Android With Clean Architecture
해당 글은 학습한 내용을 정리한 글로 틀린 내용이 포함되어 있을 수 있습니다.
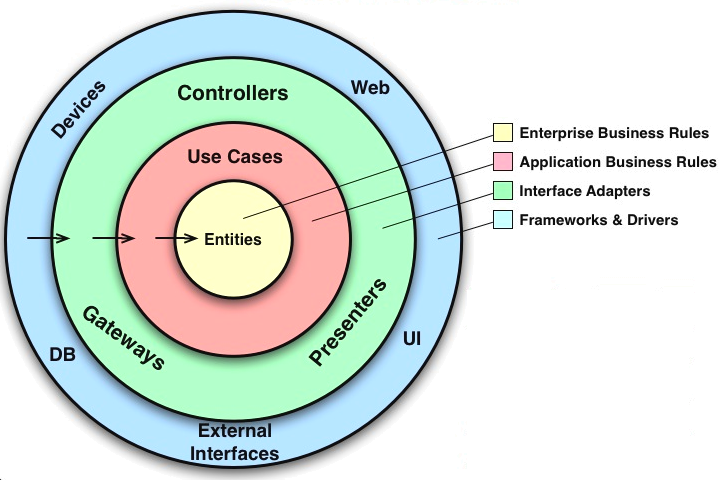
우리는 흔히 클린 아키텍처라는 단어를 검색하면 위 이미지를 확인할 수 있습니다.
사실 필자는 위 이미지를 보고 클린 아키텍처를 쉽게 이해하지는 못 했습니다.
하지만, 코드로 직접 구현해보고 반복해서 관련 글을 읽어 봄으로써 그 '느낌'을 이해하는 경험을 할 수 있었습니다.
오늘은 해당 과정을 통해 배운 내용을 담아보는 글을 작성 해볼까 합니다.
Why?
저는 클린 아키텍처를 배우기 이전에 '왜' 라는 단어가 머릿속에서 끊이지 않았습니다.
Android 앱을 만들 때 저의 주된 관심사는 '패턴'이었습니다.
MVVM, MVP, MVI ... 등 다양한 패턴을 어떻게 앱에 적용하고 구현할 수 있을까?
하지만, 이런 디자인 패턴을 적용해도 프로젝트가 커지고 내용이 많아지면
어김없이 찾아오는 유지보수 라는 문제가 있었습니다.
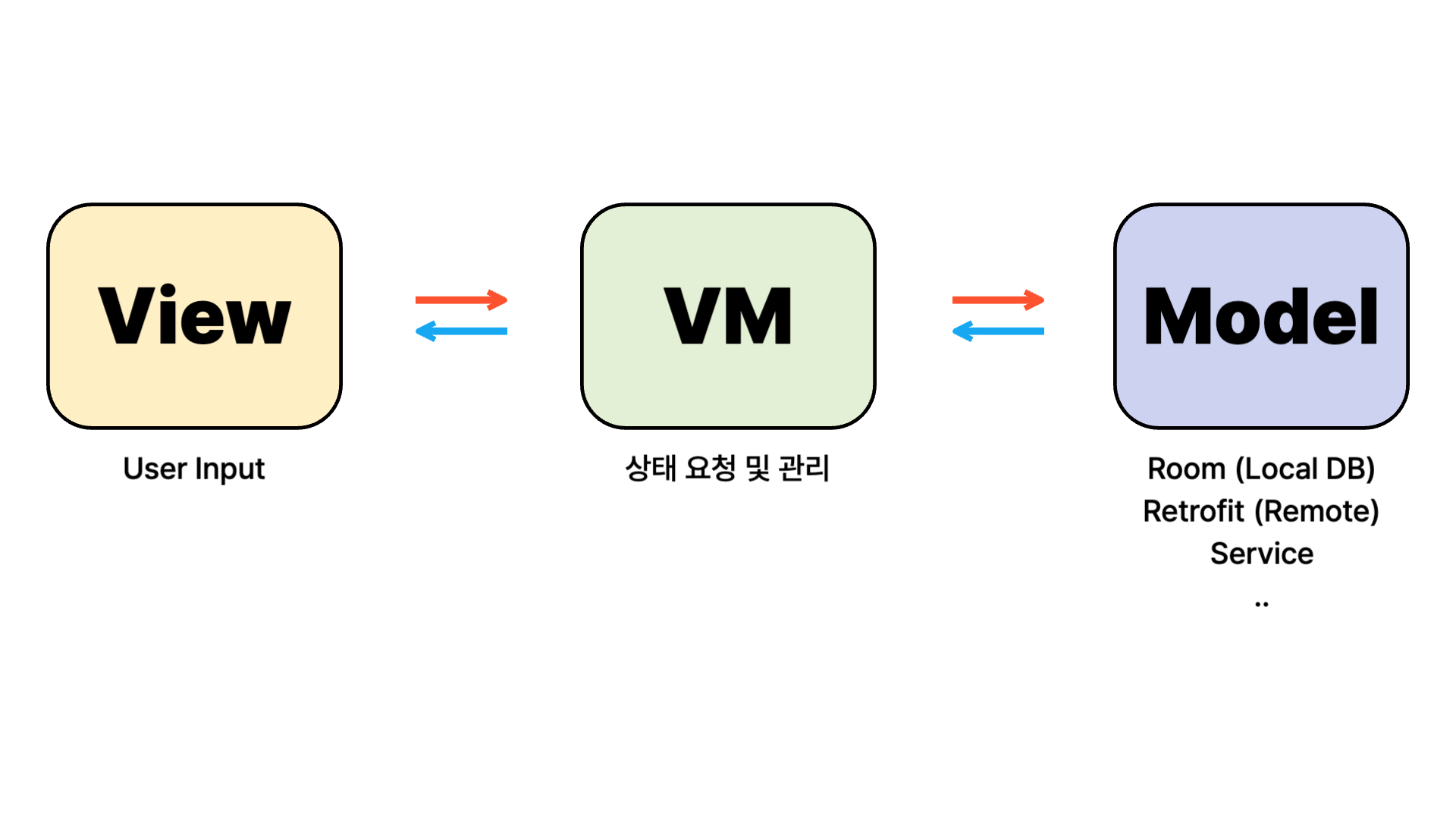
위 상황을 예로 들어보겠습니다.
우리는 MVVM 디자인 패턴을 적용해 앱을 제작하다 보면
Model 부분이 점점 비대해지는 경험을 하게 됩니다.
처음에는 데이터를 단순히 제공하는 역할이었던 Model이,
점점 데이터 가공, 예외 처리, 비즈니스 로직까지 떠안으며
결국 ViewModel과 강하게 결합되는 문제가 발생합니다.
그렇다면, 해결 방법은 무엇일까요?
이 지점에서 등장하는 개념이 바로 “관심사의 분리(Separation of Concerns)” 입니다.
프로젝트를 진행하며 이 용어를 자주 들어왔지만,
정확히 어떤 의미인지 짚고 넘어갈 필요가 있습니다.
관심사의 분리?
제일 먼저 디자인 패턴 수준에서 관심사의 분리를 접근해보겠습니다.
MVVM 패턴에서는 <View, ViewModel, Model(Repository)> 세 가지 레이어를 나누어
각자의 책임을 갖도록 합니다.
View – 화면 UI 처리 및 사용자 입력
ViewModel – UI 상태 관리 및 화면 로직
Model – 데이터 관리 (DB, API, Repository 등)
이렇게 나누는 것만으로도 Activity나 Fragment에 로직이 몰리지 않고
코드를 깔끔하게 정리할 수 있습니다.
그러나 여기에도 한계가 있습니다.
아무리 MVVM으로 레이어를 나눠도, Model은 여전히 비대해질 수 있습니다.
왜냐하면 MVVM은 어디까지나 “UI 설계 패턴”이기 때문입니다.
비즈니스 규칙, 도메인 정책, 복잡한 로직을 완전히 보호하기에는 부족합니다.
위와 같은 한계를 극복한 내용이 바로 Clean Architecture입니다.
Clean Architecture ?
그렇다면 Clean Architecture는 어떻게 이 문제를 해결할 수 있었을까요?
먼저, 전체 구조를 살펴보겠습니다.
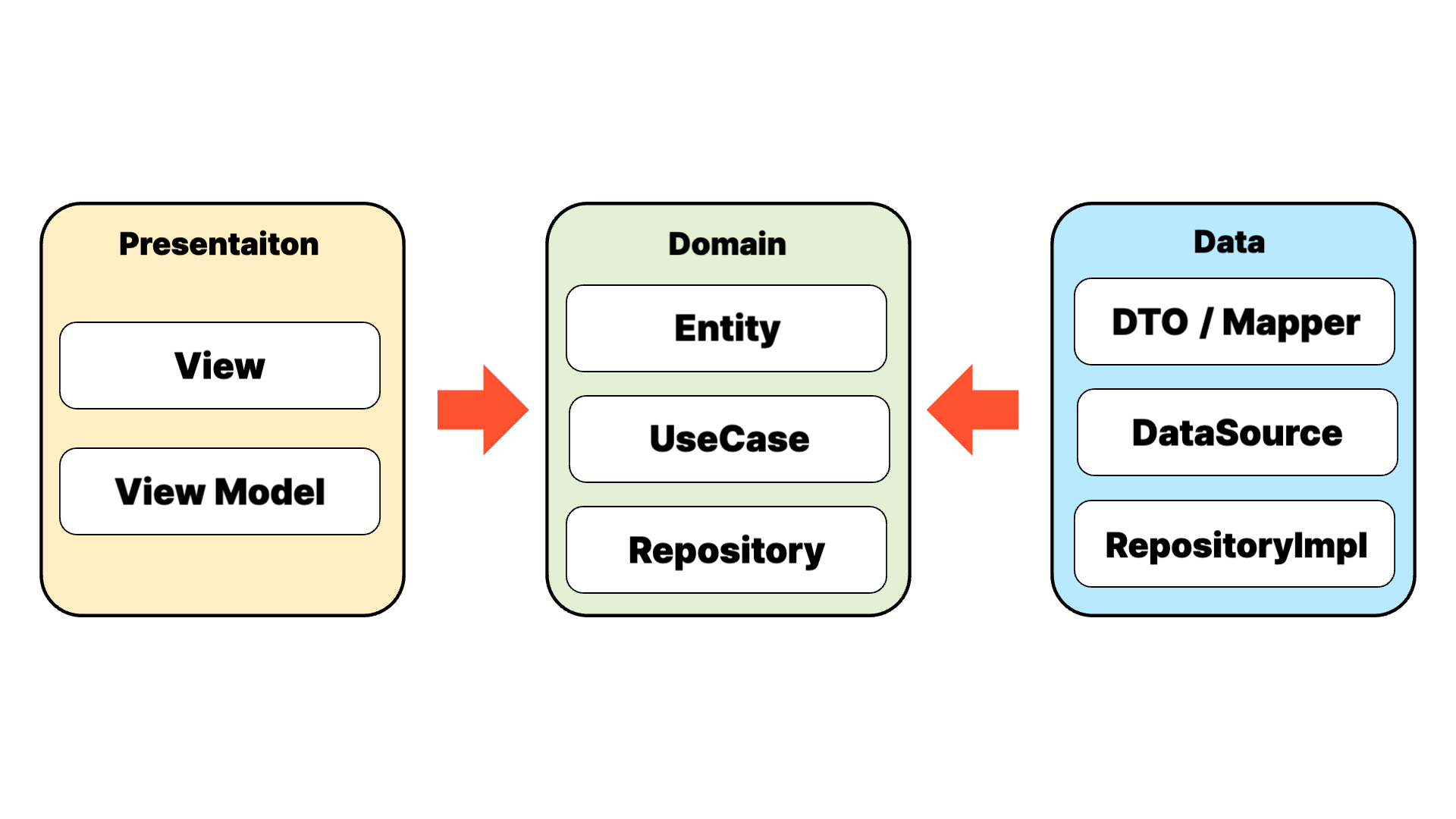
위 그림을 통해 Clean Architecture는 MVVM 패턴 대비 더욱 명확하게 관심사를 분리 했음을
확인할 수 있습니다.
각 레이어에 대해 자세히 알아보겠습니다.
Presentation Layer
역할
- 화면 렌더링 (Compose / View)
- ViewModel 상태(State) 관찰 및 UI에 반영합니다.
- 사용자 이벤트를 UseCase로 전달합니다.
의존
- 오직 Domain Layer의 UseCase만 의존합니다.
(Retrofit, Room 등 외부 기술 직접 의존)
결과물
- UI State (ex. Loading, Success, Error)
- 이벤트 처리 후 Domain 호출합니다.
안티패턴
- ViewModel 내부에서 API/DB 직접 호출. X
- DTO를 그대로 UI에 바인딩. X (Mapper 통해 Entity 변환 필요)
예시 코드 (ViewModel → UseCase)
@HiltViewModel
class ProfileViewModel @Inject constructor(
private val getProfile: GetProfileUseCase
) : ViewModel() {
private val _ui = MutableStateFlow<ProfileUiState>(ProfileUiState.Loading)
val ui: StateFlow<ProfileUiState> = _ui
fun load() = viewModelScope.launch {
_ui.value = when (val r = getProfile()) {
is Result.Success -> ProfileUiState.Success(r.value)
is Result.Failure -> ProfileUiState.Error(r.cause.message ?: "Error")
}
}
}Domain Layer
역할
- Domain Layer는 애플리케이션의 비즈니스 규칙과 핵심 기능(행위) 를 정의하는 계층.
- UI, DB, 네트워크 등 외부 요소와 완전히 분리되어 있습니다.
- 순수한 Kotlin 코드만 존재하는 것이 특징입니다.
-> 애플리케이션이 무엇을 할 수 있는가(UseCase) 정의합니다.
-> 핵심 개념과 규칙 (Entity) 정의합니다.
-> 외부 데이터가 아닌 "의미 있는 비즈니스 결과"를 다룹니다.
의존
- 어느 외부 레이어에도 의존하지 않습니다
- Dependency Inversion Principle (DIP) 을 실현하는 계층입니다.
구성 요소
Entity - 비즈니스 규칙을 담는 핵심 모델 (순수 데이터 + 불변 조건)
UseCase - 도메인 기능 수행, 앱의 기능 정의
Repository Interface - 도메인에서 데이터 접근을 "요구"하는 계약 (구현 X)
안티패턴
| 금지 | 이유 |
|---|---|
| Domain에서 Retrofit, Room, Android 코드 사용 | 외부 기술 의존 -> Clean Architecture 원칙 위반 |
| DTO를 Domain에서 다룸 | 외부 포맷 유입 -> Entity 오염 |
| UseCase에서 ViewModel/Context 접근 | UI/Infrastructure 영향 수용 -> 규칙층 붕괴 |
예시 코드 (ViewModel → UseCase)
// Entity (비즈니스 핵심 모델)
data class User(
val id: String,
val name: String
)
// Repository Interface (Domain이 Data에게 요구)
interface UserRepository {
suspend fun getUser(): User
}
// UseCase (앱이 수행할 수 있는 기능 정의)
class GetUserProfileUseCase(
private val repository: UserRepository
) {
suspend operator fun invoke(): Result<User> {
return runCatching { repository.getUser() }
}
}Domain Layer는 앱의 심장부이며,무엇을 할지(행위)를 정의하고,
어떻게 할지(구현)는 전혀 알지 못하는 특징을 가지고 있습니다.
Presentation과 Data는 모두 Domain의 규칙을 따르며,
Domain은 어떤 기술 변화에도 영향을 받지 않습니다.
Data Layer
역할
- Domain이 정의한 Repository Interface를 구현합니다.
- API /DB 등 외부 데이터 소스를 사용하여 실제 데이터 획득합니다.
- DTO -> Entity 변환을 통해 Domain 규칙을 지킵니다.
의존
- Domain Layer에 의존합니다. (Interface 구현)
- Retrofit, Room 등 외부 기술을 사용할 수 있는 유일한 레이어입니다.
구성 요소
| 구성 요소 | 역할 |
|---|---|
| RepositoryImpl | Repository 인터페이스 구현체. 데이터 조합·캐싱 등 |
| DataSource (Remote/Local) | Retrofit, Room, Cache 등의 실제 호출 계층 |
| DTO & Mapper | 외부 데이터 구조 → Domain Entity 변환 |
안티패턴
| 금지 | 이유 |
|---|---|
| DTO를 Domain/Presentation으로 직접 전달 | 외부 포맷 유입 → 아키텍처 경계 붕괴 |
| RepositoryImpl에 비즈니스 로직 작성 (ex. VIP는 이름 옆에 별추가) | Domain 규칙 오염 |
| RemoteDataSource에서 Entity 생성 | 계층 책임 위반 (Mapper 사용 필요) |
예시 코드
// Data → RepositoryImpl
class UserRepositoryImpl(
private val remote: UserRemoteDataSource,
private val local: UserLocalDataSource
) : UserRepository {
override suspend fun getUser(): User {
val cached = local.loadUser()
if (cached != null) return cached.toEntity()
val dto = remote.fetchUser()
local.cacheUser(dto)
return dto.toEntity()
}
}DIP?
이처럼 Clean Architecture는 새로운 패턴이 아닌,
'무엇을 어디에 둘 것인가'에 대한 기준을 제시하는 아키텍처입니다.
MVVM이 UI 설계에 집중했다면,
Clean Architecture는 애플리케이션의 '의미'와 '정책'을 지키기 위해
관심사와 의존성을 더 명확하게 분리합니다.
즉, 비대해지는 Model을 해결하려면 단순 분리가 아니라,
"역할을 가진 계층"으로 나누는 설계 철학이 필요합니다.
이러한 문제의식을 기반으로 등장한 원칙이 바로 DIP (Dependency Inversion Principle) 입니다.
DIP는 Clean Architecture의 핵심 뼈대 역할을 하며,
"상위 계층(정책)은 하위 구현(기술)에 의존하지 않는다"는 개념을 통해
애플리케이션의 핵심 규칙(Domain)을 외부 변화로부터 보호합니다.
DIP를 코드로 알아보겠습니다
Domain
// Domain Layer
interface UserRepository {
suspend fun getUser(): User
}Data(구현-의존 제공)
// Data Layer (Retrofit 예시)
class UserRepositoryImpl(
private val api: UserApi // Retrofit or Ktor etc...
) : UserRepository {
override suspend fun getUser(): User {
return api.getUser().toEntity() // DTO → Entity (Mapper)
}
}
Presentation(구현을 모른 채 규칙만 호출)
// Presentation Layer
class GetUserProfileUseCase(
private val repository: UserRepository
) {
suspend operator fun invoke(): Result<User> {
return runCatching { repository.getUser() }
}
}여기서 만약 Data Layer의 getUser() 함수가
Retrofit이 아닌 Ktor나 Room을 사용하도록 변경된다면 어떤 일이 발생할까요?
결론은, 아무런 영향도 발생하지 않습니다.
그 이유는 DIP 덕분에 Presentation Layer는 UserRepository 라는 규칙만 알고 있고,
실제 구현 UserRepositoryImpl에는 전혀 의존하지 않기 때문입니다.
따라서 Data Layer에서 Retrofit을 Ktor로 교체하거나,
로컬 DB(Room)로 방식을 변경하더라도
GetUserProfileUseCase는 Result<User>만 받아 처리하면 됩니다.
즉, 규칙은 그대로 두고, 구현만 교체할 수 있는 구조.
이것이 DIP가 제공하는 가장 강력한 장점입니다.
Mapper?
우리는 앞서 Clean Architecture와 DIP를 설명하며
.toEntity()와 같은 함수를 여러 번 보았습니다.
이 함수는 단순한 변환이 아니라,
외부 데이터(DTO)를 Domain이 이해할 수 있는 Entity로 바꾸는 과정,
즉 Mapper의 역할입니다.
Mapper는 Clean Architecture에서
각 계층의 경계를 지키기 위한 핵심 도구이며,
Domain이 외부 포맷에 오염되지 않도록 보호하는 역할을 담당합니다.
이를 코드로 구현 하면 아래와 같습니다.
data class UserDto(val id: String, val nickname: String)
fun UserDto.toEntity(): User {
return User(id = id, name = nickname)
}그럼 Mapper가 왜 필요한지 좀 더 자세히 알아보도록 하겠습니다.
| 문제 상황 | 위험 요소 |
|---|---|
| Retrofit, Room에서 받은 DTO를 그대로 Domain에서 사용할 경우 | 외부 포맷이 비즈니스 규칙(Entity)을 오염 |
| DTO를 Presentation(UI)까지 전달할 경우 | 화면이 데이터 포맷에 종속됨 • 유지보수 악화 |
| RepositoryImpl에서 DTO를 그대로 반환 | Clean Architecture 경계 붕괴 |
-> 즉, Mapper는 “데이터 포맷”과 “비즈니스 의미”를 분리하는 경계자(Guard) 입니다.
왜 Clean Architecture는 테스트에 강한가?
지금까지 Clean Architecture를 경험하면서 관심사를 분리하면서 구조를 나누는 느낌이 강했습니다.
하지만, 본질적인 목표는 "관심사를 분리해 유지보수를 향상 시키는 것"입니다.
이 과정으로 우리는 "독립된 테스트 가능성" 도 확보할 수 있었습니다.
특히 순수 Kotlin만 사용하는 Domain Layer는 안드로이드 프레임워크 없이
JVM 환경에서 테스트 가능하다는 특징이 있습니다.
이는 Mock Repository를 통해 UseCase만 단독으로 테스트할 수 있다는 뜻으로,
UI를 띄우지 않고도 핵심 로직을 검증 가능할 수 있고 유지보수 비용 절감으로 이어질 수 있습니다.
간단한 코드로 예를 들어보겠습니다.
class GetUserProfileUseCaseTest {
private val fakeRepository = object : UserRepository {
override suspend fun getUser(): User {
return User(id = "1", name = "Alice")
}
}
private val useCase = GetUserProfileUseCase(fakeRepository)
@Test
fun `유저 정보를 정상적으로 반환한다`() = runBlocking {
val result = useCase()
assertTrue(result.isSuccess)
assertEquals("Alice", result.getOrNull()?.name)
}
}
이처럼 Clean Architecture로 명확하게 분리해놓으면, 간단한 테스트 코드도 손쉽게 구현해서
사용할 수 있습니다.
끝마치며
Clean Architecture는 단순히 한 번 읽고 이해할 수 있는 개념이 아니며,
프로젝트를 경험하면서 서서히 체감하게 되는 아키텍처라고 생각합니다.
이번 글을 정리하면서 다양한 개발자들의 글과 관점을 참고했고,
그 속에서 각자가 처한 환경에 따라 Clean Architecture를 해석하는 방식이 다르다는 것도 알 수 있었습니다.
저 역시 하나의 정답을 찾기보다는,
앞으로 진행할 프로젝트에 가장 적합한 구조와 원칙을 선택할 수 있는 개발자로 성장해야겠다 느꼈습니다.
긴 글 읽어주셔서 감사합니다.
