📔 오늘 공부한 내용
OpenCV 기초를 공부하는 세번째 날이다. 화소를 처리해서 이미지에 변화를 가져오는 기능들을 위주로 학습을 진행했다.
화소 처리(Point Processing)
화소 처리(Point Processing)은 영상의 특정 좌표 픽셀 값을 변경하는 연산을 말한다.
영상의 밝기 조절
이미지는 0~255의 수치로 값을 표현한다. 그레이스케일 영상에서는 밝기를 조절하기 위해 이 값을 전체적으로 더하거나 줄이면 된다.
이를 코드로 작성하면 다음과 같이 작성할 수 있다. 숫자 50이 Scalar로 OpenCV 내부에서 typecast 되기 때문에 쉽게 변경할 수 있다.
int main(){
Mat src = imread("lenna.bmp", IMREAD_GRAYSCALE);
if(src.empty()){
cerr << "Image load failed!" << endl;
return -1;
}
Mat dst;
dst = src + 50;
// add(src, 50, dst); add 함수를 사용해도 된다.
...
}영상의 데이터는 0 ~ 255로 한정된다. 따라서 연산을 진행했을 때 255을 넘기지 않기 위해서는 saturate_cast를 통해 변환해줄 필요가 있다.(포화연산) 255를 넘게 되면 255로, 0보다 내려가게 되면 0으로 값이 변경된다.
for(int j = 0; j < src.rows; j++){
for(int i = 0; i < src.cols; i++){
dst.at<uchar>(j, i) = saturate_cast<uchar>(src.at(j, i) + 50);
}
}영상의 명암비 조절
명암비(Contrast)는 밝은 곳과 어두운 곳 사이에 드러나는 밝기 정도의 차이를 발한다.

명암비는 비율을 변경해야 하므로, 밝기 조절이 더하거나 빼는 연산을 하는 것에 비해 곱하기 연산을 수행하면 된다.
단순하게 곱셈 연산을 하게되면, 어느 순간을 지났을 때 255를 초과하므로 영상이 많이 날라갈 수 있다. 따라서, 효과적으로 명암비를 조절하기 위해서는 다음과 같이 변환 함수를 구성해야 한다.(m: 그래프의 중간점)
히스토그램(Histogram)
히스토그램(Histogram)
히스토그램(Histogram)은 영상의 픽셀 값 분포를 그래프 형태로 표현한 것을 말한다. 히스토그램 함수는 다음과 같이 표현할 수 있다.
정규화된 히스토그램(Normalized Histogram)은 히스토그램으로 구한 각 픽셀의 개수를 영상 전체 픽셀 개수로 나눈 것을 말한다.
그레이스케일은 0에서 255의 값만 갖고 있으므로, OpenCV의 히스토그램 계산 함수를 쓰지 않아도 쉽게 히스토드램을 구할 수 있다.
// 히스토그램 계산
int hist[256] = {};
for(int y = 0; y < src.rows; y++){
for(int x = 0; x < src.cols; x++){
hist[src.at<uchar>(y, x)]++;
}
}
// 히스토그램 그래프 그리기
Mat imgHist(100, 256, CV_8UC1, Scalar(255));
for(int i = 0; i < 256; i++){
line(imgHist, Point(i, 100), Point(i, 100 - cvRound(hist[i] * 100 / histmax)), Scalar(0));
}
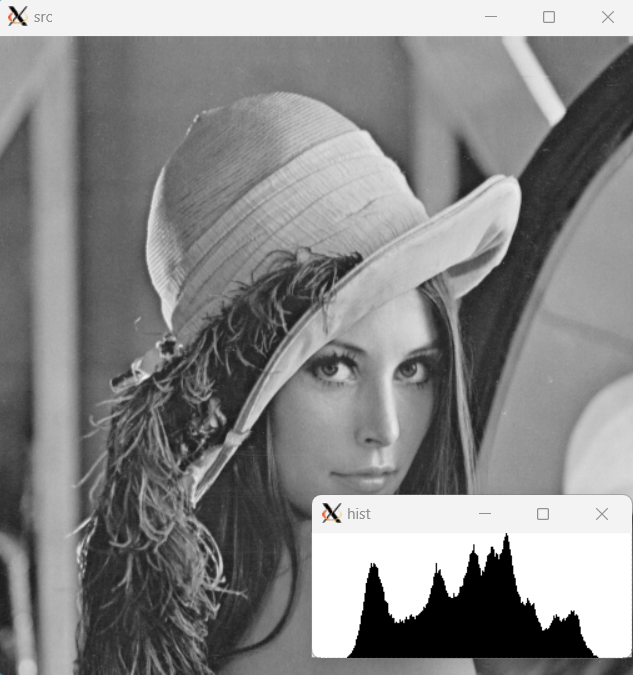
OpenCV 히스토그램 함수
OpenCV에서는 히스토그램을 구하는 함수가 있다. GrayScale 이미지 뿐만 아니라 Color 이미지, 여러 이미지 간의 히스토그램들을 구할수 있기에, 다소 복잡한 형태로 구성되어 있다.
void calcHist(cosnt Mat* images, int nimages, const int* channels, InputArray mask, OutputArray hist, int dims, const int* histSize, const float** ranges, bool uniform = true, bool accumulate = false);
--- images: 입력 영상
--- nimages: 입력 영상의 개수
--- channels: 히스토그램을 구할 채널
--- mask: 마스크 영상
--- hist: 출력 히스토그램
--- dims: 출력 히스토그램 차원
--- histSize: 히스토그램 각 차원의 크기
--- ranges: 히스토그램 각 차원의 최솟값과 최대값
--- uniform: 히스토그램 빈의 간격이 균등한지를 나타내는 플래스
--- accumulate: 누적 플래스위의 그레이스케일 이미지와 동일하게 히스토그램을 OpenCV 함수로 구하는 방법은 다음과 같다.
Mat calcGrayHist(const Mat& img)
{
CV_Assert(img.type() == CV_8U);
Mat hist;
int channels[] = { 0 };
int dims = 1;
const int histSize[] = { 256 };
float graylevel[] = { 0, 256 };
const float* ranges[] = { graylevel };
calcHist(&img, 1, channels, noArray(), hist, dims, histSize, ranges);
return hist;
}히스토그램 스트레칭(Histogram Stretching)
히스토그램 스트레칭은 히스토그램이 그레이스케일 전 구간에 걸쳐 나타나도록 변경하는 선형 변환 기법을 말한다. 히스토그램 스트레칭의 수식은 다음과 같다.
이미지에 0~15에 해당하는 값이 없어도, 히스토그램을 그리게 되면 0~15는 빈 값으로 출력되게 된다. 이 부분에서 빈 부분이 없도록 그래프를 확대해서 보여주는 것을 히스토그램 스트레칭이라 말할 수 있다.
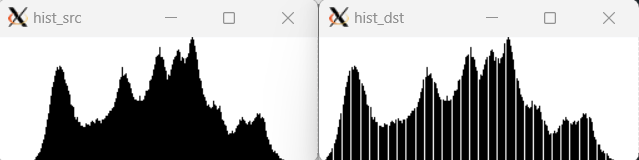
히스토그램 스트레칭은 위의 수식을 그대로 그현하면 된다.
// 직접 히스토그램 스트레칭 수행
double gmin, gmax;
minMaxLoc(src, &gmin, &gmax);
Mat dst = (src - gmin) * 255 / (gmax - gmin);
// normalize 이용
Mat dst;
notmalize(src, dst, 0, 255, NORM_MINMAX);히스토그램 평활화(Histogram equalization)
히스토그램 평활화는 히스토그램이 그레이스케일 전체 구간에서 균일한 분포로 나타나도록 변경하는 명함비 향상 기법이다. 이를 수행하기 위해서는 누적분포함수가 필요하다.
이를 다음과 같이 직접 구현할 수 있다.
Mat dst(src.rows, src.cols, src.type());
int hist[256] = {};
for (int y = 0; y < src.rows; y++)
for (int x = 0; x < src.cols; x++)
hist[src.at<uchar>(y, x)]++;
int size = (int)src.total();
float cdf[256] = {};
cdf[0] = float(hist[0]) / size;
for (int i = 1; i < 256; i++)
cdf[i] = cdf[i - 1] + float(hist[i]) / size;
for (int y = 0; y < src.rows; y++) {
for (int x = 0; x < src.cols; x++) {
dst.at<uchar>(y, x) = uchar(cdf[src.at<uchar>(y, x)] * 255);
}
}OpenCV에서는 히스토그램 평활화를 위한 함수를 지원하기 때문에 위처럼 작성하는 것보다 함수를 이용하는 것이 더 편리하다.
Mat dst;
equalizeHist(src, dst);이를 수행하면, 아래 이미지처럼 0과 255에 가까운 값들도 전체적으로 높게 나오는 것을 볼 수 있다.
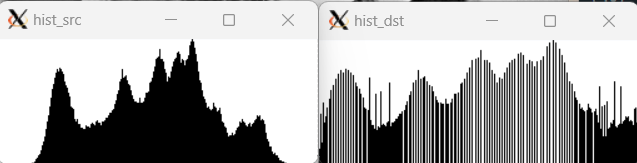
히스토그램 스트레칭과 히스토그램 평활화를 하게 되면 두 방법 모두 명암비가 높아지는 효과를 얻을 수 있다. 다만, 스트레칭은 직선의 방정식, 평활화는 곡선의 방정식 형태로 이루어진다는 것을 알아야 한다.
영상의 산술 및 논리 연산
영상에는 다양한 산술 및 논리 연산을 수행할 수 있다. 이 연산들을 통해 다수의 사진을 병합하거나, 병합된 사진들을 통해 잡음을 제거하는 결과물을 만들 수 있다.
덧셈 연산
두 영상의 데이터를 합산하는 연산이다.
가중치 합(Weighted sum)
두 영상을 더할 때 가중치 합을 계산해 결과 영상의 픽셀 값으로 설정한다. 보통 이 되도록 설정한다.
뺄셈 연산
두 영상의 데이터를 빼는 연산이다. 덧셈과 다르게 순서에 따라 결과물이 변경될 수 있다.
차이 연산
두 영상의 뺄셈에 절댓값을 사용해 영상간 차를 확인하기 위한 연산이다.
// 행렬의 덧셈
void add(InputArray src1, InputArray src2, OutputArray dst, InputArray mask = noArray(), int dtype = -1);
// 행렬의 가중치 합
void addWeighted(InputArray src1, double alpha, InputArray src2, double beta, double gamma, OutputArray dst, int dtype = -1);
// 행렬의 뺏셈
void subtract(InputArray src1, InputArray src2, OutputArray dst, InputArray mask = noArray(), int dtype = -1);
// 행렬의 차이 연산
void absdiff(InputArray src1, InputArray src2, OutputArray dst);
// 행렬의 AND
void bitwise_and(InputArray src1, InputArray src2, OutputArray dst, InputArray mask = noArray());
// 행렬의 OR
void bitwise_or(InputArray src1, InputArray src2, OutputArray dst, InputArray mask = noArray());
// 행렬의 XOR
void bitwise_xor(InputArray src1, InputArray src2, OutputArray dst, InputArray mask = noArray());
// 행렬의 NOT
void bitwise_not(InputArray src, OutputArray dst, InputArray mask = noArray());📝 TIL을 정리하며
🤕 어려웠던 점
크게 어려웠던 점은 없었다. VSCode를 사용해 실습을 진행하기에 한번 코드를 수정하면 build를 다시 해야되는 것이 불편했다. 이 부분에 대해 개선할 수 있는 방법이 있는지 알아봐야겠다.
🤔 궁금한 점
아직은 궁금한 점이 없었다.
😁 느낀 점
지금 당장 이 수업에서 배운 내용들이 어떻게 활용되는지는 알지 못하겠다. 하지만, 나중에 OpenCV를 통해 딥러닝을 수행할 때 이 지식들이 필수적이라는 것은 느낄 수 있었다. 기본기를 다지기 위해 열심히 해야겠다.
📌 프로그래머스 데브코스 6기 자율주행 인지과정(Perception) 수강 내용을 바탕으로 정리한 TIL 입니다.
📅 Today: 2023.10.19.
