.drop(drop_columns, axis=1, inplace=True)👨🏫 히트맵을 보면서 이 중에서 정확히 어떤 특성이 대여량에 많은 영향을 주는지 우선 보겠다.
- 이 모든 특성에 대해서 다 이상치를 제거할 수도 있겠죠. 그렇게 하면 시간이 굉장히 오래걸리고, 너무 많이 제거하다 보면 오히려 정확도가 내려가는 경우도 있다.
- 우리에게 필요한 영향을 줄것같은 특성을 뽑아서 그것만 이상치를 제거해 본다.
plt.figure(figsize=(15,10))
sns.heatmap(train.corr(), annot = True, fmt = '.1f')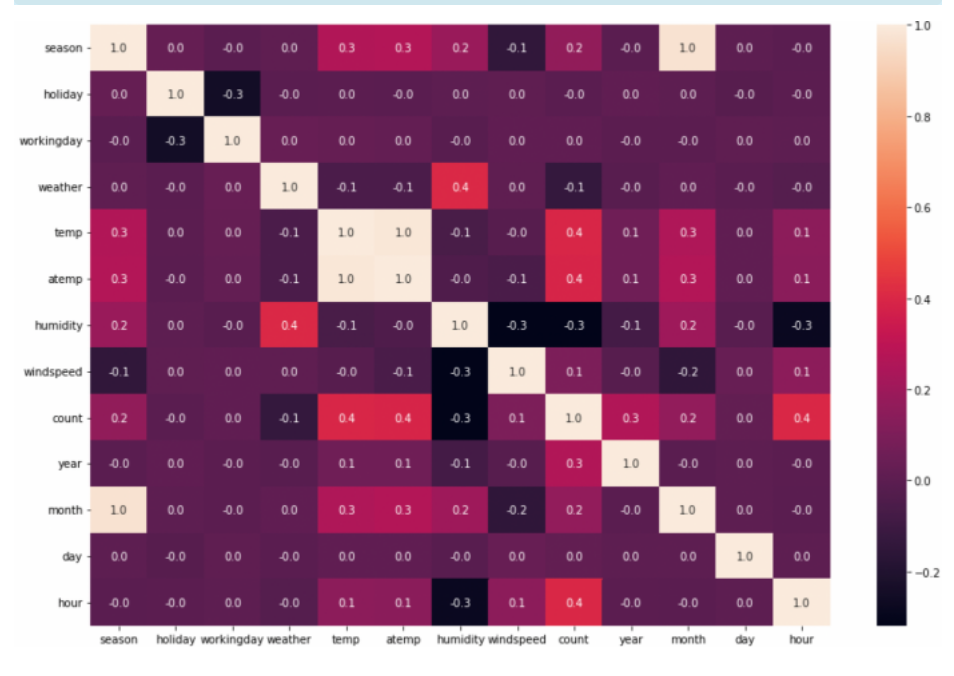
count와 상관관계가 높은 특성은 무엇인가요? temp, atemp, hour이 0.4로 가장 양의 상관도가 높고, humidity가 -0.3으로 가장 음의 상관도가 높습니다. 여기서는 humidity를 임의로 고르고 humidity에 대한 이상치를 제거해봅시다.
- [코드스니펫] 이상치 찾아내기
이상치는 최댓값보다 크고 최솟값보다 작은 거를 이상치라고 함. 그 최댓값,최솟값은 이런식으로 계산한다.외울필요는 없다.
# humidity 열을 fraud 라는 변수로 저장
fraud = train['humidity']
# Numpy의 percential 함수는 입력한 값의 %의 분위값을 추출해준다.
quantile_25 = np.percentile(fraud.values, 25)
quantile_75 = np.percentile(fraud.values, 75)
# IQR에 1.5를 곱한다.
iqr = quantile_75 - quantile_25
iqr_weight = iqr * 1.5
# 최솟값과 최댓값 연산.
lowest_val = quantile_25 - iqr_weight
highest_val = quantile_75 + iqr_weight
# 아웃라이어 필터링 (최솟값보다 작거나 최댓값보다 큰 데이터를 추출) 후 인덱스만 저장
outlier_index = fraud[(fraud < lowest_val) | (fraud > highest_val)].index
>>>>>>>>>>>>>실행 >>>>>>>>>>>>>>>>>>>
이상치 샘플의 인덱스: Int64Index([1091, 1092, 1093, 1094, 1095, 1096, 1097, 1098, 1099, 1100, 1101,
1102, 1103, 1104, 1105, 1106, 1107, 1108, 1109, 1110, 1111, 1112],
dtype='int64')총 22개의 데이터가 이상치 데이터로 뽑혔습니다.
👨🏫 코드 설명)
- 습도라는 열의 있는 값들 중에서 25%, 75%, 그러니깐 Q1, Q3 값을 찾아서 Q3에서 Q1빼고 거기에 1.5를 곱한 값을 Q3에 75%에 더하면 그게 최댓값이 되는 거고, 거기서 Q1에서 빼면 최솟값이 된다.
- 그래서
lowest_val값을 토대로 최댓값보다 큰거 찾아내고, 최솟값보다 작은것.- 조건문 걸었죠. 이렇게 or 조건문. 최솟값보다 작은 데이터가 이상치고, 최댓값보다 큰 데이터가 이상치니깐 그것을 찾아내 달라고 조건문 검.
- 그렇게 해서 그 데이터들이 인덱스 번호가
.index이렇게 출력해 달라고 한것. 그 인덱스 값만 뽑아내 달라고 한 것.outlier_index안에 이상치 값들이 다 저장되어 있습니다.
이제 drop()이라는 함수를 써서 드랍할 것이다. 이상치에 해당하는 행들은 다 없애겠다는 것. 인덱스를 토대로 이상치 데이터를 제거한 후에 해당 데이터로 학습해봅시다.
train.drop(outlier_index, axis=0, inplace=True)
len(train)
>>>>>>>>>>>>>>>>>실행>>>>>>>>>>>
10864원래는 10886개 있었는데 그중에서 22개 없어졌다.
drop() 됨
👨🏫 그 다음은 똑같다. train에서 이상치를 제거했으니깐 train이라는 Dataframe을 x,y나눠주고 거기서 훈련,테스트 데이터 나눠주고 학습을 진행해서 정확도를 보면 됨.
- x, y 분할 및 훈련, 테스트 분할 후 모델 학습 진행
y_target = train['count']
x_features = train.drop(['count'], axis=1, inplace=False)
# 범주형 변수 활용
x_features_dummy = pd.get_dummies(x_features,
columns = ['year', 'month', 'day', 'hour', 'holiday', 'workingday', 'season', 'weather'])
# X_data와 y_data를 7:3 비율로 분할
x_train, x_test, y_train, y_test = train_test_split(x_features_dummy, y_target, test_size=.3, random_state=777)
>>>>>>>>>>>>>>>>>>>>>>>실행 >>>>>>>>>>>>>>>>>
0.6721295107338193
0.7037352548447868
👨🏫 정확도가 굉장히 올라갔다.
훈련데이터가 70%을 넘었던 적이 한번도 없었다. 근데test 데이터는 조금 줄었다. 여기서 규제 같은 것을 써보면 test data에 대해서도 정확도를 올려볼 수도 있겠죠.- 한번 시도 해보시고 이렇게 (2)
이상치 데이터를 해봤더니 정확도 올라간걸 확인했고,- 그 전에 (1)
StatndardScaler()을 써서 정규화. 정규화분포 할때 했던 그정규화. 데이터 자체를 어떤 평균과 분포에 맞게 조정하는 것.- 그래서 이런것들을 막 복합적으로 겹쳐서 사용하면서 정확도를 높혀가는 것이다. 어떻게 하면 정확도를 더 높일 수 있을까 고민하는 과정이 어떻게 보면 머신러닝으로 회귀 분석하는 과정의 전체인 것이다.
- x랑 y 나누고, 훈련데이터랑 테스트데이터 나누고 것들은 기본적인 부분이고,
어떻게 하면 정확도를 높일수 있지?아 범주형 변수를 더미형 변수로 바꿔보자, 아y데이터 그 값을 한번 로그화 해볼까이런 생각들을 하는게 어떻게 보면 더 중요한 부분이라고 할 수 있습니다.- 규제, 정규화, 이상치 공부했으니 꼭 복습하면서 새로운 문제에 직면했을때 어떻게 정확도를 높일수 있을지 고민하는 시간을 가져보면 좋겠습니다.
이상치 데이터가 제거되었으니, x와 y를 분할하고, 범주형 변수를 더미 변수로 활용하겠습니다.
y_target = train['count']
x_features = train.drop(['count'], axis=1, inplace=False)# 범주형 변수 활용
x_features_dummy = pd.get_dummies(x_features,
columns = ['year', 'month', 'day', 'hour', 'holiday', 'workingday', 'season', 'weather'])이제 훈련 데이터와 테스트 데이터를 분할하고, 모델을 학습 후 평가합니다.
# X_data와 y_data를 7:3 비율로 분할
x_train, x_test, y_train, y_test = train_test_split(x_features_dummy, y_target, test_size=.3, random_state=777)lr = LinearRegression()
lr.fit(x_train, y_train)print(lr.score(x_test, y_test))
print(lr.score(x_train, y_tr
>>>>>>>>>>>>>>결과 >>>>>>>>>>
0.6952962691056962
0.6939108142632644여태까지의 실험 중에서 테스트 데이터의 정확도가 가장 높은 것을 확인할 수 있습니다.
