
작성에 앞서 해당 게시글은 공부하는 입장에서 작성한 내용으로 완전 초보입니다. 작성 내용에 오류가 있다면 알려주세요 🐳
🚀🚀
오늘은 RAG 연습 첫 번째로 파일명을 키로 해서 context 딕셔너리를 만들고, 해당 파일 명이 인풋 메시지(질문)에 포함되어있다면 해당 내용을 기반으로 Open AI 모델을 써서 답장하는 가벼운 채팅 인터페이스 구현 실습을 해보려고 한다.
📂 폴더 및 기초 파일 생성
우선 프로젝트 폴더를 생성한 후 데이터를 넣기 위한 knowledge-base 폴더를 제작하였다.
그리고, 기초 Jupyter Notebook 파일을 생성하였고, OPENAI_API_KEY 를 담은 .env 파일도 생성한다.
실습 환경을 위해 필요한 패키지와 의존성을 정의한 environments.yml 파일을 넣어줬다. 해당 파일의 내용은 다음의 강의를 보며 있던 환경을 그대로 넣었다. (이 중에서 모든 의존성을 사용하지는 않겠지만, 우선은 다른 학습이 목표기 때문에 따로 수정하지는 않았다)
name: llms
channels:
- conda-forge
- defaults
dependencies:
- python=3.11
- pip
- python-dotenv
- requests
- beautifulsoup4
- pydub
- numpy
- pandas
- scipy
- pytorch
- jupyterlab
- ipywidgets
- pyarrow
- anthropic
- google-generativeai
- matplotlib
- scikit-learn
- chromadb
- langchain
- langchain-text-splitters
- langchain-openai
- langchain-experimental
- langchain-chroma
- faiss-cpu
- tiktoken
- jupyter-dash
- plotly
- twilio
- duckdb
- feedparser
- pip:
- transformers
- sentence-transformers
- datasets
- accelerate
- sentencepiece
- bitsandbytes
- openai
- gradio
- gensim
- modal
- ollama
- psutil
- setuptools
- speedtest-cli다음의 명령어로 종속성과 라이브러리를 자동으로 설치할 수 있다. 나는 이미 환경이 만들어져 있으므로 activate 만 해주었다.
-
가상환경 생성
conda env create -f envorionment.yml -
가상환경 활성화
conda activate llms의 명령어를 통해 활성화할 수 있다.

활성화가 된 상태에서 주피터 랩 명령어를 통해 jupyter lab을 켜준다.
이런 식으로 주피터 랩이 켜진 것을 확인할 수 있다.
이제 RAG 에서 사용할 데이터를 생성을 할 건데, 나는 내 허접한 포트폴리오 파일과 간단한 정보를 적었다.
👩💻 코드 작성
(아 갑자기 노트북 파일이 안열려서 삭제 후 주피터랩에서 다시 생성해줬다!)
1. 라이브러리 임포트 & 모델 정의
- 가장 먼저 라이브러리를 임포트한다.
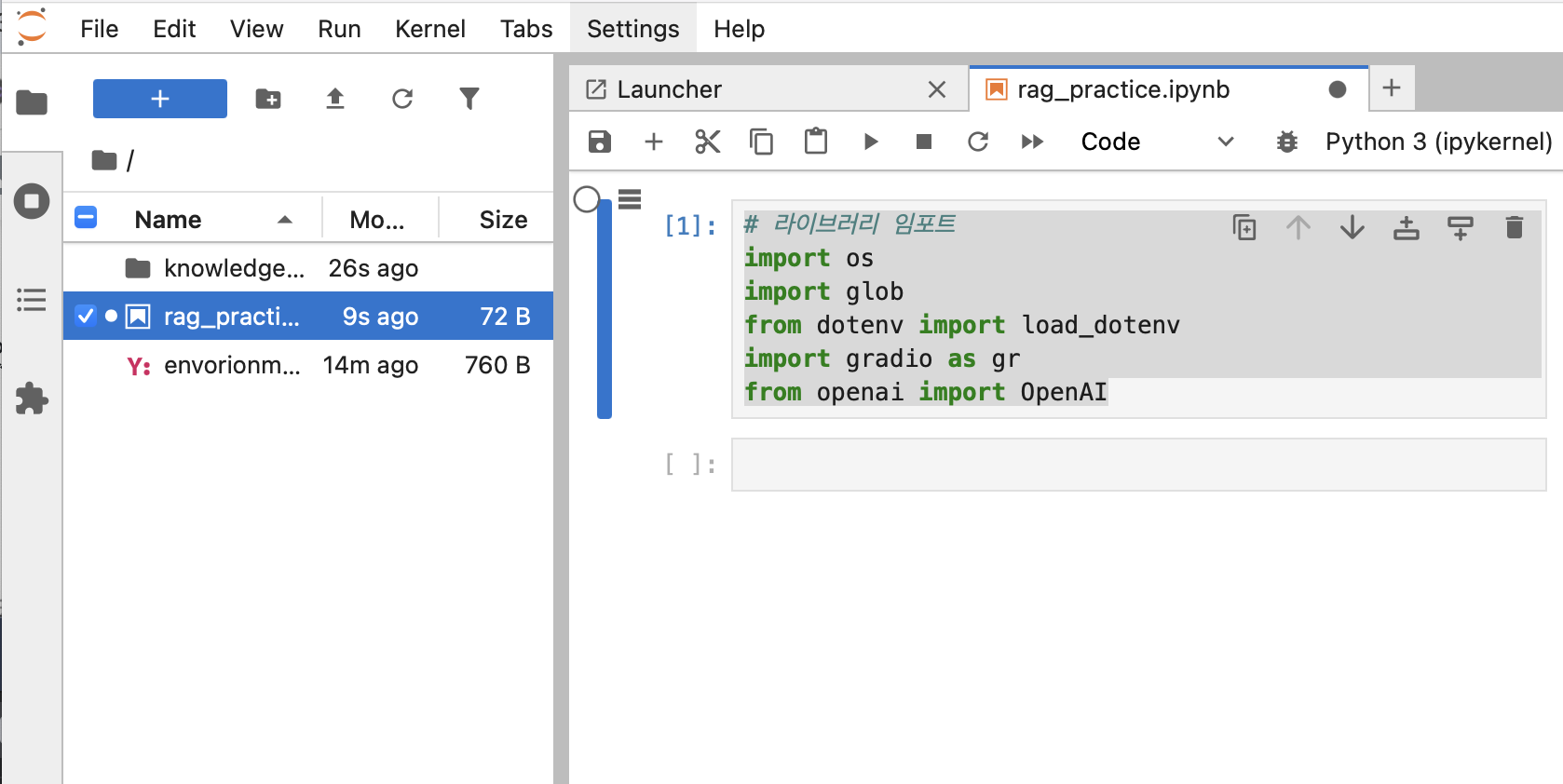
import os # 운영 체제와 상호작용(파일/디렉토리 관리, 환경 변수 접근 등).
import glob # 파일 경로를 패턴으로 검색(와일드카드 지원).
from dotenv import load_dotenv # .env 파일에서 환경 변수를 로드.
import gradio as gr # 머신러닝 모델용 대화형 웹 UI 생성.
from openai import OpenAI # OpenAI API 호출(GPT, DALL·E, Whisper 등).그리고 OpenAI 모델을 다음처럼 gpt-4o-mini로 정해줬다.
MODEL = "gpt-4o-mini"2. OPEN AI API 키 불러오기
이제 .env 에 적었던 키를 다음의 명령어로 불러온다.
load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_API_KEY', 'your-key-if-not-using-env')
openai = OpenAI()3. 지식베이스 로드
knowledge-base 디렉토리 내 모든 파일에 대해 각 파일의 내용을 context라는 딕셔너리에 저장했다. (파일명을 키로 사용했다)
(지식베이스 파일의 내용을 메모리에 로드하여, 이후 검색(Query)나 LLM 호출 시 활용할 수 있도록 준비)
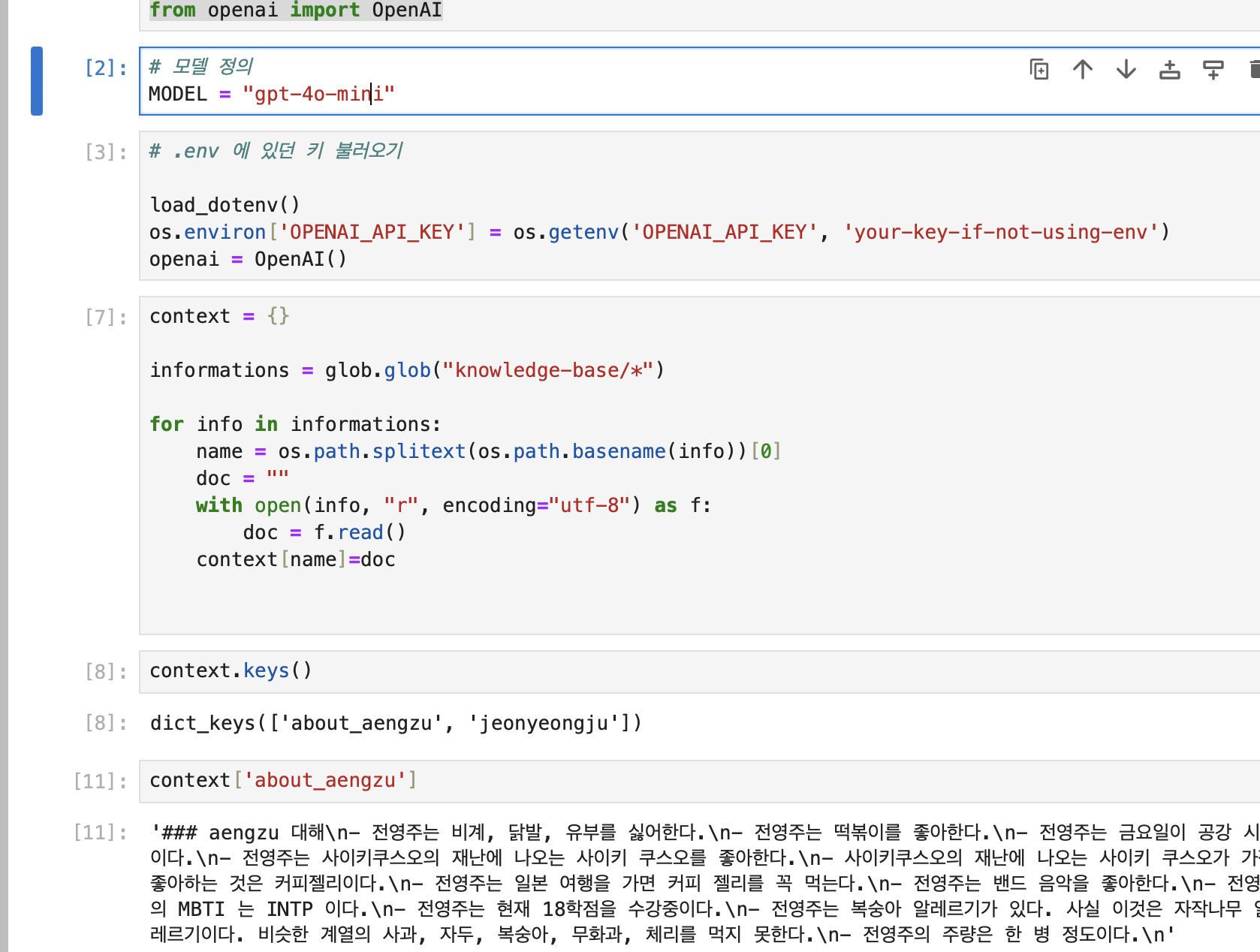
코드는 다음과 같다.
# 지식베이스를 저장할 딕셔너리
context = {}
# knowledge-base 디렉토리의 모든 파일 경로를 가져옴
informations = glob.glob("knowledge-base/*")
# 각 파일에 대해 반복 처리
for info in informations:
# 파일 이름에서 확장자를 제거한 순수 파일명 추출
name = os.path.splitext(os.path.basename(info))[0]
doc = "" # 파일 내용을 저장할 변수 초기화
# 파일을 읽어서 문자열로 저장
with open(info, "r", encoding="utf-8") as f:
doc = f.read()
# 파일명을 키, 파일 내용을 값으로 딕셔너리에 저장
context[name] = doc4. 간단한 검색 함수 구현
OEPN_AI 호출을 위한 시스템 메시지는 다음처럼 정의하였다.
system_message = "당신은 '전영주'이라는 사람에 대해 정확한 질문에 답변하는 전문가입니다. 간결하고 정확한 답변을 제공하세요. 만약 답변을 모른다면, 모른다고 말하세요. 제공된 관련 정보가 없다면 아무것도 만들어내지 마세요."이제 간단한 검색 함수를 구현하였다. 해당 함수는 키를 기반으로 메시지에 key 가 추가되어있다면 관련 내용을 리스트에 추가하는 간단한 검색함수이다. 처음에 왜 결과가 안나오지 🥸 했는데 생각해보니 영어로 파일명을 지어서 그런거였다.. 다음처럼 'who is jeonyeongju' 라고 한다면, 해당 message 에 jeonyeongju 라는 키워드가 있으므로 해당 파일의 내용을 리턴하게 된다
def get_relevant_context(message):
# 관련 컨텍스트를 저장할 리스트 초기화
relevant_context = []
# context 딕셔너리의 모든 항목을 순회 (context_title: 키, context_details: 값)
for context_title, context_details in context.items():
# 메시지에 컨텍스트 제목(context_title)이 포함되어 있는지 확인 (대소문자 무시)
if context_title.lower() in message.lower():
# 관련된 컨텍스트 내용을 리스트에 추가
relevant_context.append(context_details)
# 관련 컨텍스트 리스트 반환
return relevant_context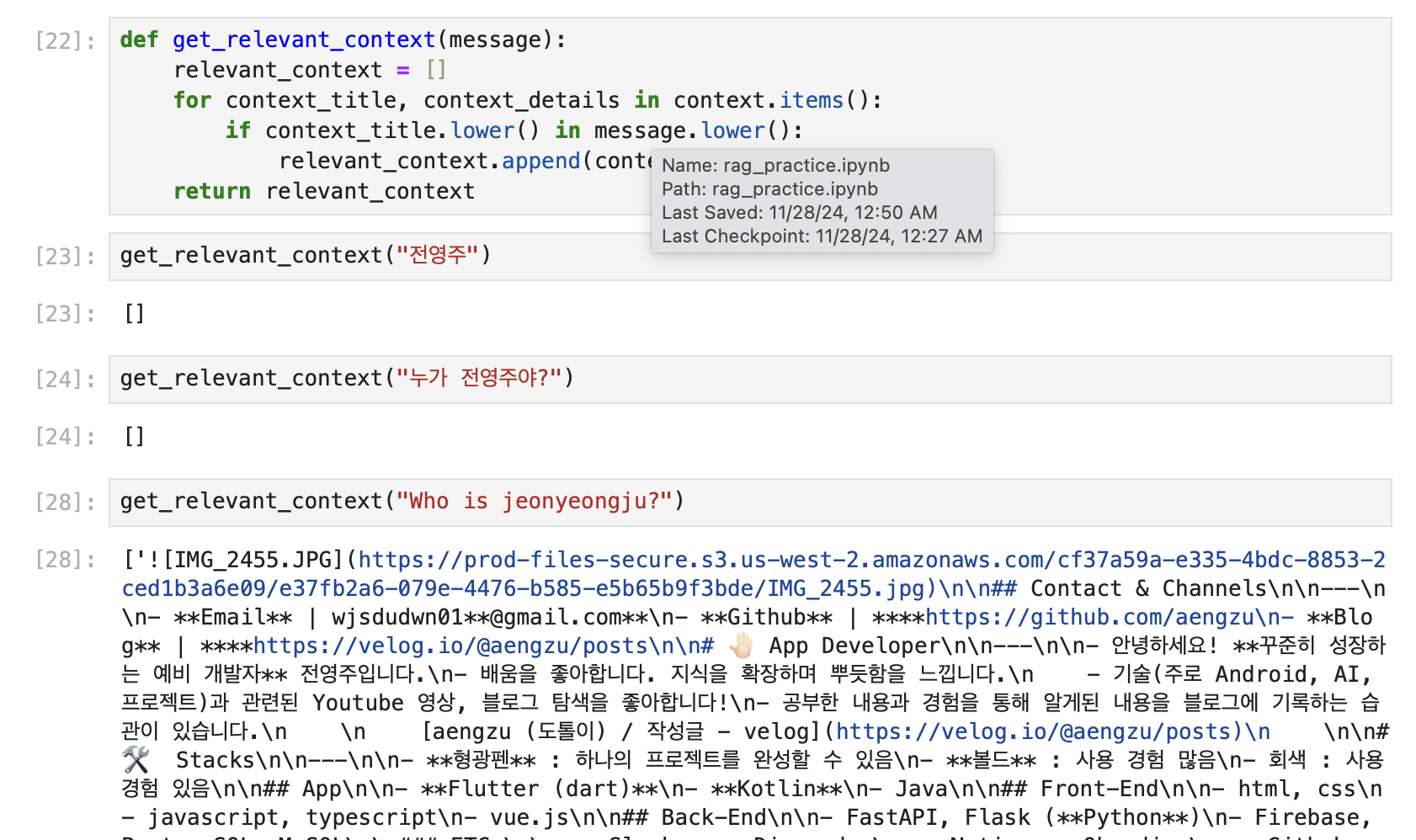
그리고, 정보 소개 문구 추가를 위한 함수도 다음처럼 생성한다.
def add_context(message):
# 사용자의 메시지와 관련된 컨텍스트를 가져옴
relevant_context = get_relevant_context(message)
# 관련 컨텍스트가 존재하는 경우
if relevant_context:
# 메시지에 추가 문맥 정보 소개 문구를 추가
message += "\n\n다음 추가 문맥은 이 질문에 답변하는 데 도움이 될 수 있습니다:\n\n"
# 관련 컨텍스트 내용을 메시지에 순차적으로 추가
for relevant in relevant_context:
message += relevant + "\n\n"
# 컨텍스트가 추가된 메시지를 반환
return message5. 채팅 함수 및 간단한 채팅 인터페이스 구현
위에서 만든 간단한 검색 함수 기반으로 채팅 함수와 채팅 인터페이스를 구현하였다. 이 함수는 사용자의 메시지와 대화 기록을 기반으로 관련 컨텍스트를 추가하고 OpenAI 모델을 통해 스트리밍 방식으로 응답을 생성하는 함수이다.
스트리밍 방식은 데이터를 부분적으로 분리하여 순차적으로 전달하는 방법을 의미하며, OpenAI API의 스트리밍 방식은 모델이 생성한 텍스트를 한 번에 모두 제공하지 않고, 청크 단위로 나눠서 실시간으로 반환하는 것이다.
채팅 함수 구현
def chat(message, history):
# 시스템 메시지와 대화 기록(history)을 합쳐 초기 메시지 리스트 생성
messages = [{"role": "system", "content": system_message}] + history
# 사용자의 메시지에 관련된 컨텍스트를 추가
message = add_context(message)
# 사용자의 메시지를 메시지 리스트에 추가
messages.append({"role": "user", "content": message})
# OpenAI 모델을 호출하여 스트리밍 방식으로 응답 생성
stream = openai.chat.completions.create(model=MODEL, messages=messages, stream=True)
# 응답 텍스트 초기화
response = ""
# 스트림에서 응답의 각 청크(chunk)를 가져와 연결
for chunk in stream:
response += chunk.choices[0].delta.content or '' # 청크의 내용을 추가 (없으면 빈 문자열)
yield response # 중간 결과를 호출자에게 반환채팅 인터페이스 표시
Gradio 라이브러리를 사용하면 아주 쉽게 chat 함수를 기반으로 한 대화형 인터페이스를 생성하고 실행할 수 있다.
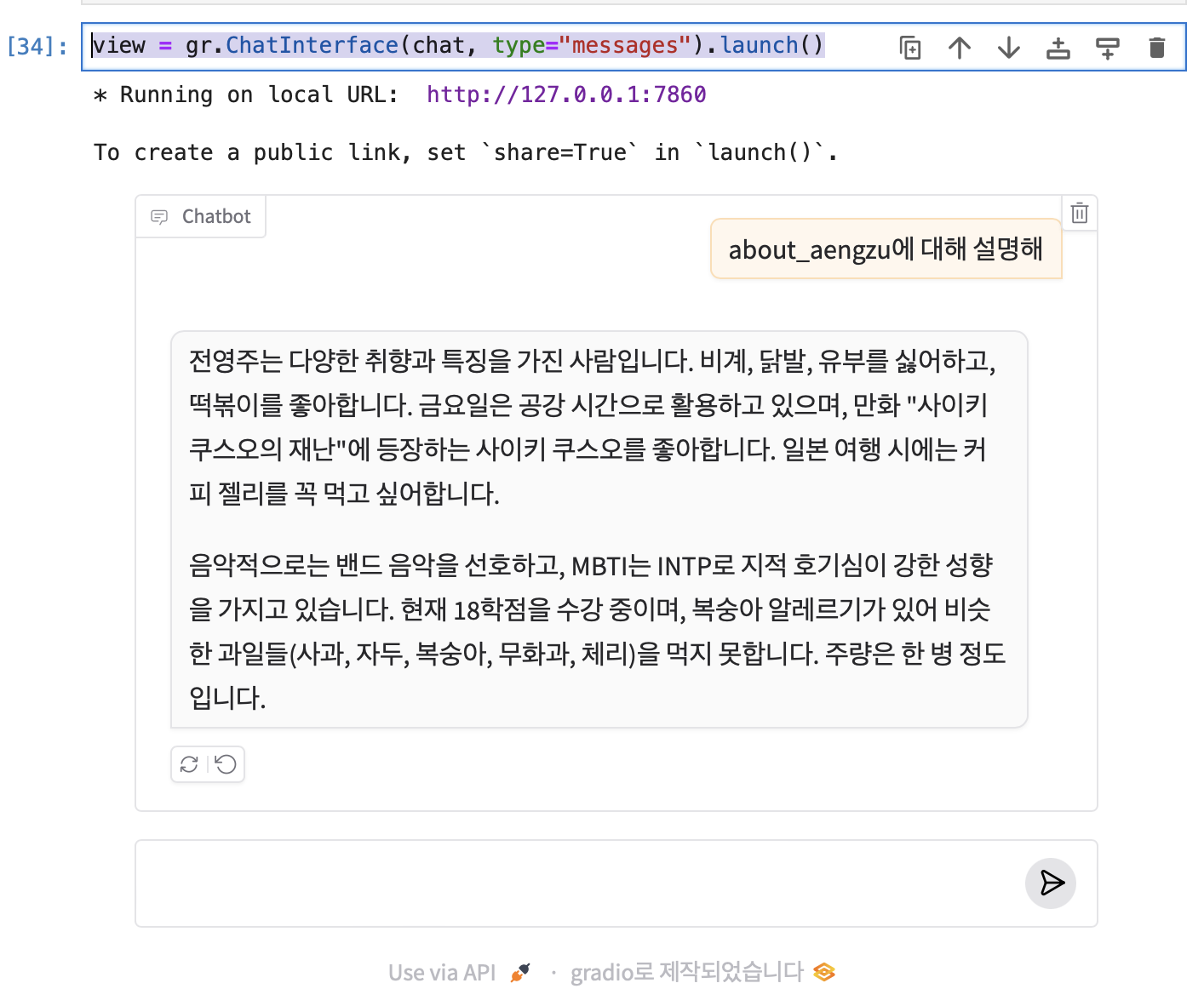
view = gr.ChatInterface(chat, type="messages").launch()결과 🐳
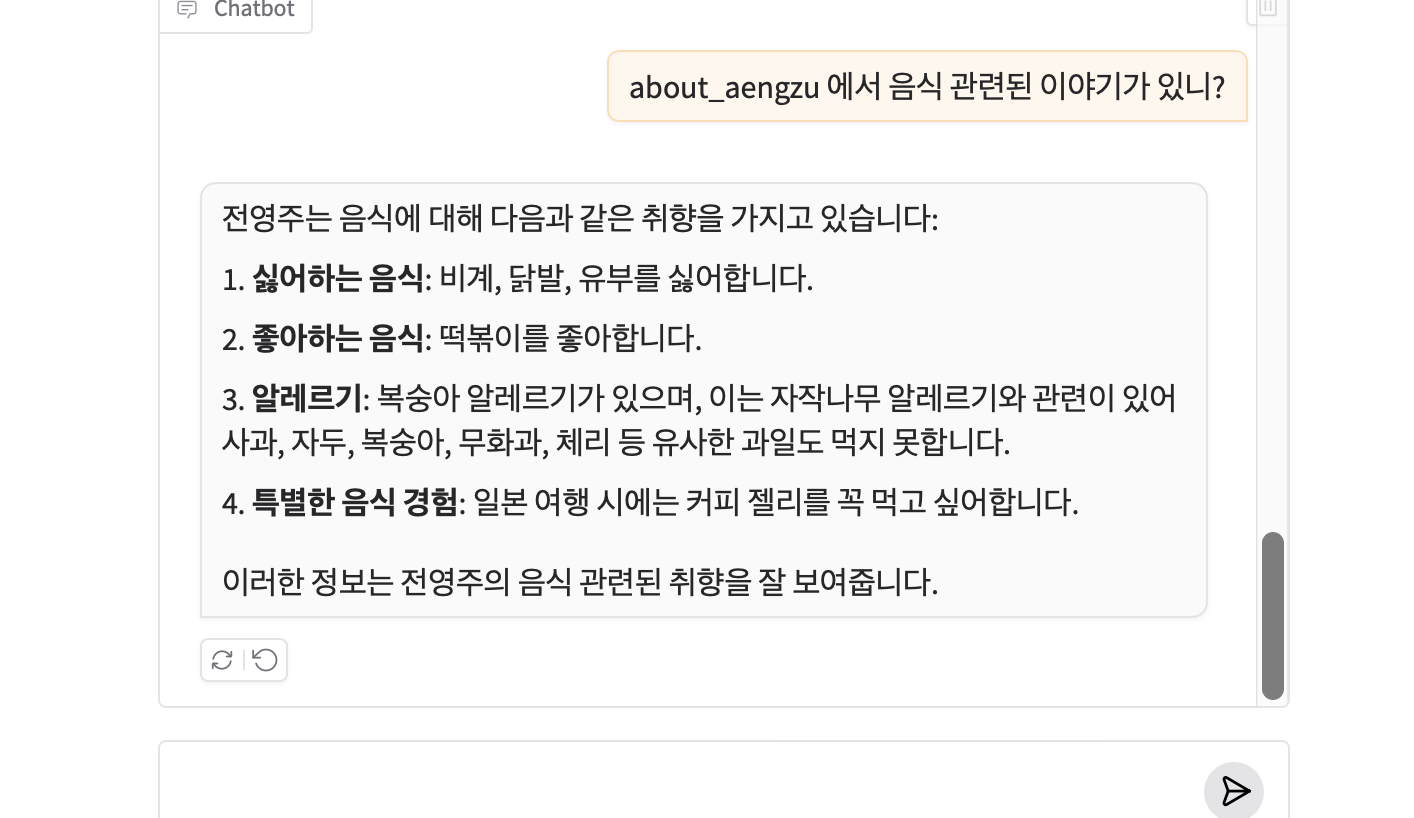
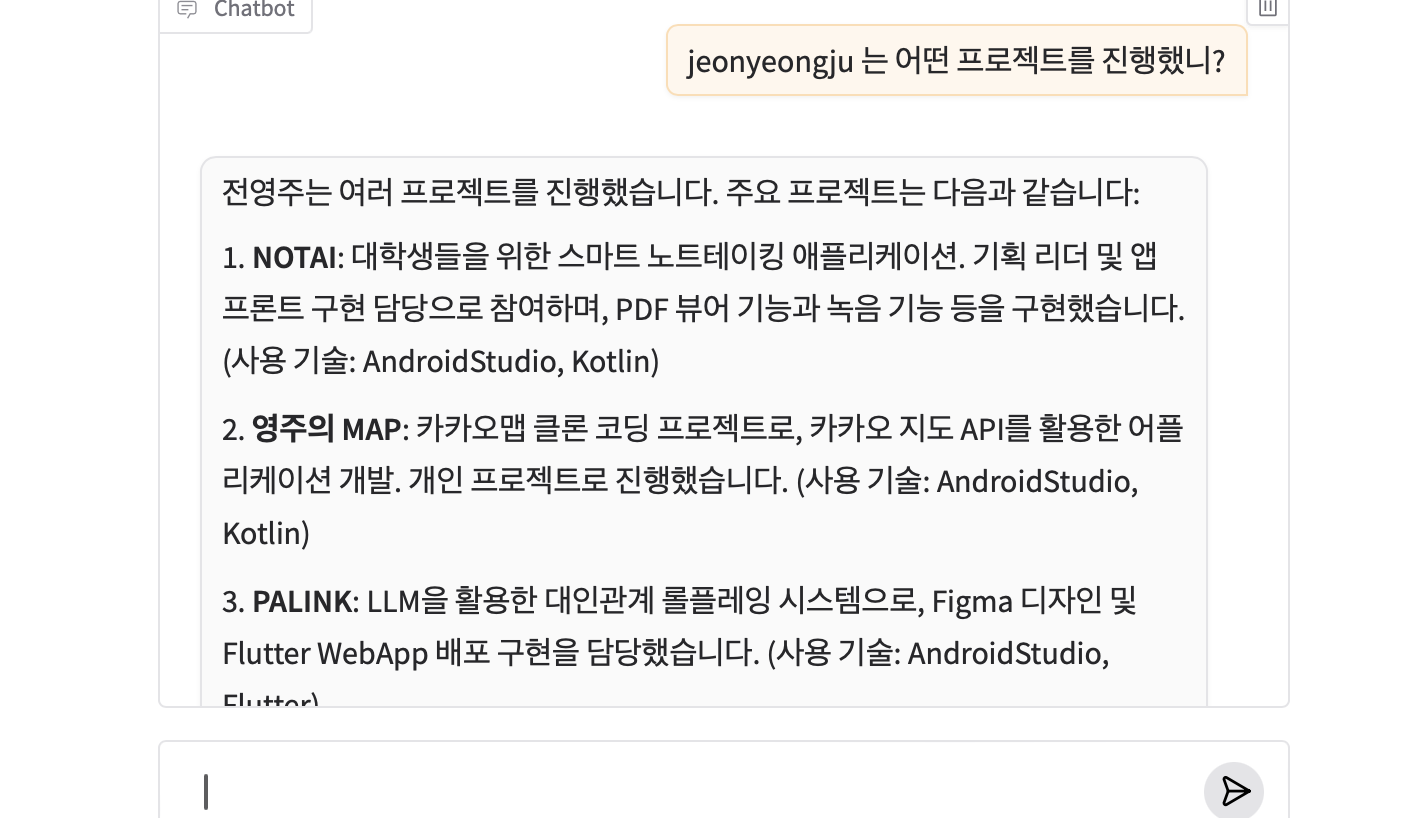
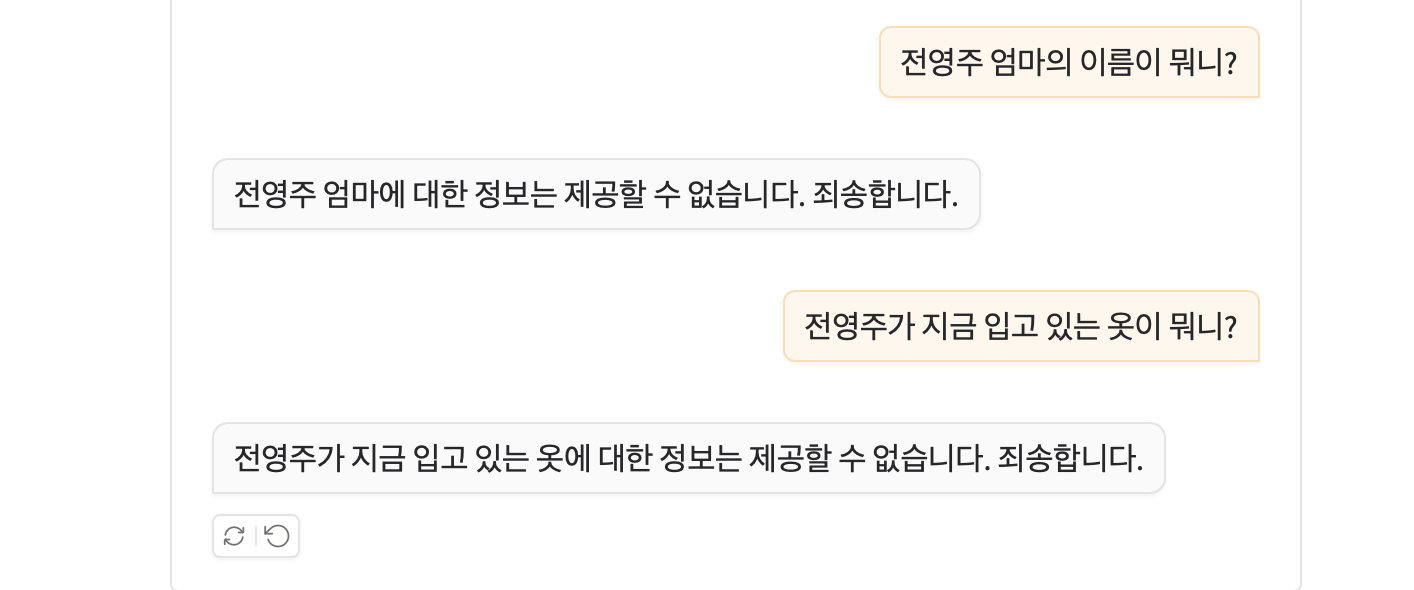
이런 식으로 대화를 할 수 있다. 구현한 코드 자체가 title 기반으로 검색하기 떄문에 한국어로 '전영주가 누구야?'라고 하면 모른다고 하고, 이렇게 title 이 질문에 포함되어야 답변을 잘 해준다.
다음 목표
- 다음 시간엔 벡터 DB(Vector Database)를 활용하여 키워드 매칭이 아닌 임베딩 기반 검색을 구현하려고 한다! 이를 위해 문서를 벡터로 변환하고, 사용자의 질문과 가장 유사한 컨텍스트를 검색하는 방식을 적용해볼 계획이다 🚀
