📔 오늘 공부한 내용
오늘부터는 OpenCV 심화 과정에 대해 공부하는 날이다. 지난주에 공부했던 내용들을 바탕으로 실제로 영상에 사용할 수 있는 기법들을 공부했다.
크기 불변 특징과 SHIFT 알고리즘
코너의 특징
코너는 평탄한 영역, 엣지 영역에 비해 변별력이 높다. 따라서 이동, 회전, 변환에 강인하지만 크기 변환에 취약하다는 문제가 있다. 따라서, 코너의 크기가 증가하더라도 코너로 검출할 수 있는 특징점이 있어야 한다.
크기 불변 특징점
Scale-Space 또는 Image Pyramid를 구성해 영상의 크기가 바뀌더라도 반복적으로 검출될 수 있는 특징점을 찾으면 매칭 등의 응용에서 사용할 수 있다. SHIFT, SURE, KAZE, AKAZE, ORB 등이 존재한다.
- feature point ≈ key point ≈ interest point
- descriptor ≈ feature vecto

SIFT 알고리즘
SIFT는 Scale Invariant Feature Transform이라는 알고리즘을 말한다. SIFT 알고리즘은 다음과 같은 과정을 거친다.
[Detector]
① Scale-space extream detection
② Keypoint localization
[Descriptor]
③ Orientation assignment
④ Keypoint description
SIFT - Detector
Scale space는 이미지의 Scale에 따라 분류하고, 에 따라 Gaussian blur를 적용해 DOG(Differenct of Gaussian)을 생성한다. DOG를 사용하면, Keypoint localization을 계산할 수 있다.
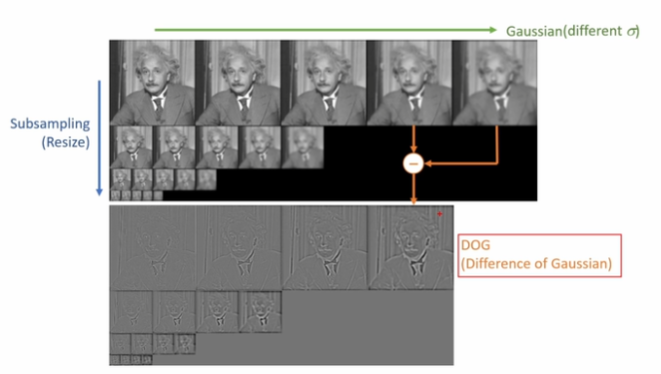
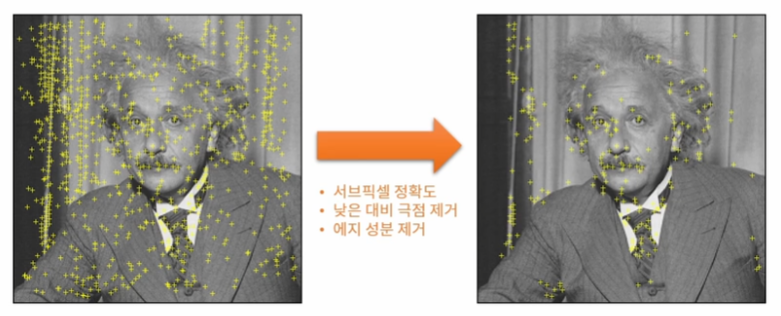
동일 스케일 DOG 영상에서 주변 8개 점과 상/하 스케일 DOG 영상에서 18개의 점, 총 26개의 점을 비교해 Local minima 또는 Local Maxima를 선택한다. 이 점들을 모두 그림에 표시하면 상당히 많은 점이 표시된다. 따라서 이 중 성분을 제거하고, Low contrast를 제거, 서브픽셀 정확도높이면 오른쪽과 같은 결과물을 얻을 수 있다.
SIFT - Descriptor
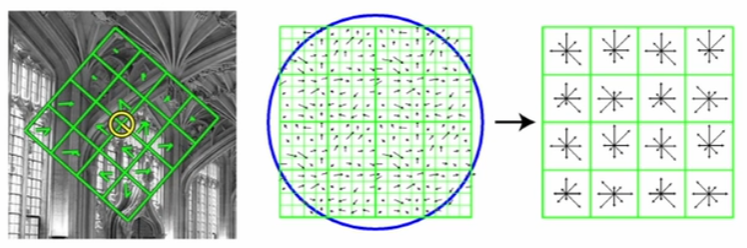
방향 불변 특성을 위해서는 주 방향 성분을 추출해야 한다. 부분 영상의 모든 픽셀에 대해 그래디언트 성분을 계산한 뒤, 히스토그램 최대값 방향과 최대값의 80% 이상 크기를 갖는 빈 방향을 키포인트 방향으로 설정한다.
키포인트는 위치, 스케일, 기준 방향 정보를 가지기에 크기와 방향에 불변한 특징 벡터를 추출할 수 있다. 각 키포인트 위치에서 스케일과 기준 방향을 고려해 사각형 영역을 선택한 뒤, 4x4 구역으로 분할하고 8방향의 방향 성분 히스토그램을 구해 128(4x4x8)차원의 벡터를 생성한다.
SIFT - 특징점 활용
이렇게 구해진 특징점을 통해, 다양한 이미지에서 동일 내용을 파악할 수 있다. 파노라마 이미지, Object Detection 등 Computer Vision의 많은 영역에서 SHIFT 알고리즘이 사용된다.
기타 특징점 알고리즘
- SURF(Speed-Up Robust Features): SHIFT를 기반으로 속도를 향상시킨 크기 불변 특징점 검출 방법으로 적분 영상을 통해 속도를 향상시킨다.
- KAZE: 비선형 스케일 스페이스에서의 공기의 흐름으로 Gaussian function 대신 nonliear diffusion filter를 통해 특정점을 검출한다.
- BRIEF(Binary Robust Independent Elementary Features): 이미 검출되있는 키포인트에서 이진 기술자를 통해 빠른 키포인트를 기술하는 방법이다.
- ORG(Oriented FAST and Rotated BRIEF): FAST 방법으로 키 포인트를 찾고, Harrison 코너 방식으로 순위를 매긴다. 피라미드 영상에 적용해 크기 불변성을 확보하며, BRIEF 방법에서 픽셀 쌍의 좌표를 회전해 특징 벡터를 추출한다. SHIFT, SURF보다 훨씬 빠르고 SURF보다 성능이 좋다.
- AKAZE(Accelerated AKZE): KAZE의 성능향상 기법으로 이진 기술자를 사용한다.
특징점 검출
OpenCV에서는 다양한 특징점 알고리즘들을 내장하고 있다. 다음과 같은 구조로 구성되어 있다.
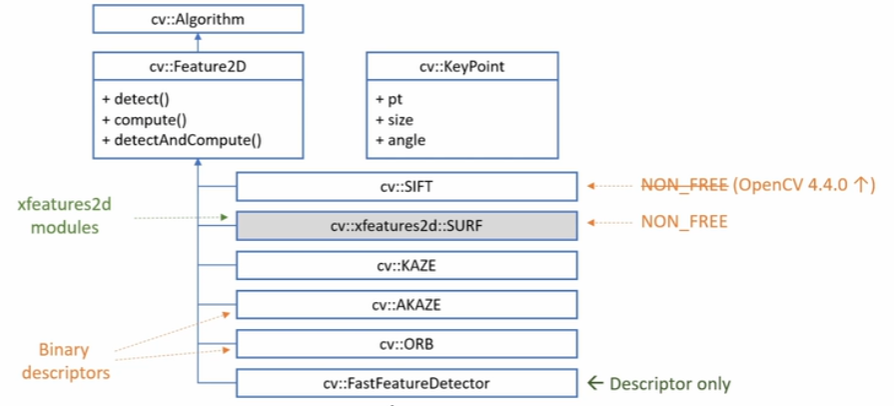
KeyPoint 클래스
KeyPoint 클래스는 특징점을 담기 위한 클래스로 다음과 같은 구조로 구성되어 있다.
class KeyPoint{
public:
KeyPoint();
KeyPoint(Point2f _pt, float _size, float _angle = 1, float _response = 0, int _octave = 0, int _class_id = -1);
KeyPoint(float x, float y, float _size, float _angle = -1, float _response = 0, int _octave = 0, int _class_id = -1);
...
Point 2f pt;
float size;
float angle;
float response;
int octave;
int class_id;OpenCV 특징점 검출
OpenCV에서는 여러 특징점 검출 알고리즘들에 대해 다음과 같이 객체를 생성할 수 있다.
static Ptr<SIFT> SIFT::create(...);
static Ptr<KAZE> KAZE::create(...);
static Ptr<AKAZE> AKAZE::create(...);
static Ptr<ORB> ORB::create(...);
...이 객체를 생성 한 뒤 특징점 검출 함수를 사용하면 된다.
virtual void Feature2D::detect(InputArray image, std::vector<KeyPoint>& keypoints, InputArray mask = noArray());
--- image: 입력 영상
--- keypoints: (출력) 검출된 특징점 정보
--- mask: 마스크 영상SIFT 알고리즘을 통해 특징점을 검출하는 코드의 예시는 다음과 같이 작성할 수 있다.
// SIFT 객체 생성
Ptr<SIFT> detector = SIFT::create();
// KeyPoint 검출
vector<KeyPoint> keypoints;
detector->detect(src, keypoints);
// 결과 이미지에 KeyPoint를 표시
Mat dst;
drawKeypoints(src, keypoints, dst, Scalar::all(-1), DrawMatchesFlags::DRAW_RICH_KEYPOINTS);검출된 키포인트를 원래 하나하나 모두 직접 그려줘야 하지만, OpenCV에서는 Key Point를 표시할 수 있는 drawKeypoints() 함수를 제공한다.
void drawKeyPoints(InputArray image, const std::vector<KeyPoint>& keypoints, InputOutputArray outImage, const Scalar& color = Scalar::all(-1), int flags = DrawMatchesFlags::DEFAULT);
--- image: 입력 영상
--- keypoints: 특징점
--- outImage: 출력 영상
--- color: 특징점 색상(Scalar::all(-1)은 랜덤 컬러 사용)
--- flags: 특징점 그리기 방법(DEFAUL - 단순 위치 표현 원, DRAW_RICH_KEYPOITNS - 크기와 방향을 반영한 원)Lenna 이미지에서 특징점을 검출하면, 다음과 같이 특징점이 검출된다.

특징점 기술자
기술자(Descriptor, feature vector)는 특징점 근방의 부분 영상을 표현하는 실수 또는 이진 벡터를 말하며, OpenCV에서는 Mat 객체로 표현된다. 특징점 기술자는 실수 기술자와 이진 기술자로 분류된다.
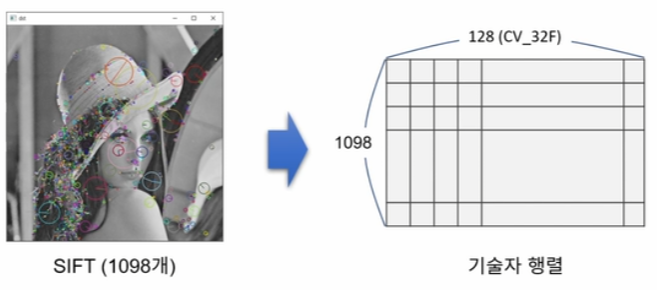
실수 기술자는 각각의 특징점 부근 영상의 방향 히스토그램을 float 자료형을 사용해 저장한다. SIFT, SURE, KAZE 등의 일고리즘이 사용하며, 보통 L2 norm을 사용해 유사도를 판단한다.
이진 기술자는 이진 테스트를 이용해 부분 영상의 특징을 기술한다. uchar 자료형 사용해 비트 단위로 영상 특징 정보를 저장한다. AKAZE, ORB, BRIEF 등의 알고리즘이 사용하며, Hamming distance를 사용해 유사도를 판단한다.
- 특징점 근방 패치에서 point pair의 픽셀 값 크기 테스트:
- 차원 특징 벡터(기술자):
OpenCV에서는 기술자(특징 벡터)를 계산하기 위한 함수를 제공한다.
// 기술자 별도 계산
virtual void Feature2D::compute(InputArray images, std::vector<KeyPoint>& keypoints, OutputArrays descriptors);
// 검출 및 기술자 함께 계산
virtual void Feature2D::detectAndCompute(InputArray image, InputArray mask, std::vector<KeyPoint>& keypoints, OutputArray descriptors, bool useProvidedKeypoints = false);특징점 매칭
특징점을 검출하는 이유는 여러 이미지나 변경된 이미지에 대해서 동일한 부분을 찾기 위함에 있다. 특징점 매칭(feature point matching, keypoint matching)은 두 영상에서 추출한 특징점 기술자를 비교해 유사한 기술자를 선택하는 작업을 말한다. 특징 벡터의 유사도를 측정할 때, 실수 특징 벡터는 L2 norm을, 이진 특징 벡터에서는 Hamming distance를 사용해 측정하게 된다.
OpenCV 특징점 매칭 클래스
OpenCV에서는 특징점 매칭을 위한 클래스를 제공하고 있어서 쉽게 특징점 매칭을 수행할 수 있다. BF(Bruth-force) 방식와 Flann(Fast Library for Approximate Nearest Neighbor, K-D Tree)방식을 지원한다.
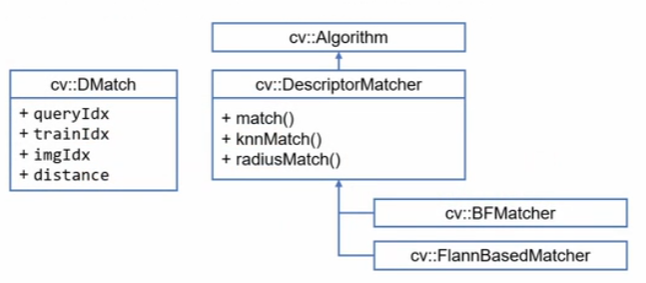
// 최선의 매칭 반환
void DescriptorMatcher::match(InputArray queryDescriptors, InputArray trainDescriptors, std::vector<DMatch>& matches, InputArray mask = noArray()) const
--- queryDescriptors: 질의 기술자 집합
--- trainDescriptors: 훈련 기술자 집합
--- matches: 매칭 결과
--- mask: 서로 매칭 가능한 질의 기술자와 훈련 기술자를 지정 할 때 사용
// 상위 k개의 매칭 반환
void DescriptorMatcher::knnmatch(InputArray queryDescriptors, InputArray trainDescriptors, std::vector<std::vector<DMatch>>& matches, int k, InputArray mask = noArray(), bool compactResult = false) const
--- k: 찾고자 하는 최선의 매칭 개수
--- copactResult: mask 행렬이 비어있지 않을 때 사용되는 파라미터OpenCV에서는 DMatch 클래스를 통해 매칭 결과를 표현한다.
class DMatch{
public:
DMatch();
DMatch(int _queryIdx, int _trainIdx, float _distance);
DMatch(int _queryIdx, int _trainIdx, int _imgIdx, float _distance);
int queryIdx;
int trainIdx;
int imgIdx;
float distance; // 두 특징점 사이의 거리(비유사도)
bool operator<(const DMatch &m) const;
};특징점 매칭 결과 영상은 drawMatches() 함수를 통해 표현할 수 있다.
// img1의 keypoints1, img2의 keypoints2와 매칭결과 matches1to2를 사용해 outImage 생성
void drawMatches(
InputArray img1, const std::vector<KeyPoint>& keypoints1,
InputArray img2, const std::vector<KeyPoint>& keypoints2,
const std::vector<DMatch>& matches1to2,
InputOutputArray outImg,
const Scalar& matchColor = Scalar::all(-1),
const Scalar& singlePointColor = Scalar::all(-1),
const std::vector<char>& matchesMask = std::vector<char>(),
int flags = DrawMatchesFlags::DEFAULT
);
--- matchesMask: std::vector<char>()를 지정하면 모든 매칭 결과를 표시
--- flags: 표현 방식(NOT_DRAW_SINGLE_POINTS: 특징점 표시 X)특징점 매칭을 수행하는 전과정에 대한 코드는 다음과 같이 작성할 수 있다.
vector<KeyPoint> keypoints1, keypoints2;
Mat desc1, desc2;
feature->detectAndCompute(src1, Mat(), keypoints1, desc1);
feature->detectAndCompute(src2, Mat(), keypoints2, desc2);
Ptr<DescriptorMatcher> matcher = BFMatcher::create();
vector<DMatch> matches;
matcher->match(desc1, desc2, matches);
Mat dst;
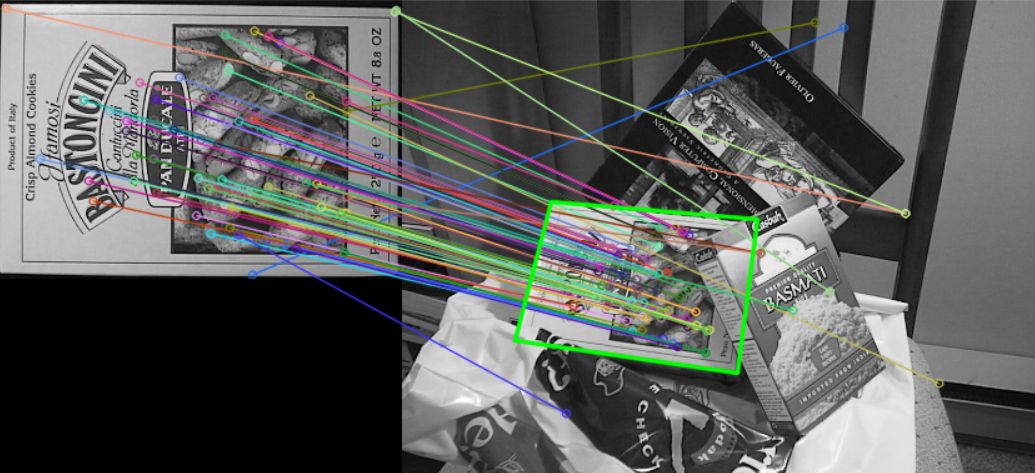
drawMatches(src1, keypoints1, src2, keypoints2, matches, dst);이 동작을 수행하면, 아래와 같은 결과물을 얻을 수 있다. 하지만, 불필요한 매칭점이 너무 많기에 유의미한 데이터를 측정하는 데 불편함이 존재한다.

그러기에 상위 개의 매칭 포인트만 사용하거나, 일부 값 이하의 를 가지는 값들만 매칭하는 것이 훨씬 좋은 데이터를 구할 수 있다.
// 거리에 따라 정렬후 선별
vector<DMatch> matches;
matcher->match(desc1, desc2, matches);
std::sort(matches.begin(), matches.end());
vector<DMatch> good_matches(matches.begin(), matches.begin() + 80);
// knnMatch를 사용해 선별(distance의 임계값을 사용)
vector<vector<DMatch>> matches;
matcher->knnMatch(desc1, desc2, matches, 2);
vector<DMatch> good_matches;
for (const auto& m : matches) {
if (m[0].distance / m[1].distance < 0.7)
good_matches.push_back(m[0]);
}위의 이미지에서 80개의 좋은 매칭 포인트만 찾으면 아래와 같은 결과를 얻을 수 있다.

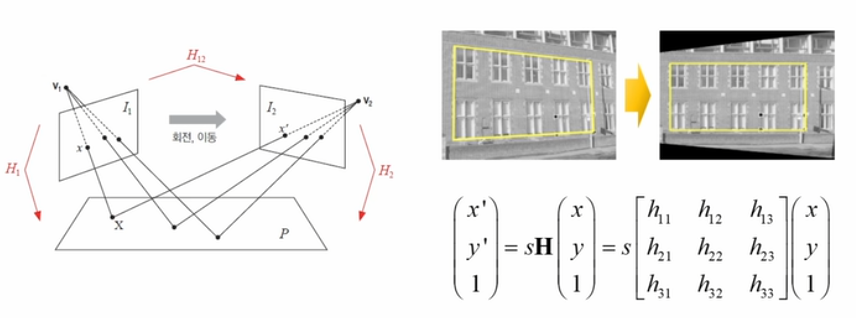
호모그래피(Homography)
호모그래피는 두 평면 사이의 투시 변환(Perspective transform)을 말한다. 8DOF 방식으로 최소 4개의 대응점 좌표가 필요한 기법이다. 호모그래피를 통해 어라운드뷰, BEV(Bird Eye View) 형태의 영상을 만들 수 있다.
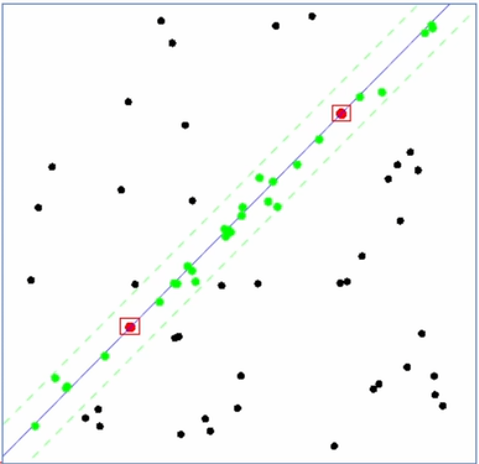
RANSAC 알고리즘
RANSAC 알고리즘은 Random Sample Consensus로 이상치(Outlier)가 많은 원본 데이터로부터 모델 파라미터를 예측하는 방법이다. 아래와 같이 Outlier가 많은 상태에서도 영향을 받지 않고, 직선을 계산할 수 있다.
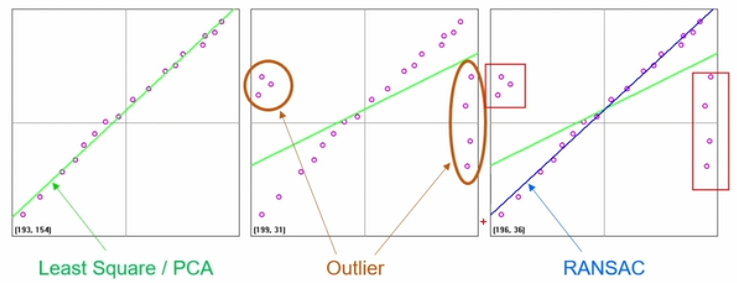
점들간의 직선을 그려보고, 그 직선으로부터 안에 있는 점들의 개수를 가운트해 가장 데이터가 부합하는 직선을 선택하는 방식으로 직선을 계산한다.
호모그래피 행렬
OpenCV에서는 findHomography()라는 호모그래피 행렬을 구할 수 있는 함수를 제공하고 있다.
Mat findHomography(
InputArray srcPoints, InputArray dstPoints,
int method = 0,
double ransacReprojThreshold = 3,
OutputArray mask = noArray(),
const int maxIters = 2000,
const double cofidence = 0.995
);
--- srcPoint: 입력 점 좌표
--- dstPoint: 결과 점 좌표
--- method: 호모그래피 행렬 계산 방버(0: 최소 차승법, LMEDS, RANSAC, RHO)
--- ransacReprojThreshold: 대응점들을 Inlier로 인식하기 위한 최대 허용 에러
--- mask: 출력 mask 행렬(Inlier로 사용된 점들)
--- maxIters: RANSAC 최대 반복 횟수
--- confidence: 신뢰도 레벨(0.0 ~ 1.0)호모그래피 연산 수행
위에서 계산했던 상위 80개의 특징점 매칭을 통해 계산된 결과로 호모그래피 연산을 구행하는 방법은 다음과 같다.
vector<KeyPoint> keypoints1, keypoints2;
// 특징점 검출
Mat desc1, desc2;
feature->detectAndCompute(src1, Mat(), keypoints1, desc1);
feature->detectAndCompute(src2, Mat(), keypoints2, desc2);
Ptr<DescriptorMatcher> matcher = BFMatcher::create();
// 상위 80개 특징점 매칭
vector<DMatch> matches;
matcher->match(desc1, desc2, matches);
std::sort(matches.begin(), matches.end());
vector<DMatch> good_matches(matches.begin(), matches.begin() + 80);
// 호모그래피 행렬 계산을 위한 vector 생성
vector<Point2f> pts1, pts2;
for (size_t i = 0; i < good_matches.size(); i++) {
pts1.push_back(keypoints1[good_matches[i].queryIdx].pt);
pts2.push_back(keypoints2[good_matches[i].trainIdx].pt);
}
// 호모그래피 연산 수행
Mat H = findHomography(pts1, pts2, RANSAC);위의 연산을 수행하면, 특징점 매칭을 통해 찾은 책에 대해 호모그래피를 그리는 기능을 구성할 수 있다.
📝 TIL을 정리하며
🤕 어려웠던 점
크게 어려웠던 점은 없었다.
🤔 궁금한 점
아직은 궁금한 점이 없었다.
😁 느낀 점
결과들이 재미있다. 이론들은 살짝 어렵지만, OpenCV에서 제공하는 함수들을 사용하면 생각보다 간단한 코드로 물체의 위치를 찾는 프로그램을 만들 수 있었다. 앞으로가 기대된다.
📌 프로그래머스 데브코스 6기 자율주행 인지과정(Perception) 수강 내용을 바탕으로 정리한 TIL 입니다.
📅 Today: 2023.10.23.
