❓Employees With Missing Information
Table: Employees
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| employee_id | int |
| name | varchar |
+-------------+---------+
employee_id is the primary key for this table.
Each row of this table indicates the name of the employee whose ID is employee_id.
Table: Salaries
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| employee_id | int |
| salary | int |
+-------------+---------+
employee_id is the primary key for this table.
Each row of this table indicates the salary of the employee whose ID is employee_id.
Write an SQL query to report the IDs of all the employees with missing information. The information of an employee is missing if:
- The employee's name is missing, or
- The employee's salary is missing.
Return the result table ordered by employee_id in ascending order.
The query result format is in the following example.
Example 1:
Input:
Employees table:
+-------------+----------+
| employee_id | name |
+-------------+----------+
| 2 | Crew |
| 4 | Haven |
| 5 | Kristian |
+-------------+----------+
Salaries table:
+-------------+--------+
| employee_id | salary |
+-------------+--------+
| 5 | 76071 |
| 1 | 22517 |
| 4 | 63539 |
+-------------+--------+
Output:
+-------------+
| employee_id |
+-------------+
| 1 |
| 2 |
+-------------+
Explanation:
Employees 1, 2, 4, and 5 are working at this company.
The name of employee 1 is missing.
The salary of employee 2 is missing.✅ 해답
여기서는 employee의 정보가 없는 것을 찾는 것인데 그 중에서도
employee 이름이 빠져있거나 월급이 기록되지 않은 것들을 찾으면 되는 것이다.
일단 조건은 쉬워보이지만 테이블이 2개로 나누어져있고 각각 없는 값을 찾아야 하기 때문에 조금 복잡하게 구해야할 것 같다는 느낌이 든다.
일단 수기로 풀어보자면
Employees 테이블에 있는데 Salaries 테이블에 없는 값과
Salaries 테이블에 있는데 Employees테이블에 없는 값을
찾으면 된다는 것이다.
그리고 MySQL에서는 합집합을 FULL OUTER JOIN으로 지원하지 않고
UNION 으로 합쳐야하기 때문에
NOT IN 구문을 사용하는 것이 가장 베스트인 것 같다.
# Employees 테이블에서 employee_id를 반환하는데
SELECT employee_id FROM Employees
/* Salaries 테이블의 employee_id에서
Employees 테이블의 employee_id가 포함되어 있지 않은 */
WHERE employee_id NOT IN (SELECT employee_id FROM Salaries)
# 위의 값과 밑의 테이블을 합친다.
UNION
# Salaries 테이블에서 employee_id를 반환하는데
SELECT employee_id FROM Salaries
/* Employees 테이블의 employee_id에서
Salaries 테이블의 employee_id가 포함되어 있지 않은 */
WHERE employee_id NOT IN (SELECT employee_id FROM Employees)
# 이 값들을 employee_id로 오름차순 정렬한다.
ORDER BY employee_id;❌ 내가 시도했다가 실패한 쿼리
SELECT a.employee_id FROM Employees a
LEFT JOIN Salaries b
ON a.employee_id = b.employee_id
WHERE a.name IS NULL
OR b.salary IS NULL;JOIN을 사용하여 Employees 테이블과 Salaries 테이블을 조인하여
name과 salary가 null 값인 것을 찾으려 했지만
employee_id = 1이 JOIN되지 않았기 때문에
employee_id = 2만 반환되었다.
📦 Rearrange Products Table
Table: Products
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| product_id | int |
| store1 | int |
| store2 | int |
| store3 | int |
+-------------+---------+
product_id is the primary key for this table.
Each row in this table indicates the product's price in 3 different stores: store1, store2, and store3.
If the product is not available in a store, the price will be null in that store's column.
Write an SQL query to rearrange the Products table so that each row has (product_id, store, price). If a product is not available in a store, do not include a row with that product_id and store combination in the result table.
Return the result table in any order.
The query result format is in the following example.
Example 1:
Input:
Products table:
+------------+--------+--------+--------+
| product_id | store1 | store2 | store3 |
+------------+--------+--------+--------+
| 0 | 95 | 100 | 105 |
| 1 | 70 | null | 80 |
+------------+--------+--------+--------+
Output:
+------------+--------+-------+
| product_id | store | price |
+------------+--------+-------+
| 0 | store1 | 95 |
| 0 | store2 | 100 |
| 0 | store3 | 105 |
| 1 | store1 | 70 |
| 1 | store3 | 80 |
+------------+--------+-------+
Explanation:
Product 0 is available in all three stores with prices 95, 100, and 105 respectively.
Product 1 is available in store1 with price 70 and store3 with price 80. The product is not available in store2.해답
여기서는
기존의 Products 테이블을 Output에 나와있는 테이블처럼 구성하면 되는 것이다.
어떻게 되어있는지 보면 컬럼 부분이 product_id, store, price로 되어있고
GROUP BY는 되어있지 않으며
product_id, store_id, price로 정렬되어있는 듯 하며
본 테이블의 null값이 반환되지 않은 것이 보인다.
따라서 UNION을 통한 테이블 값 재정립에 들어갈 수 밖에 없다.
# product_id, store1 문자열을 store열에 입력하고 store1의 값들을 price열로 이름 붙힌다.
SELECT product_id, 'store1' AS store, store1 AS price FROM Products
# 그중 NULL 값은 포함하지 않아야 한다.
WHERE store1 IS NOT NULL
UNION
# 나머지는 동일하다.
SELECT product_id, 'store2' AS store, store2 AS price FROM Products
WHERE store2 IS NOT NULL
# UNION은 중복값을 제거한다.
UNION
SELECT product_id, 'store3' AS store, store3 AS price FROM Products
WHERE store3 IS NOT NULL
ORDER BY 1, 2;위에서처럼 store1을 문자열로 넣어주면 store1을 2개 반환하게 된다.
이런식으로 storeN 값을 채워준다.
🎋 Tree Node
Table: Tree
+-------------+------+
| Column Name | Type |
+-------------+------+
| id | int |
| p_id | int |
+-------------+------+
id is the primary key column for this table.
Each row of this table contains information about the id of a node and the id of its parent node in a tree.
The given structure is always a valid tree.
Each node in the tree can be one of three types:
- "Leaf": if the node is a leaf node.
- "Root": if the node is the root of the tree.
- "Inner": If the node is neither a leaf node nor a root node.
Write an SQL query to report the type of each node in the tree.
Return the result table ordered by id in ascending order.
The query result format is in the following example.
Example 1:
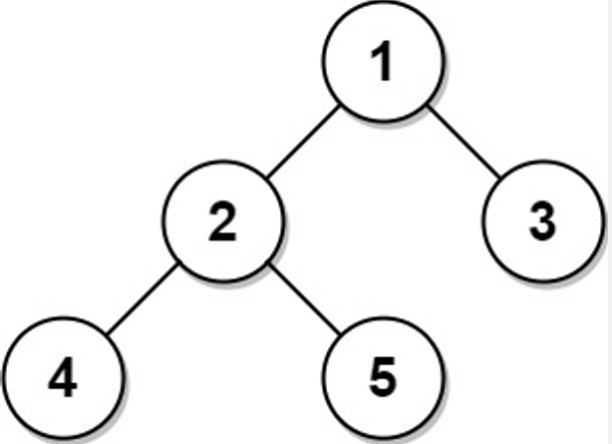
Input:
Tree table:
+----+------+
| id | p_id |
+----+------+
| 1 | null |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 2 |
+----+------+
Output:
+----+-------+
| id | type |
+----+-------+
| 1 | Root |
| 2 | Inner |
| 3 | Leaf |
| 4 | Leaf |
| 5 | Leaf |
+----+-------+
Explanation:
Node 1 is the root node because its parent node is null and it has child nodes 2 and 3.
Node 2 is an inner node because it has parent node 1 and child node 4 and 5.
Nodes 3, 4, and 5 are leaf nodes because they have parent nodes and they do not have child nodes.
Example 2:
Input:
Tree table:
+----+------+
| id | p_id |
+----+------+
| 1 | null |
+----+------+
Output:
+----+-------+
| id | type |
+----+-------+
| 1 | Root |
+----+-------+
Explanation: If there is only one node on the tree, you only need to output its root attributes.✅ 해답
여기서는
Output 테이블에 있는 것처럼 트리 노드 값을 반환해 주면 되는 것이다.
로직만 이해하면 CASE WHEN 구문으로 간단히 구현 가능하다.
단 하나의 문제는, 사진에서 보이는 2와 3이다.
2는 4-5의 Leaf를 가지고 있는 Inner이지만 3은 단순한 Leaf이다.
그리하여 나는 Inner를 규정하는 CASE WHEN 구문에 id가
Tree 테이블의 p_id에 포함되어있는지 안되어있는지를 통해
Inner와 Leaf를 구분하였다.
SELECT id, CASE
WHEN p_id IS NULL THEN 'Root'
WHEN id IN (SELECT p_id FROM Tree) THEN 'Inner'
ELSE 'Leaf'
END AS type
FROM Tree;💶 Second Highest Salary
Table: Employee
+-------------+------+
| Column Name | Type |
+-------------+------+
| id | int |
| salary | int |
+-------------+------+
id is the primary key column for this table.
Each row of this table contains information about the salary of an employee.
Write an SQL query to report the second highest salary from the Employee table. If there is no second highest salary, the query should report null.
The query result format is in the following example.
Example 1:
Input:
Employee table:
+----+--------+
| id | salary |
+----+--------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+----+--------+
Output:
+---------------------+
| SecondHighestSalary |
+---------------------+
| 200 |
+---------------------+
Example 2:
Input:
Employee table:
+----+--------+
| id | salary |
+----+--------+
| 1 | 100 |
+----+--------+
Output:
+---------------------+
| SecondHighestSalary |
+---------------------+
| null |
+---------------------+✅ 해답
여기서는
Employee테이블에서 두번째로 높은 월급을 구하면 되는 것이다.
또한 두번째로 높은 월급이 없다면 null값을 반환해야한다.
# Employee 테이블에서 Salary의 특정 조건을 만족하는 가장 큰 값을 반환한다.
SELECT MAX(Salary) as SecondHighestSalary from Employee
# 조건은 Employee 테이블에서 가장 큰 값보다 작은 값 중에서이다.
WHERE Salary < (SELECT MAX(Salary) FROM Employee);이제 Day 5 문제들을 알아보도록 하자.
