참고:
https://blog.naver.com/gypsi12/222977571589
https://velog.io/@gunny1254/Variational-Auto-Encoder-VAE
https://blog.naver.com/gypsi12/222972181857
https://chickencat-jjanga.tistory.com/192
https://www.youtube.com/watch?v=yQvELPjmyn0&t=399s
VQ-VAE 에서 다루고자 하는 문제점
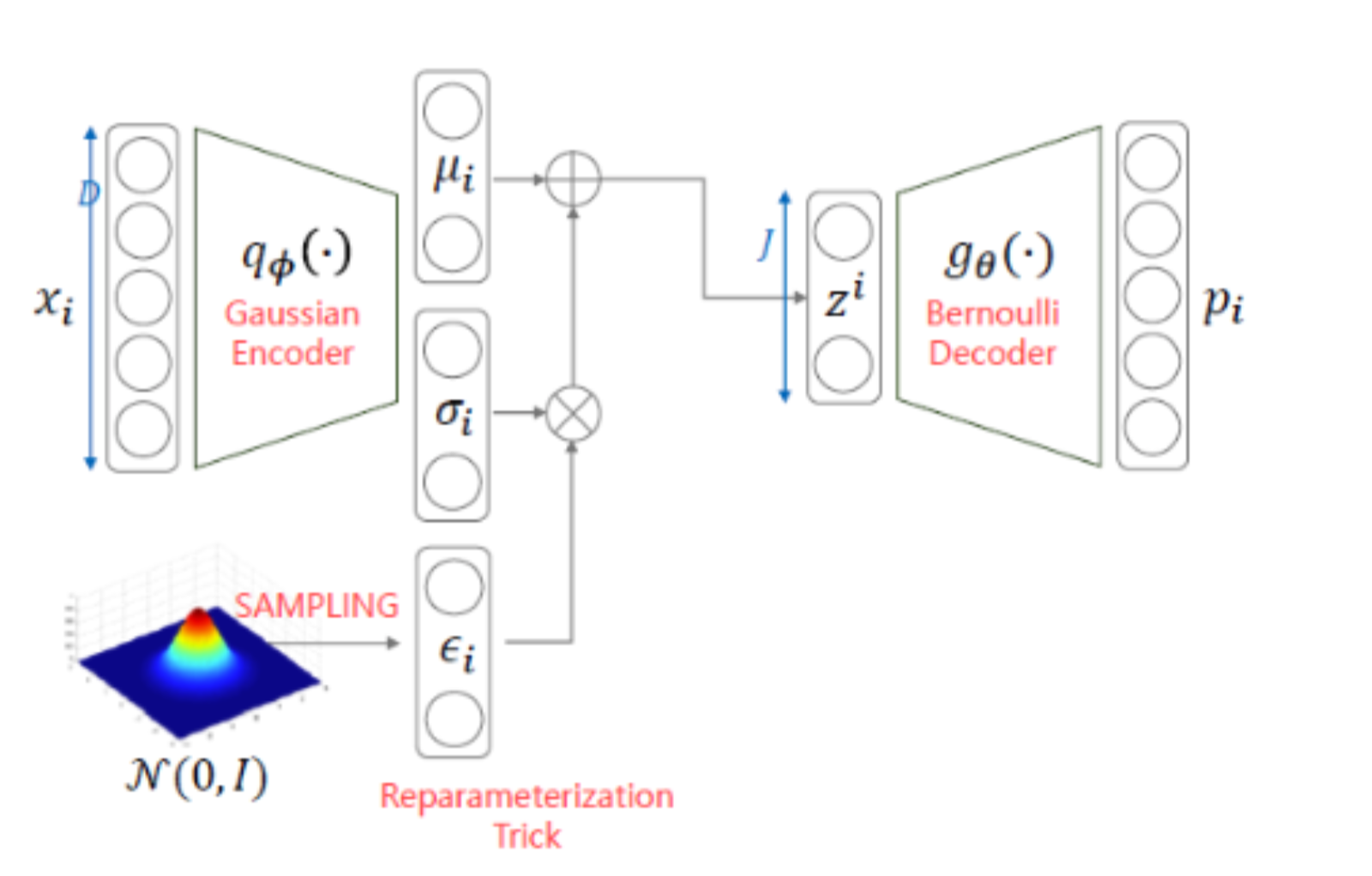

위의 그림은 VAE 의 모델 구조와 loss 를 나타낸 Figure 이다.
VAE 에서 특히 Regularization term 이 0 이 되어버려
q_ϕ(z∣xi) = q(z) 가 되어, 더이상 x 를 참조하지 않아버리는 posterior collaps 현상이 나타나게 되어진다.
이 현상으로 인하여, encoder 의 condition 을 무시하여 decoder 에서 output 을 생성하게 되어진다.
이런 현상에 대해서 다루기 위해, VQ-VAE 가 나타나게 되어진다.
VQ-VAE
Idea
VAE 에서의 문제는 Optimization 과정중에 q_ϕ(z∣xi) 가 더이상 xi 를 참조하지 않는다는 점이다.
그러면, xi 에 대한 확율분포와 유사한 벡터들을 따로 만들어서 사용하면 어떨까?
Terminology
- CodeBook
- Code
Quantization
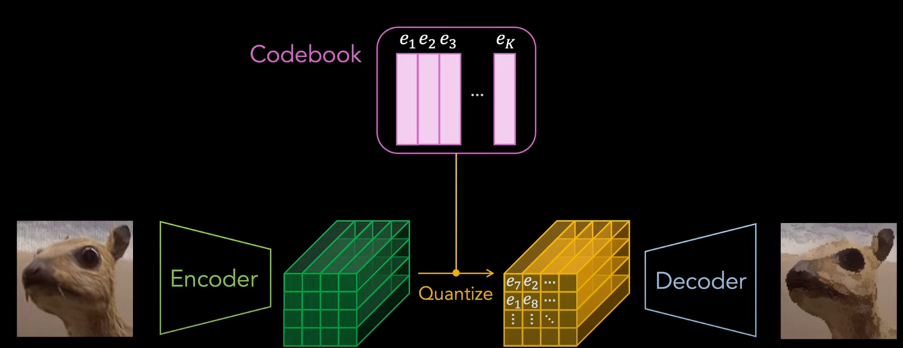
여기서 trainable 한 것은 3가지 요소이다.:
- Encoder
- CodeBook
- Decoder
Input image is input to Encdoer (CNN), the dimension of the code book Is defined by the feature dimension in the encoded vector
-> 각각의 features in the encoded output 들은 in lantspace (Ze) Codebook 에 구성요소들 e_i 에서 L2 Norm 으로 가까운 얘들로 replace 해당 z 가 e 로 바뀌게 되어진다.
-> 이런 바뀌어진 featujre 들을 decoder 에 넣어서 output 을 얻는다
