
작성에 앞서 해당 게시글은 공부하는 입장에서 작성한 내용으로 완전 초보입니다. 작성 내용에 오류가 있다면 알려주세요 🐳
🚀🚀
오늘은 RAG 연습 두 번째로 랭체인 패키지를 사용해서 문서를 청크 단위로 분리해서 간단한 검색 기능 실습을 해보려고 한다.
📂 더미데이터 생성
지난 실습에 이어 이번엔 이력서 더미 데이터들을 우선 GPT 를 통해 몇 개 생성했다.
이력서 뿐 아니라 produccts 와 company 에 대한 더미데이터도 생성하였다. 이러한 더미데이터는 해당 github의 더미데이터인데 나는 한국어로 번역하거나 일부 수정하여 가져왔다.
이런식으로 데이터를 모으면 준비가 끝났다.
지난 번에 만든 가상 환경을 가장 먼저 활성화해준다.
conda activate llms 의 명령어를 통해 활성화할 수 있다.

활성화가 된 상태에서 주피터 랩 명령어를 통해 jupyter lab을 켜준다.
이런 식으로 주피터 랩이 켜진 것을 확인할 수 있다. 주피터랩에서 rag_practice 라는 노트북 파일을 생성한다.
👩💻 코드 작성
1. 라이브러리 임포트 & 모델 정의
- 가장 먼저 라이브러리를 임포트한다.
# imports
import os # 운영 체제와 상호작용하기 위한 라이브러리로, 파일 경로나 환경 변수 등을 관리할 때 사용됩니다.
import glob # 특정 패턴에 맞는 파일 경로를 검색하는 데 사용되는 라이브러리입니다. 예: *.txt로 모든 텍스트 파일 찾기.
from dotenv import load_dotenv # .env 파일에 저장된 환경 변수(예: API 키)를 로드하여 Python 환경 변수로 설정하는 데 사용됩니다.
import gradio as gr # 머신러닝 모델 및 기타 Python 함수의 웹 인터페이스를 간단히 생성할 수 있는 라이브러리입니다.지난번 실습에서 변한 건 랭체인을 임포트 한다는 점이다
다음처럼 임포트 한다.
from langchain.document_loaders import DirectoryLoader, TextLoader
from langchain.text_splitter import CharacterTextSplitter그리고 모델과 db 명을 설정한다. 모델은 지난번처럼 gpt-4o-mini 를 사용하였고, 이번엔 벡터 db 를 사용하므로 다음처럼 db_name 을 vector_db 로 하였다.
MODEL = "gpt-4o-mini"
db_name = "vector_db"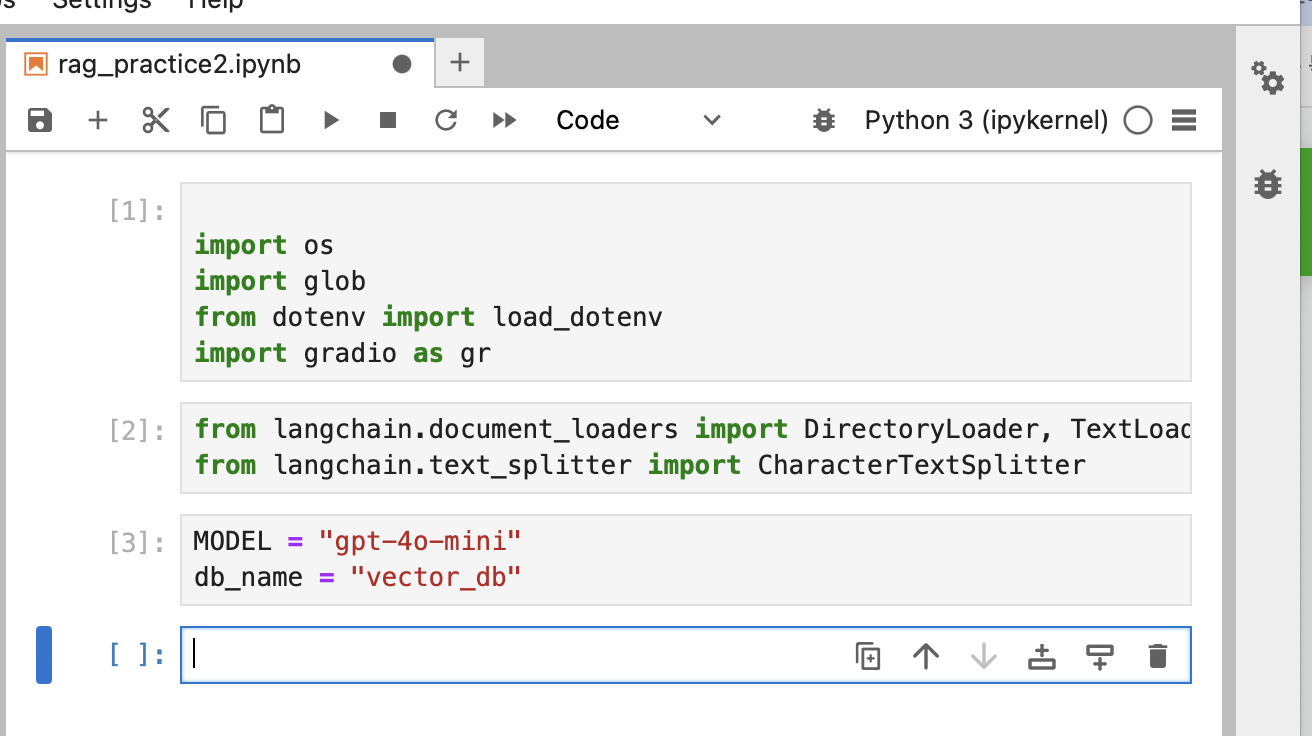
2. OPEN AI API 키 불러오기
이제 .env 에 적었던 키를 다음의 명령어로 불러온다.
load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_API_KEY', 'your-key-if-not-using-env')3. 메타데이터 붙이기
이제 (knowledge-base)의 하위 디렉토리들에서 .md 파일을 찾아 로드하고, 각 문서에 해당 폴더 이름을 doc_type 메타데이터로 추가하는 과정을 진행했다. 이렇게 처리된 모든 문서는 documents 리스트에 저장된다.
코드는 다음과 같다.
folders = glob.glob("knowledge-base/*")
# glob 사용해서 "knowledge-base" 디렉토리 내의 모든 하위 폴더를 검색하여 리스트로 반환
text_loader_kwargs = {'encoding': 'utf-8'}
# 텍스트 파일을 로드할 때 사용할 인코딩 설정
documents = []
# 최종적으로 모든 문서를 저장할 리스트
for folder in folders:
doc_type = os.path.basename(folder)
# 현재 폴더의 이름(폴더 경로에서 마지막 부분)을 가져와서 문서의 타입으로 저장함
loader = DirectoryLoader(
folder,
glob="**/*.md",
loader_cls=TextLoader,
loader_kwargs=text_loader_kwargs
)
# 현재 폴더에서 .md 파일을 로드하기 위해 DirectoryLoader 객체 생성
# **/*.md: 하위 디렉토리를 포함한 모든 .md 파일을 검색
# loader_cls: 파일 로더로 사용할 클래스 (여기서는 TextLoader 사용).
# loader_kwargs: 텍스트 로드 시 사용할 옵션 (예: UTF-8 인코딩 설정).
folder_docs = loader.load()
# 해당 폴더 내의 모든 .md 파일을 로드하여 리스트로 반환
for doc in folder_docs:
doc.metadata["doc_type"] = doc_type
# 각 문서의 메타데이터에 'doc_type' 속성 추가, 현재 폴더 이름을 값으로 설정
documents.append(doc)
# 문서를 documents 리스트에 추가
이러한 과정을 거치게 되면 다음의 출력처럼 metadata 에 doc_type 으로 폴더명이 추가된 것을 확인할 수 있다.

4. 문서를 청크로 나누기
이제 랭체인 패키지를 사용하여 문서를 작은 크기로 나눠 LLM에서 더 효율적으로 처리할 수 있게 하려 한다.
CharacterTextSplitter는 LangChain 라이브러리에서 제공하는 기능으로 문서를 각 청크의 최대 문자 수를 1000자로, 청크 간 겹치는 문자 수를 200자로 설정하여 청크로 분리하였다.
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
# 문서를 작은 조각(청크)으로 나누기 위해 CharacterTextSplitter 객체 생성
# - chunk_size: 각 청크의 최대 문자 수를 1000자로 설정
# - chunk_overlap: 청크 간에 겹치는 문자 수를 200자로 설정하여 문맥의 연속성을 유지함
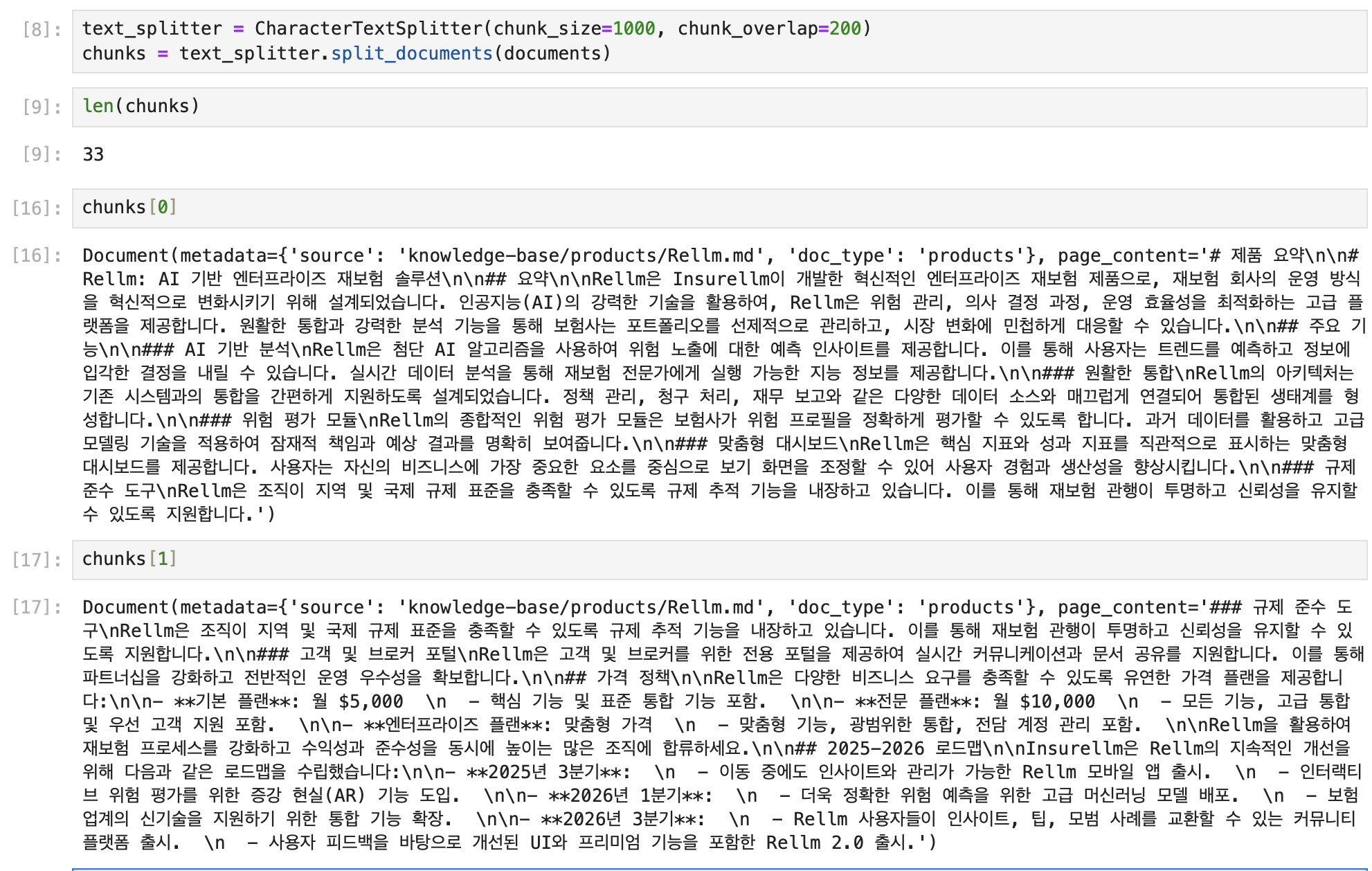
chunks = text_splitter.split_documents(documents)
# 앞서 로드한 `documents` 리스트를 CharacterTextSplitter로 분리하여 청크 단위로 나눔
# 결과는 `chunks` 리스트에 저장결과를 살펴보면 Rellm 이라는 제품이 하나의 파일이었는데 다음처럼 청크로 분리된 것을 확인할 수 있다.
5. 청크 단위 검색 기능 구현
이제 청크 단위로 특정 텍스트가 있다면 출력을 해보려고 한다.
chunk.page_content 는 각 청크의 텍스트 내용이 저장된 속성인데 이것 중 if ~ in chunk.page_content 를 통해 청크에 ~라는 텍스트가 있다면 해당 청크를 프린트할 수 있다.
예를 들어 '성과' 라는 단어가 들어간 청크를 알고 싶다면 다음처럼 코드를 작성하고 결과를 확인할 수 있다.
for chunk in chunks:
if '성과' in chunk.page_content:
print(chunk)
print("_________")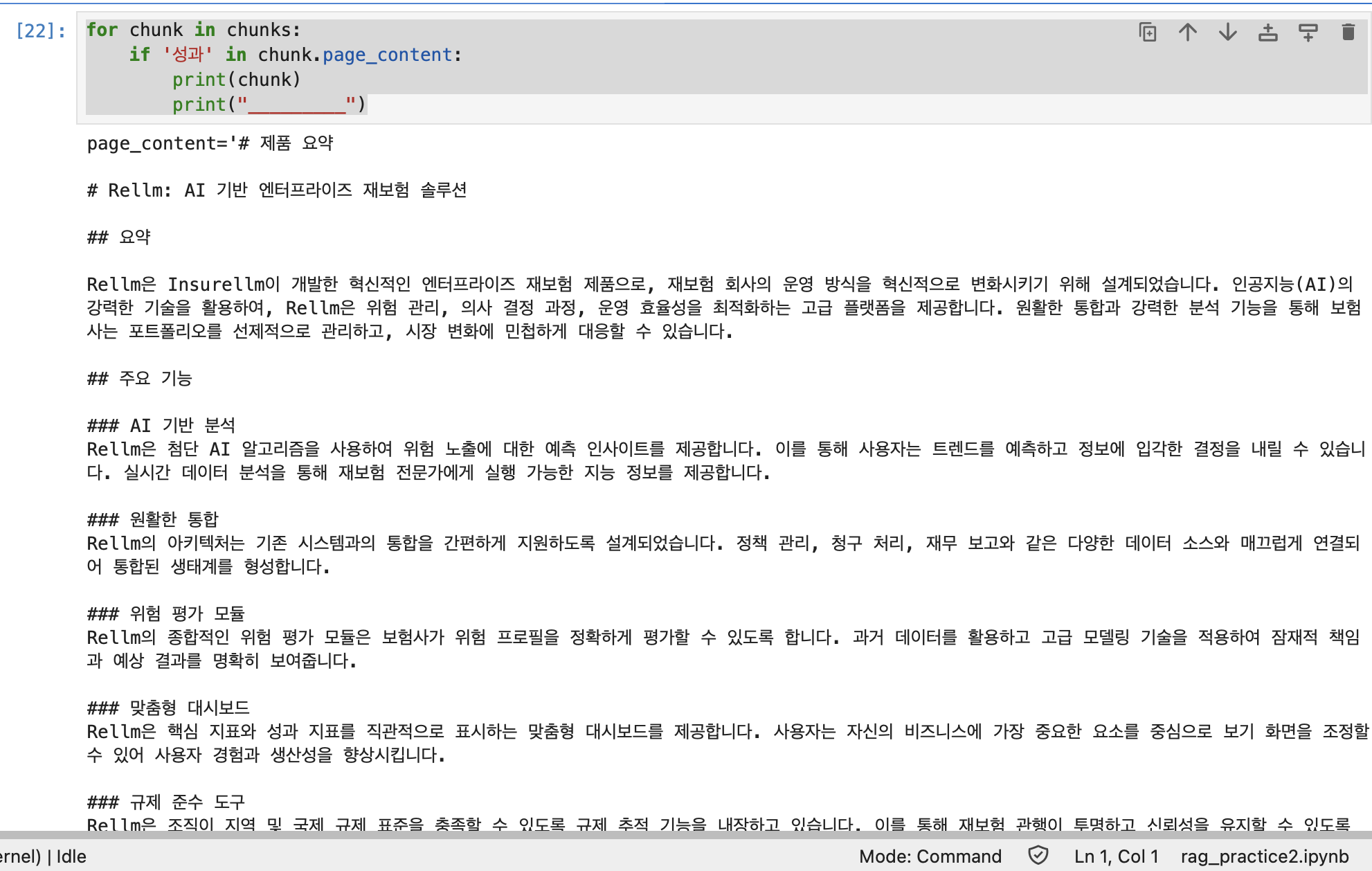
다음 목표
- 다음 시간엔 텍스트 임베딩을 실습해보려고 한다. 🚀🚀
