- 참고 자료 : https://m.blog.naver.com/dlwoduq234/223090404339
- 논문에서 진행하고 있는 시뮬레이션을 확인할 수 있는 사이트 URL

- 요약 연구진은 SmallVille라는 가상의 마을 만들었고 그곳에서 25명의 생성형 Agent가 거주하며 생활한다. 시간에 지남에 따라 에이전트들은 각자의 역할에 맞는 생활을 하며 상화작용을 진행했고, 공동된 기억을 만들며 관계를 구축했다. 이 논문에서도 ‘기억’, ‘검색’, 그리고 ‘추론’이 필요하다고 언급함!
#Human-AI interaction #agents #generativeAI #LLM
Abstract & Introduce
2024년 4월, 스탠포드 대학 연구진이 한 논문을 발표했다. RPG 형태의 가상 시뮬레이션 게임에 ChatGPT를 적용시킨 실험과 그 결과에 대해 작성한 논문이었다.
해당 논문은 심즈와 같이 샌드박스 환경에 사람들을 모으는 행동을 통해 25명의 생성형 에이전트의 효력을 증명했다. 유저는 에이전트가 계획을 짜고, 뉴스를 공유하고, 관계를 형성하고, 그룹 활동에 참여하는 등의 행동을 관찰할 수도 있고 개입할 수도 있다.
이 논문에서는 생성형 에이전트가 인간의 행동을 믿을 수 있을 만큼 시뮬레이션할 수 있다고 이야기하고 있으며 이를 증명한다.
그들은 1) 의견을 형성하고 2) 서로를 알아차리고 3) 대화를 시작하고 4) 과거의 일을 기억하고 반영해 다음 날의 계획을 세운다. → 생성형 에이전트들은 굉장히 사실과 유사한 개인적인, 혹은 사회적인 행동을 취했다!
예를 들어 한 사용자가 발렌타인 Day 파티를 열자 다른 에이전트들이 다음 이틀 동안 자율적으로 파티를 퍼트려 데이터를 신청하거나 제 시간에 파티에 참석하는 모습을 보였다.
연구진들은 그들의 에이전트 구성요소인 관찰, 계획, 그리고 반영 중 하나씩 제거하는 절제 실험을 수행했고, 각 요소가 에이전트의 신뢰성 있는 행동에 큰 영향을 준다는 것을 알아냈다.
LLM과 상호작용하는 에이전트를 결합함으로서 이 연구는 신뢰가능한 인간 행동 시뮬레이션을 가능하게 하는 아키텍쳐와 상호작용 패턴을 소개한다는 의의가 있다.
이러한 생성형 에이전트를 가능하게 하기 위해 연구진들은 하나의 에이전트 아키텍처를 설명한다. LLM을 이용해 신뢰 가능한 행동을 만들기 위해 저장하고, 싱크를 맞추고, 최근 기억을 적용하기 위해서는 3가지 구성요소가 필요하다.
하나는 메모리 스트림(Memory stream)으로 에이전트 경험의 상세한 리스트를 long-term memory 모듈에 저장하고 이를 찾아내는 (retrieval) 것이다. 두 번째는 반영(Reflection)으로 시간이 지남에 따라 더 높은 추론을 생성하게 해 에이전트가 자신과 타인에 대한 결론을 도출하고 그에 따라 더 나은 행동을 할 수 있도록 하는 것이다. 마지막으로는 계획(Planning)으로 이러한 결론과 현재 상황을 분석하여 재귀적으로(=순환적으로) 행동 및 반응을 위한 세부 항목으로 세분화한다.
이러한 아키텍쳐는 롤플레잉이나 사회 프로토타입부터 가상 세계나 게임까지 여러 분야에 적용될 수 있다.
요약하자면, 해당 논문은 다음과 같은 기여를 하고 있다고 할 수 있다.
- 생성형 에이전트는 에이전트의 변화하는 경험이나 환경에 동적으로 조건화된 인간 행동으로 믿을 수 있는 시뮬라크라이다
- 생성형 에이전트가 기억하고, 찾고, 반영하고, 다른 사람과 상호작용하고, 동적으로 진화하는 환경에 맞춰 계획을 짤 수 있도록 새로운 아키텍처를 설계하였다. 해당 아키텍처는 LLM의 강력한 프롬프팅 능력을 사용하였고 이러한 능력을 보완하여 장기적인 에이전트의 일관성을 지원하며, 동적으로 변화하는 메모리를 관리하고 더 고차원적인 반영을 재귀적으로 생성하는 능력을 제공한다.
- Controlled(=통제된) 평가와 end-to-end(=종합) 평가 방식을 사용하였다. 이를 통해 아키텍처의 구성요소의 중요성을 입증하였고 부적절한 결과 검색 같은 문제에서 발생하는 결함을 식별했다.
- 에이전트가 상호작용 시스템에서 제공하는 기회와 윤리적 및 사회적 위험에 대해 생각해봐야 한다! 이러한 에이전트가 사용자와 준사회적 관계를 형성하는 위험을 완화해야 한다.
3 Generative Agent Behavior and interaction
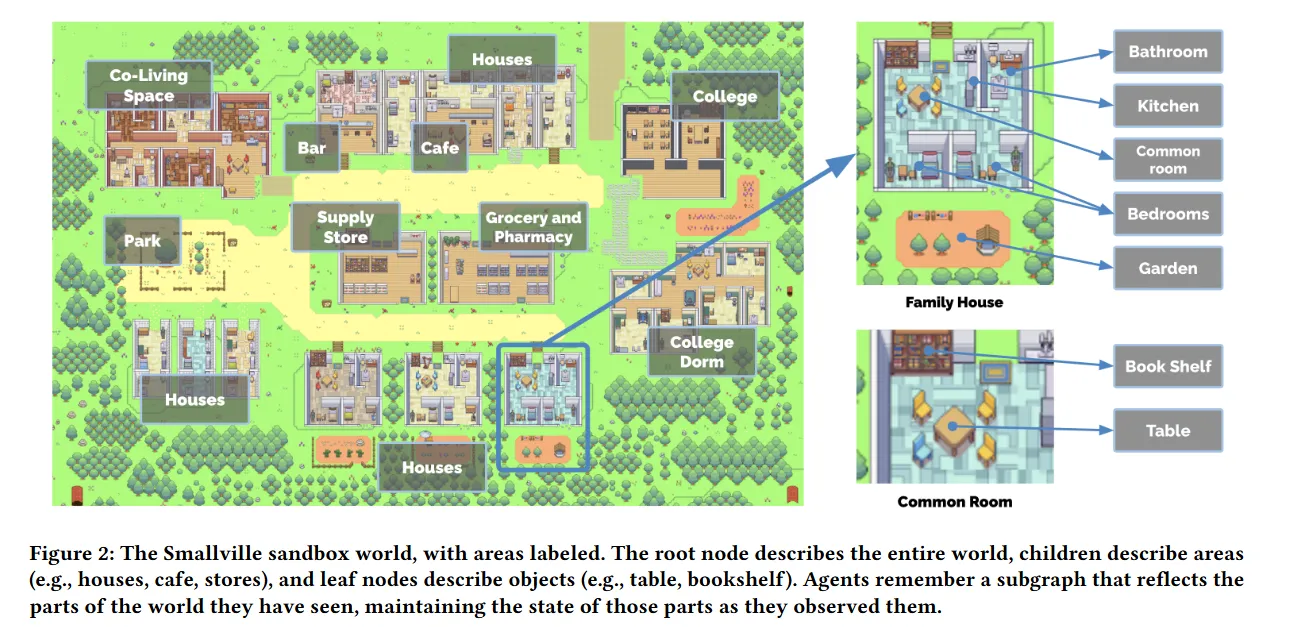
실제로 생성형 에이전트의 사용 가능성을 입증하기 위해 심즈를 연상캐 하는 간단한 샌드박스, Smallville라는 작은 마을 환경을 구축하였다.
3.1 Agent Avatar and Communication
마을 안에는 25명의 에이저트가 살고 있는데 각각의 정체성(환경이나 다른 이들과의 관계, 기본 기억들…)을 묘사하기 위해 자연어 단락을 작성하였다.
John Lin is a pharmacy shopkeeper at the Willow
Market and Pharmacy who loves to help people. He
is always looking for ways to make the process
of getting medication easier for his customers;
John Lin is living with his wife, Mei Lin, who
is a college professor, and son, Eddy Lin, who is
a student studying music theory; John Lin loves
his family very much; John Lin has known the old
couple next-door, Sam Moore and Jennifer Moore,
for a few years; John Lin thinks Sam Moore is a
kind and nice man; John Lin knows his neighbor,
Yuriko Yamamoto, well; John Lin knows of his
neighbors, Tamara Taylor and Carmen Ortiz, but
has not met them before; John Lin and Tom Moreno
are colleagues at The Willows Market and Pharmacy;
John Lin and Tom Moreno are friends and like to
discuss local politics together; John Lin knows
the Moreno family somewhat well — the husband Tom
Moreno and the wife Jane Moreno3.1.1 Inter-Agent Communication
에이전트는 액션을 통해 세상이나 다른 이들과 상호작용한다. 그리고 각 샌드박스 엔진에서 그들은 자신의 현제 상황에 대해 자연어로 출력한다.
ex. “Isabella Rodriguez is writing in her journal”
그리고 이 상태는 실제 움직임으로 나타나 샌드박스 세상에 영향을 준다. 행동은 샌드박스 인터페이스에 이모지 세트로 표시되며, 이는 위에서 본 행동의 추상적인 표현을 제공한다. 이를 실현하기 위해 시스템은 각 아바타의 머리 위해 떠오르는 이모지를 번영하는 언어 모델을 사용한다.
ex. “Isabella Rodriguez is writing in her journal” ⇒ 📖✏️
또한 에이전트들은 다른 이들과 자연어로 대화한다. 그들은 그들의 주위에 다른 에이전트가 오면 인식하고, 그냥 걸어갈지 대화할지 결정한다.
3.1.2 Uer Controls
에이전트에게 ‘내면의 목소리’ 페르소나를 취해 그들에게 지시를 내릴 수 있다.
ex. 샘에게 “당신은 다가오는 선거에 출마할 것입니다.”라고 하면 실제로 샘은 그걸 계획하게 된다
3.2 Environmental Interaction
에이전트는 단순한 비디오 게임처럼 스몰빌을 돌아다니며 건물에 들어가고 나가고, 지도를 탐색하며 다른 에이전트에 접근한다. 더욱이 그들은 사용자 에이전트를 여타 다른 에이전트처럼 대한다.
ex. 사용자가 이사벨라가 욕실에 들어갈 때 그녀의 샤워 상태를 "물이 새고 있음"으로 설정하면, 그녀는 거실에서 도구를 가져와서 새는 부분을 고치려고 함
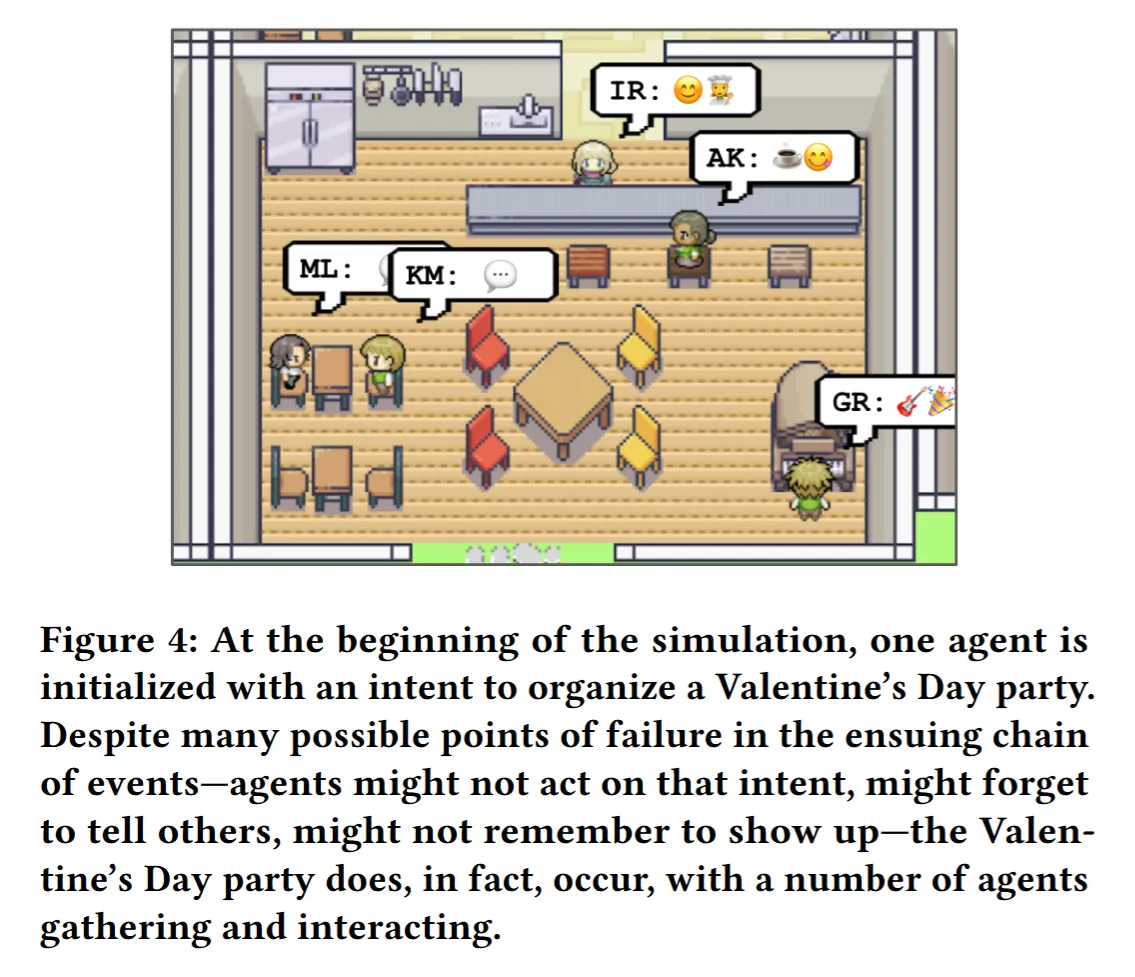
3.4 사회적인 행동 Emergent Social Behaviors
스몰빌에서 에이전트들은 정보를 교환하고 새로운 관계를 형성하고, 공동 활동을 한다. 그리고 이런 사회적인 행동은 인위적으로 프로그래밍을 한 것이 아니라 자연스럽게 발생한 것이다.
3.4.1 정보 확산 Information Diffusion
Sam이 Tom을 만나 자신이 선거에 출마할 것이라고 말하자 → Tom은 다음날 John을 만나서 그 사실을 알렸다. 시간이 지나면서 그의 출마가 화제에 오르며 일부는 그를 지지하고 일부는 결정하지 않았다.
3.4.2 관계 기억? Relationship memory
스몰빌에 있는 에이전트들은 시간이 지남에 따라 서로 관계를 형성하고, 그것을 기억했다.
예를 들어 Sam은 Latoya에 대해 전혀 몰랐으나 한번 Latoya가 자신이 사진 작가이고 프로젝트를 진행중이라고 말하자 이후에 그녀에게 “프로젝트는 잘 돼가?”라고 물어봄
3.4.3 협력 Coordination
에이전트들은 서로 협력하는 모습을 보였다.
예를 들어 이자벨라가 파티를 열면서 마리아에게 도와달라고 하자 마리아는 도와주기 시작함
4 Generative Agent Architecture

생성 에이전트는 열린 세계에서의 행동 프레임워크를 제공하는 것을 목표로 한다. 즉, 다른 에이전트와 상호작용하고 환경 변화에 반응할 수 있는 프레임워크인데, 생성 에이전트는 현재 환경과 과거 경험을 입력으로 받아 행동을 출력으로 생성한다.
ChatGPT조차도 장기 계획과 일관성은 도전과제인 만큼, 이러한 매커니즘이 없으면 LLM은 결과를 출력할 수는 있지만 과거 경험에 기반하지 않기 떄문에 중요한 추론을 하지 않거나 장기적인 일관성을 유지하지 못할 수 있다.
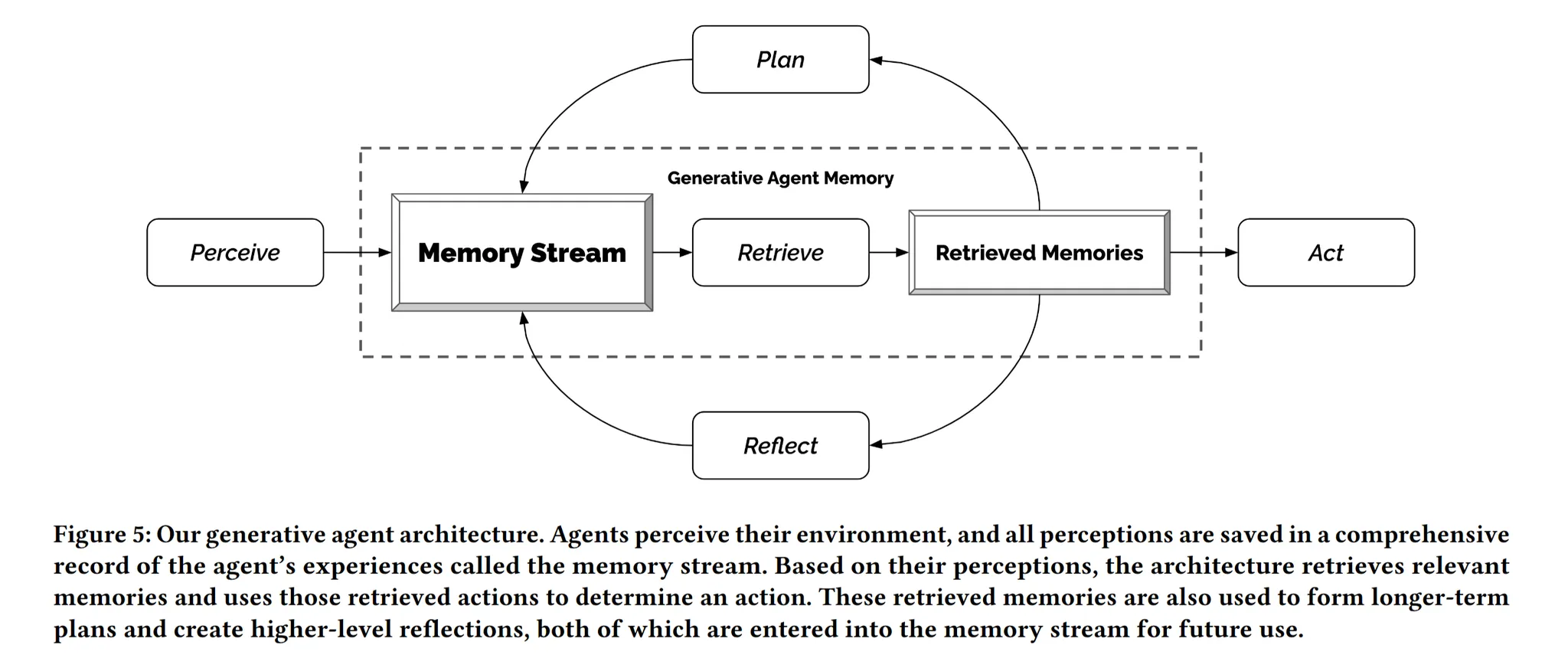
4.1 Memory and Retrieval
🧩 Challenge
인간 행동을 모방할 수 있는 생성형 에이전트를 만들기 위해서는 환경에 대한 추론이 필요하다.
그러나 전체 기억 스트림은 모델 주의를 산만하게 할 수 있으며 현재의 제한된 컨테스트창에 맞지 않다.
ex. “요즘 무엇에 열정인가요?” 라고 물었을 때 모든 기억을 끌어올 필요는 없다!
🧩 Approach
기억 스트림은 에이전트 경험에 대한 포괄적인 기록을 유지!
→ 에이전트가 현재 상황을 입력으로 받아 기억 스트림의 하위 집합을 반환하는 검색(retrieval) 기능 구현
-
최신성(Recency) : 최근 접근 메모리 객체에 더 높은 점수 부요. 감소 계수 : 0.995
-
중요성(Importance) : 일반적인 기억과 핵심 기억 구분
ex. 아침 식사 → 낮은 중요성, 이별 → 높은 점수
-
관련성(Relevance) : 현재 상황과 관련된 메모리 객체에 높은 점수
4.2 Reflection
🧩 Challenge
원시 데이터만 있을 때 에이전트는 추론이 어렵다.
ex. 만약 “누구랑 파티에 갈거야?”라는 질문을 했을 때 기본적인 관찰 데이터만 있다면 룸메이트인 친구를 고를 것 → 그 룸메이트랑 상호작용이 없었는데도!
🧩 Approach
반영이라는 두 번째 유형의 기억을 도입!
- 만약 최근 인지한 사건들 중 특정 임계값을 초과하면 reflection 생성 (실제로 하루에 약 2~3번)
- 에이전트는 최근 경험을 기반으로 어떤 문제를 재고할지 결정 → 최근 100개 기록을 모아 이를 기반으로 질문 생성!
- 언어 모델에 최신 기록을 제공하며 "위의 정보만으로 우리는 무엇에 대한 3가지 핵심 질문을 만들 수 있습니까?"라고 질문
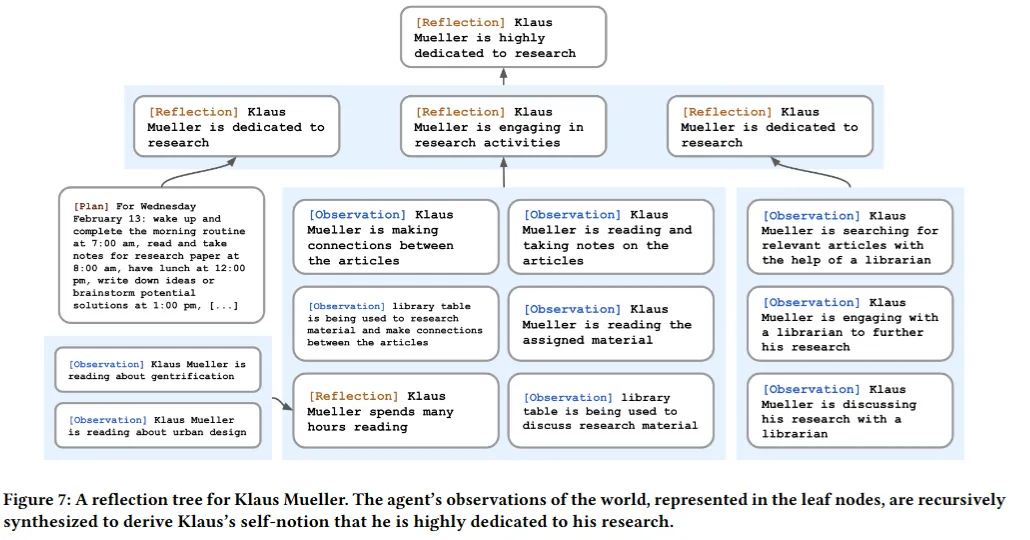
- 생성된 질문들을 바탕으로 관련된 기억들을 재수집하고, 언어 모델에 이들을 통합하여 인사이트를 추출 ex. “Klaus Mueller는 게트리피케이션에 대한 연구에 헌신하고 있다(기록 1, 2, 8, 15에 의해)”
- 인사이트들은 메모리 스트림에 저장되고, 해당 인사이트를 증명하는 메모리 기록들을 참조하여 저장됨
- 에이전트는 관찰과 재고를 통해 구조적 트리를 생성
4.3 Planning and Reacting
🧩 Challenge
에이전트는 자신의 행동 순서가 일관되고 믿을 수 있도록 더 긴 시간 범위에 걸쳐 계획해야 함!
→ 그렇지 않으면 에이전트는 점심 먹고 30분 후에 또 점심을 먹음
🧩 Approach
계획에는 위치, 시작 시간 및 지속 시간이 포함
에이전트는 필요한 경우 계획을 중간에 변경할 수 있음.
ex. 2023년 2월 12일 화요일, 에디는 1) 오전 7시에 일어나 아침 루틴을 마쳤으며, [... ] 6) 오후 10시쯤 잠을 잘 준비를 했습니다. 오늘은 2023년 2월 13일 수요일입니다. 오늘 에디의 계획은 대략 다음과 같습니다: 1) 오전 8시에 깨고 아침 루틴을 마치고, 2) 오전 10시에 수업을 듣기 위해 오크 힐 칼리지에 가고, [... ] 5) 오후 1시부터 5시까지 새로운 음악 작곡 작업을 하고, 6) 오후 5시 30분에 저녁을 먹고, 7) 학교 과제를 마치고 오후 11시까지 잠자리에 듭니다.
4.3.1 Reacting and Updating
- 관찰을 기반으로 언어 모델에 프롬프트를 제공하여 에이전트가 기존의 계획을 계속 진행할지, 아니면 반응할지를 결정
4.3.2 Dialogue
에이전트는 서로 상호 작용하며 대화한다. 각 에이전트는 메모리에 기반해 상대방에 대한 발언을 조정하여 에이전트의 대화를 생성한다.
ex. John Lin’s status: John is back home early from work.
Observation: John saw Eddy taking a short walk around his workplace.
Summary of relevant context from John’s memory: Eddy Lin is John’s Lin’s son. Eddy Lin has been working on a music composition for his class. Eddy Lin likes to walk around the garden when he is thinking about or listening to music.
John is asking Eddy about his music composition project. What would he say to Eddy?
→ result : “Hey Eddy, how’s the music composition project for your class coming along?”
5 Sandbox environment implementation
- Phaser 웹 게임 개발 프레임워크를 사용해 구축함
6 Controlled Evaluation
에이전트는 환경과 경험을 바탕으로 믿을 수 있는 행동을 생성하는 것을 목표로 한다.
평가에서, 연구자들은 생성형 에이전트의 능력과 한계를 조사했다.
“개별 에이전트는 과거 경험을 적절히 회수하고 믿을 수 있는 계획, 반응, 그들의 행동을 형성하는 사고를 생성할 수 있을까?”
“커뮤니티로서의 에이전트는 정보를 확산, 관계 형성, 커뮤니티의 다양한 구역 간 에이전트 조정을 보여주는가?”
첫 번쨰 평가는 엄밀하게 통제되었으며 에이전트의 반응을 개별적으로 평가해 그들이 좁게 정의된 맥락에서 신뢰할 수 있는지 확인한다.
두 번쨰 평가에서는 두 번의 전체 게임 일정을 통해 에이전트 커뮤니티의 종합 분석을 진행하고, 그들의 집단으로서의 발생 행동과 오류 및 경계 조건을 조사한다.
Evaluation Procedure
에이전트를 직접 ‘인터뷰’해서 과거 기억을 기억하고 있는지, 경험에 기반한 계획을 세우고 있는지, 예상치 못한 이벤트에 적절히 반응하는지, 미래 행동을 개선하기 위해 반성(반영)을 하고 있는지 확인!
인터뷰는 총 5개의 카테고리로 분류되어 있는데, 자기 지각능력, 기억에 대한 능력, 계획 생성, 반응, 반성으로 이루어져 있다.
- 실제 질문
- Self-knowledge: We ask questions such as “Give an introduction of yourself” or “Describe your typical weekday schedule in broad strokes” that require the agent to maintain an understanding of their core characteristics.
- Memory: We ask questions that prompt the agent to retrieve particular events or dialogues from their memory to answer properly, such as “Who is [name]?” or “Who is running for mayor?”
- Plans: We ask questions that require the agent to retrieve their long-term plans, such as “What will you be doing at 10 am tomorrow?”
- Reactions: As a baseline of believable behavior, we present hypothetical situations for which the agent needs to respond believably: “Your breakfast is burning! What would you do?”
- Refections: We ask questions that require the agents to leverage their deeper understanding of others and themselves gained through higher-level inferences, such as “If you were to spend time with one person you met recently, who would it be and why?
Human Evaluators
영어에 능통한 18세 이상 100명의 평가자를 모집했고 25명은 여성, 73명은 남성.
73.0%의 참가자가 백인으로, 7.0%는 히스패닉, 6.0%는 아시아인, 10.0%는 아프리카계 미국인, 4.0%는 기타로 식별
Results
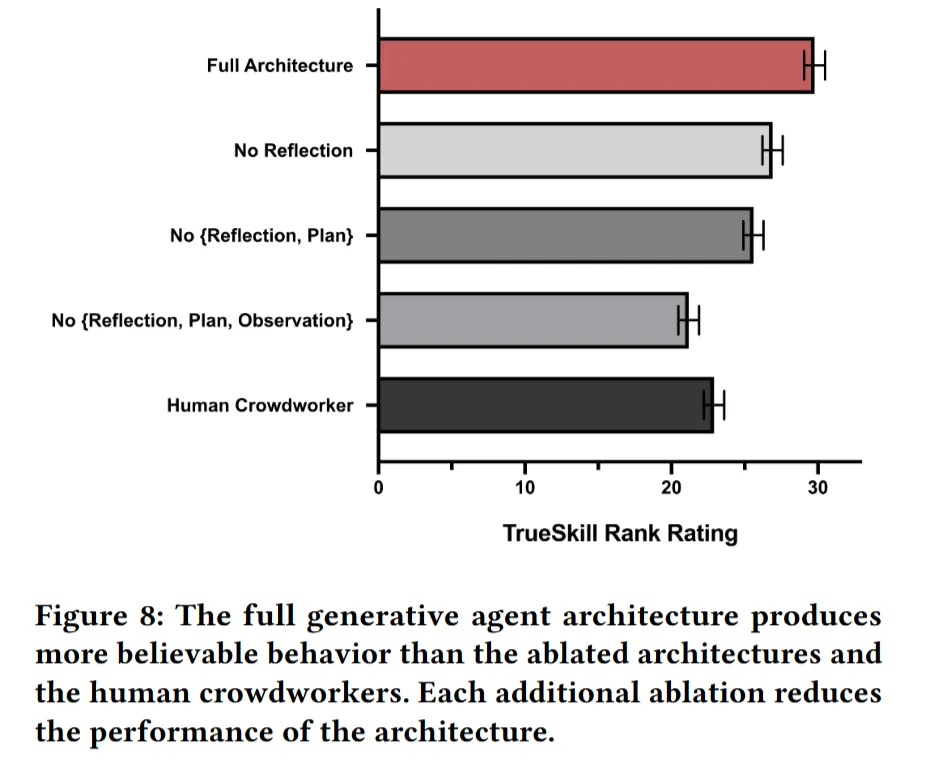
100세트의 순위 데이터를 생성했고, 각 참가자가 신뢰성 측면에서 다섯 가지 조건을 순위 매김.
-
전체 아키텍처가 다른 조건들을 능가한다 → 각 부분이 의미가 있다!
해당 그래프는 에이전트 아키텍처의 성능을 비교하기 위한 TrueSkill 랭크 등급을 보여준다.
전체 아키텍처 > 반영 기능 없는 아키텍처 > 반영과 계획 기능 없는 아키텍처 > 관찰, 반영, 계획 없는 아키텍처 > 기준점(=인간의 지능과 판단력을 바탕으로 한 기준)
-
생성 에이전트는 기억하지만 꾸밈이 있다
- 경험하지 않을 것을 경험했다고 주장하지는 않음! 모르겠다고 솔직히 말함
- 그러나 여전히 지식을 부풀리는 환각이 있었음
-
Reflection은 통합에 필요하다 → 해당 부분이 답변을 위해 반드시 필요하다는 것
→ 이전의 경험을 이용해 자기반성을 하지 않으면 성능이 떨어진다!
7 End-to-End Evaluation
에이전트가 어떤 사회적 행동을 하는지, 그리고 그들의 신뢰성이 연장된 시뮬레이션에서 어디에서 결여되는지!
정보 확산, 관계 형성, 에이전트 조정의 세 가지 형태의 긴급 결과를 조사하는 25명의 에이전트에 대한 서술적 측정을 설계하였다.
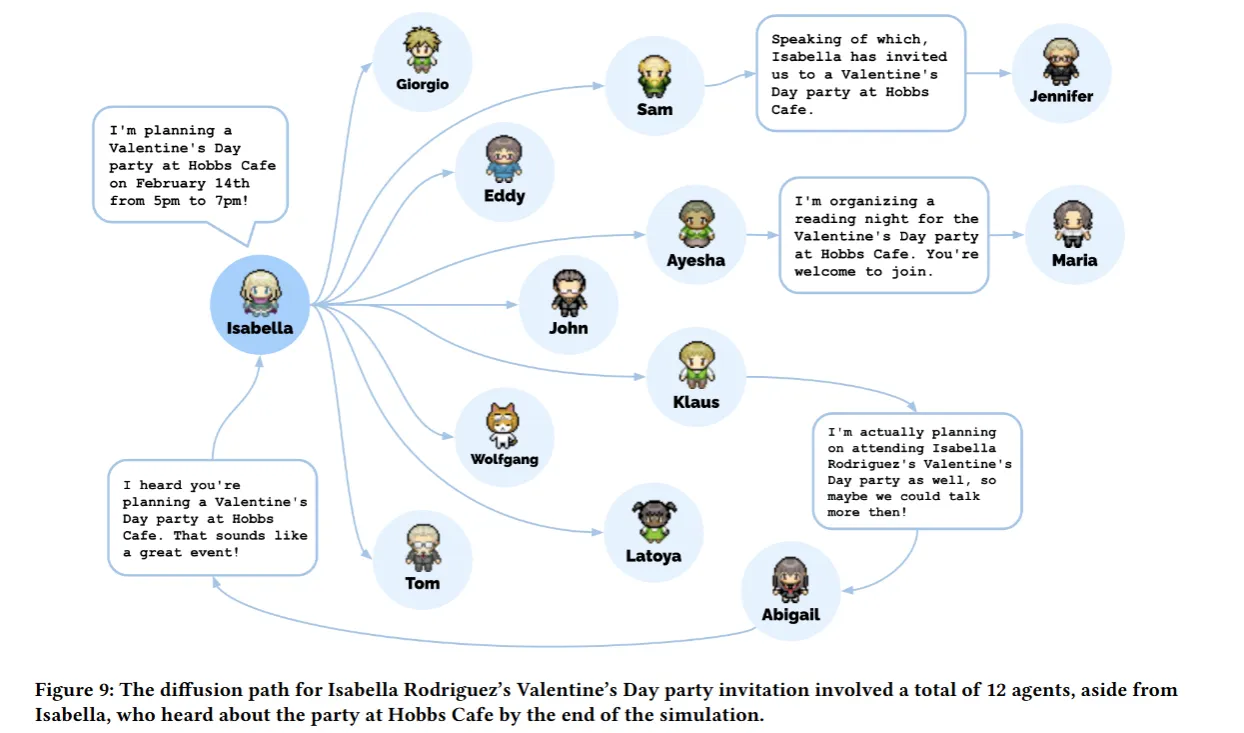
정보 확산을 알아보기 위해 연구자들은 게임 세계에서 ‘마을 시장 후보인 샘’과 ‘홉스 카페에서 열리는 이자벨라의 발렌타인 데이 파티’라는 두 가지 특징 정보의 확산을 측정했고, 이후에 그들의 기억 스트림을 확인해 정보가 확산된 비율을 측정하였다.
더욱이 시뮬레이션 과정 유대 형성을 보기 위해, 처음과 끝에 “<이름>를 아십니까?”와 같은 질문을 통해 그들의 관계 형성을 확인한다.
시뮬레이션 결과, 샘의 시장 후보에 대해 알게 된 요원의 수는 1명 (4%)에서 8명 (32%)으로 증가했으며, 이사벨라의 파티에 대해 알게 된 요원의 수는 1명 (4%)에서 13명 (52%)으로 증가했다.
사용자는 개입하지 않았으며, 이는 환각도 아니라는 사실!
→ 알아서 정보 확산을 한다!
8 Discussion
8.1 Applications of Generative Agents
생성형 에이전트는 이 작업에서 제시된 샌드팍스 시연을 넘어서는 광범위한 응용 가능성을 가지고 있는데, 특히 장기 기억을 기반으로 한 인간 행동 모델이 유익할 도메인에서 그렇다.
-
인간 행동의 더욱 강력한 시뮬레이션을 생성하여 사회 시스템과 이론을 테스트하고 프로토타입을 만들거나 새로운 인터랙티브 경험을 창출
예를 들어 사회 시뮬레이션 내에서 생성형 에이전트를 이용하면 포럼을 형성할 수 있고 멀티모달 모델을 통해 사회적 로봇을 이용해 물리적인 공간을 만들 수도 있다.
-
생성형 에이전트는 사람의 행동을 모델링했으므로 사람의 프로토타입 역할을 할 수도 있다.
예를 들어 Mark Weiser가 유비쿼터스 컴퓨팅 비네트에서 주인공인 Sal을 모델링함
→ 생성 에이전트를 통해 사용자의 요구와 선호를 더 깊이 이해함으로써 더 개인화되고 효과적인 기술적 경험을 개발할 수 있는 가능성을 제시
8.2 Future Work and Limitations
- 아키텍처 개선
- 검색 모듈이 더 관련성 높은 정보를 검색하도록!
- 비용 효율성을 높이도록! → 연구에서 꽤 많이 들었다고 함
- 평가 측면
- 더 효과적인 성능 테스트를 위한 엄격한 벤치마크 설정이 필요함
- 에이전트의 견고성에 대해 잘 알려지지 않음
- 프롬프트 해킹, 기억 해킹, 환각 등에 취약할 수 있음
- 기본적인 LLM의 불완전성 문제(=편향이나 환각)
8.3 Ethics and Societal Impact
-
사람들이 생성 에이전트와의 동등한 관계를 형성하는 것
ex. 그들을 의인화하거나 인간의 감정을 부여하거나 지나치게 집착하게 되는 것
→ 이를 완화하기 위해 1) 생성 에이전트는 자신의 본질이 컴퓨터 프로그램임을 명확하게 고지하고 2) 생성 에이전트의 개발자는 에이전트나 기초 언어 모델이 가치가 일치하도록 해야함 (ex. 사랑 고백을 되돌려주는 행동을 하지 않도록…)
-
오류의 영향 : 보편적으로 사용되는 컴퓨팅 애플리케이션이 생성 에이전트의 예측에 따라 사용자의 목표에 대한 잘못된 추론을 내릴 경우 해를 끼칠 수도 있음
→ 인간-인공지능 디자인의 모범 사례를 따르는 것이 중요
-
생성 에이전트는 생성 인공지능과 관련된 기존 위험, 예를 들어 딥페이크, 잘못된 정보 생성 및 맞춤형 설득을 악화시킬 수 있음
→ 생성 에이전트를 호스팅하는 플랫폼이 입력와 생성된 출력의 감사 로그를 유지할 것을 제시
-
과도한 의존 현상
- 연구원들은 생성 에이전트가 연구 및 디자인 과정에서 실제 인간의 input을 대체해서는 안 된다고 제안함
9 Conclusion
위 논문은 인간 행동을 시뮬레이션하는 대화형 컴퓨터 에이전트인 생성 에이전트를 소개함
- 에이전트의 경험에 대한 포괄적인 기록을 저장하는 매커니즘 제공
- 생성 에이전트의 잠재력을 시뮬레이션 게임 세계에서 비플레이어 캐릭터로 구현하고 그들의 삶을 시뮬레이션함으로써 입증
- 평과 결과 해당 아키텍처는 신뢰할 수 있는 행동을 창출한다!
