강의 주소 : 연남대 최규상 교수님 컴퓨터 구조 강의 (2015년)
Chapter 2. Instructions : Language of the Computer
2.1 Introduction
1) Instruction Set
- 명령어들의 집합
- 다른 컴퓨터는 다른 instruction set을 가진다.
- 초창기 컴퓨터들은 아주 단순한 instruction set을 가졌었다. = instruction의 수가 적었다.
- 최근의 컴퓨터들도 단순한 instruction set을 가지고 있다. -> 초창기에 단순했고 복잡해지다가 다시 단순해지는 과정을 거침(복잡했던 시기 : Complex IS가 있었음)
2) ISA(Instruction Set Architecture)
ISA란?
- 명령어 집합 구조
- HW와 저레벨 SW(OS)간의 인터페이스 : SW에서 HW로 넘어가는 단계에서 중재자 역할
- instruction, register, memory access, I/O 등을 포함한, 기계어 프로그램을 작성하기 위해 필요한 모든 정보
- 필요한 정보를 모아 HW(CPU)에 주면, HW가 이를 실행
- ISA가 같은 경우, 똑같은 SW를 여러 CPU에서 실행할 수 있다.
ABI(Application Binary Interface)란?
ISA + OS 인터페이스- 어떤 프로그램이 특정 머신에서 실행이 가능할 때, ABI가 같다면 다른 머신에서도 실행이 가능하다.
3) The MIPS Instruction Set
MIPS = Millions Instructions Per Second(CPU의 이름이기도 함)
- Stanford 대학에서 처음 제안한 MIPS는 MIPS Technologies라는 회사에 의해 상용화되었다.
- CPU는 가능한 메인 메모리보다 CPU 내부의 메모리인 레지스터로부터 데이터를 읽어오는 것이 속도가 더 빠르다.
- MIPS는 임베디드 시스템에 많이 쓰이고 있다.
- 현대의 ISA들과 비슷한 특성을 공유한다.
2.2 Operations of the Computer HW
1) Arithmetic Operations
산술 연산
- ADD a, b, c = a에 b + c의 값을 저장
- 2개의 source와 하나의 destination
👉 설계 원칙 1. Simplicity favors regularity
- 규칙성을 이용해 구현을 간결하게(수월하게) 한다.
- 간결성은 cost가 낮은 상황에서도 성능을 높일 수 있도록 해준다.
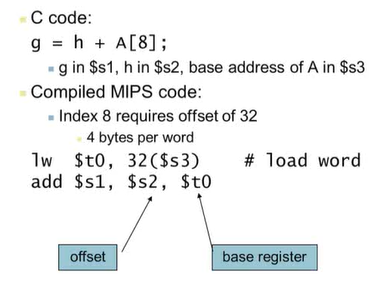
Arithmetic 예제

C 코드를 컴파일해 MIPS의 어셈블리 코드로 만들면 위 그림처럼 3가지의 어셈블리 명령어가 된다.
2.3 Operands of the Computer HW
1) Register Operands
- Arithmetic instruction들은 register operand를 사용한다.
- MIPS는 32개(0 ~ 31)의 32-bit register 파일을 갖는다.
- Assembler names
- temporary values : $t0, $t1, ... $t9
- saved variables : $s0, $s1, ... $t7
👉 설계 원칙 2. Smaller is faster
- 적을수록 빠르다.
- 메인 메모리는 수백만개의 구역을 가진다. 반면 레지스터는 32-bit가 32개인 굉장히 작은 저장소로, 메인 메모리보다 약 1000배 더 속도가 빠르다.
Register Operands 예제

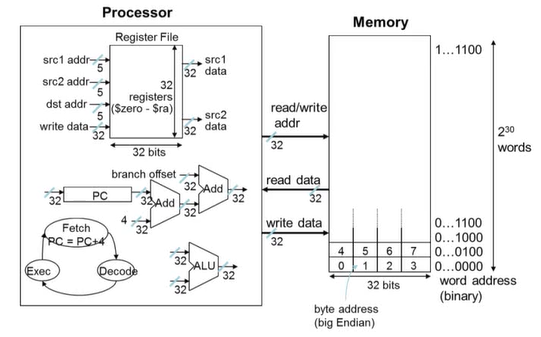
2) Byte Addresses
- 대부분의 아키텍처들은 메모리를 byte 단위(8-bit)로 지정한다.
- Alignment restriction : 32-bit 프로세서에서 메모리 주소들은 word(32bit) 단위로 묶여진다.
데이터를 읽는 방식
-
Big Endian
- 높은 비트에서 낮은 비트 순으로 데이터를 읽는다.
- 가장 왼쪽 byte가 word address
- IBM 360/370, Motorola 68k, MIPS, Sparc, HP PA
-
Little Endian
- 낮은 비트에서 높은 비트 순으로 데이터를 읽는다.
- 가장 오른쪽 byte가 word address
- Intel 80x86, DEC Vax, DEC Alpha(Windows NT)
- 하드웨어에서는 보통 리틀 엔디안을 사용한다.
3) Memory Operands
- 메인 메모리는 복합 데이터를 다룬다.
- 산술 연산을 하려면
- 메모리에서 레지스터로 값을 적재시킴
- 연산 결과를 레지스터에서 다리 메모리로 가져옴
- 메모리는 byte 단위로 접근
- 주소 한 칸은 byte(8-bit)로 이루어짐
- word 단위로 메모리에 정렬
- 주소들은 4의 제곱
- MIPS는 Big Endian
- 가장 큰 자릿수의 바이트가 word(4byte)의 least address에 위치
Memory Operand 예제 1.
Memory Operand 예제 2.

4) Register vs Memory
- 메모리에 직접 접근하는 것보다 레지스터 접근하는 것이 훨씬 빠름
- Load-Store Architecture(MIPS) : 메모리의 데이터를 이용하기 위해 레지스터에 데이터를 불러오고(= load), 다시 메모리에 저장(= store)하는 방법 이용 -> 더 많은 명령어들이 필요
- 컴파일러는 가능한 변수들을 레지스터로 활용해 처리해야 함
- 변수 처리를 위해 메모리에 접근하는 일을 덜 수행하도록
- 컴파일러, 컴퓨터 아키텍처에서 레지스터 최적화는 매우 중요 -> 가능한 메모리에 접근을 줄여 load, store instruction을 적게 수행하도록
5) MIPS Register File
MIPS는 32개의 32-bit 레지스터를 갖는다. -> 각각 5bit(2^5 = 32)만 담을 수 있어도 충분하다.
2개의 read 포트 + 1개의 write 포트
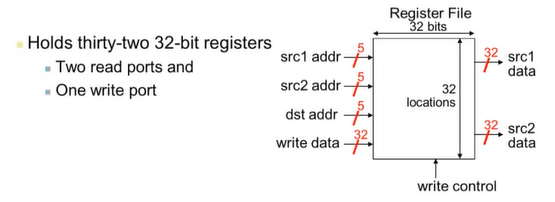
레지스터
- 레지스터는 메인 메모리보다 빠르지만, 구성되는 레지스터 수가 많을수록 속도가 느리다.
- read, write 포트의 증가로 속도에 2차 함수적인 영향을 준다.
- 컴파일러가 쓰기에 용이하다.
- code density 향상(메모리는 32bit, 레지스터는 5bit 필요)
MIPS Register Convention
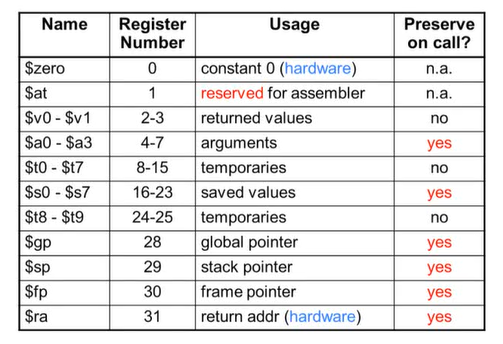
6) Immediate Operands
- 즉각 연산(변수가 아닌 상수)
- instruction에 상수(constant data) 사용
- 뺄셈은 지원하지 않으므로 덧셈에 음수 값을 사용
👉 설계 원칙 3. Make the common case fast
- 많이 발생되는 사항을 빨리 처리한다.
- 적은 수의 상수는 프로그래밍에서 자주 사용된다. -> 바로 사용 가능
- load instruction의 수를 줄여준다.
The Constant Zero
- MIPS 레지스터의 0번 레지스터는 항상 0이다.
- 값을 변경할 수 없는 고정된 상수, 읽기만 가능한 레지스터
- 많은 작업들에 유용
2.4. Signed and Unsigned Numbers(컴퓨터가 숫자를 사용하는 방식)
1) Unsigned Binary Integers
- 부호가 없는 이진 정수
- 범위 : 0 ~ 2^n - 1
2) 2s-Complement Signed Integers
- 부호가 있는 정수를 표현할 때는 2의 보수 사용
- 범위 : (-2)^(n-1) ~ 2^(n-1) - 1
3) Signed Negation
- 부호 반전
- 보수를 취하고 1을 더한다.
- 예) 2의 보수 : 1 -> 0, 0 + 1 = 1
4) Sign Extension
- 수의 비트 범위 확장
- 같은 수를 더 많은 비트를 이용해 표현
2.5 Representing Instructions in the Computer(명령어가 숫자를 사용하는 방식)
1) Representing Instruction
- 모든 명령어들은 binary로(기계어) 인코딩된다.
- MIPS instruction
- 32-bit의 word로 인코딩
- 적은 종류의 포맷으로 되어 있음
- 규칙성을 가짐
- 레지스터 번호
- $t0 ~ $t7의 레지스터 번호 : 8 ~ 15
- $t8 ~ $t9의 레지스터 번호 : 24 ~ 25
- $s0 ~ $s7의 레지스터 번호 : 16 ~ 23
- 명령어 형태 : R-Type, I-Type, J-Type
2) MIPS R-format Insturctions
레지스터 타입

- op : operation code, 어떤 종류의 연산을 할지
- rs : first source register number, 피연산자1이 들어있는 레지스터 번호
- rt : second source register number, 피연산자2가 들어있는 레지스터 번호
- rd : destination register number, 연산결과가 담길 레지스터 번호
- shamt : shift amount
- funct : function code, opcode와 함께 어떤 종류의 연산을 할지
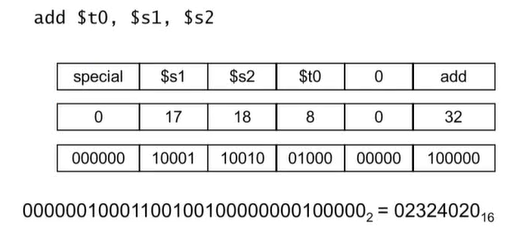
R-format Example
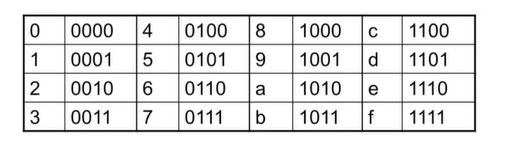
Hexadecimal
- 16진수(0 ~ 15)
- 예) eca8 6420 -> 1110 1100 1010 1000 0110 0100 0010 0000
3) MIPS I-format Instructions
즉시값(Immediate) 타입
Immediate arithmetic과 load/store instructions에 이용되는 포맷

- rt : destination 혹은 피연산자2의 레지스터 번호
- constant : -2^15 ~ 2^15 - 1의 수 표현 가능
- address : rs에 담긴 base address로부터 얼마나 멀리 있는지
👉 설계 원칙 4. Good design demands good compromises
- Immediate arithmetic과 load/store instruction은 별개의 작업이지만 I-format으로 모두 표현할 수 있다.
- 다른 종류의 작업들을 한 포맷으로 표현하면 decode하는 것을 어렵게 만들지만 32-bit instruction들을 균일하게 해준다.
4) Stored Program Computers
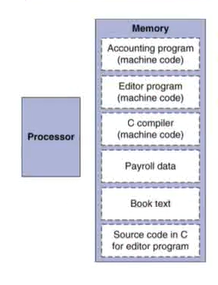
- 명령어들은 binary로 표현된다.
- 명령어들과 데이터는 메모리에 store된다.
- 프로그램은 다른 프로그램 위에서 동작하기도 한다. -> compilers, linkers 등
- Binary 일치성은 컴파일된 프로그램이 다른 컴퓨터에서도 작동되게 해준다. -> Standardized ISAs
2.6 Logical Operations
1) Logical Operation
bit 단위 조작을 위한 instruction -> word(32bit 집합)에서 비트 그룹을 추출하거나 새로 집어넣을 때 유용
2) Shift Operation
- 왼쪽으로 shift
- 전체 비트가 왼쪽으로 이동, 오른쪽의 빈 공간들은 0으로
- i 비트만큼 왼쪽으로 shift하면 2^i와 같음
- 오른쪽으로 shift
- 전체 비트가 오른쪽으로 이동, 왼쪽의 빈 공간들은 0으로
- i 비트만큼 왼쪽으로 shift하면 2^i만큼 나눈 것과 같음(unsigned only : 부호 있는 정수표현에서 MSB가 무조건 0이 되므로)
3) AND Operation
word에서 특정 부분의 비트를 뽑을 때 유용

4) OR Operation
word에서 특정 부분을 포함시킬 때 유용

5) NOT Operation
word의 비트들을 모두 반전시킬 때 유용
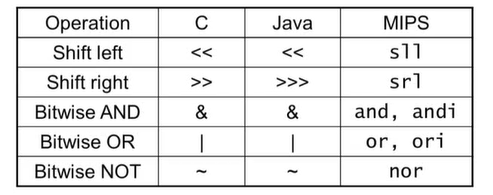
- MIPS는 NOT operation을 가지고 있지 않음 -> NOR 3항 연산으로 구현
2.7. Instructions for Making Decisions
1) Conditional Operation
만약 조건이 true라면 표시, 표시된(labeled) instruction으로 향하는 분기(branch)
- beq rs, rt, L1 : 만약 rs == rt라면, L1이라고 표시된 instruction으로 이동
- bne, rs, rt, L1 : 만약 rs != rt라면, L1이라고 표시된 instruction으로 이동
- j L1 : 무조건 L1이라고 표시된 instruction으로 이동
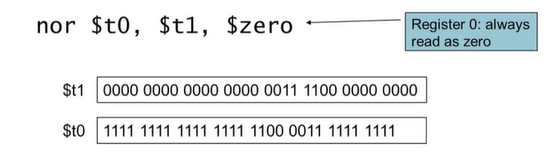
2) Compiling If Statements(if문)
3) Compiling Loop Statements(while문)

4) Basic Blocks
- 어떤 명령어들의 sequence(순서)로 모인 집합
- embedded branch(일체형 분기)가 없다.
- branch target(분기 대상, labeled)이 없다.
- 컴파일러, 프로세서는 최적화를 위해 이런 basic block을 찾아 빨리 실행하도록 한다.
- 프로세서는 baic block의 수행을 가속시킬 수 있다.
5) Branch Instruction Design
- 왜 blt(branch less than), bge(branch greater or equal than)를 지원해주지 않는가?
-> HW에서 위의 연산은 =, != 보다 느리고 복잡하다.
-> 모든 분기를 지원하면 한 instruction마다 기존보다 더 많은 일이 수행되고 클럭 속도가 느려진다. 따라서 모든 instruction 전체게 불이익을 받는다.
-> beq와 bne가 더 일반적인 경우로 많이 사용된다.
-> 좋은 설계를 위한 타협
6) Signed vs Unsigned
signed (부호 있는 비교) : slt, slti
unsigned (부호 없는 비교) : sltu, sltui
2.8. Supporting Procedures in Computer HW
1) 6 Steps in Execution of a Procedure
- Main routine(Caller)이 파라미터를 프로시저(Callee)가 접근가능한 곳에 위치시킨다.
- Caller가 제어권을 Callee에게 넘겨준다.
- Callee는 필요한 storage(메모리)를 할당받는다.
- Callee는 요구되는 일을 수행한다.
- Callee는 결과값을 Caller가 접근가능한 곳에 위치시킨다.
- Callee는 제어권을 Caller에게 반납한다.
2) Register Usage

3) Procedure Call Instructions
프로시저 호출(call) : jump and link
jal "Procedure Label"
- 바로 다음에 올 instruction의 주소를 $ra에 담는다.
- 타겟 주소(프로시저가 수행되기 위해 label된)로 점프
프로시저 리턴(return) : jump register
jr $ra
- 프로그램 카운터(PC : 현재 실행하고 있는 명령어의 메모리 주소)에 $ra를 복사한다.
- jr은 computed jump에 사용되기도 한다.
4) Leaf Procedures
Leaf Procedure : 함수에서 다른 함수를 호출하지 않는 것
int leaf_example(int g, h, i, j)
{
int f;
f = (g + h) - (i + j);
return f;
}위의 코드를 Assembly 코드로 바꾸면 다음과 같다.
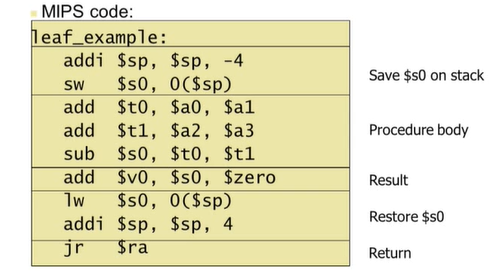
1. 4만큼 스택포인터 이동(위에서 아래로 이동)
2. 기존 $s0에 있던 것을 $sp에 저장해둔다. -> 새로운 루틴으로 들어가며 $s0을 사용하기 위해
3. MIPS는 MOV(move 명령어)가 없으므로 $zero의 add로 처리
4. $sp에 저장해둔 것을 $s0으로 복귀
5. 4만큼 스택포인터 복귀
6. 프로시저 다음 명령으로 진행
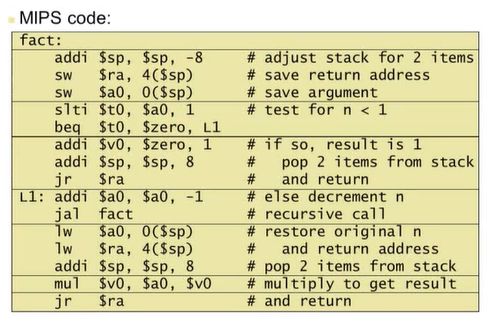
5) Non-Leaf Procedures
Non-Leaf Procedure : 프로시저 내에서 다른 프로시저를 호출하는 것
- nested call이 있으므로 Caller는 스택에 다음 값들을 저장해야 한다.
- 반환될 주소
- 필요한 매개값이나 임시값
- call 이후에 스택에 저장해둔 값을 복원시켜야 한다.
// 팩토리얼을 계산하는 C 함수
int fact(int n)
{
if (n < 1) return 1;
else return n * fact(n - 1);
}위의 코드를 Assembly 코드로 바꾸면 다음과 같다.
6) Local Data on the Stack
프로그램에서 프로시저(함수)가 호출될 때 메모리가 어떻게 할당되는가?
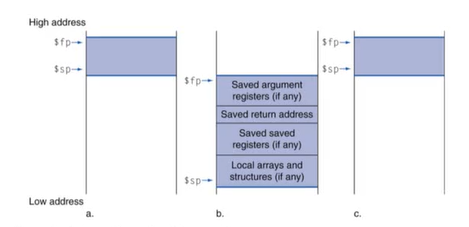
- $sp는 현재 스택의 top을 가리키고 $fp(frame pointer)는 이번 프로시저에 할당되기 직전 가리키고 있던 스택포인터(activation record의 시작 주소)를 가리킨다.
- procedure frame(= activation record)
- $fp에서 $sp까지 -> 하나의 함수를 실행할 때 할당되는 메모리 공간
- 몇몇 컴파일러들은 스택 공간을 관리하기 위해 사용
- local data는 Callee에 의해 할당된다.
7) Memory Layout
실제 사용하는 메모리의 구조
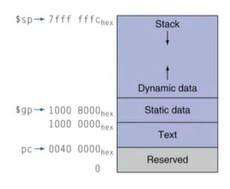
- Text : 프로그램 코드(명령어들)
- Static data : 전역 변수들
- Dynamic data : heap 메모리에 할당(Java에서의 new, C에서의 malloc)
- Stack : automatic storage
2.9. Communicating with People
1) Character Data
Byte-encoded character sets
- ASCII : 128 characters
- Latin-1 : 256 characters
Unicode : 32-bit character set
- Java, C++ 등에서 사용
- 대부분의 국가 언어 문자, 기호 표현 가능
- UTF-8, UTF-16 : 여러 길이의 인코딩 존재
2) Byte/Halfword Operations
bitwise operation으로 1비트씩 옮길 수도 있지만, byte/halfword 단위로도 데이터 이동이 가능하다.

String Copy 예제
// leaf procedure
void strcpy (char x[], char y[])
{
int i = 0;
while ((x[i]=y[i]) != '\0')
{
++i;
}
}x와 y의 주소는 각각 레지스터 $a0, $a1에, i의 값은 $s0에 매핑되어 있다고 가정.

2.10. MIPS Addressing for 32-Bit Immediates and Addresses
1) 32-bit Constants
- 대부분의 상수는 작은 크기이다. -> 16-bit의 immediate로도 충분
- 가끔 32-bit의 상수를 사용한다. -> 2개의 instruction 필요
lhi rt, constant

- 16bit의 상수를 rt 왼편 16비트 자리에 복사
- rt의 나머지 오른편 16비트 자리는 모두 0이 됨
2) Branch Addressing

- 대부분의 분기 대상(branch target)은 branch 근처에 위치한다.
- PC-relative addressing
- target address = PC(프로그램 카운터) + offset x 4
- MIPS에서 PC는 어떤 루틴에 들어가면 다음에 실행할 명령의 주소값을 가리키게 되어있다. 따라서 이미 이번 분기에 진입할 때 4만큼 증가했던 것이다. -> 타겟 주소 계산 시 고려해야 함
3) Jump Addressing

- 점프 대상은 어디든지 가능하다.
- Direct jump addressing
- target address = PC(31...28) : address x 4
4) Branching Far Away
분기 대상 주소가 너무 멀어 16-bit의 offset으로 커버할 수 없다면 어셈블러는 코드를 다시 작성한다. -> branch 명령어 대신 jump 명령어 사용
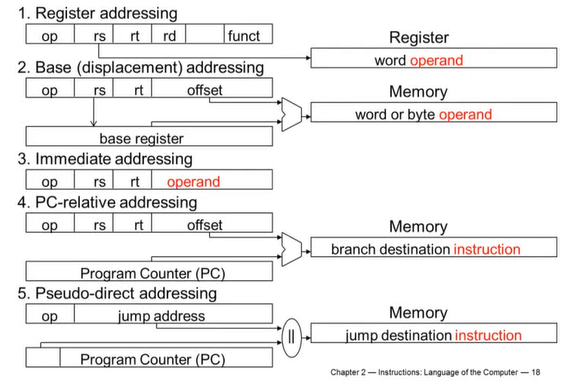
5) Addressing Mode Summary
MIPS에서 5가지 addressing 방법
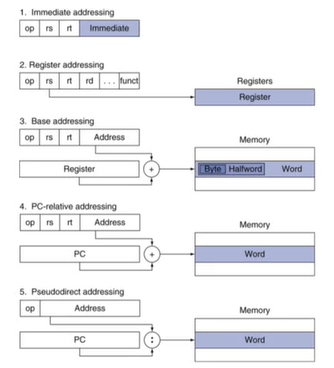
2.11 Parallelism and Instructions : Synchronization
1) Synchronization
동기화
- 두개 이상의 프로세서가 메모리의 같은 영역을 공유 -> race-condition 발생
HW적으로 동기화 해결
- Atomic read/write memory operation을 활용
- spin lock 메커니즘을 구현할 때 사용
2.12 Translating and Starting a Program
1) Translation & Startup
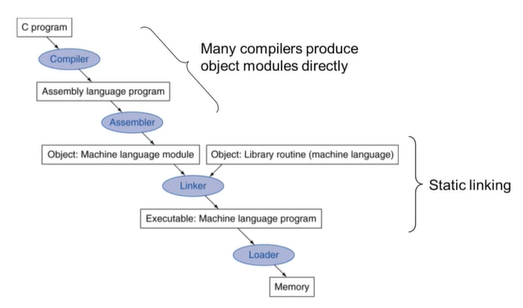
1. C언어로 작성된 프로그램을 컴파일러가 어셈블리어 프로그램으로 해석
2. 어셈블리어 프로그램을 어셈블러가 기계어 모듈로 해석
3. 내 코드로 만들어진 오브젝트들과 사용한 라이브러리에 의해 만들어진 오브젝트들을 링커가 합쳐 실행가능한 기계어 프로그램(실행파일)으로 작성 = static linking(<-> dynamic linking)
4. 실행파일이 실행되기 위해 로더가 실팽파일을 메모리에 로드
2) Assembler Pseudoinstructions
- 대부분의 어셈블러 instruction들은 기계 instruction들을 1:1 대응으로 표현한다.
- 실제 MIPS instruction엔은 없지만 어셈블러에서 사용할 수 있는 가짜 명령어 -> 어셈블러가 이를 실제 MIPS instruction으로 바꿔줌
3) Producing an Object Module
Object Module은 하나의 완전한 프로그램을 만들기 위한 정보를 가지고 있다.
- Header : object module의 내용
- Text segment : 번역된 instructions
- Static data segment : 프로그램의 수명과 함께 할당된 데이터
- Relocation info : 로드된 프로그램에서 절대경로에 의존하는 내용들을 위해
- Symbol table : global definition과 external ref들
- Debug info : 디버깅을 위한 source 코드 정보
4) Linking Object Module
하나의 실행가능한 이미지 생성
1. 조각들(segments)을 병합한다.
2. label을 결정한다.
3. 경로 의존적인 것들을 해결하고, 외부 참조들을 처리한다.
relocating loader에 조절되는 경로 의존성을 그냥 둔다.
하지만 가상 메모리 환경(현재 컴퓨터 형태)에서는 그럴 필요가 없다. = 버려도 된다.
가상 메모리 환경은 모든 프로그램들이 같은 메모리 영역을 사용하므로 경로 의존 정보가 필요 없어진다. -> 프로그램은 가상 메모리 공간의 절대 경로로 로드될 수 있다.
5) Loading a Program
- segment size들을 결정하기 위해 header를 읽는다.
- 가상 메모리 공간을 만든다.
- 텍스트, 초기 데이터를 메모리에 복사한다.
- 스택에 arguments을 세팅한다.
- 레지스터를 초기화한다.
- startup 루틴으로 점프한다.
- 실행이 끝나면 exit syscall을 수행한다.
5) Dynamic Linking
- 해당 함수를 호출할 때만 라이브러리 함수에 link/load
- 재배치 가능한 프로시저 코드가 필요하다.
- 모든 라이브러리를 static linking으로 이미지에 포함시키면 이미지가 아주 커질 수 있고, 메모리에도 공통되는 라이브러리 코드가 여러 번 존재할 수 있는데 이를 방지할 수 있다.
- DLL(Dynamically Linked Libraries)이 별도로 존재하기 때문에 프로그램 코드를 수정하지 않아도 라이브러리 프로시저를 이용할 때 자동적으로 새 버전의 라이브러리를 적용시킬 수 있다.
Lazy Linkage
항상 Dynamic Linking에 필요한 정보들을 통해 프로시저들을 메모리에 미리 전부 준비시키는 방식이 있고, 처음 프로시저가 호출되었을 때 준비시키는 방식이 있다. 후자가 Lazy Linkage.
-> dynamic linking은 static linking에 비해 속도가 느릴 수 밖에 없다.
2.13 A C Sort Example to Put It All Together
1) C Sort Example
// Swap procedure(leaf)
void swap(int v[], int k)
{
int temp;
temp = v[k]; v[k] = v[k + 1];
v[k + 1] = temp;
}v는 $a0, k는 $a1, temp는 $t0에 매핑되어 있다고 가정.
어셈블리 코드

2) The Sort Procedure in C
// non-leaf(bubble sort)
void sort(int v[], int n)
{
int i, j;
for (i = 0; i < n; ++i)
{
for (j = i - 1; j >= 0 && v[j] > v[j + 1]; --j)
{
swap(v, j);
}
}
}v는 $a0, k는 $a1, temp는 $t0에 매핑되어 있다고 가정.
어셈블리 코드 : Procedure Body

어셈블리 코드 : Full Procedure

3) Effect of Compiler Optimization
컴파일러 최적화의 효과
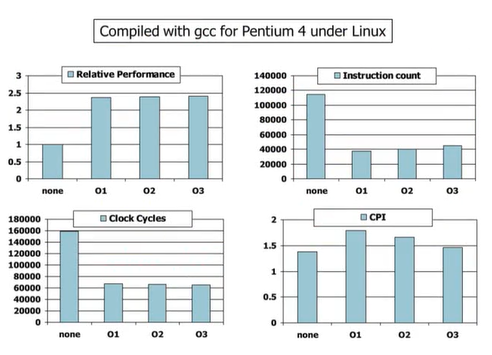
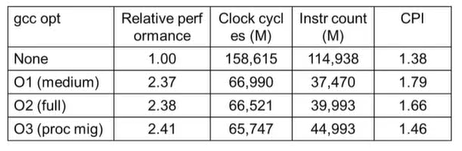
-> o3의 성능이 가장 좋고 o1의 성능이 가장 낮다.
Compiler Benefits
버블 정렬을 통해 본 성능 비교 : 100,000개의 데이터를 정렬하는 작업을 Pentium 4, 2GB DDR SDRAM, Linux 2.4.20 환경에서 테스트한 결과
4) Effect of Language and Algorithm
버블 정렬을 서로 다른 언어로 구현 후 성능 비교 : 기본적으로 Java가 C보다 느리다. 특히 인터프리터 방식의 Java는 성능차이가 많이 났으나 JIT 컴파일러의 발전으로 성능차이를 많이 따라잡았다.
-> 인터프리터는 line by line으로, JIT 컴파일러는 chunck 단위로
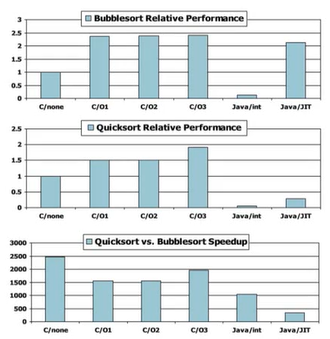
5) Lessons Learnt
- Instruction count와 CPI는 각각 별개로는 성능 측정의 좋은 지표가 아니다.
- 컴파일러 최적화는 알고리즘(코드 구현 방식)에 좌우된다.
- Java에서 JIT 컴파일된 코드는 JVM의 인터프리터 방식보다 아주 빠르다.
- 좋지 않은 알고리즘으로는 성능을 향상시키기 어렵다.
2.14 Arrays versus Pointers
1) Array vs Pointers
배열
- 요소의 크기를 index에 곱한다.
- 배열의 기본 주소에 위의 값을 offset으로 더한다.
포인터
- 메모리 주소를 직접적으로 가리킨다.
- offset을 계산하는 과정을 피할 수 있다. -> 성능 향상에 도움
Comparison of Array vs Pointers
- 인덱스 계산(shift 연산)을 줄이는 효과가 쌓이며 성능 향상
- 배열 방식은 루트문 내부에서 shift 명령 필요
- 인덱스를 나타내는 변수가 변하면서, 여기에 맞춰 주소를 다시 계산하기 때문
- 포인터 방식에서는 그냥 주소에 바로 증감
- 배열을 사용해도 컴파일러는 프로그래머가
포인터를 명시적으로 사용한 것과 같은 효과를 최적화로 이끌어낼 수 있음- 유도 변수 제거(i를 사용하는 방식)
- 코드가 깔끔하고 안전
-> Array 권장
2.15 Real Stuff : ARM Instructions
1) ARM과 MIPS의 유사점
ARM(Advanced Risk Machine) : 임베디드 코어 시장에서 가장 많이 쓰이는 프로세서 방식으로 MIPS와 아주 유사하다.
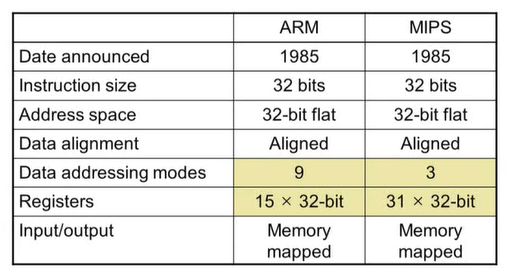
-> 최근의 ARM(v8)은 64-bit 지원
2) Compare and Branch in ARM
- 산술/논리 instruction의 결과를 써서 조건 코드를 만들 수 있다.
- negative, zero, carry, overflow
- 결과를 보존하기보다는 condition code에 넣어 compare instruction에 사용
- 각 명령어가 conditional이 될 수 있다.
- instruction의 최상위 4비트를 condition 값으로 둠
- 단일 instruction만으로도 branch 구문 없이 조건적인 동작 가능
Instruction Encoding
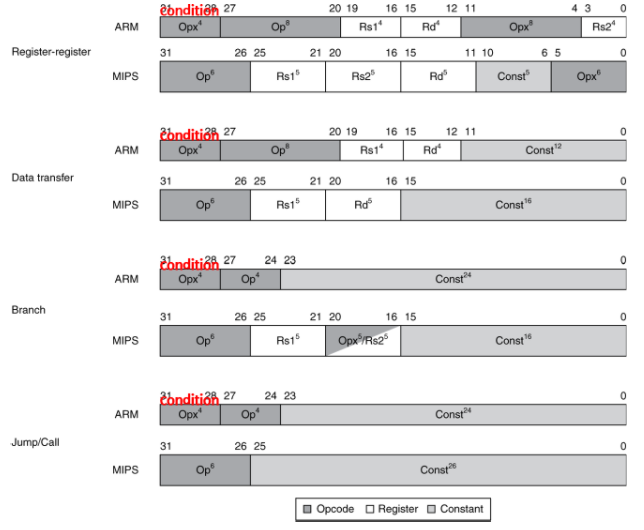
2.16 Real Stuff : x86 Instructions
1) The Intel x86 ISA
하휘 호환성(backward compatibility)을 유지하며 발전
- 8080(1974) : 8-bit 마이크로프로세서
- 8086(1978) : 8080으로부터 16-bit 확장
- 8087(1980) : floating-point corprocessor
- 80286(1982) : 24-bit addresses, MMU 포함
- 80386(1985) : 32-bit extension -> IA-32
- i486(1989)
- Pentium(1993)
- Pentium Pro(1995)
- Pentium III(1999)
- Pentium 4(2001)
- EM64T(2004)
- Intel Core(2006)
- Advanced Vector Extension(2008)
2) Intel 프로세서의 레지스터
Basic x86 Registers
-> MIPS와 달리 레지스터의 길이가 동일하지 않다.

Basic x86 Addressing Models
x86의 주소 표현 방식 : instruction마다 2개의 operand 존재
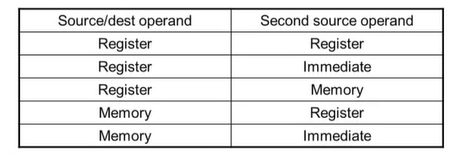
Memory addressing models

x86 Instruction Encoding
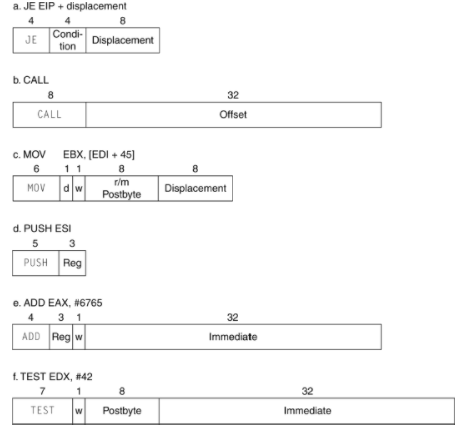
-> 다양한 길이의 encoding(MIPS는 명령어의 길이가 32-bit로 고정)
-> 첫 번째 설계 원칙에 위배되는 아키텍처 : 레지스터의 길이도 다르고 addressing mode도 많고 instruction의 길이도 다르다. 따라서 높은 성능을 기대하기 힘들지만 고성능을 보여주고 있다.
Implementing IA-32
CISC : Complex Instruction Set Computer
- 복잡한 instruction set은 implementation을 어렵게 한다. 따라서 HW가 instruction을 간단한 microoperation으로 나누어 준다.
- RISC와 비슷한 microengine을 가지고 있다. -> Micr engine이 RISC와 유사
- 비용이 들지만 시장 점유율 덕분에 경제적으로 실현 가능하다.
- RISC와 견줄만한 성능을 낸다. -> 컴파일러가 복잡한 instruction을 해결시켜 준다.
-> Intel 프로세서는 겉은 CISC지만, 속은 RISC와 같다. CISC instruction을 RISC 방식의 microoperation으로 나누어주는 오버헤드를 제외하면 내부적인 성능은 RISC와 유사하다.
RISC : Reduced Instruction Set Computer
2.17 Real Stuff : ARM v8(64-bit) Instructions
1) ARM v8 Instructions
64-bit이 되며 ARM은 기존의 것들을 많이 포기했다. 높은 성능을 내기 위해 기존의 것을 버리고 MIPS와 유사한 형태로 바뀌었다.
ARM v8은 MIPS와 닮아있다.
v7과 달라진 점은 다음과 같다.
- conditional execution field(상위 4비트)를 없앰
- immediate field를 12-bit로 고정
- 여러 개의 word를 동시에 load/store하는 방식 포기
- PC는 더 이상 GPR이 아님
- GPR을 32-bit 확장
- addressing mode는 모든 word 크기에 동작
- devide instruction
- equal 이라면 분기(beq)와 equal이 아니라면 분기(bne) instruction 지원
2.18 Fallacies and Pitfalls
1) Fallacies(오류)
- Powerful instruction(하나의 명령어가 여러 동작을 한 번에 수행)이 고성능으로 이어지는가? -> X
- 구현을 어렵게 만든다.
- 여러 일을 동시에 하는 명령어를 실행하기 위해 느린 clock을 사용해야 하고 이로 인해 모든 명령어들이 느려진다.
- 컴파일러는 powerful instruction보다 simple instruction으로 만들어진 코드에서 더 빠르게 동작한다.
- 고성능을 위해 어셈블리 코드를 사용해야 하는가? -> X
- 현대의 컴파일러는 최적화를 잘 시켜주기 때문에 HLL로도 어셈블리 코드와 유사한 성능으로 이끌어 준다.
- 오히려 어셈블리 코드로 인한 line 수 증가는 더 많은 오류를 증가하게 하고 생산성이 떨어진다.
- 단, 임베디드 시스템과 같은 특수한 경우 어셈블리 코드를 사용해야 할 상황이 생기기도 한다.
- 하휘 호환성(backward compatibility = 예전 것을 새로운 환경에서도 지원)을 유지하려면 instruction set은 바꿀 수 없는가? -> X
- 하휘 호환성을 유지한다는 것이 instruction set을 바꾸지 않는다는 말은 아니다.
- 시간이 지남에 따라 명령어의 수가 증가하지만 예전에 지원했던 명령어도 계속 사용이 가능하다.
2) Pitfalls(함정)
- Sequential words are not at sequential addresses
- Keeping apointer to an automatic variable after procedure returns
Addressing Modes Illustrated
MIPS Organization So Far