1. 도입
(1) 해결하고자 하는 문제점
- 논문은 학술공부를 하고자 하는 많은 분들이 필수로 읽어야 하는 기본 Context이다. 다만 읽어야 하는 대부분의 논문이 영어로 되어 있고, 한글로 작성된 논문도 읽기 쉽지 않은 상황에서 다른 언어로 작성된 논문을 읽는 것은 영어를 잘하는 사람에게도 쉬운 일은 아니다.
- 인공지능이 발달하며 기계번역은 매우 높은 성능을 가지고 있다. 다만 몇가지 문제점 때문에 기계번역(구글 translate, deepl)을 통해 번역된 논문의 가독성이 매우 떨어진다.
- 전문용어에 대한 무작위적인 직해. 현재 대부분의 기계번역은 해당분야의 전문용어를 고려하지 않고, 앞뒤 맥락만 고려해 번역하기 때문에 알아보기 힘든 경우가 많다. 고유 명사를 사용한 경우에는 덜하지만, 일반명사가 전문용어가 되어 있는 경우(예: transformer 구조, gradient descent 등) 특히 가독성을 해치는 경우가 발생한다.
- 구글 translate나 deepl의 경우 pdf문서를 입력받아 거기서 text를 추출한 후 번역하는 것으로 보인다. 그 과정에서 수학 수식이 깨치는 경우가 많으며, 이는 AI나 engineering계열 논문에서 치명적인 문제를 발생시키게 된다.
- 논문에 첨부된 이미지나 표의 경우 번역을 하지 않고, 그대로 첨부하는 것이 논문을 이해하는데 더 도움이 되는 경우가 많다. 대부분의 기계번역이 pdf로 부터 추출한 text를 그대로 번역하기에 이럴경우 내용에 오해가 생길수가 있다.
- 한 article을 마침표(.)를 기준으로 이어진 문장들의 연속된 글로 인식해야 하나 pdf에서 text를 추출할 때는 개행(줄바꿈)을 기준으로 별개의 문장으로 인식하는 경우가 있어 번역질을 떨어뜨리는 요인이 된다.
(2) 해결을 위한 기본아이디어
1) OCR
- 일단 논문을 제대로 이해하기 위해서는 논문구조 특히 이미지나 표의 위치가 애초 논문 저작자가 의도한 위치에 있으면서 논문 자체를 편집 가능한 형태의 문서로 인식하는 것이 중요하다. 특히 한문단으로 작성된 글을 정확히 ocr해주는 것이 중요하다. 또한 이미지와 표를 pdf로 다시 만들때 다시 이용가능하도록 구조화 해주는 것이 중요하다.
- 상기된 문제를 해결하기 위해 고려한것이, 많은 사람들이 논문작성시 latex를 통해 수식을 쓰고 있다는 사실이다. 이를 쉽게 인식하는 프로그램으로 mathpix를 떠올리게 되었고, 실제로 사용해보니 mathpix는 무서구조를 고려해서 ocr하고 있음을 알게되었다. 특히 pdf를 ocr해서 markdown으로 만들어주는 기능은 parsing을 쉽게 할 수 있다는 매우 큰 장점이 있음을 알게 되었다.
- 따라서 mathpix를 통해 문서 전체를 ocr하고 그를 통해 aritcle들을 차례로 불러와 번역을 진행한다.
2) 번역
- 번역에 있어서 가장 문제가 되는 것은 전문용어에 대한 처리와 수식에 대한 처리였다. 전문용어는 글을 읽는 사람이 해당 분야의 전문용어임을 알수 있도록 해야 했으며, 수식은 번역없이 그대로 출력해줘야 했다. 특히 문장속에 $$기호로 둘러쌓여 있는 수식에 대한 처리가 문제였다. 문장이 잘 진행되다가 이상한 기호의 연속이 나타나는 형태이기에 단순 기계번역에서는 번역질을 저하시키는 요인이 되는 것을 발견했다.
- LLM을 통해 번역을 진행해보니 openai의 GPT의 경우 latex 수식을 인식하는 것인지 모르겠지만, 이를 하나의 별개의 것으로 인식해서 문장을 번역하고 있음을 알게되었다. 결과적으로 gpt-3.5나 gpt-4의 경우 수식이 포함된 article도 수식과 함께 자연스런 번역을 하고 있음을 알게되었다.
- LLM을 통해 번역하는 것이 논문번역에 유리하다.
2. 작동구조
(1) OCR(mathpix api를 통한 ocr)
- ocr은 mathpix를 통해 이뤄진다.
- 가장먼저 mathpix에 문서를 업로드 한다. 문서를 업로드하면 api가 응답을 보내주는데 그 응답에 api에서 처리하고 있는 문서의 ID와 처리 상황을 respond한다. 아래의 함수는 문서를 업로드하고, respond를 반환한다.
def call_api(filename, headers):
options = {
"conversion_formats": {"md": True},
"math_inline_delimiters": ["$", "$"],
"rm_spaces": True,
"enable_tables_fallback": True,
}
r = requests.post(
"https://api.mathpix.com/v3/pdf",
headers=headers,
data={"options_json": json.dumps(options)},
files={"file": open("./pdf/" + filename + ".pdf", "rb")},
)
return r
- respond로 부터 문서 ID를 확인하다.
def get_pdf_id(response):
r = json.loads(response.text.encode("utf8"))
return r.get("pdf_id")- 문서ID로 ocr진행상황을 체크한 뒤에 완료되었을 경우 markdown파일을 다운받아 저장한다.
def make_md(pdf_id, headers):
start_time = time.time()
url_1 = "https://api.mathpix.com/v3/pdf/" + pdf_id
while time.time() - start_time < 120:
r = requests.get(url_1, headers=headers)
r = json.loads(r.text.encode("utf8"))
if r.get("status") == "completed":
print("OCR is done")
break
time.sleep(3)
print(r.get("status"))
url_2 = "https://api.mathpix.com/v3/pdf/" + pdf_id + ".md"
response = requests.get(url_2, headers=headers)
with open("./markdown/" + pdf_id + ".md", "w") as f:
f.write(response.text)(2) 번역(openai api를 통한 번역)
1) chunk 전략
-
보통 chunk라 하면 사람이 기억 할수 있는 단위를 말하지만 llm에서는 문장을 토큰단위로 자른 단위를 세는 단위로 쓰인다.
-
매끄러운 번역을 위해서, LLM이 맥락을 잘 파악 할 수 있도록 되도록이면 많은 문장을 넣어주고 한번에 결과를 받은것이 좋다. GPT-4의 경우 context 윈도우의 크기가 128,000 token이기 때문에 책이 아닌 이상, 대부분의 논문을 통으로 GPT-4에 넣을 수 있다 그렇지만 output max token은 4000개이므로 통번역은 사실상 어렵다.
-
또한 영어와 한글을 토큰 길이가 상이하기 때문에 최대값에 너무 근접시키면, 기본적으로 LLM은 자신의 max token 아래로 출려하려 하기 때문에 내용이 생략될 가능성이 높다.(실제로 그런 문제가 발생한다.)
-
chunk전략은 openai의 cookbook에서 가져왔다. 해당 링크는 다음과 같다. (https://cookbook.openai.com/examples/book_translation/translate_latex_book)
-
가장먼저 ocr한 markdown파일을 개행(\n\n, 즉 두번개행)을 기준으로 나누어 chunk를 만든뒤에 각chunk의 token개수를 계산하여 리스트로 반환한다.
-
이때 chunk를 나누는 기준을 한번개행(\n)으로 하지 않는 이유는 수식때문이다. 중앙정렬로 표시되는 별도의 수식은 아래와 같이 작성되기 때문에 한번개행을 기준으로 삼을 경우 수식이 깨져서 서로다른 chunk로 나뉘어질 가능성이 있다.
$$ m = \frac{m_0}{\sqrt{1-\frac{v^2}{c^2}}} $$ -
chunk작성 함수는 아래와 같다.
def make_chunks(pdf_id): print("Make chunk with Markdown file") with open("./markdown/" + pdf_id + ".md", "r") as f: text = f.read() tokenizer = tiktoken.encoding_for_model("gpt-4") chunks = text.split("\n\n") ntokens = [] for chunk in chunks: ntokens.append(len(tokenizer.encode(chunk))) return chunks, ntokens
-
-
각각 나뉘어진 chunk를 최대 토큰 기준으로 묶어서 chunk group으로 만든다 이는 model에 최대한 많은 글을 입력해줘서 자연스러운 번역이 가능하도록 하기 위함이다. cookbook의 작성자는 최대token을 1,000token을 제안했으나 실제로 적용해보니 1k token에서도 생략하는 내용이 종종 생겨서 좀더 줄여서 하게 된다.
def group_chunks(chunks, ntokens, max_len=600, hard_max_len=3000):
"""
Group very short chunks, to form approximately page long chunks.
"""
print("Grouping chunks")
batches = []
cur_batch = ""
cur_tokens = 0
# iterate over chunks, and group the short ones together
for chunk, ntoken in zip(chunks, ntokens):
# discard chunks that exceed hard max length
if ntoken > hard_max_len:
print(
f"Warning: Chunk discarded for being too long ({ntoken} tokens > {hard_max_len} token limit). Preview: '{chunk[:50]}...'"
)
continue
# if room in current batch, add new chunk
if cur_tokens + 1 + ntoken <= max_len:
cur_batch += "\n\n" + chunk
cur_tokens += 1 + ntoken # adds 1 token for the two newlines
# otherwise, record the batch and start a new one
else:
batches.append(cur_batch)
cur_batch = chunk
cur_tokens = ntoken
if cur_batch: # add the last batch if it's not empty
batches.append(cur_batch)
return batches2) Prompt 전략
- 번역에서 신경써야 할 점은 전문용어와 수식이다. 처음에는 gpt의 강력한 zero샷 성능을 이용하여 규칙을 넣어, prompt를 만들었다.
[{'role': 'system',
'content': 'You are an expert in the field of ai. You have the ability to explain the ai field easily, even to those who are not familiar with it.'},
{'role': 'system',
'content': '\nYou will translate English academic papers in the field of ai, which are written in Markdown, section by section into Korean.\n\nCondition 1: Translate the ai academic papers into an easy-to-understand style.\nCondition 2: For specialized terms related to the field, translate them in the format of Korean(English).\nCondition 3: Do not create any other responses, only generate the translation.\nCondition 4: Please Leave all Markdown or LaTeX commands unchanged.\nCondition 5: Translate quotations, examples, etc., enclosed in double quotes (“”), in the format of Korean(English).\n\n'}You are an expert in the field of ai. You have the ability to explain the ai field easily, even to those who are not familiar with it.
You will translate English academic papers in the field of ai, which are written in Markdown, section by section into Korean.
Condition 1: Translate the ai academic papers into an easy-to-understand style.
Condition 2: For specialized terms related to the field, translate them in the format of Korean(English).
Condition 3: Do not create any other responses, only generate the translation.
Condition 4: Please Leave all Markdown or LaTeX commands unchanged.
Condition 5: Translate quotations, examples, etc., enclosed in double quotes (“”), in the format of Korean(English).
- 이렇게 규칙만 줄 경우 규칙대로 번역하지 않는 경우가 종종있었고, 번역의 질이 일정하지 않았다. 때문에 번역예시를 영문 original과 함께 번역했다. 결과적으로 few shot형태로 prompt를 작성했다.
{'role': 'user',
'content': 'Translation Sample\n\n\n## 3 INTRODUCTION\n\nThe second misconception arises from implementing the dual averaging form of AdaGrad without considering what modifications need to be made for the deep learning setting. The algorithm as originally stated, uses an initial point of the origin $x_{0}=0$, and a proximity function $\\psi_{t}(x)=\x0crac{1}{2}\\left\\langle x, H_{t} x\right\rangle$ that is quadratic, but centered around the origin. It is well known that neural network training exhibits pathological behavior when initialized at the origin, and so naive use of this algorithm does not perform well. When centering around 0 , we have observed severely degraded empirical performance and a high risk of divergence. Instead, a proximity function centered about $x_{0}$ needs to be used:\n\n\n\n$$\nx_{k+1}=x_{0}-\\sum_{i=0}^{k} \\gamma_{i} g_{i}\n$$\n\n \n\n## 3 INTRODUCTION\n\n두 번째 오해는 AdaGrad의 이중 평균 형태(the dual averaging form)를 딥 러닝(deep learning) 환경에 맞게 수정해야 한다는 점을 고려하지 않고 구현하는 데서 비롯됩니다. 원래의 알고리즘은 원점 $x_0=0$에서 시작하고, 근접시 함수 $\\psi_t(x)=\x0crac{1}{2}\\left\\langle x, H_t x\right\rangle$를 사용하며, 이 함수는 이차 함수이지만 원점을 중심으로 합니다. 신경망 학습은 원점에서 초기화할 때 비정상적인 행동을 보인다는 것은 잘 알려져 있으며, 따라서 이 알고리즘을 순진하게 사용하면 성능이 좋지 않습니다. 0을 중심으로 할 때, 우리는 심각한 성능 저하와 발산의 위험을 관찰했습니다. 대신 $x_0$를 중심으로 한 근접 함수를 사용해야 합니다:\n\n\n\n$$\nx_{k+1}=x_{0}-\\sum_{i=0}^{k} \\gamma_{i} g_{i}\n$$\n\n'},
{'role': 'user',
'content': 'Based on the conditions and sample translation provided above, please translate the following English paper written in Markdown into Korean.\n'},
Translation Sample
## 3 INTRODUCTION
The second misconception arises from implementing the dual averaging form of AdaGrad without considering what modifications need to be made for the deep learning setting. The algorithm as originally stated, uses an initial point of the origin $x_{0}=0$, and a proximity function $\psi_{t}(x)=
rac{1}{2}\left\langle x, H_{t} x
ight
angle$ that is quadratic, but centered around the origin. It is well known that neural network training exhibits pathological behavior when initialized at the origin, and so naive use of this algorithm does not perform well. When centering around 0 , we have observed severely degraded empirical performance and a high risk of divergence. Instead, a proximity function centered about $x_{0}$ needs to be used:

$$
x_{k+1}=x_{0}-\sum_{i=0}^{k} \gamma_{i} g_{i}
$$## 3 INTRODUCTION
두 번째 오해는 AdaGrad의 이중 평균 형태(the dual averaging form)를 딥 러닝(deep learning) 환경에 맞게 수정해야 한다는 점을 고려하지 않고 구현하는 데서 비롯됩니다. 원래의 알고리즘은 원점 $x_0=0$에서 시작하고, 근접시 함수 $\psi_t(x)=
rac{1}{2}\left\langle x, H_t x
ight
angle$를 사용하며, 이 함수는 이차 함수이지만 원점을 중심으로 합니다. 신경망 학습은 원점에서 초기화할 때 비정상적인 행동을 보인다는 것은 잘 알려져 있으며, 따라서 이 알고리즘을 순진하게 사용하면 성능이 좋지 않습니다. 0을 중심으로 할 때, 우리는 심각한 성능 저하와 발산의 위험을 관찰했습니다. 대신 $x_0$를 중심으로 한 근접 함수를 사용해야 합니다:

$$
x_{k+1}=x_{0}-\sum_{i=0}^{k} \gamma_{i} g_{i}
$$- 최종 예시 prompt는 다음과 같다.
[{'role': 'system',
'content': 'You are an expert in the field of ai. You have the ability to explain the ai field easily, even to those who are not familiar with it.'},
{'role': 'system',
'content': '\nYou will translate English academic papers in the field of ai, which are written in Markdown, section by section into Korean.\n\nCondition 1: Translate the ai academic papers into an easy-to-understand style.\nCondition 2: For specialized terms related to the field, translate them in the format of Korean(English).\nCondition 3: Do not create any other responses, only generate the translation.\nCondition 4: Please Leave all Markdown or LaTeX commands unchanged.\nCondition 5: Translate quotations, examples, etc., enclosed in double quotes (“”), in the format of Korean(English).\n\n'},
{'role': 'user',
'content': 'Translation Sample\n\n\n## 3 INTRODUCTION\n\nThe second misconception arises from implementing the dual averaging form of AdaGrad without considering what modifications need to be made for the deep learning setting. The algorithm as originally stated, uses an initial point of the origin $x_{0}=0$, and a proximity function $\\psi_{t}(x)=\x0crac{1}{2}\\left\\langle x, H_{t} x\right\rangle$ that is quadratic, but centered around the origin. It is well known that neural network training exhibits pathological behavior when initialized at the origin, and so naive use of this algorithm does not perform well. When centering around 0 , we have observed severely degraded empirical performance and a high risk of divergence. Instead, a proximity function centered about $x_{0}$ needs to be used:\n\n\n\n$$\nx_{k+1}=x_{0}-\\sum_{i=0}^{k} \\gamma_{i} g_{i}\n$$\n\n \n\n## 3 INTRODUCTION\n\n두 번째 오해는 AdaGrad의 이중 평균 형태(the dual averaging form)를 딥 러닝(deep learning) 환경에 맞게 수정해야 한다는 점을 고려하지 않고 구현하는 데서 비롯됩니다. 원래의 알고리즘은 원점 $x_0=0$에서 시작하고, 근접시 함수 $\\psi_t(x)=\x0crac{1}{2}\\left\\langle x, H_t x\right\rangle$를 사용하며, 이 함수는 이차 함수이지만 원점을 중심으로 합니다. 신경망 학습은 원점에서 초기화할 때 비정상적인 행동을 보인다는 것은 잘 알려져 있으며, 따라서 이 알고리즘을 순진하게 사용하면 성능이 좋지 않습니다. 0을 중심으로 할 때, 우리는 심각한 성능 저하와 발산의 위험을 관찰했습니다. 대신 $x_0$를 중심으로 한 근접 함수를 사용해야 합니다:\n\n\n\n$$\nx_{k+1}=x_{0}-\\sum_{i=0}^{k} \\gamma_{i} g_{i}\n$$\n\n'},
{'role': 'user',
'content': 'Based on the conditions and sample translation provided above, please translate the following English paper written in Markdown into Korean.\n'},
{'role': 'user',
'content': "\n\n\nFigure 1: Number of search results on Google Scholar with different keywords by year 3\n\n\n\nFigure 2: Annual number of preprints posted under the cs.AI category on arXiv.org\n\n2) Analysis of the transformative effect of advanced generative AI systems on academic research, exploring how these developments are altering research methodologies, setting new trends, and potentially leading to the obsolescence of traditional approaches.\n3) Thorough assessment of the ethical, societal, and technical challenges arising from the integration of generative AI in academia, underscoring the crucial need for aligning these technologies with ethical norms, ensuring data privacy, and developing comprehensive governance frameworks.\n\nThe rest of this paper is organized as follows: Section III explores the historical development of Generative AI. Section III presents a taxonomy of current Generative AI research. Section IV explores the Mixture of Experts (MoE) model architecture, its innovative features, and its impact on transformer-based language models. Section $\\nabla$ discusses the speculated capabilities of the Q* project. Section VI] discusses the projected capabilities of AGI. Section VII examines the impact of recent advancements on the Generative AI research taxonomy. Section VIII identifies emerging research priorities in Generative AI. Section X discusses the academic challenges of the rapid surge of preprints in AI. The paper concludes in Section XI] summarizing the overall effects of these developments in generative AI.\n\n## II. Background: Evolution of Generative AI\n\nThe ascent of Generative AI has been marked by significant milestones, with each new model paving the way for the next evolutionary leap. From single-purpose algorithms to LLMs like OpenAI's ChatGPT and the latest multimodal systems, the AI landscape has been transformed, while countless other fields have been disrupted.\n\n## A. The Evolution of Language Models\n\nLanguage models have undergone a transformative journey (Fig. 3), evolving from rudimentary statistical methods to the\n\n$\\left\\{\\right.$| 1980s: Statistical Models (n-grams) |\n| :--- |\n| 1990s: Adoption in NLP, n-gram Usage |\n| 1997: Introduction of LSTMs |\n| 2000s: LSTMs in Text/Voice Processing |\n\nFigure 3: Timeline of Key Developments in Language Model Evolution\n\n"}]- 위의 내용을 토대로 prompt를 만들어서 모델에 넣고 결과를 받아 하나씩 합쳐다시 markdown파일로 만든다. 이와 관련한 코드는 아래와 같다. 일정한 번역결과를 위해 모델의 하이퍼파라미터중 temperature는 낮게(0.1) 잡는다.
def make_prompts(paper_field, tr_example_orgin, tr_example_trans, text):
prompt = [
{
"role": "system",
"content": f"You are an expert in the field of {paper_field}. You have the ability to explain the {paper_field} field easily, even to those who are not familiar with it.",
},
{
"role": "system",
"content": f"""
You will translate English academic papers in the field of {paper_field}, which are written in Markdown, section by section into Korean.
Condition 1: Translate the {paper_field} academic papers into an easy-to-understand style.
Condition 2: For specialized terms related to the field, translate them in the format of Korean(English).
Condition 3: Do not create any other responses, only generate the translation.
Condition 4: Please Leave all Markdown or LaTeX commands unchanged.
Condition 5: Translate quotations, examples, etc., enclosed in double quotes (“”), in the format of Korean(English).
""",
},
{
"role": "user",
"content": f"""Translation Sample
{tr_example_orgin}
{tr_example_trans}
""",
},
{
"role": "user",
"content": f"""Based on the conditions and sample translation provided above, please translate the following English paper written in Markdown into Korean.
""",
},
{
"role": "user",
"content": f"""
{text}
""",
},
]
return prompt
def tranlate_content(prompts):
completion = client.chat.completions.create(
model="gpt-4-1106-preview", messages=prompts, temperature=0.1
)
return completion.choices[0].message.content
def make_translated_markdown(chunks, file_name, paper_field):
print("Translating")
translated_content = []
for chunk in tqdm(chunks):
prompt = make_prompts(paper_field, tr_example_orgin, tr_example_trans, chunk)
tranlated = tranlate_content(prompt) + "\n\n"
translated_content.append(tranlated)
print("Make Translated Markdown")
with open("./markdown/translated_" + file_name + ".md", "w") as file:
for line in translated_content:
file.write(line)3. 문제현상
(1) 번역관련(prompt 문제 가능성 높음)
-
특정 chunk group에서 번역 할때 이미지link를 생략하거나 내용을 생략하는 문제가 발생한다. 재미있는 점은 gpt-4는 생략하고, gpt-3.5는 생략하지 않는다. 그러나 gpt-3.5는 전문용어를 처리함에 있어서 condition으로 제공한 규칙을 따르지 않는 듯한 경향을 보인다.
-
GPT-4 번역
그림 1: 연도별로 다른 키워드로 Google Scholar에서 검색된 결과의 수 3
그림 2: arXiv.org의 cs.AI 카테고리에 게시된 연간 프리프린트(preprints) 수
2) 학술 연구에 대한 고급 생성 AI 시스템의 변혁적인 영향 분석, 이러한 발전이 연구 방법론을 어떻게 변화시키고, 새로운 트렌드를 설정하며, 전통적인 접근법을 구식으로 만들 가능성을 탐구합니다.
3) 학계에서 생성 AI의 통합으로 발생하는 윤리적, 사회적, 기술적 도전 과제에 대한 철저한 평가, 이러한 기술을 윤리적 규범과 일치시키는 중요성을 강조하고, 데이터 프라이버시를 보장하며, 포괄적인 거버넌스 프레임워크를 개발할 필요성을 강조합니다.
이 논문의 나머지 부분은 다음과 같이 구성됩니다: 섹션 III에서는 생성 AI의 역사적 발전을 탐구합니다. 섹션 III에서는 현재 생성 AI 연구의 분류를 제시합니다. 섹션 IV에서는 전문가의 혼합(Mixture of Experts, MoE) 모델 아키텍처, 그 혁신적인 특징들, 그리고 변환기 기반 언어 모델에 미치는 영향을 탐구합니다. 섹션 $\nabla$에서는 Q* 프로젝트의 추측된 능력에 대해 논의합니다. 섹션 VI]에서는 AGI의 예상 능력에 대해 논의합니다. 섹션 VII에서는 최근의 발전이 생성 AI 연구 분류에 미치는 영향을 검토합니다. 섹션 VIII에서는 생성 AI에서 나타나는 새로운 연구 우선순위를 식별합니다. 섹션 X에서는 AI에서 프리프린트의 급격한 증가로 인한 학술적 도전을 논의합니다. 논문은 섹션 XI]에서 생성 AI의 이러한 발전의 전반적인 영향을 요약하며 마무리됩니다.
## II. 배경: 생성 AI의 진화
생성 AI의 상승은 중요한 이정표들로 표시되었으며, 각각의 새로운 모델은 다음 진화적 도약을 위한 길을 닦았습니다. 단일 목적 알고리즘에서 OpenAI의 ChatGPT와 같은 대규모 언어 모델(LLMs)에 이르기까지, 최신의 다중 모달 시스템까지, AI 분야는 변모되었으며, 수많은 다른 분야들도 혼란에 빠졌습니다.
## A. 언어 모델의 진화
언어 모델은 변혁적인 여정을 거쳤으며(그림 3), 기초적인 통계 방법에서부터
$\left\{\right.$| 1980년대: 통계 모델(n-grams) |
| :--- |
| 1990년대: NLP에서의 채택, n-gram 사용 |
| 1997년: LSTM의 도입 |
| 2000년대: 텍스트/음성 처리에서의 LSTM 사용 |
그림 3: 언어 모델 진화의 주요 발전 타임라인- GPT-3.5 번역

그림 1: 연도별로 다른 키워드로 Google Scholar에서 검색 결과 수

그림 2: arXiv.org의 cs.AI 범주에 게시된 논문의 연간 사전 인쇄물 수
2) 고급 생성 AI 시스템이 학술 연구에 미치는 변형적 영향을 분석하여, 이러한 발전이 연구 방법론을 변경하고 새로운 트렌드를 설정하며 전통적인 접근 방식의 구식화로 이어질 가능성을 탐구합니다.
3) 학계에 생성 AI를 통합함으로써 발생하는 윤리적, 사회적 및 기술적 도전에 대한 철저한 평가를 통해, 이러한 기술을 윤리적 규범에 부합시키고 데이터 개인 정보 보호를 보장하며 포괄적인 지배 구조를 개발하는 중요성을 강조합니다.
본 논문의 나머지 부분은 다음과 같이 구성되어 있습니다: 섹션 III에서는 생성 AI의 역사적 발전을 탐구합니다. 섹션 IV에서는 현재 생성 AI 연구의 분류 체계를 제시합니다. 섹션 IV에서는 MoE(Mixture of Experts) 모델 아키텍처, 그의 혁신적인 특징 및 트랜스포머 기반 언어 모델에 미치는 영향을 탐구합니다. 섹션 $\nabla$에서는 Q* 프로젝트의 추정 능력을 논의합니다. 섹션 VI]에서는 AGI의 예상 능력을 논의합니다. 섹션 VII에서는 최근 발전이 생성 AI 연구 분류 체계에 미치는 영향을 검토합니다. 섹션 VIII에서는 생성 AI에서 신흥 연구 우선 순위를 식별합니다. 섹션 X에서는 AI의 사전 인쇄물 급증에 따른 학술적 도전을 논의합니다. 논문은 섹션 XI]에서 생성 AI의 이러한 발전의 전반적인 영향을 요약하며 마무리됩니다.
## II. 배경: 생성 AI의 진화
생성 AI의 부상은 각 새로운 모델이 다음 진화적 도약을 열어가며 중요한 이정표로 표시되었습니다. 단일 목적 알고리즘부터 OpenAI의 ChatGPT와 최신 다중 모달 시스템과 같은 LLMs까지, AI 분야는 변화되었으며, 무수히 많은 다른 분야도 혼란스러워졌습니다.
## A. 언어 모델의 진화
언어 모델은 변형적인 여정을 거쳤습니다 (그림 3), 초기의 통계적 방법에서부터
$\left\{\right.$| 1980년대: 통계 모델 (n-gram) |
| :--- |
| 1990년대: NLP에서의 채택, n-gram 사용 |
| 1997년: LSTM 도입 |
| 2000년대: 텍스트/음성 처리에서의 LSTM |
그림 3: 언어 모델 진화의 주요 발전 사항 타임라인(2) OCR관련
1) 표 OCR
-
표를 OCR하는 과정에서 markdown형식으로 변화하다보니 번역후 pdf로 만들면 가독성이 매우 떨어지는 경우가 생긴다.
-
마크다운으로 만들어진 표
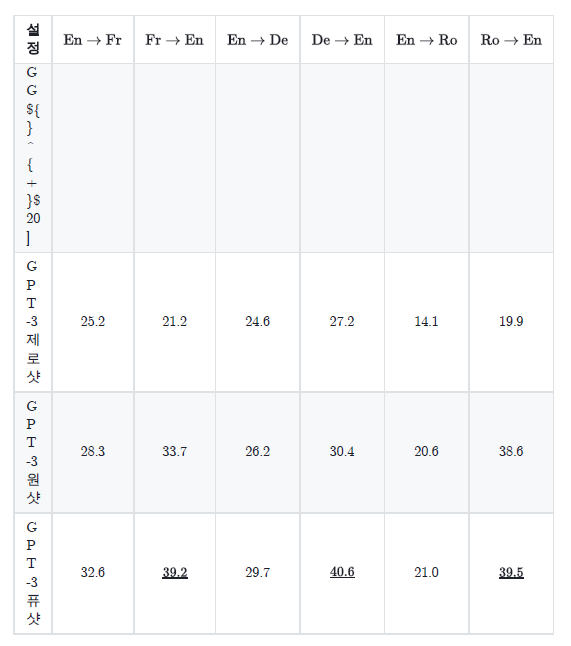
-
원본 표
-
이에 관한 예시 해결책으로 현재는 markdown to pdf를 mathpix의 app을 사용중이나 다른 어플리케이션을 통해 설정을 조정해서 해결 할 수도 있고, 다른 ocr을 통해 좀더 정돈된 ocr을 시도해도 좋을 듯 하다.
- Latex형식으로 변환한뒤에 Latex를 번역하는 방법도 고민할 필요가 있다. 다만 현재까지 짧은 시도록 파이썬에서 Latex의 변환에 조금 어려움이 있는 듯 하다.
- Latex로 번역을 진행할 경으 parsing 방법에 대한 전반적인 재고려가 필요하다.
4. 발전방향
(1) Trouble Shooting
- 앞서 문제현상에서 밝힌 문제들을 해결하는 것이다.
- prompt 전략, chunk 전략 모두 검토가 필요한 부분이다.
- OCR관련해서도 상기한 여러 해결책을 모두 검토해 볼 필요가 있다.
(2) End-to-End pipeline 완성
- 본래 목적은 pdf를 넣으면 번역해서 번역된 pdf파일을 바로 얻을 수 있도록 하는 것이었다.
- mathpix의 local용 application의 경우 인스톨과정에서 dependency문제가 발생하고 있다. Node.js로 만들어진 프로그램이라 파이썬 Node.js가상환경에서 설치하는 경우 발생하는 문제이다.
- 다른 open-source markdown-to-pdf 코드를 고려해 볼 필요가 있다.
(3) 번역의 질 문제
- 좀더 나은 번역을 위해 먼저 번역했던 내용을 context로 제공하는 것에 대해 고민해볼 필요가 있다. 앞에서 번역한 chunk group을 context로 제공하면 번역의 질이 좋아지긴 하겠지만 얼마나 좋아 질지가 문제이다. 왜냐하면 한 chunk group을 번역할때 들어가는 token의 수가 많아 지기 때문에 비용이 더 발생한다. 금액과 성능의 상관관계와 함께 논의해볼 필요가 있다.
(4) Token 효율화
- 현재 한 논문을 번역할때 openai 비용만 2달러가량 발생한다. 이 부분을 줄이기 위해 좀더 token을 줄일 방법에 대한 고민이 필요하다.
(5) Open Source LLM탐색
- 더 비용을 절약하기 위해 Open source llm을 이용하는 방안을 고민해볼 필요가 있다. 한국어 llm을 탐색해보기 위한 좋은 수단이 될 수도 있다.
- 구글의 jemini나, 네이버 Hyper X의 가능성도 탐색해볼 필요가 있다.
(6) Gui
- 지금을 터미널 명령어로 작동하지만, 접근성을 위해 GUI를 이용한다. streamlit이나 gradio가 적절해 보인다.
