Thread는 프로그램, 특히 프로세스 안에서 실행되는 흐름의 단위다. 하나의 프로세스 안에서 여러개의 쓰레드를 만들 수 있다. 한 프로세스에 자원이 부여되면 그 안에서 프로세스에 속한 여러 쓰레드가 자원을 공유할 수 있다. 이러한 실행 방식을 멀티스레드(multithread)라고 한다.
쓰레드는 동시성을 위해서 만들어진 개념이다. 쓰레드를 사용하면 하나의 프로세스 안에서 여러개의 루틴을 만들어서 병렬적으로 실행할 수 있다.
단순 반복하는 작업을 분리해서 처리 가능하며, 다음과 같은 장점이 있다.
1. CPU의 사용률 향상
2. 효율적인 자원 활용 및 응답성 향상
3. 코드 간결 및 유지보수성 향상
다음 코드를 살펴보자. 단일 스레드의 단일 프로세스로 1억번 1를 더하는 코드를 구현하였다.
import time
if __name__ == "__main__":
increased_num = 0
start_time = time.time()
for i in range(100000000):
increased_num += 1
print("--- %s seconds ---" % (time.time() - start_time))
print("increased_num=",end=""), print(increased_num)
print("end of main")
단일 스레드로는 계산에 약 6초가 소요되는 것을 확인할 수 있다.
쓰레드를 2개 만든 코드로 수정해 보았다.
import threading
import time
shared_number = 0
def thread_1(number):
global shared_number
print("number = ",end=""), print(number)
for i in range(number):
shared_number += 1
def thread_2(number):
global shared_number
print("number = ",end=""), print(number)
for i in range(number):
shared_number += 1
if __name__ == "__main__":
threads = [ ]
start_time = time.time()
t1 = threading.Thread( target= thread_1, args=(50000000,) )
t1.start()
threads.append(t1)
t2 = threading.Thread( target= thread_2, args=(50000000,) )
t2.start()
threads.append(t2)
for t in threads:
t.join()
print("--- %s seconds ---" % (time.time() - start_time))
print("shared_number=",end=""), print(shared_number)
print("end of main")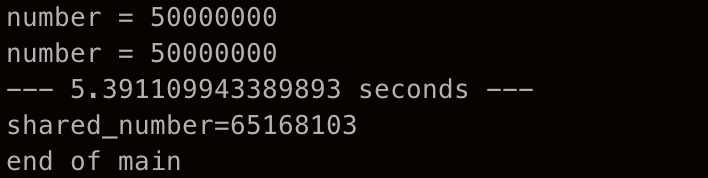
쓰레드를 2개를 만들어서 실행시켜 보았으나 숫자는 1억이 되지 않았고, 계산 속도도 반으로 줄지 않았다. 왜 이런 것일까?
이를 알아보기 위해서는 GIL과 Mutex, Condition Variable를 알아야 한다.
먼저 GIL에 대해 알아보자. 현존하는 대부분의 프로그래밍 언어는 스레드를 실행하는 환경에서 자원을 보호하기 위해서, 더 정확하게는 자원에 대한 접근에 대해 제한하기 위해서 Lock을 사용한다. 락은 상호 배제, 영어로 Mutual exclusion, 줄여서 Mutex를 강제하기 위해서 설계된다. Mutex에 대해서는 후술하겠다.
파이썬에서는Lock으로 Global Interpreter Lock, 줄여서 GIL 정책을 사용한다. 파이썬은 한번에 오직 하나의 스레드가 코드를 실행하기 위해서(자원을 사용하기 위해서), 하나의 프로세스 안에 모든 자원에 Lock을 글로벌(Global)하게 관리한다.
이 파이썬의 GIL 정책 때문에, shared_number를 공유하는 두 쓰레드가 동시에 실행되지 않고 한번에 하나의 쓰레드만 계산을 실행하여 실행 시간이 비슷한 것이다.
다음으로 Mutex, 상호 배제에 대해 알아보자. 상호 배제는 주어진 특정 시간에 하나의 스레드만 특정 자원을 사용할 수 있는 것을 의미한다. 한 프로그램에 여러 스레드가 존재하는 경우에, 상호 배제는 스레드가 특정 자원을 동시에 사용하는 것을 제한하며 다른 스레드를 잠그고(Lock) 임계 영역으로의 진입을 제한한다.
*임계 영역 : 둘 이상의 스레드가 동시에 접근해서는 안되는 공유 자원에 접근하는 코드의 일부,
혹은 프로세스간에 공유 자원을 접근하는데 있어서 문제가 발생하지 않도록 한번에 하나의 프로세스만 이용하게끔 보장해줘야 하는 영역
그렇다면 파이썬에서는 상호 배제를 어떻게 구현할까? 파이썬에서는 상호 배제를 구현하기 위해서 내장되어 있는 Threading 모듈의 lock()함수를 사용하여 스레드를 잠근다. 스레드가 2개 존재하는 프로세스가 있다고 가정해보자.
lock()함수를 통해 두 번째 스레드를 잠근 뒤 첫 번째 스레드가 완료 될 때까지 기다리고, 첫 번째 스레드가 완료되면 두 번째 쓰레드의 잠금을 해제한다. 이를 통해 두 번째 스레드가 첫 번째 스레드보다 먼저 끝나려고 하면 첫 번째 스레드가 끝날 때 까지 기다릴 수 있게 된다.
잠금과 잠금 해제는 acquire()와 release() 두 매서드를 통해서 구현할 수 있다. acquire()매서드는 상태를 잠금으로 변경하고 즉시 반환하고,
release()매서드는 상태를 잠금 해제로 변경하고 즉시 반환한다.
Condition variable, 조건 변수는 상호 배제로는 해결이 힘든 문제를 해결하기 위한 개념이다.
멀티 쓰레드 프로그램에서 자주 등장하는 패턴인, 로그를 처리하기 위한 스레드를 생산자/소비자 스레드로 나눈 패턴이 있다고 가정해보자.
생산자 스레드는 로그 데이터를 생성하서 queue에 삽입하고 소비자 스레드는 queue에 데이터가 들어오면 데이터를 전달받아 파일에 기록한다.
생산자/소비자 스레드 양쪽에서 사용하는 queue 데이터는 스레드 간 공유 자원이 되기 때문에 Lock을 통해서 보호해야 하며, 또한 소비자 스레드는 queue에 데이터가 들어 있을 경우에만 동작을 해야 하고 데이터가 들어 있지 않다면 행동을 멈춰 자원을 소모하지 않는 형태가 자원 사용의 측면에서 이상적이게 된다.
상호 배제를 통해서 생산자/소비자 스레드를 구현하게 되면, 소비자 스레드는 동작의 필요 여부를 확인하기 위해 생산자 스레드에게 계속 호출을 해서 자원을 계속해서 소모하게 되므로 비효율적이게 되지만, 조건 변수를 사용하면 소비자 스레드는 동작을 멈추고 생산자 스레드가 호출할때만 동작하게 되므로 효율적으로 자원을 사용할 수 있다..
파이썬에서는 각각 with문과 wait(), notify() 메서드를 통해서 조건 변수 객체를 구현할 수 있다. 다음 코드를 살펴보자.
# 소비자 스레드
with cv:
while not an_item_is_available():
cv.wait()
get_an_available_item()
# 생산자 스레드
with cv:
make_an_item_available()
cv.notify()with문을 통해 조건 변수 객체를 생성하고, wait()을 통해 소비자 스레드의 대기를, nofity()를 통해 생산자 스레드의 호출을 구현하였다.
자, 이제 앞에서 설명한 상호배제와 관련된 매서드를 통해서 `shared_number`에서 두 스레드를 통해서 각각 오천만씩 증가시켜 총 1억까지 증가시키는 코드를 작성해 보자.
import threading
import time
shared_number = 0
def thread_1(number):
global shared_number
mutex.acquire() # acquire()를 통해 접근 권한 획득
print("number = ",end=""), print(number)
for i in range(number):
shared_number += 1
mutex.release() # release()를 통해 접근 권한 반환
def thread_2(number):
global shared_number
mutex.acquire() # acquire()를 통해 접근 권한 획득
print("number = ",end=""), print(number)
for i in range(number):
shared_number += 1
mutex.release() # release()를 통해 접근 권한 반환
if __name__ == "__main__":
mutex = threading.Lock() # thread 모듈의 lock 함수 선언을 통해 상호 배제 구현
threads = [ ]
start_time = time.time()
t1 = threading.Thread( target= thread_1, args=(5000000,) )
t1.start()
threads.append(t1)
t2 = threading.Thread( target= thread_2, args=(5000000,) )
t2.start()
threads.append(t2)
for t in threads:
t.join()
print("--- %s seconds ---" % (time.time() - start_time))
print("shared_number=",end=""), print(shared_number)
print("end of main")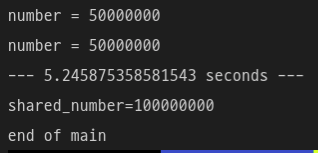
주석을 통해 추가된 코드를 확인할 수 있다.
lock()과 acquire(), release()으로 접근 권한을 설정해서 멀티스레드를 생성했다.
그리고각각의 스레드가 자원 접근 권한을 얻고, 계산(명령)을 수행하고 다시 권한을 반환한 뒤에,
join()을 통해 두 스레드의 결과값을 합친 값이 정상적으로 1억으로 출력되는 것을 확인할 수 있다.
