Deep learning에 관해 몇몇 학습에 도움이 되고자 하는 글을 번역하려 합니다.
- 이 글은 clova hyperX로 번역되었습니다.
- 논문 번역은 chatGPT로 하고 있으니 정성적인 번역 성능 비교도 될수 있지만, 클로바x로는 별다른 Prompt를 사용하지 않고 번역만 요청했습니다.
- 첫글은 clova로 진행했으나 api가 아닌 챗봇 상에서 few-shot 형태의 추론이 잘 이뤄지지 않은 것 같아서 이후에는 chatGPT로 진행할 예정입니다.
- 원글은 PyTorch Blog의 Understanding GPU Memory 1: Visualizing All Allocations over Time입니다.
- 링크는 다음과 같습니다: https://pytorch.org/blog/understanding-gpu-memory-1/
Understanding GPU Memory 2: Finding and Removing Reference Cycles
이것은 GPU 메모리 이해(Understanding GPU Memory) 블로그 시리즈의 2부입니다. 첫 번째 게시물 'GPU 메모리 1 이해: 시간에 따른 모든 할당 시각화(Understanding GPU Memory 1: Visualizing All Allocations over Time)'는 메모리 스냅샷 도구(Memory Snapshot tool) 사용 방법을 보여줍니다. 이번 파트에서는, 메모리 스냅샷(Memory Snapshot)을 사용하여 참조 사이클(reference cycles)에 의해 발생하는 GPU 메모리 누수를 시각화하고, 참조 사이클 탐지기(Reference Cycle Detector)를 사용하여 코드에서 이를 찾아내고 제거하는 방법을 다룰 것입니다.
가끔 메모리 스냅샷을 사용할 때, 이와 유사하게 보이는 GPU 메모리의 그래프를 보았습니다.
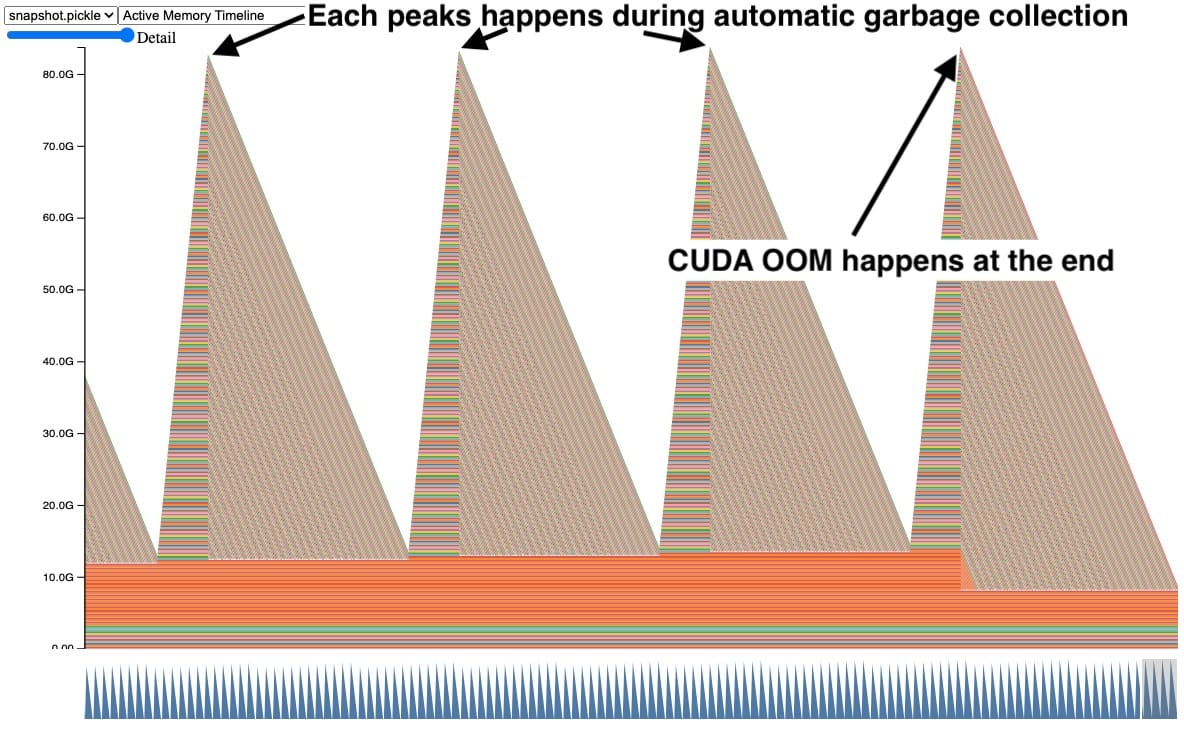
이 스냅샷에서, 각 피크는 시간이 지남에 따라 GPU 텐서들이 쌓이고, 그 후에 여러 텐서들이 한 번에 해제되는 것을 보여줍니다. 또한, 오른쪽에서 CUDA OOM(Out of Memory)이 발생하여 모든 텐서들이 해제됩니다. 이렇게 텐서들이 쌓이는 것을 보는 것은 문제의 명확한 징후이지만, 즉시 왜 그런지를 제안하지는 않습니다.
참조 사이클(Reference Cycles)에 있는 텐서들
초기 디버깅 과정에서, 우리는 이 **패턴이 Python 코드에 참조 사이클을 가진 객체들이 있을 때 자주 발생한다는 것을 알게 되었습니다.** Python은 참조 카운팅을 사용하여 비순환 객체들을 즉시 정리합니다. 하지만 참조 사이클에 있는 객체들은 나중에 사이클 수집기에 의해 정리됩니다. 만약 이 사이클들이 GPU 텐서를 참조한다면, GPU 텐서는 그 사이클 수집기가 실행되어 참조 사이클을 제거할 때까지 살아있게 됩니다. 간단한 예를 살펴봅시다.
Code Snippet behind the snapshot (full code in Appendix A):
def leak(tensor_size, num_iter=100000, device="cuda:0"):
class Node:
def __init__(self, T):
self.tensor = T
self.link = None
for _ in range(num_iter):
A = torch.zeros(tensor_size, device=device)
B = torch.zeros(tensor_size, device=device)
a, b = Node(A), Node(B)
# A reference cycle will force refcounts to be non-zero.
a.link, b.link = b, a
# Python will eventually garbage collect a & b, but will
# OOM on the GPU before that happens (since python
# runtime doesn't know about CUDA memory usage).이 코드 예제에서, 텐서 A와 B가 생성되는데, A는 B에 대한 링크를 가지고 있고 그 반대의 경우도 마찬가지입니다. 이것은 A와 B가 스코프를 벗어날 때 비 0 참조 카운트(non-zero reference count)를 강제합니다. 100,000회의 반복으로 이것을 실행할 때, 자동 쓰레기 수집이 스코프를 벗어날 때 참조 사이클을 해제할 것으로 기대합니다. 그러나, 이것은 실제로 CUDA OOM을 일으킬 것입니다.
왜 자동 쓰레기 수집이 작동하지 않을까요?
자동 쓰레기 수집은 CPU에서 흔한 많은 여분의 메모리가 있을 때 잘 작동합니다. 왜냐하면, 세대 쓰레기 수집(Generational Garbage Collection)을 사용하여 비싼 쓰레기 수집 비용을 분산시키기 때문입니다. 그러나 수집 작업을 분산시키기 위해 일부 메모리 정리를 연기함으로써 최대 메모리 사용량이 더 높아지는데, 이는 메모리 제한 환경에는 덜 적합합니다. Python 런타임도 CUDA 메모리 사용에 대한 통찰력이 없어서 높은 메모리 압박에도 트리거되지 않습니다. GPU 트레이닝은 거의 항상 메모리 제약 조건이 있기 때문에 더 어렵습니다. 왜냐하면 추가적인 여유 메모리를 사용하기 위해 종종 배치 크기를 늘리기 때문입니다.
CPython의 쓰레기 수집은 마크 앤 스윕(mark-and-sweep)을 통해 참조 사이클에서 도달할 수 없는 객체를 해제합니다. 쓰레기 수집은 객체 수가 특정 임계값을 초과할 때 자동으로 실행됩니다. 모든 객체에 대해 쓰레기 수집을 실행하는 비싼 비용을 분산시키기 위해 3세대의 임계값이 있습니다. 나중 세대는 덜 자주 실행됩니다. 이것이 자동 수집이 각 피크마다 여러 텐서를 해제할 수 있지만, 여전히 누출되어 CUDA OOM을 일으키는 텐서가 있음을 설명합니다. 이러한 텐서들은 나중 세대의 참조 사이클에 의해 보유되었습니다.
명시적으로 GC.COLLECT() 호출하기
이를 해결하는 한 가지 방법은 쓰레기 수집기를 자주 명시적으로 호출하는 것입니다. 여기에서 우리는 100번의 반복마다 쓰레기 수집기를 명시적으로 호출할 때 스코프를 벗어난 텐서의 GPU 메모리가 정리되는 것을 볼 수 있습니다. 이것은 또한 누출된 텐서들에 의해 보유된 최대 GPU 피크 메모리를 제어합니다.
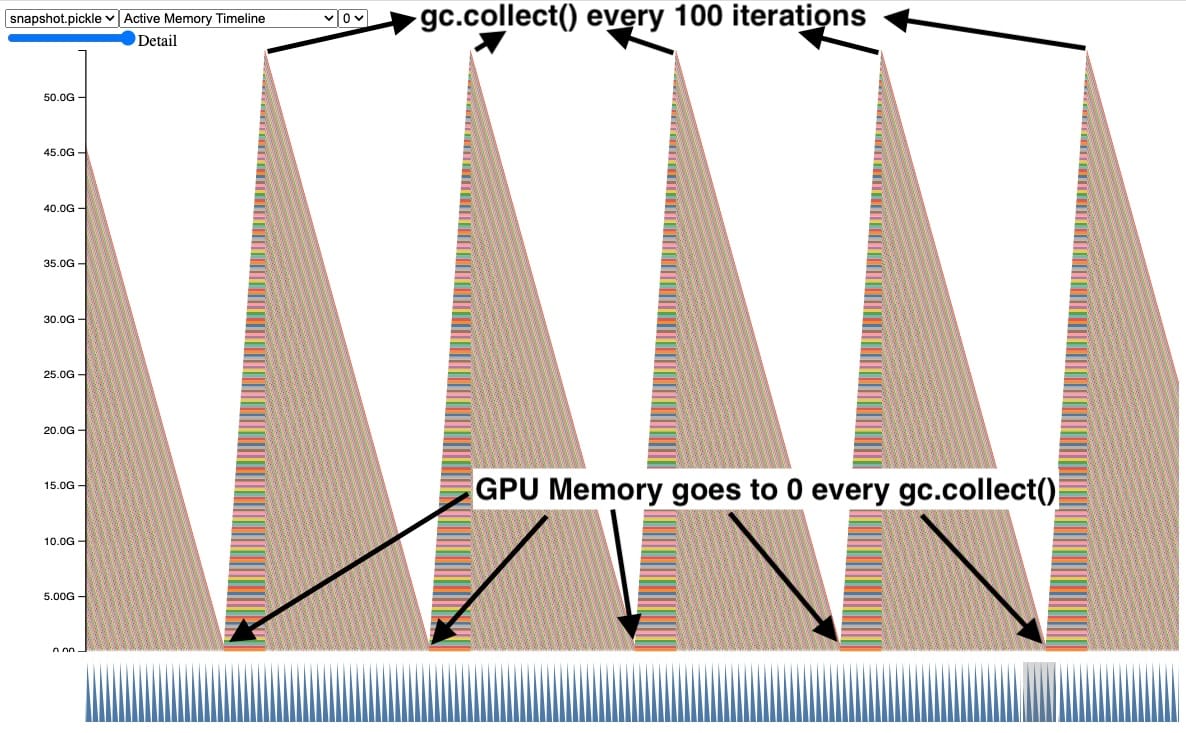
이 방법은 작동하여 CUDA OOM 문제를 해결하지만, gc.collect()를 너무 자주 호출하면 QPS(Quality of Service) 회귀와 같은 다른 문제를 일으킬 수 있습니다. 따라서 우리는 모든 트레이닝 작업에서 쓰레기 수집 빈도를 단순히 늘릴 수 없습니다. 참조 사이클을 처음부터 만들지 않는 것이 가장 좋습니다. 이에 대한 자세한 내용은 '참조 사이클 탐지기(Reference Cycle Detector)' 섹션에서 다룹니다.
콜백에서의 교묘한 메모리 누수(SNEAKY MEMORY LEAK IN CALLBACK)
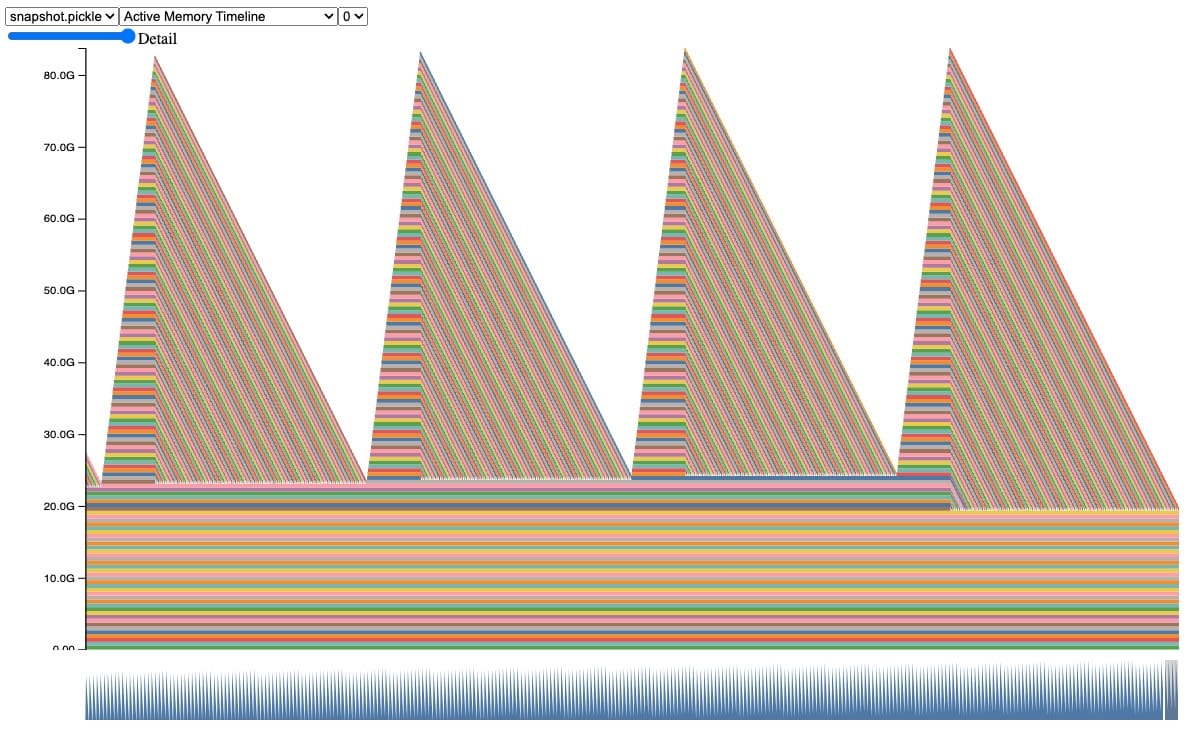
실제 예시는 더 복잡하기 때문에, 유사한 행동을 보이는 더 현실적인 예를 살펴보겠습니다. 이 스냅샷에서, 자동 쓰레기 수집 동안 텐서들이 축적되고 해제되는 동일한 행동을 관찰할 수 있습니다, CUDA OOM에 도달할 때까지.
Code Snippet behind this snapshot (full code sample in Appendix A):
class AwaitableTensor:
def __init__(self, tensor_size):
self._tensor_size = tensor_size
self._tensor = None
def wait(self):
self._tensor = torch.zeros(self._tensor_size, device="cuda:0")
return self._tensor
class AwaitableTensorWithViewCallback:
def __init__(self, tensor_awaitable, view_dim):
self._tensor_awaitable = tensor_awaitable
self._view_dim = view_dim
# Add a view filter callback to the tensor.
self._callback = lambda ret: ret.view(-1, self._view_dim)
def wait(self):
return self._callback(self._tensor_awaitable.wait())
async def awaitable_leak(
tensor_size=2**27, num_iter=100000,
):
for _ in range(num_iter):
A = AwaitableTensor(tensor_size)
AwaitableTensorWithViewCallBack(A, 4).wait()이 코드에서, 우리는 두 개의 클래스를 정의합니다. AwaitableTensor 클래스는 대기 상태에서 텐서를 생성합니다. 다른 클래스인 AwaitableTensorWithViewCallback은 콜백 람다를 통해 AwaitableTensor에 뷰 필터를 적용합니다.
awaitable_leak을 실행할 때, 텐서 A(512MB)를 생성하고 100,000회 반복하여 뷰 필터를 적용하는데, A는 스코프를 벗어날 때마다 참조 카운트가 0에 도달해야 하므로 회수되어야 합니다. 그러나, 이것은 실제로 OOM을 일으킬 것입니다!
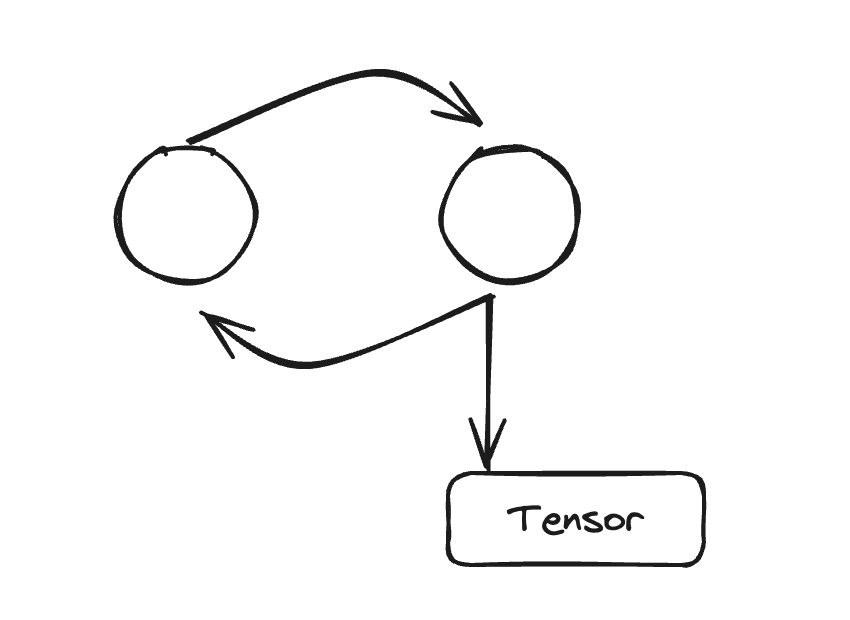
여기서 참조 사이클이 있다는 것을 알고 있지만, 코드에서 사이클이 어디서 생성되는지 명확하지 않습니다. 이러한 상황을 돕기 위해, 우리는 이러한 사이클을 찾아내고 보고하는 도구를 만들었습니다.
참조 사이클 탐지기(REFERENCE CYCLE DETECTOR)
GPU 텐서를 살아있게 유지하는 참조 사이클을 찾는 데 도움이 되는 참조 사이클 탐지기를 소개합니다. API는 상당히 간단합니다:
- 모델 초기화 과정중:
- Import:
from torch.utils.viz._cycles import warn_tensor_cycles - Start:
warn_tensor_cycles()
- Import:
참조 사이클 탐지기(Reference Cycle Detector)는 사이클 수집기가 실행되어 해제되는 CUDA 텐서를 찾을 때마다 경고를 발행합니다. 이 경고는 참조 사이클이 GPU 텐서를 어떻게 참조하는지 보여주는 객체 그래프를 제공합니다.

예를 들어, 이 객체 그래프에서는 그래프의 외부 원에 순환 의존성(circular dependency)이 있으며, 살아있는 GPU 텐서가 빨간색으로 강조 표시된 것을 쉽게 관찰할 수 있습니다.
대부분의 사이클은 발견되면 해결하기가 꽤 쉽습니다. 예를 들어, 여기에서는 콜백에서 self._view_dim에 의해 생성된 self에 대한 참조를 제거할 수 있습니다.
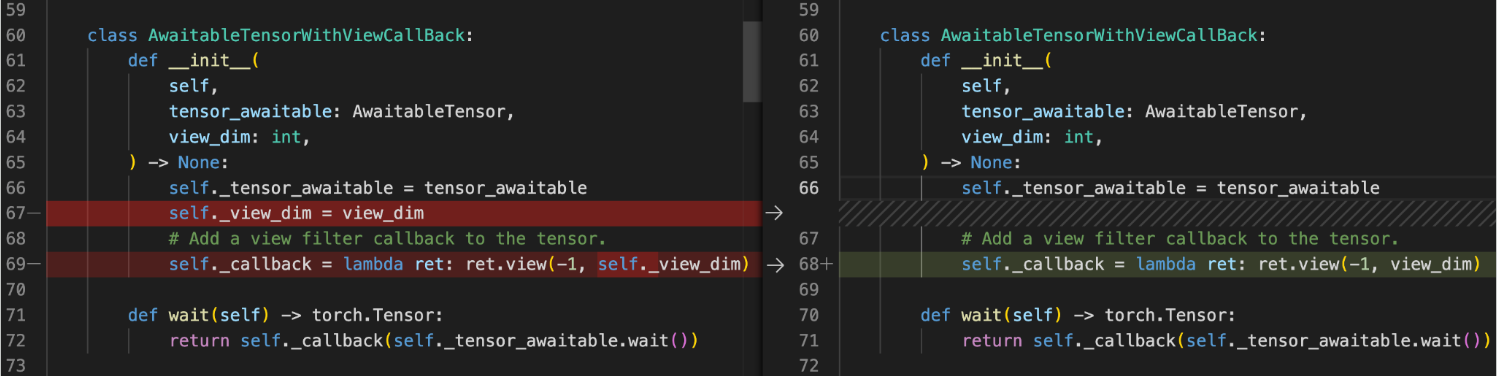
이 도구들을 사용하여 기존 모델들에서 사이클을 수정하는 데 시간을 할애했습니다. 예를 들어, TorchRec에서는 PR#1226에서 참조 사이클(reference cycle)을 발견하고 제거했습니다.
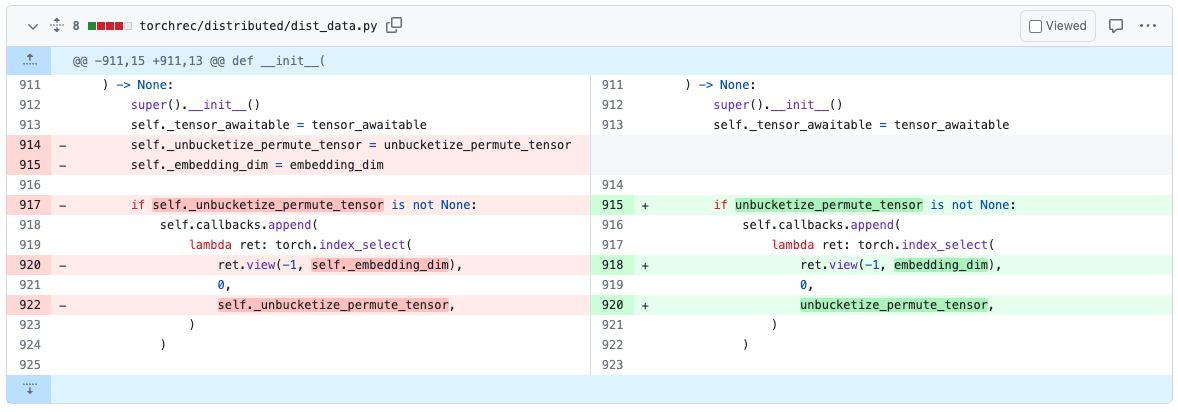
참조 사이클을 제거하고 나면, 코드는 더 이상 CUDA OOM을 발생시키지 않으며 스냅샷에서 메모리 누수를 보여주지 않을 것입니다.
참조 사이클 탐지기(Reference Cycle Detector)를 사용하는 다른 이점은 무엇인가요?
이러한 사이클을 제거하면 최대 GPU 메모리 사용량을 직접적으로 낮추고, 할당자가 각 반복(iteration) 후에 동일한 상태로 돌아가기 때문에 메모리 조각화(fragmentation)가 발생할 가능성도 줄어듭니다.
이 도구들은 어디에서 찾을 수 있나요? (WHERE CAN I FIND THESE TOOLS?)
참조 사이클로 인한 메모리 누수를 찾고 제거하는 능력을 크게 향상시킬 것이라고 기대합니다. 참조 사이클 탐지기는 PyTorch의 v2.1 릴리스에서 실험적 기능으로 제공되며, 참조 사이클 탐지기에 대한 자세한 정보는 여기 PyTorch 메모리 문서(docs)에서 찾을 수 있습니다.
피드백 (FEEDBACK)
우리 도구들이 해결한 향상, 버그 또는 메모리 이야기에 대해 듣고 싶습니다! 항상 그렇듯, PyTorch의 Github 페이지에 새로운 이슈를 열어주시기 바랍니다.
우리는 OSS 커뮤니티의 기여에도 열려 있으며, Github PR에 Aaron Shi와 Zachary DeVito를 태그하여 리뷰를 요청할 수 있습니다.
감사의 말 (ACKNOWLEDGEMENTS)
이 글을 검토하고 가독성을 향상시켜 준 콘텐츠 검토자 Mark Saroufim, Gregory Chanan, 그리고 Adnan Aziz에게 진심으로 감사합니다.
APPENDIX
Appendix A - Code Sample
이 코드 스니펫은 보여진 그래프와 예제를 생성하는 데 사용되었습니다. 여기에 섹션을 재현하기 위한 인자들이 있습니다:
- 서론(Introduction):
python sample.py - 명시적으로 gc.collect() 호출하기(Explicitly calling gc.collect()):
python sample.py --gc_collect_interval=100 - 콜백에서의 교묘한 메모리 누수(Sneaky Memory Leak in Callback):
python sample.py --workload=awaitable - 참조 사이클 탐지기(Ref Cycle Detector):
python sample.py --workload=awaitable --warn_tensor_cycles
sample.py:
# (c) Meta Platforms, Inc. and affiliates.
import argparse
import asyncio
import gc
import logging
import socket
from datetime import datetime, timedelta
import torch
logging.basicConfig(
format="%(levelname)s:%(asctime)s %(message)s",
level=logging.INFO,
datefmt="%Y-%m-%d %H:%M:%S",
)
logger: logging.Logger = logging.getLogger(__name__)
logger.setLevel(level=logging.INFO)
TIME_FORMAT_STR: str = "%b_%d_%H_%M_%S"
# Keep a max of 100,000 alloc/free events in the recorded history
# leading up to the snapshot.
MAX_NUM_OF_MEM_EVENTS_PER_SNAPSHOT: int = 100000
def start_record_memory_history() -> None:
if not torch.cuda.is_available():
logger.info("CUDA unavailable. Not recording memory history")
return
logger.info("Starting snapshot record_memory_history")
torch.cuda.memory._record_memory_history(
max_entries=MAX_NUM_OF_MEM_EVENTS_PER_SNAPSHOT
)
def stop_record_memory_history() -> None:
if not torch.cuda.is_available():
logger.info("CUDA unavailable. Not recording memory history")
return
logger.info("Stopping snapshot record_memory_history")
torch.cuda.memory._record_memory_history(enabled=None)
def export_memory_snapshot() -> None:
if not torch.cuda.is_available():
logger.info("CUDA unavailable. Not exporting memory snapshot")
return
# Prefix for file names.
host_name = socket.gethostname()
timestamp = datetime.now().strftime(TIME_FORMAT_STR)
file_prefix = f"{host_name}_{timestamp}"
try:
logger.info(f"Saving snapshot to local file: {file_prefix}.pickle")
torch.cuda.memory._dump_snapshot(f"{file_prefix}.pickle")
except Exception as e:
logger.error(f"Failed to capture memory snapshot {e}")
return
# This function will leak tensors due to the reference cycles.
def simple_leak(tensor_size, gc_interval=None, num_iter=30000, device="cuda:0"):
class Node:
def __init__(self, T):
self.tensor = T
self.link = None
for i in range(num_iter):
A = torch.zeros(tensor_size, device=device)
B = torch.zeros(tensor_size, device=device)
a, b = Node(A), Node(B)
# A reference cycle will force refcounts to be non-zero, when
# a and b go out of scope.
a.link, b.link = b, a
# Python will eventually gc a and b, but may OOM on the CUDA
# device before that happens (since python runtime doesn't
# know about CUDA memory usage).
# Since implicit gc is not called frequently enough due to
# generational gc, adding an explicit gc is necessary as Python
# runtime does not know about CUDA memory pressure.
# https://en.wikipedia.org/wiki/Tracing_garbage_collection#Generational_GC_(ephemeral_GC)
if gc_interval and i % int(gc_interval) == 0:
gc.collect()
async def awaitable_leak(
tensor_size, gc_interval=None, num_iter=100000, device="cuda:0"
):
class AwaitableTensor:
def __init__(self, tensor_size, device) -> None:
self._tensor_size = tensor_size
self._device = device
self._tensor = None
def wait(self) -> torch.Tensor:
self._tensor = torch.zeros(self._tensor_size, device=self._device)
return self._tensor
class AwaitableTensorWithViewCallBack:
def __init__(
self,
tensor_awaitable: AwaitableTensor,
view_dim: int,
) -> None:
self._tensor_awaitable = tensor_awaitable
self._view_dim = view_dim
# Add a view filter callback to the tensor.
self._callback = lambda ret: ret.view(-1, self._view_dim)
def wait(self) -> torch.Tensor:
return self._callback(self._tensor_awaitable.wait())
for i in range(num_iter):
# Create an awaitable tensor
a_tensor = AwaitableTensor(tensor_size, device)
# Apply a view filter callback on the awaitable tensor.
AwaitableTensorWithViewCallBack(a_tensor, 4).wait()
# a_tensor will go out of scope.
if gc_interval and i % int(gc_interval) == 0:
gc.collect()
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="A memory_leak binary instance")
parser.add_argument(
"--gc_collect_interval",
default=None,
help="Explicitly call GC every given interval. Default is off.",
)
parser.add_argument(
"--workload",
default="simple",
help="Toggle which memory leak workload to run. Options are simple, awaitable.",
)
parser.add_argument(
"--warn_tensor_cycles",
action="store_true",
default=False,
help="Toggle whether to enable reference cycle detector.",
)
args = parser.parse_args()
if args.warn_tensor_cycles:
from tempfile import NamedTemporaryFile
from torch.utils.viz._cycles import observe_tensor_cycles
logger.info("Enabling warning for Python reference cycles for CUDA Tensors.")
def write_and_log(html):
with NamedTemporaryFile("w", suffix=".html", delete=False) as f:
f.write(html)
logger.warning(
"Reference cycle includes a CUDA Tensor see visualization of cycle %s",
f.name,
)
observe_tensor_cycles(write_and_log)
else:
# Start recording memory snapshot history
start_record_memory_history()
# Run the workload with a larger tensor size.
# For smaller sizes, we will not CUDA OOM as gc will kick in often enough
# to reclaim reference cycles before an OOM occurs.
size = 2**26 # 256 MB
try:
if args.workload == "awaitable":
size *= 2
logger.info(f"Running tensor_size: {size*4/1024/1024} MB")
asyncio.run(
awaitable_leak(tensor_size=size, gc_interval=args.gc_collect_interval)
)
elif args.workload == "simple":
logger.info(f"Running tensor_size: {size*4/1024/1024} MB")
simple_leak(tensor_size=size, gc_interval=args.gc_collect_interval)
else:
raise Exception("Unknown workload.")
except Exception:
logger.exception(f"Failed to allocate {size*4/1024/1024} MB")
# Create the memory snapshot file
export_memory_snapshot()
# Stop recording memory snapshot history
stop_record_memory_history()