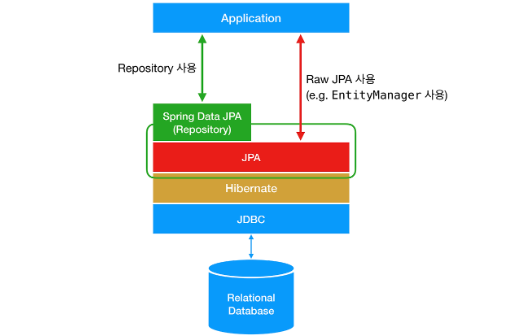
JPA란 무엇인가?
JPA(Java Persistence API)는 자바 진영의 ORM 표준이다. ORM(Object-Relational Mapping)은 객체와 관계형 데이터베이스를 매핑해주는 기술로, 개발자가 SQL을 직접 작성하지 않고도 객체지향적으로 데이터를 관리할 수 있도록 도와준다.
JPA를 사용하는 이유
// JPA 이전의 데이터 처리
String sql = "INSERT INTO users (name, email) VALUES (?, ?)";
PreparedStatement pstmt = connection.prepareStatement(sql);
pstmt.setString(1, user.getName());
pstmt.setString(2, user.getEmail());
pstmt.executeUpdate();
// JPA를 사용한 데이터 처리
@Entity
public class User {
@Id @GeneratedValue
private Long id;
private String name;
private String email;
}
entityManager.persist(user);
위 처럼 개발자가 sql 쿼리를 작성하지 않고, 객체 중심의 개발이 가능하다. 즉 데이터베이스 설계 중심의 패러다임에서 객체 지향적 설계로 전환된 것이다. 이에 따라 객체 지향적 코드 작성으로 가독성이 올라감과 동시에 유지보수성이 올라감을 뜻한다.
영속성 컨텍스트(Persistence Context)
영속성 컨텍스트는 JPA에서 엔티티(Entity)를 관리하는 메모리 상의 공간을 의미한다. 쉽게 말해, 애플리케이션과 데이터베이스 사이에서 엔티티 객체를 캐싱하고, 데이터베이스와의 동기화를 관리하는 역할을 한다.
// 영속성 컨텍스트 예제
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
try {
tx.begin(); // 트랜잭션 시작
// 비영속 상태
User user = new User();
user.setName("김철수");
// 영속 상태
em.persist(user);
// 1차 캐시에서 조회
User foundUser = em.find(User.class, user.getId());
tx.commit(); // 트랜잭션 커밋
} catch (Exception e) {
tx.rollback();
} finally {
em.close();
}영속성 컨텍스트는 영속상태로 관리되는 엔티티를 메모리에 캐싱하여 관리하여, 같은 트랜잭션 내에서 동일한 엔티티를 조회할 때, 데이터베이스를 다시 조회하지 않고 1차 캐시에서 반환한다.
엔티티의 생명주기
비영속(new/transient): 영속성 컨텍스트와 관계없는 상태
영속(managed): 영속성 컨텍스트에 저장된 상태
준영속(detached): 영속성 컨텍스트에서 분리된 상태
삭제(removed): 삭제된 상태
더티 체킹(Dirty Checking)
@Transactional
public void updateUser(Long id, String newName) {
User user = em.find(User.class, id);
user.setName(newName); // 별도의 update 문 불필요
// 트랜잭션 커밋 시점에 변경을 감지하여 자동으로 UPDATE SQL 실행
}
영속성 컨텍스트가 최초 상태를 저장, 복사하여 스냅샷 생성 후 트랜잭션 커밋 시점에 엔티티와 스냅샷 비교하여 변경된 엔티티 찾아 정보 준비
플러시(Flush)
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
try {
tx.begin(); // 트랜잭션 시작
User user = em.find(User.class, 1L);
user.setName("새이름");
// 강제로 플러시 호출
em.flush();
// 이 시점에서 DB와 동기화됨
tx.commit(); // 트랜잭션 커밋
} catch (Exception e) {
tx.rollback();
}
// 영속성 컨텍스트 내부
Map<String, Object> snapshot; // 최초 상태
Map<String, Object> current; // 현재 상태
// 변경 감지
if (!snapshot.equals(current)) {
// 변경 감지!!
}
// 생성된 UPDATE SQL
UPDATE USER
SET name = ?
WHERE id = ?N+1
N+1 문제는 연관된 엔티티를 조회할 때 발생하는 성능 이슈
// N+1 문제가 발생하는 코드
List<Team> teams = em.createQuery("SELECT t FROM Team t", Team.class)
.getResultList();
// 각 팀의 멤버를 조회할 때마다 추가 쿼리 발생
for (Team team : teams) {
team.getMembers().size(); // 추가 쿼리 실행
}
// Fetch Join으로 해결
List<Team> teams = em.createQuery(
"SELECT t FROM Team t JOIN FETCH t.members", Team.class)
.getResultList();
실제 실행되는 SQL:
1. 처음 실행되는 팀 조회 쿼리
SELECT * FROM TEAM; -- 1번 실행
2. 각 팀마다 실행되는 멤버 조회 쿼리
SELECT * FROM MEMBER WHERE TEAM_ID = ? -- N번 실행
SELECT * FROM MEMBER WHERE TEAM_ID = ?
SELECT * FROM MEMBER WHERE TEAM_ID = ?
...해결방법
Fetch Join 사용
// JPQL fetch join
List<Team> teams = em.createQuery(
"SELECT t FROM Team t JOIN FETCH t.members", Team.class)
.getResultList();
// 이제 members 접근시 추가 쿼리 발생하지 않음
for (Team team : teams) {
team.getMembers().size(); // 이미 로딩되어 있음
}
-- 한 번의 조인 쿼리로 해결
SELECT T.*, M.*
FROM TEAM T
JOIN MEMBER M ON T.ID = M.TEAM_ID
@BatchSize 사용
@Entity
public class Team {
@BatchSize(size = 100) // 여러 건을 한번에 조회
@OneToMany(mappedBy = "team")
private List<Member> members = new ArrayList<>();
}
-- 1. 팀 조회
SELECT * FROM TEAM;
-- 2. 멤버 조회 (IN 절 사용으로 쿼리 횟수 감소)
SELECT * FROM MEMBER
WHERE TEAM_ID IN (?, ?, ?, ...); -- 최대 100개씩 묶어서 조회
EntityGraph 사용 (Spring Data JPA)
@Repository
public interface TeamRepository extends JpaRepository<Team, Long> {
@EntityGraph(attributePaths = {"members"})
List<Team> findAll();
}
Spring Data JPA 활용 팁
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
// 메서드 이름으로 쿼리 생성
List<User> findByNameAndAgeGreaterThan(String name, int age);
// @Query 애노테이션으로 직접 JPQL 작성
@Query("SELECT u FROM User u WHERE u.email like %:email%")
List<User> findByEmailPattern(@Param("email") String email);
}
+ queryDSL
public class UserRepositoryImpl implements UserRepositoryCustom {
private final JPAQueryFactory queryFactory;
public UserRepositoryImpl(EntityManager entityManager) {
this.queryFactory = new JPAQueryFactory(entityManager);
}
@Override
public Optional<User> findByIdWithSocial(Long userId) {
return Optional.ofNullable(
queryFactory
.selectFrom(QUser.user)
.leftJoin(QUser.user.social).fetchJoin()
.where(QUser.user.userId.eq(userId))
.fetchOne()
);
}
}
queryDSL 예제
//연재중인 작품 인기순 정렬 - (졸아요 즐겨찾기 + 댓글)top 50
@Override
public List<Novel> findPopularNovelsByTag(NovelSortRequestDTO request) {
return queryFactory
.selectFrom(novel)
.leftJoin(novel.user).fetchJoin()
.where(
novel.tag.eq(request.getMainTag()),
novel.status.eq(NovelStatus.PUBLISHED)
)
.orderBy(
getOrderSpecifier(request.getType())
)
.fetch();
}
@Override
public List<Novel> findNovelByOrder(NovelSortType novelSortType) {
return queryFactory
.selectFrom(novel)
.leftJoin(novel.user).fetchJoin()
.where(novel.status.eq(NovelStatus.PUBLISHED))
.orderBy(getOrderSpecifier(novelSortType))
.limit(10)
.fetch();
}
private OrderSpecifier[] getOrderSpecifier(NovelSortType sortType) {
return switch (sortType) {
case LATEST -> new OrderSpecifier[] {
novel.episodeUpdatedAt.desc()
};
case NAME -> new OrderSpecifier[] {
novel.title.asc()
};
case POPULARITY -> new OrderSpecifier[] {
novel.likeCount.add(novel.favoriteCount).desc(), // 좋아요+즐겨찾기 합산
novel.episodeUpdatedAt.desc() // 같은 인기도일 경우 최신순
};
};
}