1. 테이블 접근 순서에 따른 용어

1-1. 드라이빙 테이블 (driving table)
- 쿼리 실행 계획에서 첫 번째로 접근되는 테이블
- 쿼리 성능에 가장 큰 영향을 미치는 테이블
- 더 작은 결과를 생성하거나, 더 효율적인 인덱스를 갖는 테이블을 드라이빙 테이블로 선택해야 한다.
1-2. 드리븐 테이블 (driven table)
- 쿼리 실행 계획에서 나중에 접근되는 테이블
JOIN연산에서 드라이빙 테이블에 의해 접근되는 테이블- 큰 데이터 집합을 갖고 있는 테이블
1-3. 예시
SELECT
학생.학번,
학생.이름,
비상연락망.관계,
비상연락망.연락처
FROM 학생
JOIN 비상연락망
ON 학생.학번 = 비상연락망.학번
WHERE 학생.학번 IN (1, 100)- 드라이빙 테이블 :
학생테이블 100건 - 드리븐 테이블 :
비상연락망테이블 1000건 학생테이블에 먼저 접근하여 학번 1번, 100번 학생 정보를 추출하고,- 학생 테이블의 검색 결과를 통해
비상연락망테이블에 접근한다.
📌 성능 최적화
- 가장 효율적인 인덱스를 가진 테이블 또는 가장 작은 결과 집합을 생성할 것으로 예상되는 테이블을 드라이빙 테이블로 선택하는 것이 좋다.
- 조인 조건절의 열이 인덱스로 사용되면 성능이 향상된다.
2. 중첩 루프 조인 (NL join; nested loop join)
- 드라이빙 테이블의 데이터 1건당 드리븐 테이블을 반복해 검색한다.
- 최종적으로 양쪽 테이블에 공통된 데이터를 출력한다.
예시 쿼리
SELECT 학생.학번,
학생.이름,
비상연락망.관계,
비상연락망.연락처
FROM 학생
JOIN 비상연락망
ON 학생.학번 = 비상연락망.학번
WHERE 학생.학번 IN (1, 100)2-1. 두 테이블(학생, 비상연락망)에 기본 키&인덱스가 없을 때
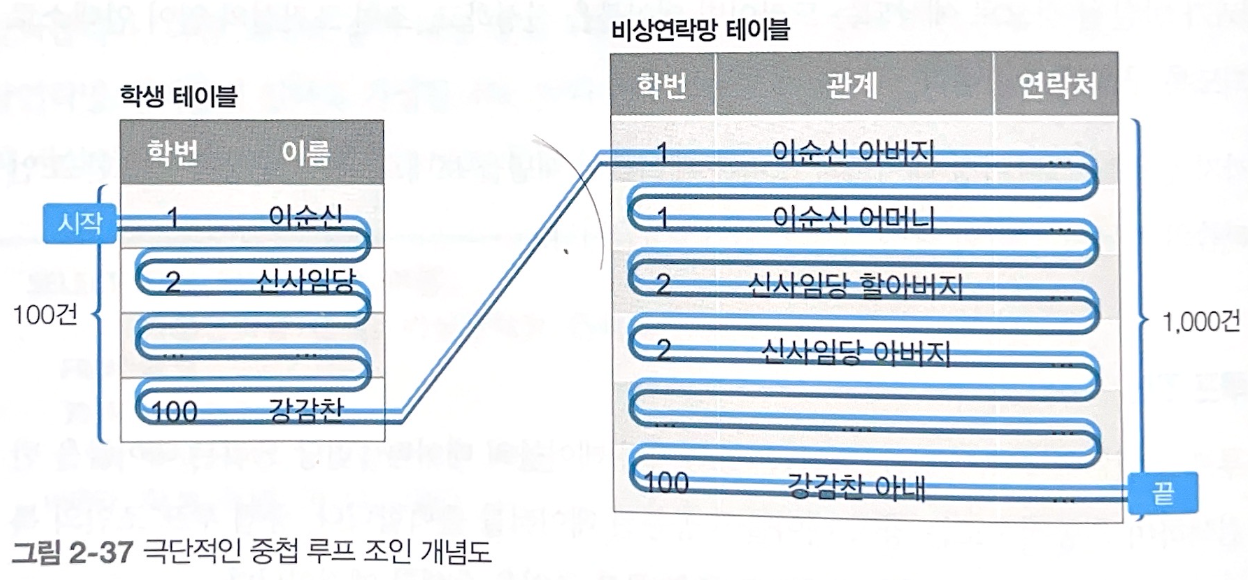
- 학번 1, 100에 해당하는 학생들의 학생 정보와 비상연락망 정보를 가져온다.
- 학번 1을
학생테이블에서 검색하기 위해 학생 테이블 데이터 100건에 모두 접근한다. - 학번 1과 동일한 데이터를 가졌는지 확인하기 위해
비상연락망테이블의 데이터 1,000건에 모두 접근한다. - 학번 100을
학생테이블에서 검색하기 위해 학생 테이블 데이터 100건에 모두 접근한다. - 학번 100과 동일한 데이터를 가졌는지 확인하기 위해
비상연락망테이블의 데이터 1,000건에 모두 접근한다.
➡️ 학번 1 데이터 (100건+1,000건) + 학번 100 데이터 (100건+1,000건) = 총 2,200건 데이터에 접근하게 된다.
2-2. 두 테이블(학생, 비상연락망)에 학번을 기준으로 인덱스가 있을 때

- 두 테이블에 모두 인덱스가 있기 때문에, 데이터를 조회 시 인덱스로 접근하게 된다.
- 학번 1을
학생테이블에서 검색하기 위해 인덱스 1로 검색한다. (데이터 1건 조회) - 학번 1을
비상연락망테이블에서 인덱스 1(=학번 1)로 검색하고, 인덱스 1인 데이터가 2건이 있었다고 가정한다. (데이터 3건 조회=데이터 2건 조회 후 다음에 오는 데이터가 인덱스 1이 아닌 것을 확인하기 위해 조회하게 된다.) - 학번 100을
학생테이블에서 검색하기 위해 인덱스 100으로 검색한다. (데이터 1건 조회) - 학번 100을
비상연락망테이블에서 인덱스 100(=학번 100)으로 검색하고, 인덱스 100인 데이터는 1건이 있었다고 가정한다. (데이터 1건 조회=인덱스 100인 데이터가 가장 마지막 데이터라고 가정한다.)
➡️ 학번 1 데이터 (1+3) + 학번 100 데이터 (1+1) = 총 6건의 데이터에 접근하게 된다.
(인덱스의 다음 값을 확인하고 접근 대상이 되는지 여부를 판단하는 것도 실제 접근 횟수에 포함되어야 하지만, 메커니즘의 이해를 위해 생략)
📌 이것이 가능한 이유
- 인덱스로 정의된 열을 기준으로 순차 정렬되어 있기 때문이다. 즉, 학번 1의 데이터가 앞에 있고, 학번 100의 데이터가 뒤에 있는 이유이다.
- 그러나, 인덱스를 이용해 테이블의 데이터를 찾아가는 과정에서 '랜덤 엑세스'가 발생한다.
- 그러므로, 데이터 액세스 범위를 좁히는 방향으로 인덱스를 설계하고 조건절을 작성하여 '랜덤 액세스'를 줄여야 한다.
랜덤 엑세스 추가 설명
- 비고유 인덱스 : 랜덤 엑세스를 유발하는 인덱스
- 기본 키 = 클러스터형 인덱스 : 즉, 기본 키의 순서대로 테이블의 데이터가 적재되어 조회 효율이 높다.
2-3. 학생 테이블에 학번을 기준으로 인덱스가 있을 때, 비상연락망 테이블에 인덱스가 없을 때
학생테이블에서 인덱스 1(=학번 1) 데이터를 찾고,- 인덱스가 없는
비상연락망테이블의 전체 데이터에 모두 접근해야 한다. 학생테이블에서 인덱스 100(=학번 100) 데이터를 찾고,- 인덱스가 없는
비상연락망테이블의 전체 데이터에 모두 접근해야 한다.
➡️ 인덱스가 없는 드리븐 테이블(비상연락망)에 대해 매번 전체 데이터를 비효율적으로 검색해야 한다.
이 경우, "블록 중첩 루프 조인"이 중첩 루프 조인의 효율성을 높일 수 있다.
3. 블록 중첩 루프 조인 (BNL join; block nested loop join)

드라이빙 테이블에 조인 버퍼 (join buffer)*를 도입한다.
- 드라이빙 테이블(
학생) 테이블에서 학번 1, 100 데이터 검색 - 검색된 데이터를 조인 버퍼에 적재
- 조인 버퍼 ↔️ 드리븐 테이블(
비상연락망) 간 데이터 비교
- NL join에서는 학번 1, 학번 100에 대해 비상연락망 테이블을 각 1,000번씩 조회한다. 총 2,000번 조회
- BNL join에서는 학번 1, 학번 100에 대해 비상연락망 테이블을 1,000번 조회한다. 총 1,000번 조회
✅ 조인 버퍼의 데이터 ↔️ 비상연락망 테이블 간의 테이블 풀 스캔 (table full scan) 으로 원하는 데이터를 찾을 수 있다.
*조인 버퍼 (join buffer) : 조인에 필요한 테이블의 일부 또는 전체를 메모리에 임시적으로 저장함으로써, 디스크 I/O를 줄이고 데이터 접근 속도를 높인다.
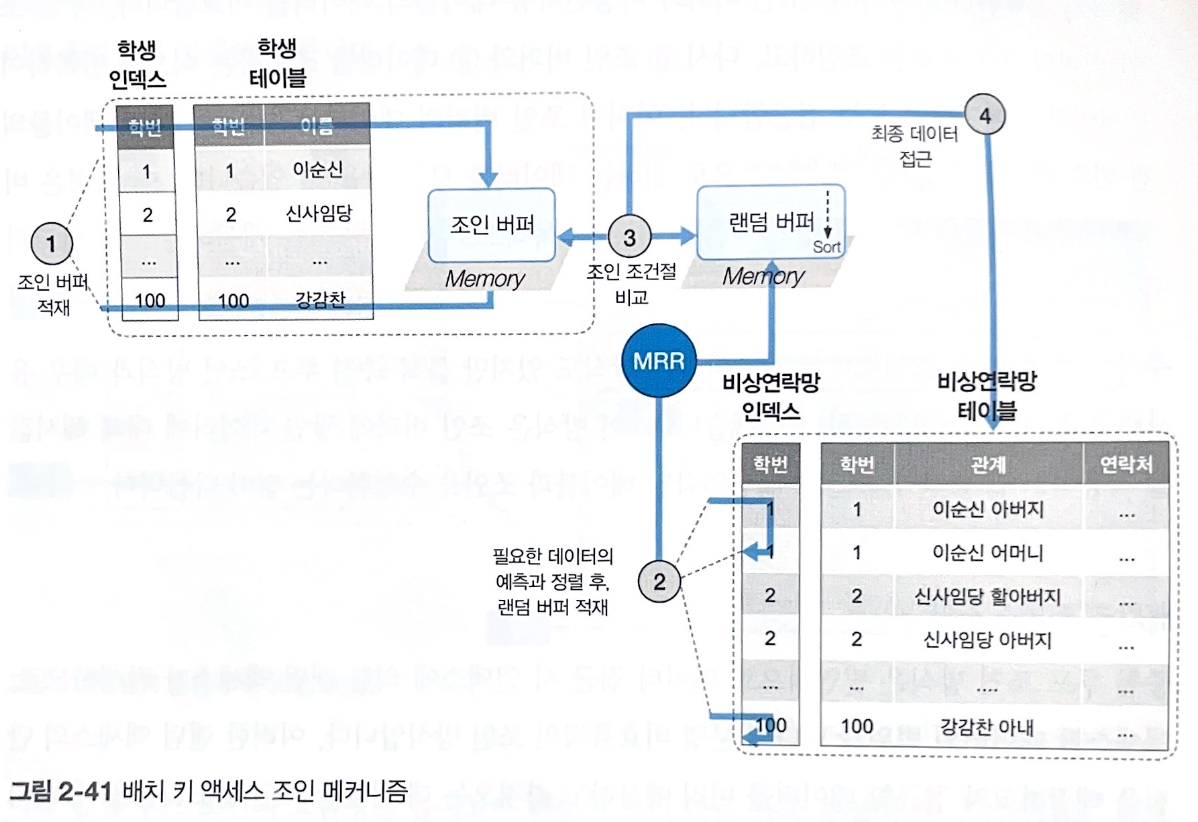
4. 배치 키 액세스 조인 (BKA join; batched key access join)
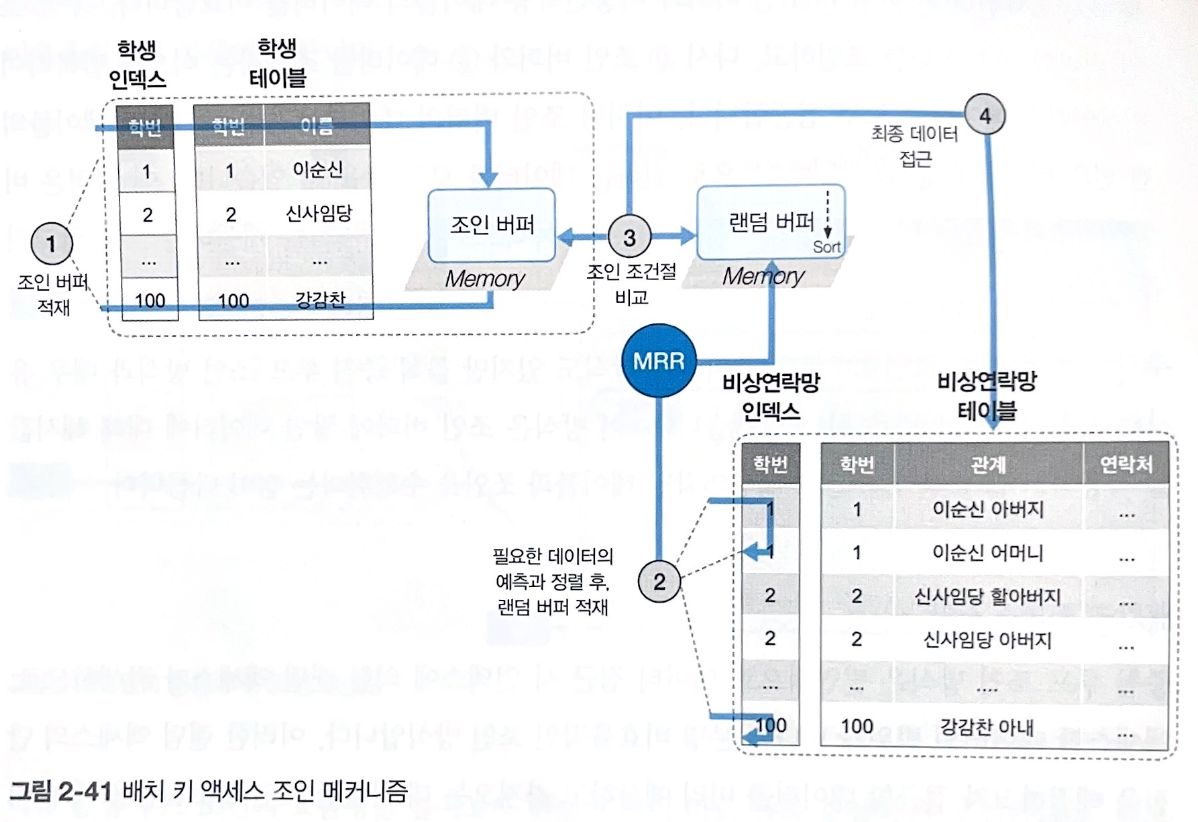
중첩 루프 조인 방식에서 "랜덤 액세스"의 단점을 해결하기 위해, 접근할 데이터를 미리 예상하고 가져온다.
다중 범위 읽기 (MRR; multi range read)
드리븐 테이블에 필요한 데이터를 미리 예측하고 정렬된 상태로 버퍼에 적재하는 기능
즉, 드리븐 테이블에 대한 랜덤 액세스가 아닌, 시퀀셜 액세스를 하게 된다.
- 드라이빙 테이블에서 필요한 데이터를 추출하여 조인 버퍼에 저장한다. (학번1, 100 데이터)
- 드리븐 테이블의 인덱스를 기반으로 필요한 데이터를 예측하여 랜덤 버퍼에 저장한다. (학번1, 100 데이터)
학생.학번 = 비상연락망.학번조인 조건절로 조인 버퍼 ↔️ 랜덤 버퍼를 비교한다.- 동일한 데이터가 있다면, 드리븐 테이블의 데이터에 접근하고 결과를 조인해 반환한다.
5. 해시 조인 (hash join)
5-1. 작동 방식
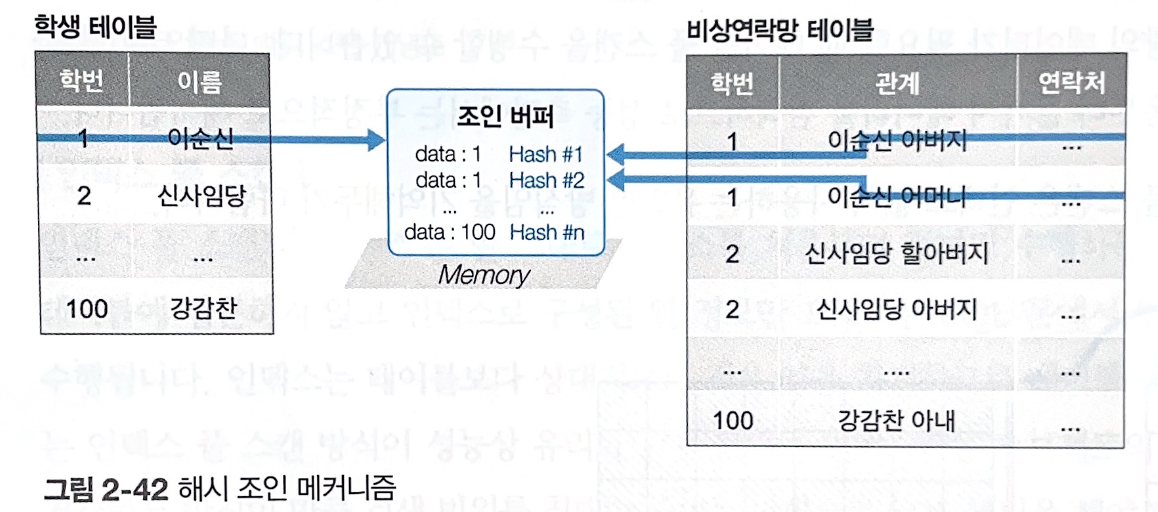
- 조인에 참여하는 각 테이블의 데이터를 내부적으로 해시값으로 만들어 내부 조인을 수행한다.
- 즉,
학생테이블의 학번 1 데이터의 해시값 ↔️비상연락망테이블의 학번 1 데이터의 해시값을 비교한다. - 각 해시값이 동일한 경우, "학번 1 데이터"에 대해 내부 조인을 수행한 결과가 조인 버퍼에 저장된다.
5-2. 특징
- 조인 열은 인덱스로 설정되지 않아도 된다.
- 해시 조인은 대용량 데이터를 처리할 때 효과적이다.
- 해시 테이블을 사용하기 때문에, 매칭되는 행을 찾는 데 걸리는 시간이 짧다.
- 적합한 상황
- 두 테이블 중 하나가 다른 하나보다 상대적으로 작고, 작은 테이블을 전체적으로 메모리에 로드할 수 있는 경우에 이상적이다.
- 또한, 조인 키에 중복 값이 많지 않을 때 효율적이다.
- 해시 조인은 초기에 해시 테이블을 생성하는 데 상당한 메모리와 시간이 소요될 수 있다.
📌 Source
- 양바른, 「업무에 바로 쓰는 SQL 튜닝」, 한빛미디어, 2021
💡 질문과 피드백은 댓글에 남겨주시기 바랍니다.
❤️ 도움이 되셨다면 공감 부탁드립니다.
