📧 Duplicate Emails
Table: Person
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| email | varchar |
+-------------+---------+
id is the primary key column for this table.
Each row of this table contains an email. The emails will not contain uppercase letters.
Write an SQL query to report all the duplicate emails.
Return the result table in any order.
The query result format is in the following example.
Example 1:
Input:
Person table:
+----+---------+
| id | email |
+----+---------+
| 1 | a@b.com |
| 2 | c@d.com |
| 3 | a@b.com |
+----+---------+
Output:
+---------+
| Email |
+---------+
| a@b.com |
+---------+
Explanation: a@b.com is repeated two times.✅ 해답
여기서는
한 개의 Person 테이블에서 중복된 이메일 값을 반환하면 쿼리를 작성하면 된다.
뭔가 쉬워보이지만 사실 지금까지 우리는 중복제거한 값을 주로 찾았고 DISTINCT를 이용했다.
하지만 이번에는 카운팅을 중복된 값을 찾은 뒤 그 값을 반환해야하므로 조금 까다로울 수 있다.
이번에도 두 가지의 해답을 소개해보겠다.
하나는 HAVING을 이용하여 조건절을 이용하는 것이고
하나는 SELF JOIN을 이용하여 찾는 것이다.
1. HAVING
# email 값을 반환하는데
SELECT email FROM PERSON
# email으로 그룹핑해준 것에서
GROUP BY email
# email 카운트의 개수가 1 이상인 값을 가져온다.
HAVING COUNT(email) > 1;일단 위의 쿼리 두 줄만 실행한다면 a@b.com 과 c@d.com만 반환될 것이다.
그리고 그룹핑한 결과에 조건을 주기 위하여 email 카운트가 1 이상이라는
조건을 부여해주면 GROUP BY한 결과와는 다르게 a@b.com은 값이 2개 이므로
중복값으로 판단되어 a@b.com값만 반환되게 된다.
2. SELF JOIN
# Person 테이블끼리 SELF JOIN을 하는데 중복제거한 email을 반환한다.
SELECT DISTINCT(A.email) FROM Person A, Person B
# 각 SELF JOIN된 ID가 서로 다른 것과 EMAIL이 서로 같은 것을 반환한다.
WHERE A.id != B.id AND A.email = B.email;이것은 쿼리로만 보기에 이해가 잘 안될 수 있으므로
위의 쿼리들을 MySQL에서 실행해보았다.
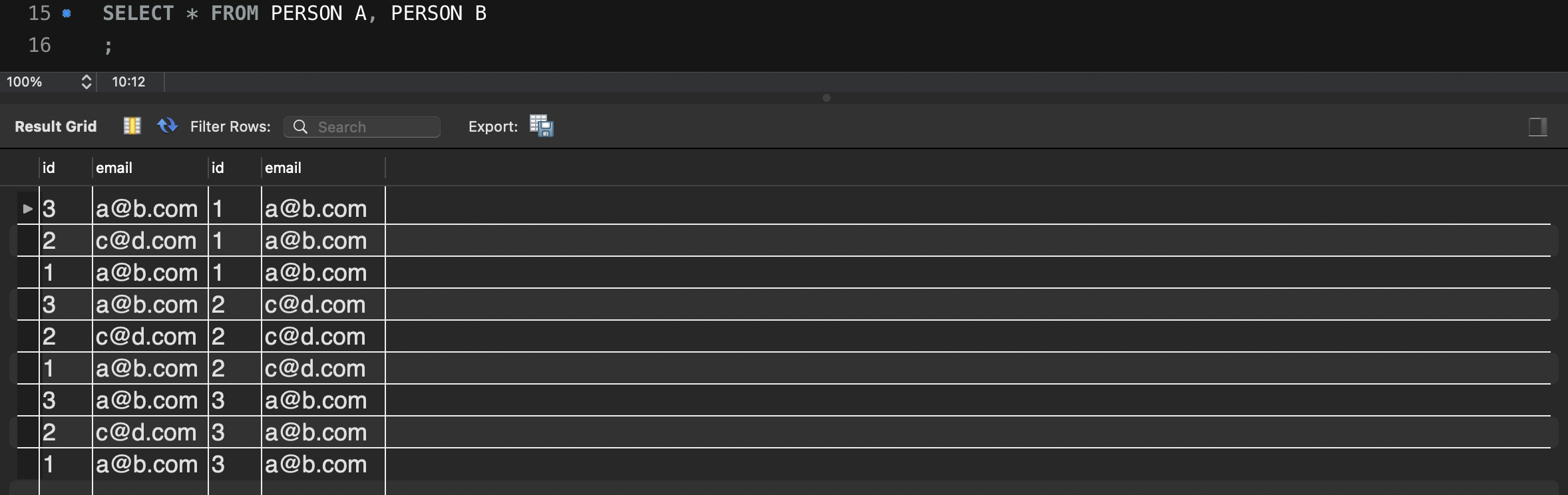
SELF JOIN에서 모든 값을 반환한 결과이다.
여기서 각 id가 다르고 각 email이 값이 같은 것을 반환하면
결과의 맨 첫줄과 밑줄의 결과만 남아 a@b.com이 반환된다.
🎬 Actors and Directors Who Cooperated At Least Three Times
Table: ActorDirector
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| actor_id | int |
| director_id | int |
| timestamp | int |
+-------------+---------+
timestamp is the primary key column for this table.
Write a SQL query for a report that provides the pairs (actor_id, director_id) where the actor has cooperated with the director at least three times.
Return the result table in any order.
The query result format is in the following example.
Example 1:
Input:
ActorDirector table:
+-------------+-------------+-------------+
| actor_id | director_id | timestamp |
+-------------+-------------+-------------+
| 1 | 1 | 0 |
| 1 | 1 | 1 |
| 1 | 1 | 2 |
| 1 | 2 | 3 |
| 1 | 2 | 4 |
| 2 | 1 | 5 |
| 2 | 1 | 6 |
+-------------+-------------+-------------+
Output:
+-------------+-------------+
| actor_id | director_id |
+-------------+-------------+
| 1 | 1 |
+-------------+-------------+
Explanation: The only pair is (1, 1) where they cooperated exactly 3 times.✅ 해답
여기서는
actor_id와 director_id를 쌍으로 그룹핑하였을 때
적어도 3번 이상 같이 일한 actor_id & director_id를 반환하는 쿼리를 작성하면 된다.
그룹핑을 한 것에서 조건을 걸어줘야하기때문에 이 역시 HAVING을 사용하여
쿼리를 작성한다.
SELECT actor_id, director_id FROM ActorDirector
GROUP BY actor_id, director_id
HAVING COUNT(1) >= 3;🏦 Bank Account Summary II
Table: Users
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| account | int |
| name | varchar |
+--------------+---------+
account is the primary key for this table.
Each row of this table contains the account number of each user in the bank.
There will be no two users having the same name in the table.
Table: Transactions
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| trans_id | int |
| account | int |
| amount | int |
| transacted_on | date |
+---------------+---------+
trans_id is the primary key for this table.
Each row of this table contains all changes made to all accounts.
amount is positive if the user received money and negative if they transferred money.
All accounts start with a balance of 0.
Write an SQL query to report the name and balance of users with a balance higher than 10000. The balance of an account is equal to the sum of the amounts of all transactions involving that account.
Return the result table in any order.
The query result format is in the following example.
Example 1:
Input:
Users table:
+------------+--------------+
| account | name |
+------------+--------------+
| 900001 | Alice |
| 900002 | Bob |
| 900003 | Charlie |
+------------+--------------+
Transactions table:
+------------+------------+------------+---------------+
| trans_id | account | amount | transacted_on |
+------------+------------+------------+---------------+
| 1 | 900001 | 7000 | 2020-08-01 |
| 2 | 900001 | 7000 | 2020-09-01 |
| 3 | 900001 | -3000 | 2020-09-02 |
| 4 | 900002 | 1000 | 2020-09-12 |
| 5 | 900003 | 6000 | 2020-08-07 |
| 6 | 900003 | 6000 | 2020-09-07 |
| 7 | 900003 | -4000 | 2020-09-11 |
+------------+------------+------------+---------------+
Output:
+------------+------------+
| name | balance |
+------------+------------+
| Alice | 11000 |
+------------+------------+
Explanation:
Alice's balance is (7000 + 7000 - 3000) = 11000.
Bob's balance is 1000.
Charlie's balance is (6000 + 6000 - 4000) = 8000.✅ 해답
여기서는
계좌에 만원 이상 가지고 있는 사람의 이름과 계좌 잔액을 반환하는 쿼리를 작성 하면 된다.
하지만 2개의 테이블에 나누어져 있으므로 먼저 두 테이블을 JOIN해야하는데
account를 기준으로 JOIN해준다.
그 뒤 account별로 그룹핑 해주어 account별로 한번에 묶은 후 그것들의 amount를 다 더해주고
HAVING을 통해 10000원 이상의 조건을 더해주면서 쿼리를 작성해주면 된다.
SELECT a.name, SUM(b.amount) AS balance FROM Users a
LEFT JOIN Transactions b
ON a.account = b.account
GROUP BY a.account
HAVING balance > 10000;📈 Sales Analysis III
Table: Product
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| product_id | int |
| product_name | varchar |
| unit_price | int |
+--------------+---------+
product_id is the primary key of this table.
Each row of this table indicates the name and the price of each product.
Table: Sales
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| seller_id | int |
| product_id | int |
| buyer_id | int |
| sale_date | date |
| quantity | int |
| price | int |
+-------------+---------+
This table has no primary key, it can have repeated rows.
product_id is a foreign key to the Product table.
Each row of this table contains some information about one sale.
Write an SQL query that reports the products that were only sold in the first quarter of 2019.
That is, between 2019-01-01 and 2019-03-31 inclusive.
Return the result table in any order.
The query result format is in the following example.
Example 1:
Input:
Product table:
+------------+--------------+------------+
| product_id | product_name | unit_price |
+------------+--------------+------------+
| 1 | S8 | 1000 |
| 2 | G4 | 800 |
| 3 | iPhone | 1400 |
+------------+--------------+------------+
Sales table:
+-----------+------------+----------+------------+----------+-------+
| seller_id | product_id | buyer_id | sale_date | quantity | price |
+-----------+------------+----------+------------+----------+-------+
| 1 | 1 | 1 | 2019-01-21 | 2 | 2000 |
| 1 | 2 | 2 | 2019-02-17 | 1 | 800 |
| 2 | 2 | 3 | 2019-06-02 | 1 | 800 |
| 3 | 3 | 4 | 2019-05-13 | 2 | 2800 |
+-----------+------------+----------+------------+----------+-------+
Output:
+-------------+--------------+
| product_id | product_name |
+-------------+--------------+
| 1 | S8 |
+-------------+--------------+
Explanation:
The product with id 1 was only sold in the spring of 2019.
The product with id 2 was sold in the spring of 2019 but was also sold after the spring of 2019.
The product with id 3 was sold after spring 2019.
We return only product 1 as it is the product that was only sold in the spring of 2019.✅ 해답
여기서는
2019년 1분기 즉, 2019년 1월 1일부터 3월 31일까지 팔린 제품의
product_id와 product_name을 반환하는 쿼리를 작성하면 된다.
여기서도 테이블이 2개로 나누어져있기 때문에 두 개의 테이블을 JOIN하고
product_id를 기준으로 한다.
그 다음 product_id로 그룹핑해야 product_id별로 얼마나 팔렸는지 개수를 셀 수 있으며
그것 중에 sale_date가 1분기인 것을 HAVING을 통해 조건을 걸어주면 된다.
SELECT a.product_id, a.product_name FROM Product a
LEFT JOIN Sales b
ON a.product_id = b.product_id
GROUP BY a.product_id
HAVING MIN(b.sale_date) > '2019-01-01' AND MAX(b.sale_date) < '2019-03-31';이렇게 Leetcode 무료 SQL 코딩 포스팅이 끝나게 되었다.
다음에는 Hackerrank의 문제들이나 다시 Python으로 하는 데이터 분석을 해보도록 하겠다.
