[+45]자료구조
자료구조 data structure이란?
- 자료구조 란 데이터에 편리하게 접근하고 변경하기 위해서 데이터를 저장하거나 조직하는 방법.
- 모든 목적에 맞는 자료구조는 없기 떄문에 각 자료구조가 갖는 장점과 한계를 잘 아는 것이 중요하다.
- 자료구조는 언어별로 지원하는 양상이 다르다.
자료구조의 분류
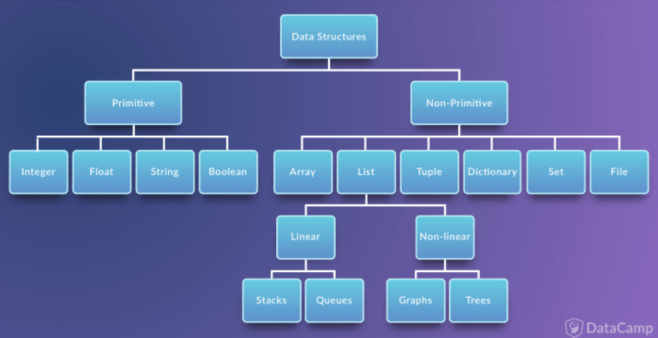
- primitive data structure(단순 구조): 프로그래밍에서 사용되는 기본 데이터 타입
- non-primtive data structure(비단순 구조): 단순한 데이터를 저장하는 구조가 아니라 여러 데이터를 목적에 맞게 효과적으로 저장하는 자료구조.
- linear data structure(선형 구조): 저장되는 자료의 전후관계가 1:1 (리스트, 스택, 큐 등)
- non-linear data structure(비선형 구조): 데이터 항목 사이의 관계가 1:n 또는 n:m(트리, 그래프 등)
일반적으로 가장 자주 사용되는 자료구조들
- array
- tuple
- set
- dictionary
- stack & queue
- tree
array는 실제 메모리 안에서 바로옆에 저장되기 때문에 순서가 있고 인덱스가 있다. 인덱스가 있으니까 어떤 인덱스의 원소를 바로바로 뽑아서 쓸 수가 있다.
array의 단점: 배열 중에 하나를 삭제 하면 그 뒤의 원소들이 한칸씩 당겨줘야 한다. 다른 자료구조에 비해 느릴 수 있다.
배열의 원소를 추가하는 것도 마찬가지. 비용도 비싸다.
append 중간에 뭐 삽입하면 다음 원소들을 한 칸씩 밀어줘야 한다.
큰 단점 하나 더. resizing
array를 생성하면 어느정도 메모리를 확보를 한 상태로 list가 만들어진다.
100개를 확보했는데 추가가 이뤄진다면 재 할당. 200개로 다시 할당해서 전에 있던 100개를 들고오고 그 다음에 추가.
더 큰 새 아파트에 이사하는 것. 비용이 비싸요.
메모리에 곧바로 access하기 때문에 array가 제일 효율적인 자료구조 이다.
그러나 상황별로 필요한 자료구조를 적절히 사용할 것 :)
tuple
list(array)랑 비슷한데 tuple은 일반적으로 2~5사이의 갯수의 element를 저장하는 용도로 사용한다.
근데 왜 tuple을 사용하는가?
-수정이 안된다. 고정 값.
-간단한 값을 빨리 쓰고싶을 때 사용
그래서 누가봐도 확실한 단순한값만 튜플로 써야한다.
Set
list(array) 와 set차이를 말해주세요
set은 순서가 없고 중복이 없다.
왜 중복이 없는가?
set은 hash를 통해 bucket에 저장한다. 같은 hash값이라면 치환하여 해당하는 bucket에 저장하기 때문에 중복이 없다.
그래서 1차 프로젝트 베스킨라빈스 팀에서 알러지 유발 선택했을 때, 우유와 초콜렛을 선택하면 해당하는 같은 제품이 2개로 뜨지 않게 사용했었다고 한다.
Set는 array나 list처럼 순열 자료구조(collection)이다.
하지만 set는 순서라는 개념이 존재하지 않는다.
set 특징
- 데이터를 비순차적(unordered)으로 저장할 수 있는 순열 자료구조(collection).
dictionary
set이 중복값을 허용하지 않았듯이 dictionaty(object)는 키 값의 중복을 허용하지 않는다.
stack & queue
stack
stack 은 Last In First Out
stack은 브라우저 뒤로가기 할 때 유용하다.
queue 은 First In First Out
cpu가 1개일 때도 노래들으면서 인터넷 하는 멀티태스킹 같은거 할 수 있는데 실제로는 두개가 동시에 돌아가는게 아니라 왔다갔다하면서 일을 하고 있는건데 너무 빨라서 우리는 두가지 일을 하고 있다고 느낀다.
tree
tree 자료구조는 데이터를 나무 거꾸로된 형태로 저장하는 자료 구조 인다. tree자료구조는 여러 유형이 있지만 그 중 가장 기본은 binary tree(이진 트리) 자료구조이다. 이진 트리는 두개의 자식 노드를 가진 트리 형태이다.
- node: 트리구조의 교점이다. node가 데이터를 가지고 있고 또한 자식 노드를 가지고 있다. 트리 자료구조는 노드를 기본으로 구성된다고 보면 된다.
- root node: 트리 구조의 가장 위 노드, 즉 시작점이 되는 노드이다.
tree구조는 데이터의 저장의 의미보다는 저장된 데이터를 더 효과적으로 탐색하기 위해서 사용된다.
이진트리는 언급한대로 최대 2개의 자식 노드를 가질 수 있고
left node에는 부모 node보다 작은 값이 저장되고
right node에는 부모 node보다 큰 값이 저장된다.

일반 array는 검색이 O(N)인데 비해 이진 트리는 O(log N)이므로 리스트 보다 훨씬 검색이 효율적이다.
추가적으로 setdms O(1)이다. 왜? 어떤걸 검색해도 검색해서 찾아내는 속도가 같다.
결론
결국 어떤 자료구조를 써도 효율을 위해서 시간이나 메모리를 희생시킨다.
각 상황에 맞춰 적절하다고 생각하는 자료구조를 쓰자.
