3. Data 확보 & 전처리(Preprocessing)
3-1. Data 확보
일단 앞서 글에서 언급한 것처럼 KOSIS 사이트에 접속한다.
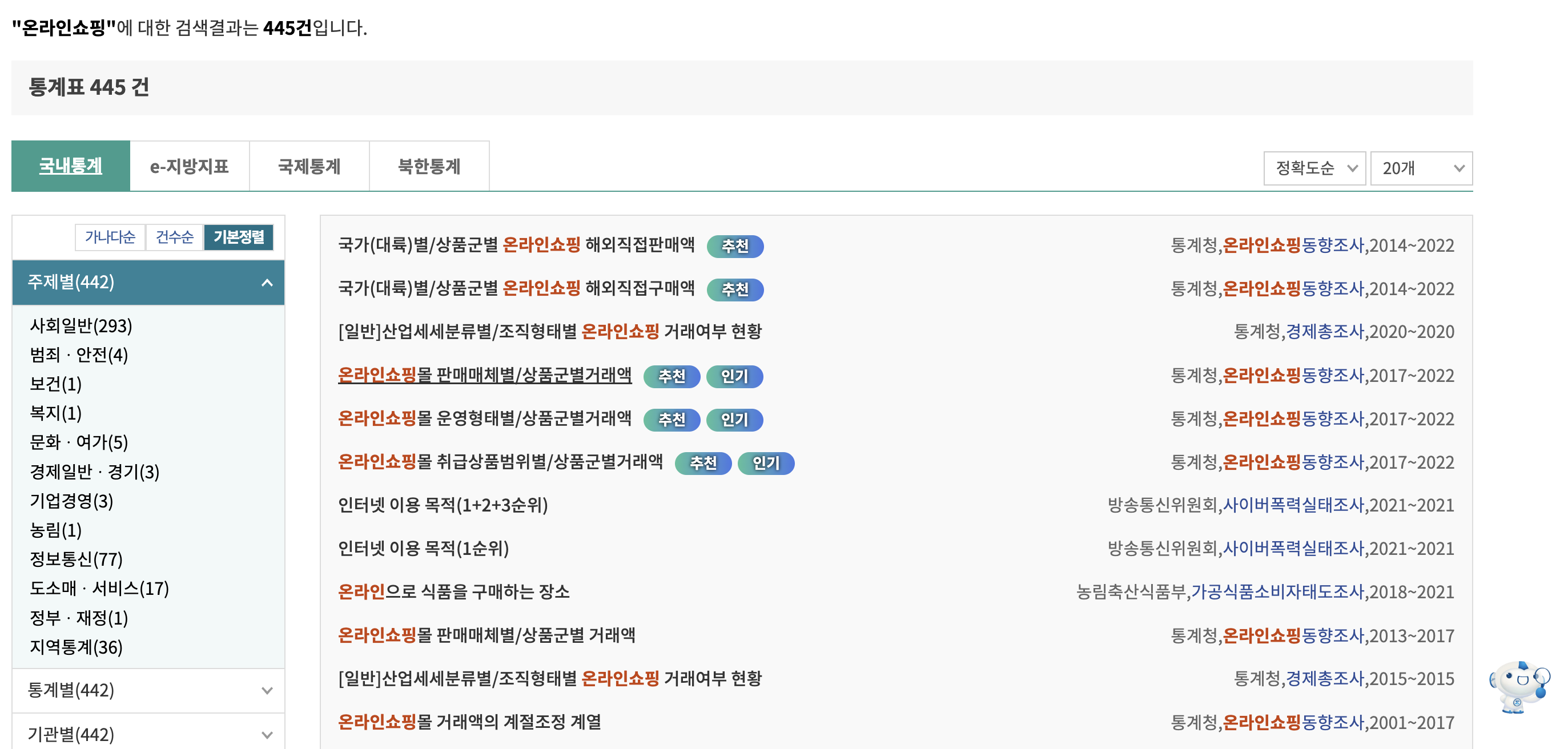
그리고 온라인 쇼핑을 검색한 후 온라인쇼핑몰 판매매체별/상품군거래액을 클릭한다.
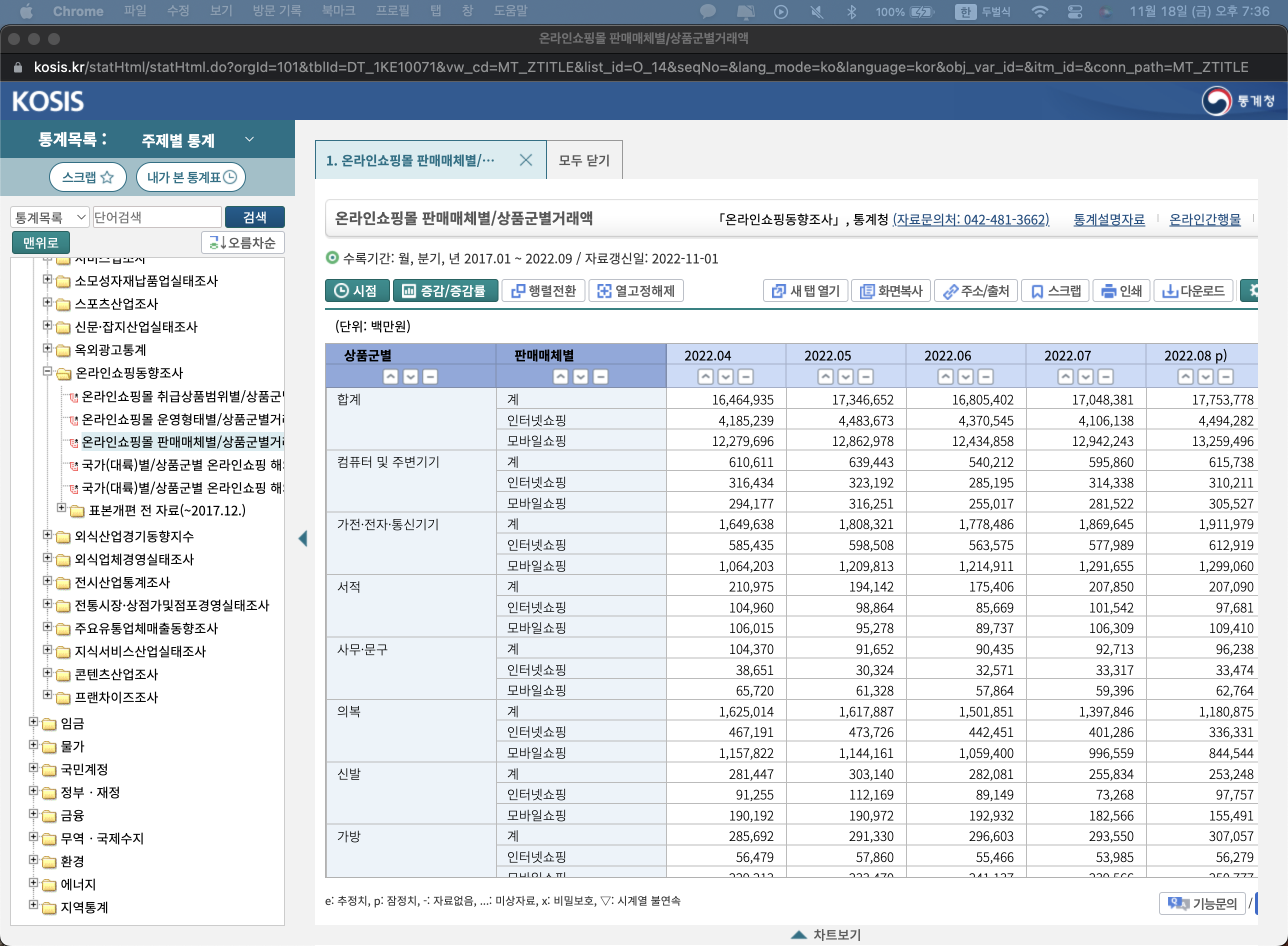
그러면 위와 같은 화면이 뜨는데
나는 맨 처음 데이터를 그대로 내려받는 실수를 범했다.
그랬더니 Python에서 Pandas로도 Tableau로도 쓸 수 없는 데이터가 되어버렸다...
정확히 얘기하자면 굉장히 쓰기 힘든 데이터로 변했다.
날짜가 행에 오고 거래액이 열로 와야 시계열적으로 좀 더 수월하게 분석할 수 있기 때문이다.
이럴 때는 당황하지말고 증감 / 증감률 옆에 있는 행렬전환을 눌러주자.
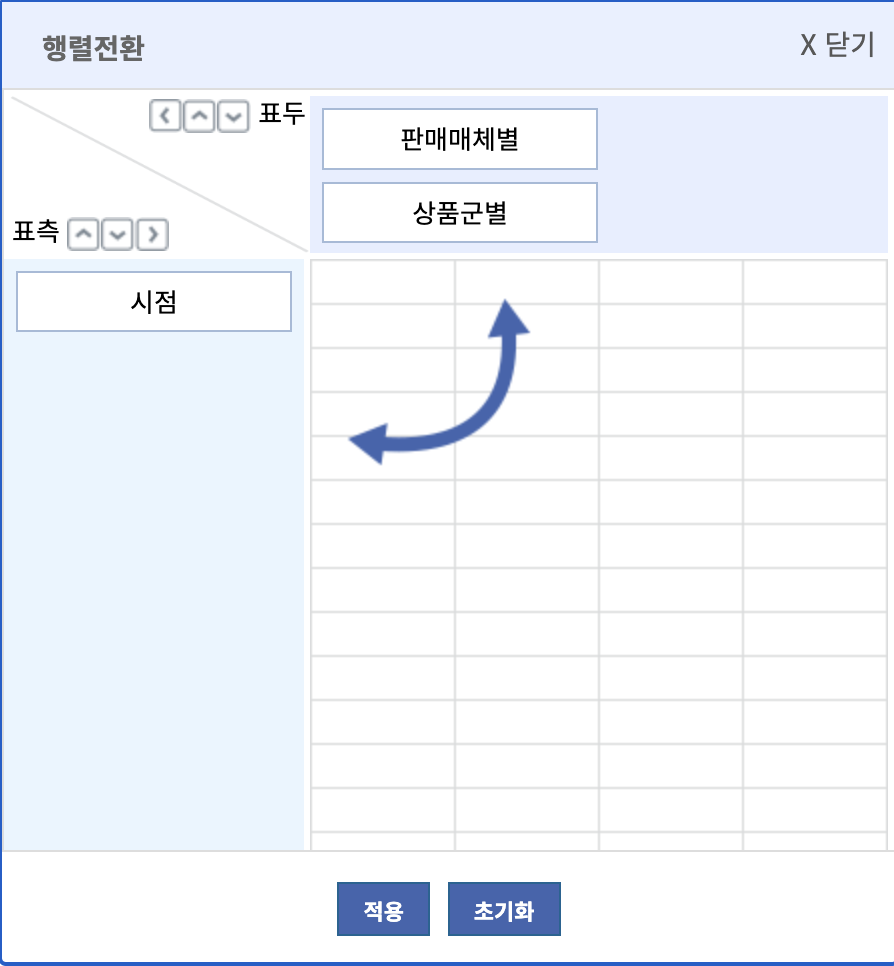
행렬전환을 누르면 다음과 같은 화면이 뜨는데 본인이 원하는데로 행과 열을 지정하여 저장할 수 있다!
(이것이 바로 K-정부...?)
따라서 바로 위와 같이 변경해주고 적용을 누르면
Python이나 다른 플랫폼에서 변경할 필요 없이 아름답게 변환된다.
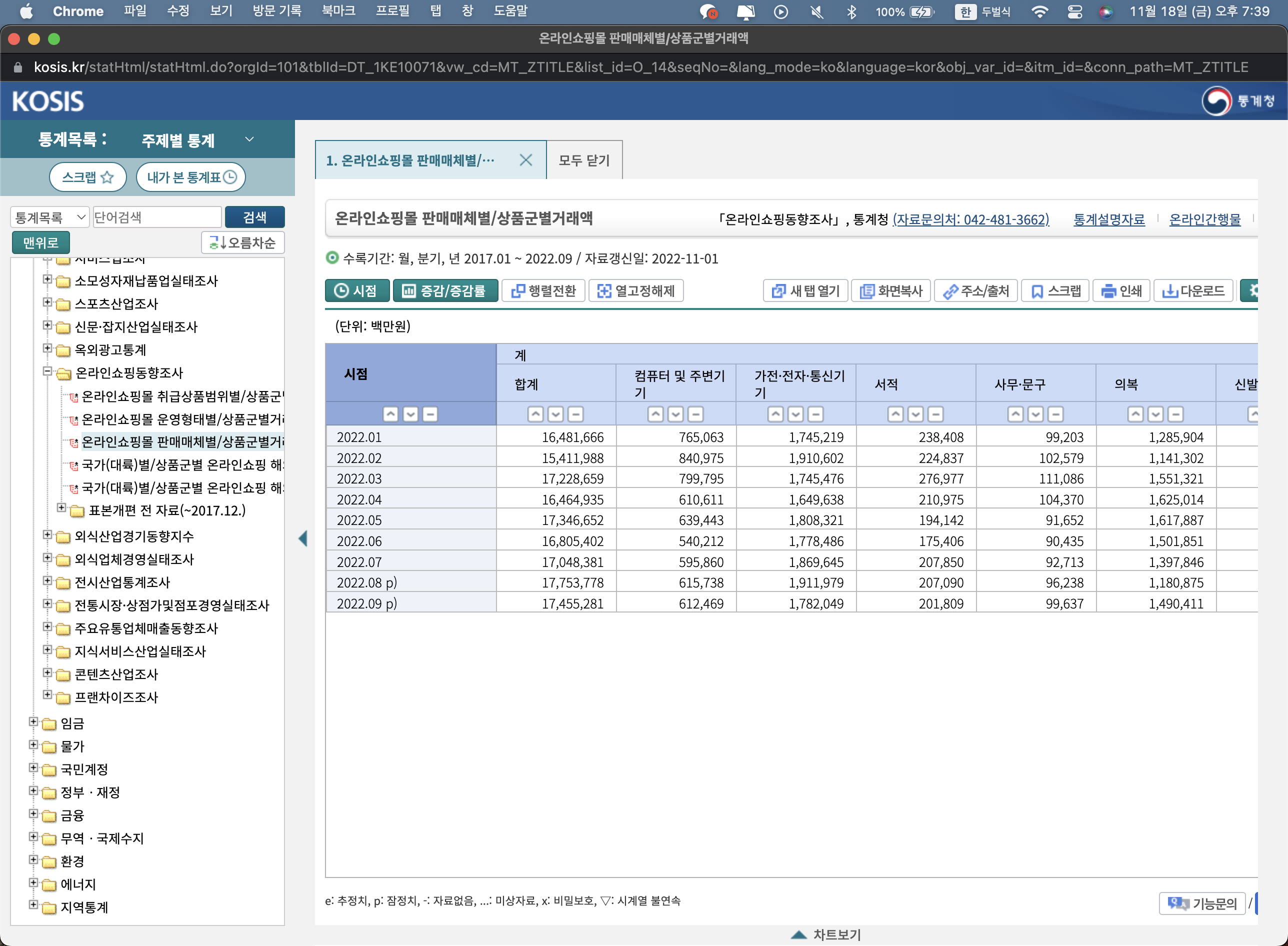
이제 엑셀 파일(.xlsx)로 다운받고 Jupyter Notebook을 켜보도록 하자.
💻 여기서 잠깐! (맥북러들을 위한 Tip)
필자는 맥북을 사용하고 Homebrew를 통해 Jupyter Notebook만 다운받았다.
Homebrew로 Jupyter Notebook을 까는 방법은 간단하지만 한번 깔고 다음에
다시 실행하면 갑자기 사라져있는 것을 볼 수 있다.
그때는 역시 우리의 구글 선생님에게 물어보면 된다.
필자의 경우에는 구글에 정확히 'M1 맥북 주피터 계속 삭제'로 치니까
바로 해결 방법이 나왔다.
여기서 말하고자하는 것은 2가지이다.
-
구글은 선생님이다.
정말 왠만한건 구글에 다 나온다.
뭔가 잘 안된다면 구글에 한글이던 영문이던 일단 검색해보자. -
맥북을 데이터 분석용으로 구매했는데 여기서부터 막히면 정말 짜증나지 않겠는가??
그런 사태를 미연에 방지하고자 필자의 Tip을 통해 해결할 수 있었으면 좋겠는 바람이다.
3-2. Data Preprocessing(데이터 전처리)
드디어 대망의 전처리 시간이다.
Pandas는 언제나 골때리는게 엑셀로 아름답게 불러와도 항상 어딘가 망가뜨리는 재주가 있다.
일단 두근두근?거리는 마음으로 차근차근 시작해보자.
먼저 필수 라이브러리 4종을 불러온다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns나중에는 각종 라이브러리의 특징과 쓰임새를 데린이의 눈으로 설명해보는 시간도 가져볼까 한다.
Anyway
그 이후 맥북의 고질적인 문제점인 Matplotlib 그래프의 한글 패치를 해결해주는 코드를 불러온다.
윈도우를 사용하시는 분들은 역시 구글에서 찾아보시길 바란다.(진짜 잘나온다.)
from matplotlib import rc
import seaborn as sns
%matplotlib inline
rc('font', family='AppleGothic')
plt.rcParams['axes.unicode_minus'] = False그 다음 다운받은 파일을 불러온다.
# sheetname = 0을 붙힌 이유는 뒤에 서술하겠다.
df1 = pd.read_excel('/Users/sung/Desktop/개인 프로젝트/온라인쇼핑몰_판매매체별_상품군별거래액_v3(22.11.13).xlsx', sheet_name = 0)
# 금액 단위는 백만원
df1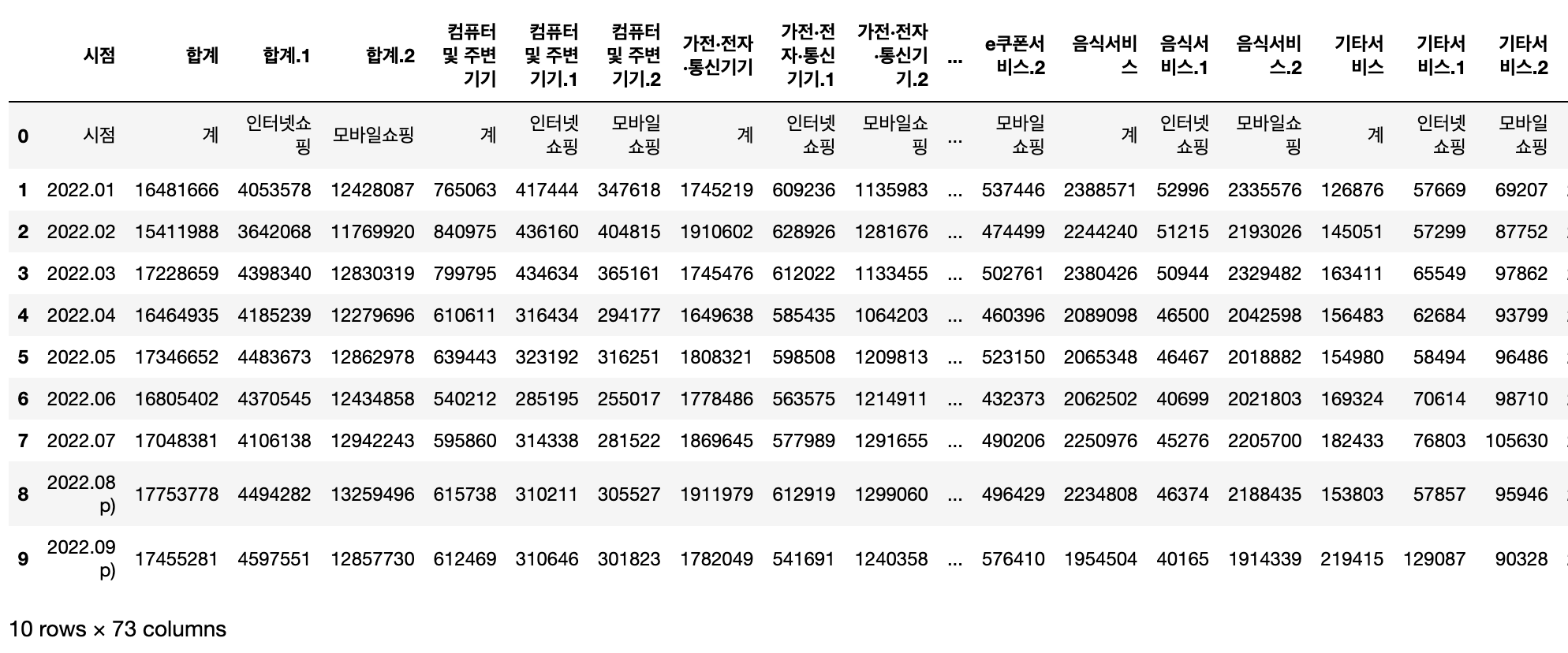
이렇게 불러오고 나니 뭔가가 이상하다.
바로 0번 Row에 '계, 인터넷 쇼핑, 모바일 쇼핑'이 들어가 있는 것이엿다.

정말 이 nom의 Pandas는 방심을 할 수 없다 ㅎㅎㅎㅎ
하지만 이게 매력이니까...
Job소리는 여기서 마치고 이것을 해결해야하는데 column명까지 다 바꾸기에는
column이 73개라 도저히 바꿀 엄두가 안났다.
따라서 필자는 편하게 인덱싱으로 맨 앞의 Row를 없애기로 했다.
df1 = df1[1:]그리고 나서 df1의 info를 찍어보았다.
df1.info()
>>>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 9 entries, 1 to 9
Data columns (total 73 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 시점 9 non-null object
1 합계 9 non-null object
2 합계.1 9 non-null object
3 합계.2 9 non-null object
4 컴퓨터 및 주변기기 9 non-null object
5 컴퓨터 및 주변기기.1 9 non-null object
6 컴퓨터 및 주변기기.2 9 non-null object
7 가전·전자·통신기기 9 non-null object
8 가전·전자·통신기기.1 9 non-null object
9 가전·전자·통신기기.2 9 non-null object
10 서적 9 non-null object
11 서적.1 9 non-null object
12 서적.2 9 non-null object
13 사무·문구 9 non-null object
14 사무·문구.1 9 non-null object
15 사무·문구.2 9 non-null object
16 의복 9 non-null object
17 의복.1 9 non-null object
18 의복.2 9 non-null object
19 신발 9 non-null object
20 신발.1 9 non-null object
21 신발.2 9 non-null object
22 가방 9 non-null object
23 가방.1 9 non-null object
24 가방.2 9 non-null object
25 패션용품 및 액세서리 9 non-null object
26 패션용품 및 액세서리.1 9 non-null object
27 패션용품 및 액세서리.2 9 non-null object
28 스포츠·레저용품 9 non-null object
29 스포츠·레저용품.1 9 non-null object
30 스포츠·레저용품.2 9 non-null object
31 화장품 9 non-null object
32 화장품.1 9 non-null object
33 화장품.2 9 non-null object
34 아동·유아용품 9 non-null object
35 아동·유아용품.1 9 non-null object
36 아동·유아용품.2 9 non-null object
37 음·식료품 9 non-null object
38 음·식료품.1 9 non-null object
39 음·식료품.2 9 non-null object
40 농축수산물 9 non-null object
41 농축수산물.1 9 non-null object
42 농축수산물.2 9 non-null object
43 생활용품 9 non-null object
44 생활용품.1 9 non-null object
45 생활용품.2 9 non-null object
46 자동차 및 자동차용품 9 non-null object
47 자동차 및 자동차용품.1 9 non-null object
48 자동차 및 자동차용품.2 9 non-null object
49 가구 9 non-null object
50 가구.1 9 non-null object
51 가구.2 9 non-null object
52 애완용품 9 non-null object
53 애완용품.1 9 non-null object
54 애완용품.2 9 non-null object
55 여행 및 교통서비스 9 non-null object
56 여행 및 교통서비스.1 9 non-null object
57 여행 및 교통서비스.2 9 non-null object
58 문화 및 레저서비스 9 non-null object
59 문화 및 레저서비스.1 9 non-null object
60 문화 및 레저서비스.2 9 non-null object
61 e쿠폰서비스 9 non-null object
62 e쿠폰서비스.1 9 non-null object
63 e쿠폰서비스.2 9 non-null object
64 음식서비스 9 non-null object
65 음식서비스.1 9 non-null object
66 음식서비스.2 9 non-null object
67 기타서비스 9 non-null object
68 기타서비스.1 9 non-null object
69 기타서비스.2 9 non-null object
70 기타 9 non-null object
71 기타.1 9 non-null object
72 기타.2 9 non-null object
dtypes: object(73)
memory usage: 5.3+ KB아주 알흠답게 0번 로우만 없어진 것을 볼 수 있다.
여기서 주의할 것은
- 아무것도 없는 컬럼명은 거래액 총계
- 컬럼명.1은 인터넷 쇼핑 거래액
- 컬럼명.2는 모바일 쇼핑 거래액
을 의미한다는 것이다.
여기까지 진행했으면 이런 분석에 필요한 날짜를 'datetime'형식으로 변환해주는 것이 필요하다.
datetime과의 사투
위에 info를 보면 분석에 가장 필요한 시점이 object 즉, string으로 되어있는 것을 볼 수 있다.
따라서 바로 ['시점']의 값을 pd.to_datetime 으로 변환시키려하였더니 변환되지 않았다...
무수한 갈고리들이 띄워진채 df1['시점']을 확인해보니...
df1['시점']
>>>
1 2022.01
2 2022.02
3 2022.03
4 2022.04
5 2022.05
6 2022.06
7 2022.07
8 2022.08 p)
9 2022.09 p)
Name: 시점, dtype: object8월과 9월에 p) 즉, 예측치라는 문자가 들어가 있었다!
또한 .으로 날짜가 나누어져있어서 이왕 값들을 고치는 김에
그것 또한 같이 수정해주기로 하였다.
# 8월과 9월은 추정치
df1['시점'] = ['2022-01', '2022-02', '2022-03', '2022-04', '2022-05', '2022-06', '2022-07', '2022-08', '2022-09']
df1['시점'] = pd.to_datetime(df1['시점'])
df1.head()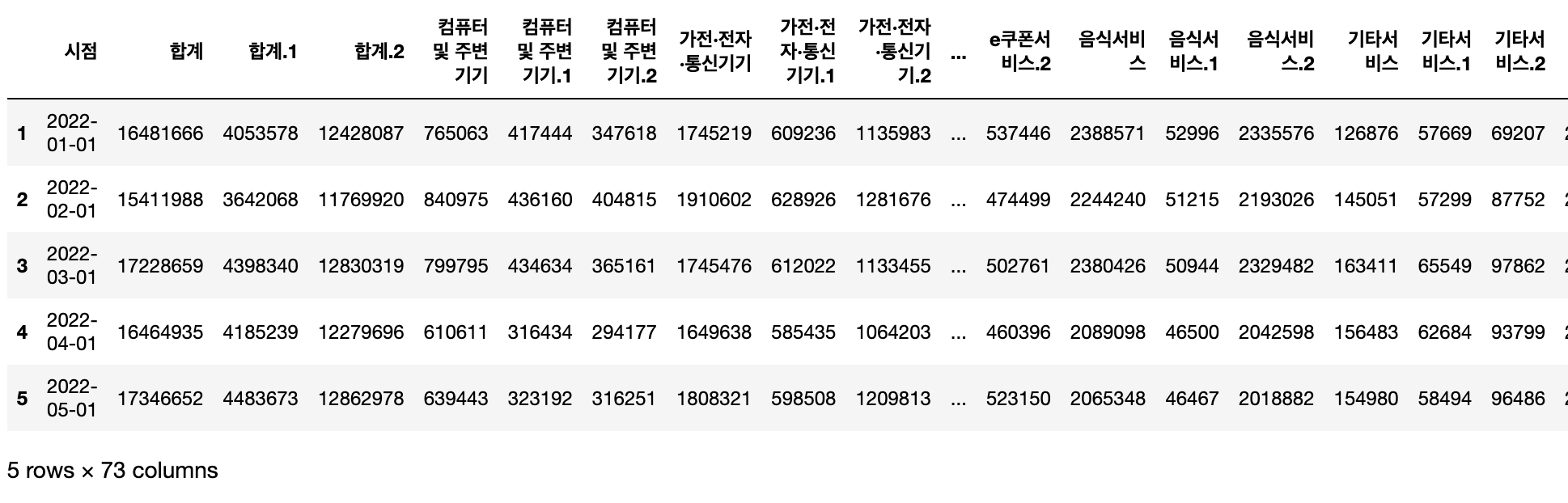
이렇게 시점이 datetime형식으로 바뀐 것을 볼 수 있었다!
여기서 월별로 좀 더 깔끔하게 나타내기 위해 df1['시점']에서 dt.month로 월을 추출해주었다.
이후 df1.columns로 월이 잘 생성되었는지 확인해준다.
df1.columns
>>>
Index(['시점', '합계', '합계.1', '합계.2', '컴퓨터 및 주변기기', '컴퓨터 및 주변기기.1',
'컴퓨터 및 주변기기.2', '가전·전자·통신기기', '가전·전자·통신기기.1', '가전·전자·통신기기.2', '서적',
'서적.1', '서적.2', '사무·문구', '사무·문구.1', '사무·문구.2', '의복', '의복.1', '의복.2',
'신발', '신발.1', '신발.2', '가방', '가방.1', '가방.2', '패션용품 및 액세서리',
'패션용품 및 액세서리.1', '패션용품 및 액세서리.2', '스포츠·레저용품', '스포츠·레저용품.1',
'스포츠·레저용품.2', '화장품', '화장품.1', '화장품.2', '아동·유아용품', '아동·유아용품.1',
'아동·유아용품.2', '음·식료품', '음·식료품.1', '음·식료품.2', '농축수산물', '농축수산물.1',
'농축수산물.2', '생활용품', '생활용품.1', '생활용품.2', '자동차 및 자동차용품', '자동차 및 자동차용품.1',
'자동차 및 자동차용품.2', '가구', '가구.1', '가구.2', '애완용품', '애완용품.1', '애완용품.2',
'여행 및 교통서비스', '여행 및 교통서비스.1', '여행 및 교통서비스.2', '문화 및 레저서비스',
'문화 및 레저서비스.1', '문화 및 레저서비스.2', 'e쿠폰서비스', 'e쿠폰서비스.1', 'e쿠폰서비스.2',
'음식서비스', '음식서비스.1', '음식서비스.2', '기타서비스', '기타서비스.1', '기타서비스.2', '기타',
'기타.1', '기타.2', '월'],
dtype='object')
# '월' column이 생성된 것을 확인!자 이제부터는 본격적인 분석을 할 차례이다.
필자는 원래 Seaborn으로 그래프를 그리려하였으나 다음 챕터에서 서술할 방법 때문에 Matplotlib을 사용하여 그래프를 그렸다.
본격적인 분석 내용은 다음 시간에 계속...
