
- NeurIPS 2021
- paper link
Abstract
- 본 논문은 강화학습(RL)을 시퀀스 모델링 문제로 추상화하는 프레임워크를 소개한다.
- 이를 통해 트렌스포머의 단순성과 확장성, 그릐고 GPT-x와 BERT와 같은 언어 모델링의 발전을 활용할 수 있다.
- 이전의 RL이 value function이나 policy gradients를 계산했던 것과는 달리 Decision Transformer는 간단하게 masked Transformer을 활용하여 최적의 Action을 도출한다.
그러니까 이 논문은 기본 RL 프레임워크를 벗어나 Transformer 아키텍처를 활용해 강화학습을 시퀀스 모델링 문제로 재정의한다. 이를 통해 동적 프로그래밍 없이도 정책 학습이 가능하도록 하는데, 이를 Decision Transformer라고 부른다.
Paper
DT가 풀고자 했던 문제는?
- 단순히 모델이나 정책을 학습시키는 것 X
- 강화학습(RL)의 기존 접근 방식들이 가진 고질적인 한계를 극복하려는 데 초점이 있음.
Method

Decision Tranformer는 Transformer 아키텍처에 최소한의 수정만 가하여, trajectory를 auto-regressive 방식으로 모델링하는 구조다.
Trajectory representation
"it is nontrivial to model rewards since we would like the model to generate actions based on future desired returns, rather than past rewards. As a result, instead of modeling the rewards directly, we model the returns-to-go..."
- trajectory 표현 방식을 정할 때 고려한 핵심 요구사항은 두 가지
1. Tranformer가 의미 있는 패턴을 학습할 수 있어야 함
2. 테스트 시점에 조건부 행동 생성을 할 수 있어야 함 - Past reward가 아니라 Future desired return을 모델에 제공함 = 미래의 보상 함수까지 함께 주는 것
- 이에 각 timestep마다 return, state, action이 번갈아 나타나는 시퀀스로 구성된다
[!tip] 조건부 행동 생성
어떤 목표 return(조건)을 제시했을 때, 그 조건에 맞는 행동을 생성하는 것
- 조건이 1.0 : 전문가처럼 정교한 행동
- 조건이 0.3 : 실수하거나 성능 낮은 행동
기존 Behavior Cloning의 경우 상태 를 보고 행동 를 예측한다. 이때 어떤 상황(조건)에서도 항상 똑같은 행동을 출력한다. (= 조건 없이 고정된 행동 생성)
반면 Decision Transformer는 조건이 들어간다. 그 조건이 바로 앞으로 받고 싶은 보상(Return)임! 즉, "return-to-go"가 1.0이면 전문가처럼 행동해줘! 를 조건으로 주는 것
Architecture
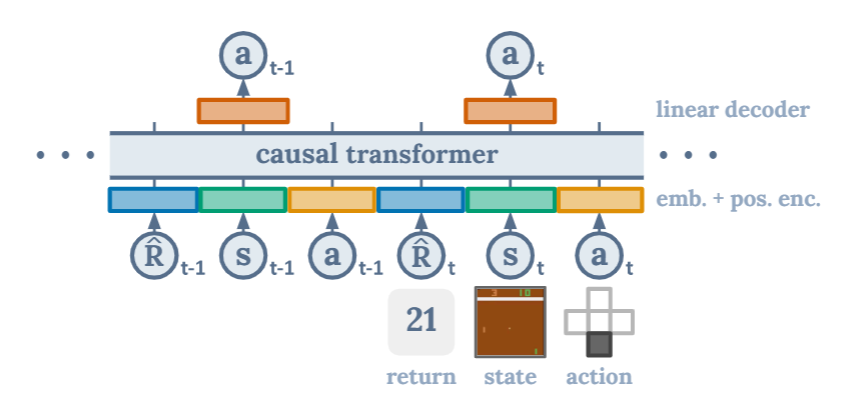
==입력 구조==
먼저 입력 구조를 살펴보자. 입력은 시간 순서대로 다음과 같은 세 가지 요소의 시퀀스로 구성된다.
= 마치 문장을 생성하는 것처럼 "미래 보상(Return)", "상태(State)", "행동(Action)"의 시퀀스를 생성!
- Return-to-go ( ) : 현재 timestep부터 목표로 하는 누적 reward
= 앞으로 얻고 싶은 누적 보상의 합! - State() : 환경의 상태, ex. 게임화면
- Action() : 에이전트가 선택한 행동
그럼 입력은 시간 순서대로 아래처럼 구성된다.
[ Rt-1, St-1, At-1, Rt, St, At, Rt+1, St+1, At+1, ... ]==내부 구성==
- 각 modality는 각각 다른 linear embedding layer를 거쳐 같은 차원으로 맵핑된다.
- 이후 포지셔널 인코딩을 추가하고, 이들을 하나의 시퀀스로 합쳐서 GPT-style causal transformer에 입력한다.
- 이때 마지막 K개의 timestep을 Decision Transformer에 입력하기 때문에 총 3K개의 토큰이 생성된다.
- Transformer는 현재 timestep의 action을 예측하도록 학습된다.
= 각 modality는 각자 다른 방식으로 임베딩되고, 그 결과는 transformer가 요구하는 동일 차원 d로 맵핑된 후, 시퀀스의 한 토큰처럼 독립적으로 입력된다. 이 벡터들은 합쳐지지 않고, 각각의 위치에서 positional embedding이 더해져서 Transformer에 입력된다.
Transformer 내부 구조
- Casual Transformer : GPT와 유사하게, 이전 시점까지만 참조 가능한 구조(unidirecitonal)
- ex.
A_t를 예측할 때는R_t, S_t까지만 참고가 가능함! - 즉, 다음 시점의 정보를 미리 보지 않도록 casual making을 적용
==예측 방식==
- Transformer는 autoregressive 하게 동작함!
- 예를 들어 아래처럼 각 액션을 예측함
입력 : R_t, S_t -> 예측 : A_t- 학습 목표는 실제 행동
A_t을 맞추는 것. 테스트 시에는 예측된 행동을 실제 환경에 적용해 다음 상태로 이동함.
[!tip] autoregressive한 방식
이전 시점까지의 모든 정보를 이용해서 다음 토큰 하나를 순차적으로 예측하는 방식
Training
- 데이터셋에서 길이가 K인 시퀀스 minibatch들을 샘플링
- 입력 토큰 에 대응되는 prediction head는 행동 를 예측하도록 학습되며, 이때 행동이 이산(discrete)일 경우에는
cross-entropy loss, 연속(continuous)일 경우에는mean-squared error를 사용함!
Evaluation Loop
target_return: 앞으로 얻고 싶은 총 보상 목표
- Decision Transformer는 "return-conditioned behavior cloning"모델이다. 즉, "미래에 어떤 return을 받고 싶다고 한다면, 그에 맞는 행동을 모방해줄게."라는 식의 조건부 시퀀스 생성 모델이다.
-target_return=1:env.reset(): 환경을 초기화하고, 시작 상태(state)를 반환
How can we solve the RL Problem by Sequence Prediction method?
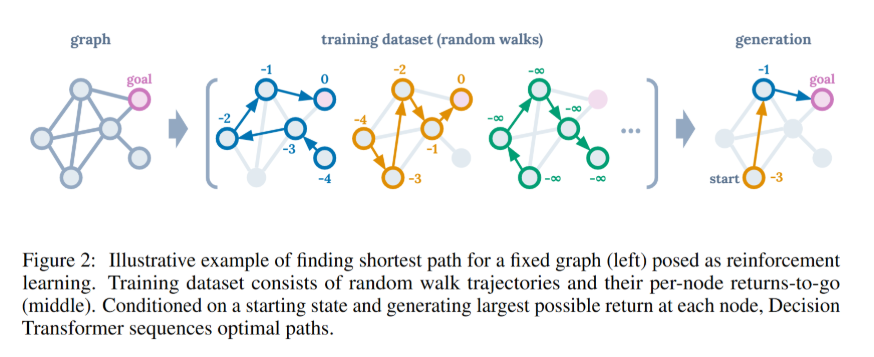
해당 그림은 Decision Transformer가 어떻게 강화학습 문제를 시퀀스 예측 방식으로 풀 수 있는지를 설명하고 있다. 그래프 위에서 최단 경로 찾기 문제를 가지고, random walk trajectory -> 학습 -> 최적 경로 생성 과정을 시각화한 것!
1. Graph
- 어떤 고정된 그래프가 있고 각 노드는 상태(State), 각 간선은 가능한 행동(Action).
- 목표를 goal 노드에 도달하는 것이고 이것은 보상 0으로 표시된다.
- (보통 goal = 보상 max)
2. Training Dataset
- 다양한 Trajectory(무작위 경로들)를 수집해서 학습 데이터로 사용한다.
- 해당 trajectory들은 보통 강화학습처럼 "좋은 행동"이 아니라 random walk처럼 여기저기 돌아다닌 경로다.
- 각 노드에 적힌 숫자 = 그 노드에서 시작했을 떄 얻을 수 있는 Return-to-Go
- ex. 목표 지점이 보상 0이라면, 한 노드에서 거기까지 가기 위해 누적된 보상으 음수임! - ==핵심== : 잘못된 trajectory도 모두 학습에 활용된다는 것!
3. Generation
- 이제 1) 새로운 상황에서 start 노드를 주고, 2) 목표 보상(return=0)을 설정한 다음, 3) DT에게 "어떻게 갈까?"라고 물어봄
- 그럼 DT는 1) 학습한 random walk들을 바탕으로 2) 가장 높은 return을 유지하는 방향으로 행동을 선택해, 3) 결과적으로 최단 경로에 해당하는 시퀀스를 생성한다!
Evaluation
In this section, we investigate if Decision Transformer can perform well compared to standard TD and imitation learning approaches for offline RL.
- TD(Temporal Difference) Learning
- 기존의 전통적인 SOTA 강화학습 기법을 대표함 - Imitation Learning
- 모방 학습 알고리즘은 구조적으로 Decision Transformer와 유사한 점이 많음
- Supervised learning, Behavior Cloning을 사용함
Atari
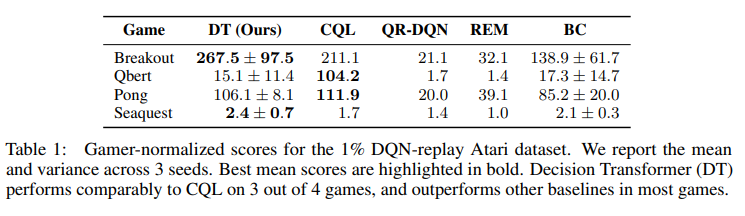
4개의 게임 중 3개에서 CQL과 대두한 성능을 보였으며, 모든 게임에서 더 우수한 성능을 보였음.
여기서는 BC의 성능도 함께 측정하였는데, 해당 모델은 Decision Transformer와 동일한 네트워크 구조와 하이퍼파라미터를 사용하였지만, return-to-go 조건부 입력은 포함하지 않았다.
OpenAI Gym
OpenAI Gym은 강화학습(RL) 실험을 쉽게 할 수 있도록 만든 표준화된 시뮬레이션 환경 모음!
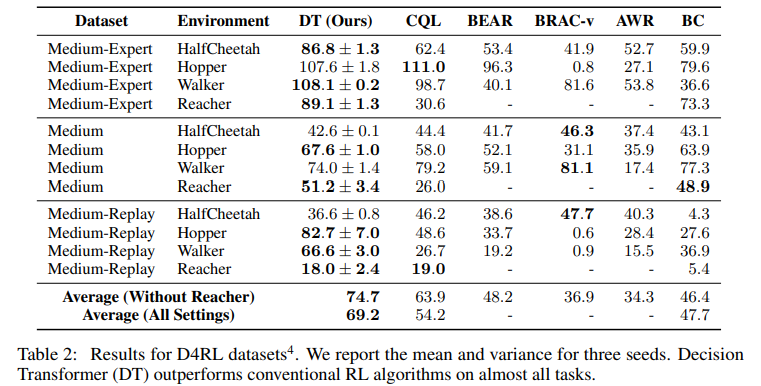
- Medium : 전문가 저책 대비 약 1/3 수준의 점수를 기록하는 중간 수준의 정책이 생성한 100만 개의 타임스텝 데이터
- Medium-Replay : 중간 수준의 성능까지 학습된 에이전트의 replay buffer에 저장된 데이터를 사용하며, 이는 약 2.5만에서 40만 타임스텝 사이의 범위로 구성되어 있음
- Medium-Expert : 중간 정책으로 생성된 100만 개의 데이터와 전문가 정책으로 생성된 100만 개의 데이터를 연결하여 구성된 데이터셋
CQL은 가치 함수에 대한 보수성(value pessimism)을 적용한 TD 학습의 구현체!
DT는 대부분의 태스크에서 최고 성능을 기록하였음.
Discussion
-
강화학습 문제를 시퀀스 모델링으로 해결
- 기존 RL 기법들과는 달리 Decision Transformer는 return-to-go와 함께 과거 상태 및 행동의 시퀀스를 모델링함으로써, RL 문제를 지도 학습(supervised learning) 문제처럼 다룬다.
- 이는 불안정한 value function 추정이나 exploration 관련 복잡성 없이도 학습이 가능하다는 장점이 있음.
- 기존은 RL은 보상이 희소하거나 delayed 될 경우 매우 불안해짐
-
목표 return을 통해 행동을 제어할 수 있는 유연성
- DT는 테스트 시점에 목표 return을 설정함으로써, 더 높은 성능의 행동을 유도하거나, exploration 수준을 조절할 수 있다. ex. 보통 수준의 성과, 최고 성과...
- 이는 goal-conditioned RL로의 확장 가능성을 보여주며, 멀티태스크 설정에서도 유용함.
-
학습 안정성과 일반화 가능성
- DT는 offline dataset에 의존하기 때문에, “보지 못한 경우”에 대해서 extrapolation 능력이 제한될 수 있음. 이건 거의 모든 offline RL의 일반적인 한계임.
- = 트레이닝 데이터에 존재하지 않는 행동이나 상황에 대해서는 성능이 떨어질 수 있음.
-
탐색(exploration)이 불가능한 점
- DT는 offline RL 전용이기 때문에 스스로 환경을 탐색하거나 새로운 데이터를 수집하는 기능이 없다.
- 미래에는 online setting에서 탐색 능력을 추가하는 방향으로 확장할 필요가 있음
-
Sequence modeling이 새로운 paradigm이 될 수 있음
- 이 논문은 RL 문제를 모델링 방식의 전환을 통해 더 단순하게 풀 수 있음을 보여준다.
- 앞으로 다양한 RL 문제나 시뮬레이션 문제에서 시퀀스 모델 기반의 접근이 허용될 수 있을 것이다.
RL vs DT vs Transformer
| 항목 | 전통적인 RL | Decision Transformer (DT) | 일반 Transformer |
|---|---|---|---|
| 🎯 목적 | 최적의 정책(policy) 학습 | trajectory 시퀀스 모방 | 자연어, 이미지 등 시퀀스 모델링 |
| 🧠 학습 방식 | 강화학습 (Value iteration, Policy gradient) | Supervised learning (sequence modeling) | Supervised learning (next token prediction 등) |
| 📊 데이터 | 환경과 실시간 상호작용 (online) | 수집된 trajectory (offline) | 일반 텍스트/이미지/음성 등 |
| ⏳ 시간 처리 | 상태 전이 순서를 내재적으로 모델링 | timestep 기반 시퀀스 + position encoding | position encoding으로 순서 학습 |
| 🔁 순차성 인식 | 정책 함수 또는 RNN 사용 | GPT-style causal Transformer | 다양한 Transformer 아키텍처 사용 (BERT, GPT 등) |
| 🚫 미래 정보 접근 | 구조적으로 불가능 | 구조적으로 가능해서 masking 필요 | causal이면 제한, BERT류는 양방향 가능 |
| 🔄 데이터 생성 | 학습 중 직접 수집 | 수집된 trajectory만 사용 | 텍스트 생성 등 가능 |
| 📦 핵심 구성 | π(s), V(s), Q(s, a), reward, env | R, S, A sequence (Rt, St → At 예측) | 다양한 토큰 (텍스트, 이미지 등) 임베딩 + attention |
| 🧪 적용 분야 | 로봇, 게임, 제어 등 RL 문제 | offline RL, imitation learning | NLP, vision, audio, multi-modal |
