Thread 포스트에서 마지막으로 작성한 코드는 상호 배제를 통해서 정상적으로 join()이 실행 된 것을 알 수 있으나, 계산 시간의 단축이 이루어지진 않았다.
해당 코드를 멀티스레드가 아닌 멀티프로세스(mulitprocess), 즉 진정한 병렬 프로그래밍 방식으로 구현하면 계산 시간을 단축할 수 있다.
프로세스를 만들면 프로세스 별로 별도의 메모리 영역을 가지며, queue나 pipe(혹은 First-in-First-Out File)을 이용한 프로세스간 통신(IPC, inter-process communication)과 같은 방법으로 객체들의 교환을 구현할 수 있다.
멀티 프로세스 프로그램은 각각 별도의 메모리 영역을 가지고 여러 작업을 동시에 나눠서 처리할 수 있으므로, 작업 속도의 비약적인 향상을 이룰 수 있다.
멀티스레드로 구현한 이전의 코드를 멀티프로세스로 수정한 다음 코드를 살펴보자.
from multiprocessing import Process, Queue # multiprocessing 패키지 import
import time
def worker(id, number, q):
increased_number = 0
for i in range(number):
increased_number += 1
q.put(increased_number)
return
if __name__ == "__main__":
start_time = time.time()
q = Queue() # Queue() 인스턴스 생성
th1 = Process(target=worker, args=(1, 50000000, q)) # process 1 생성
th2 = Process(target=worker, args=(2, 50000000, q)) # process 2 생성
th1.start() # process 1 호출
th2.start() # process 2 호출
th1.join()
th2.join()
print("--- %s seconds ---" % (time.time() - start_time))
q.put('exit')
total = 0
while True:
tmp = q.get()
if tmp == 'exit':
break
else:
total += tmp
print("total_number=",end=""), print(total)
print("end of main")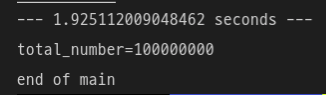
계산 속도가 1.9초로 두 배 이상 빨라진 것을 확인할 수 있다.
파이썬의 multiprocessing 모듈에서, 프로세스는 process 객체를 생성한 후에 start() 매서드를 호출해서 스폰한다. 여기서 start()매서드를 사용하는 것에서 알 수 있듯이, multiprocessing 모듈은 Threading 모듈의 API를 따른다. run() 혹은 join()등의 스레드 모듈에서 사용한 매서드를 그대로 사용하면 된다. 자원 접근 권한 매서드인 acquire()와 release() 또한 그대로 사용할 수 있다.
*스폰(spawn) : 새로운 자식 프로세스를 로드하고 실행함, 혹은 그 함수
프로세스의 IPC 방법은 앞에서 설명했듯이 queue ,pipe, shared memory등이 있다.
파이썬의 multiprocessing은 queue와 pipe 두 가지 유형의 IPC를 지원하며, 각각 queue()나 pipe()로 호출하면 된다. 다음 코드들을 통해 각각의 IPC를 어떻게 구현하는지 살펴보자.
from multiprocessing import Process, Queue
def f(q):
q.put([42, None, 'hello'])
if __name__ == '__main__':
q = Queue() # queue
p = Process(target=f, args=(q,))
p.start()
print(q.get()) # prints "[42, None, 'hello']"
p.join()from multiprocessing import Process, Pipe
def f(conn):
conn.send([42, None, 'hello'])
conn.close()
if __name__ == '__main__':
parent_conn, child_conn = Pipe()
p = Process(target=f, args=(child_conn,))
p.start()
print(parent_conn.recv()) # prints "[42, None, 'hello']"
p.join()스레드에서는 프로세스를 나눈 단위므로 공유 데이터를 사용할 때 제약 없이 사용 가능하지만, 프로세스는 독립적인 메모리 공간을 가지므로 각각의 프로세스의 메모리는 다른 프로세스에서 접근 할 수 없다. 그러나 꼭 공유된 메모리가 필요한 경우에는 shared memory, 공유 메모리를 사용하면 된다. 공유 메모리를 사용하면 메모리의 일부 공간을 두 독립적인 프로세스에서 공유하고, 해당 메모리를 통해서 데이터를 주고받을 수 있다.
파이썬에서 공유 메모리 인스턴스는 share_memory를 통해 import를 하여 호출하면 된다. 구조는 다음과 같다.
class multiprocessing.shared_memory.SharedMemory(name=None, create=False, size=0)공유 메모리에 여러 프로세스가 동시에 쓰기를 시도하면 데이터가 손상되는 현상이 발생할 수 있다. 따라서 여러 프로세스 사이에서 동작의 순서를 지정해 줘야 하는데, 이럴때 Semaphore가 사용된다.
세마포어는 지정한 변수만큼의 프로세스 혹은 쓰레드가 자원에 접근 가능하게 하는 방법이다. 오직 하나의 프로세스 혹은 쓰레드만 자원에 접근 가능한 상호 배제와는 다르게 세마포어는 여러 대상을 처리할 수 있고 공유 메모리라는 임계 영역을 사용할 수 있는게 차이점이다.
또한 락(Lock)을 통해서 접근 권한을 관리하는 상호 배제와는 다르게 세마포어는 락을 사용하지 않으므로 현재 수행중인 프로세스가 아닌 다른 프로세스가 세마포어를 해제할 수 있다.
파이썬에서 세마포어 객체의 구현은 스레드나 프로세스 모듈에서 Semaphore를 import 해주면 된다.
공유 메모리와 세마포어가 파이썬에서 어떻게 구현되는지 알아보자. 앞에서 구현한 멀티프로세싱은 queue를 통한 IPC를 이용하여 구현한 코드다. 이를 shared memory 방식과 Semaphore를 사용한 코드로 수정하고, 이에 사용된 각각의 매서드를 설명하겠다. 공식문서를 번역한 Flowdas를 참조하였다.
from multiprocessing import Process, shared_memory, Semaphore
import numpy as np
import time
#매개 변수 : 프로세스명, 숫자, 공유메모리, 공유메모리를 저장할 배열, 세마포어 객체
def worker(id, number, shm, arr, sem):
increased_number = 0
for i in range(number):
increased_number += 1
sem.acquire() # mutex와 동일
# 기존 공유 메모리 블록에 연결
existing_shm = shared_memory.SharedMemory(name=shm)
# numpy 배열 형태에 맞게 변환
tmp_arr = np.ndarray(arr.shape, dtype=arr.dtype, buffer=existing_shm.buf)
# 각각의 프로세스에서 연산한 값을 합해서 numpy 배열에 저장
tmp_arr[0] += increased_number
sem.release() # mutex와 동일
if __name__ == "__main__":
start_time = time.time()
sem = Semaphore()
# 숫자를 저장할 numpy 배열 생성
arr = np.array([0])
# 공유 메모리 생성
shm = shared_memory.SharedMemory(create=True, size=arr.nbytes)
# 공유 메모리의 버퍼를 numpy 배열로 변환
np_shm = np.ndarray(arr.shape, dtype=arr.dtype, buffer=shm.buf)
th1 = Process(target=worker, args=(1, 50000000, shm.name, np_shm, sem))
th2 = Process(target=worker, args=(2, 50000000, shm.name, np_shm, sem))
th1.start()
th2.start()
th1.join()
th2.join()
print("--- %s seconds ---" % (time.time() - start_time))
#프로세스에서 계산된 값을 저장한 np_shm 배열 출력
print("total_number=",end=""), print(np_shm[0])
print("end of main")
# 공유 메모리 사용 종료
shm.close()
# 공유 메모리 블록 삭제
shm.unlink()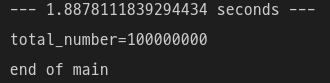
queue 뿐만 아니라 shared_memory와 Semaphore로도 멀티프로세스를 구현할 수 있음을 알 수 있다.
