
💡 Lowe, D. G. (2004). Distinctive image features from scale-invariant keypoints.
International journal of computer vision, 60, 91-110.
1. Introduction
이미지를 회전하거나 크기를 조절하는 등 변화를 주었을 때, 변하지 않는(invarient)한 특징(feature)에 대해 서술하고 있다. 이러한 이미지 feature들을 찾기 위한 방법은 다음과 같다.
- Scale-space extrema detection
- Keypoint localization
- Orientation assignment
- Keypoint descriptor
정리하자면, 이미지로부터 특징점을 찾고, 각 특징에 대해 keypoint descriptor를 생성하며 outlier 혹은 잘못 매칭되는 경우를 제거하여 정확하게 한 뒤, 기술자의 차이가 가장 적은 곳이 매칭되는 것이다.
2. Related Research
3. Detection of Scale-Space Extrema
Introduction에서 언급됐듯 cascade filtering approach를 통해 keypoint를 찾는 과정을 진행한다. 가장 먼저 같은 물체에 대해 시점이 달라질 때, 반복되는 location과 scale을 identify해야한다. 모든 가능한 영역에서 stable한 feature를 찾기 위해 Scale Space(Witkin, 1983)으로 알려진 continuous function of scale을 이용할 것이다.
Koenderink(1984)와 Lindeberg(1994)에서 보여졌듯 유일하게 가능한 scale-space kernel은 Gaussian function이다.
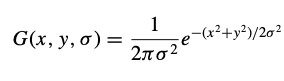
여기에서 I(x, y)는 인풋 이미지이고, G(x, y,σ)는 가우시안 필터이며, 이 둘을 컨벌루션하여 L(x, y,σ)라는 블러된 이미지를 얻을 수 있다. 그리고, 이렇게 블러된 이미지들을 여러 개 만든 뒤 각 이미지들 간의 차이를 도출하는 DoG(Difference of Gaussian)를 이용한다.(Lowe, 1999)
DoG는 LoG(Laplacian of Gaussian)과 유사하지만, 계산 과정을 줄인다는 점에서 더 효과적이므로 LoG가 아닌 DoG를 선택하였다.
위의 식을 통해 k가 1에 접근하여 (k-1)이 0에 가까워질 수록 approximation error가 0에 가까워짐을 알 수 있다. 그러나 실험을 통해 k=√2와 같이 차이가 커도 stability에 큰 영향을 끼치지 않는 것을 알 수 있다.
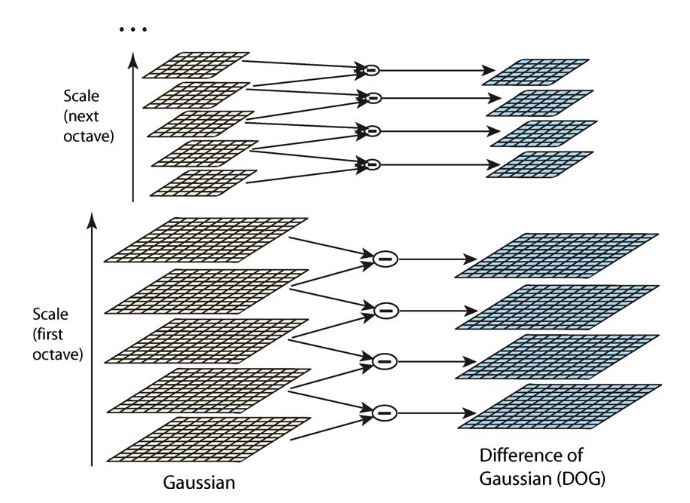
DoG를 만드는 과정은 아래와 같이 초기 이미지에 점진적으로 가우시안을 컨벌루션하여 constant k로 분리되는 이미지를 scale-space에서 생성한다(왼쪽 열). 이 때. scale-space의 각 octave의 간격 정수 s로 나누기로 선택한다. 즉, k=2^(1/s). 각 옥타브에 대해 s+3개의 블러된 이미지를 생성하여 최종 극값 감지가 전체 옥타브를 포괄하도록 해야 한다. 옥타브를 바꿀 때는 σ를 2배하여 down-sample한다. 그러면 σ에 대한 샘플링의 정확도는 이전 옥타브와 다르지 않지만 계산은 크게 줄어든다.
3.1. Local Extrema Detection
D(x, y,σ)의 최대 최소값을 찾기 위해 각각의 sample point는 같은 이미지 내에서 주변의 8개의 point들, 인접한 이미지의 각 9 point들(총 26개)과 비교된다. 이 이웃 모두보다 크거나 모든 이웃보다 작은 경우에만 선택된다. 앞선 몇번의 체크로 인해 대부분의 포인트들이 제거된 것이므로 이러한 체크하는 방식은 계산이 많이 들지 않는다.
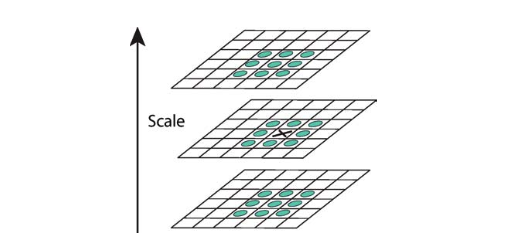
중요한 문제는 극값을 안정적으로 감지하는 데 필요한 이미지 및 스케일 영역에서 샘플링 빈도를 결정하는 것이다. 그러나 극값이 임의로 서로 가까워질 수 있기 때문에 모든 극값을 감지할 수 있는 샘플의 최소 간격은 없다. 그러므로 효율성과 완전성을 절충하는 지점을 찾기 위해 시뮬레이션을 진행하여 가장 신뢰할 수 있는 결과를 제공하는 주파수를 사용해야한다.
3.2. Frequency of Sampling in Scale
극값을 안정하게 최대회하는 sampling frequency를 결정하는 실험을 통해 sampling 3 scales per octave가 가장 효과적임을 파악하여 이를 이용한다.
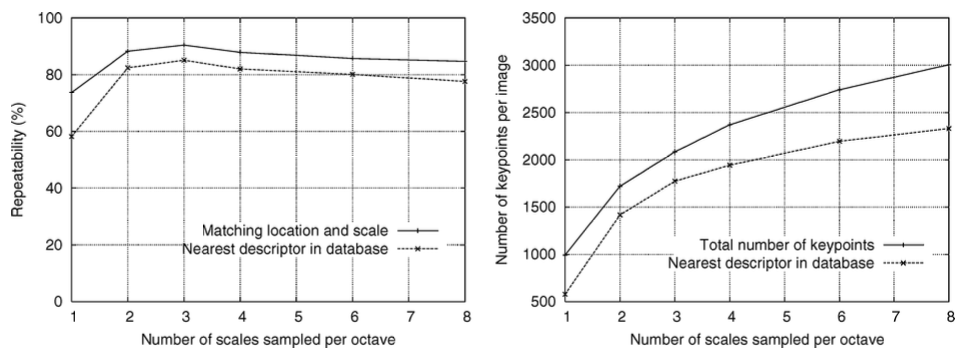
이 때, 우측 그래프를 통해 볼 수 있듯이 scales sampled per octave가 증가할 수록 keypoints의 전체 수도 증가하는 것을 알 수 있다. 더 정확한 결과를 위해 points가 많을수록 좋지만 계산 비용이 증가하므로 이 논문의 실험에서는 옥타브당 3개의 scales sample을 이용한다.
3.3. Frequency of Samling in the Spatial Domain
Scale-space에서 옥타브 당 샘플링 빈도를 결정한 것처럼, smoothing scale과 관련하여 이미지 도메인에서의 샘플링 빈도를 결정해야한다.
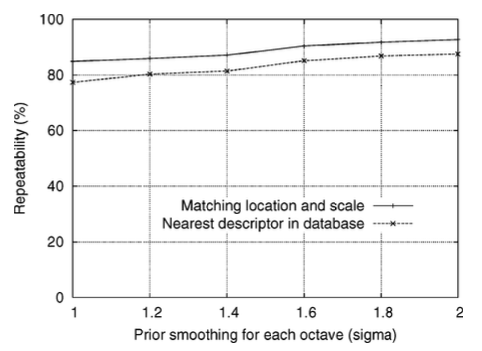
위 그림은 옥타브에 대한 scale-space를 구축하기 전에 각 이미지에 적용하는 smoothing 정도(σ)를 결정하는 실험 결과이다. σ가 증가함에 따라 keypoint 감지의 반복성이 증가하지만, 효율성 측면에서 σ가 크면 비용이 들기 때문에 최적인 σ=1.6을 사용하기로 선택했다.
4. Accurate Keypoint Localization
각 픽셀들을 이웃 픽셀들과 비교하여 keypoint 후보가 결정되고 나면, 그 다음은 곡률의 위치, 규모 및 비율에 대해 인근 데이터에 대한 세부적으로 fit 시키는 과정이다. 대비가 낮거나, edge를 따라 잘 localized되지 않는 points들은 제거된다. 원래는 단순히 central sample point의 위치와 규모에 대해 keypoint를 찾았다(Lowe, 1999). 그러나 local sample point에 3D 2차 함수를 맞추는 방법이 개발되었고 이를 이용한다(Brown and Lowe, 2002).
원점이 샘플 지점에 있도록 이동된 스케일 공간 함수 D(x, y, σ)의 Taylor expansion(최대 2차 항)을 사용한다.
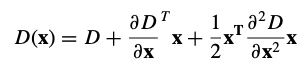
여기서 D와 그 도함수는 샘플 포인트에서 평가되고 x = (x, y, σ)^T는 이 포인트로부터의 오프셋이다. 극값의 위치 xˆ는 이 함수에 미분을 구하고 x를 0으로 설정한다.
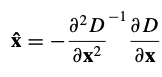
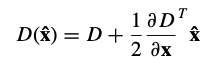
4.1. Eliminating Edge Responses
안정성을 위해 대비가 낮은 keypoints를 제거하는 것만으로는 충분하지 않다. DoG는 가장자리를 따라 위치가 제대로 결정되지 않기 때문에 작은 양의 노이즈에 불안하더라도 가장자리를 따라 강한 response를 갖는다. DoG에서 제대로 정의되지 않은 peak는 가장자리에 대해 큰 principal curvature를 가지지만 수직 방향에 대해서는 작은 곡률을 가진다. 2 × 2 Hessian matrix H를 이용해서 principal curvature를 계산할 수 있다.
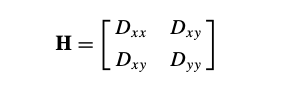
H의 고유값은 D의 주 곡률에 비례한다. 꼭 고유값을 다 찾을 필요는 없고 Trace와 Determinant를 이용해 고유값을 간접적으로 알 수 있다.
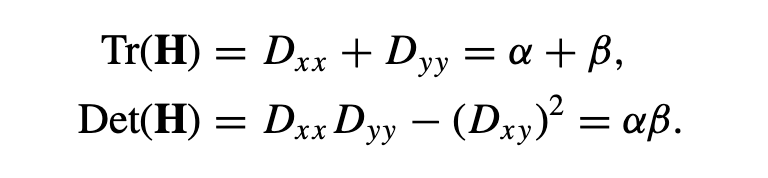
r은 두 개의 고윳값의 비율이고, trace와 determinant를 활용하여 계산하기에 효율적인 비율 r을 찾을 수 있다.
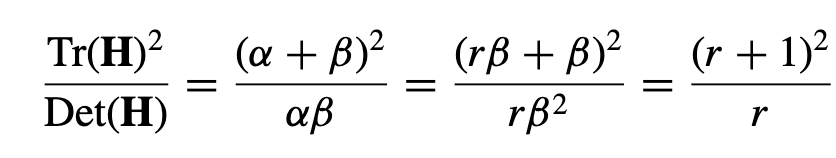
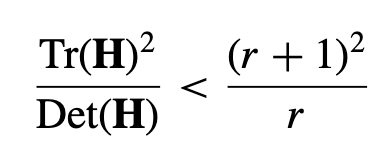
이 논문에서는 r=10을 이용하며, 이는 주 곡률 간의 비율이 10보다 큰 키포인트를 제거한다.
로컬 이미지 속성을 기반으로 각 keypoint에 방향을 할당함으로써 keypoint descripter는 이 방향을 기준으로 표현될 수 있으므로 이미지 회전에 대한 불변성을 달성할 수 있다.
5. Orientation Assignment
키포인트의 scale은 가장 가까운 스케일을 가진 Gaussian smoothed image L을 선택하는 데 사용되므로 모든 계산은 스케일 불변(scale-invariant) 방식으로 수행된다. 이 스케일에서 각 이미지 샘플 L(x, y)에 대해 기울기 크기 m(x, y) 및 방향 θ(x, y)는 픽셀 차이를 사용하여 미리 계산된다.
Orientation histogram은 keypoint 주변 영역내의 sample point의 그라데이션 방향으로 형성된다.60도 범위의 방향을 포괄하는 36개의 bin이 있으며, histogram에 추가된 각 sample은 gradient magnitude와 key point의 scale의 1.5배인 σ를 갖는 gaussian-weighted circular window에 의해 가중치가 부여된다.
Orientation histogram의 peak는 local gradient의 주요 방향이다.
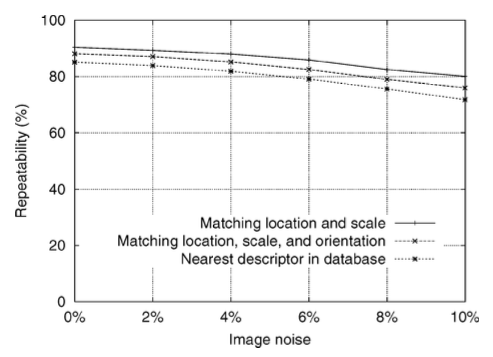
이미지 노이즈가 10%까지 추가가 되어도 95%의 정확도를 가지고 있는 것을 알 수 있다. 위 그래프를 통해 알 수 있듯이 SIFT는 큰 픽셀 노이즈에도 견딜 수 있다. 오류가 발생한다면 그것은 initial location과 scale detection으로 인한 것이다.
6. The Local Image Descriptor
각 keypoint에 image location, scale, orientation을 할당하여 반복가능한 local 2D 좌표계를 적용하므로 불변성을 제공했다. 이제는 조명이나 3D 시점의 변화에 대해서도 불변성을 유지할 수 있도록하는 local image descriptor을 계산해야한다.
기존에 쓰이던 방식은 keypoint 주변의 local image intensities(강도)를 샘플링하고 정규화된 correlation measure을 사용해 match하는 것이었으나, 3D 시점이 변경되는 등 상황에서 샘플이 잘못 등록되는 문제가 발생할 수 있다(Edelman et al, 1997). 그러므로 생물학적 시각의 뉴런 모델을 기반으로 하여 어느 정도 기울기 위치를 수용할 수 있는 방법을 이용했다. 이와 비슷한 아이디어를 활용하지만, 다른 계산 메커니즘을 사용하여 위치 이동을 허용하고자 한다.
6.1. Descriptor Representation
먼저, 이미지에서 키포인트 주변의 gradient 크기와 방향을 고려한다. keypoint의 스케일에 맞게 이미지를 블러처리하여 gradient를 샘플링한 뒤, 회전 불변성을 위해 descriptor 좌표와 gradient 방향을 keypoint 방향과 맞추어 회전시킨다.
Descriptor의 계산에는 가우시안 가중 함수가 사용되고 있다. 이 함수는 Descriptor window 폭의 절반인 값 σ를 이용하여 각 샘플 지점에 가중치를 부여하고 있으며 이 가중치는 중심에서 멀어질수록 부드럽게 감소하고, 위치 오차에 영향을 적게 받는 gradient에 중요성을 적게 부여한다.
키포인트 descriptor는 방향 히스토그램을 이용하여 생성한다. 4 × 4 샘플 영역에서 방향 이동을 고려하면서 방향을 파악하고 있다. 각 방향 히스토그램에는 여덟 가지 방향이 있으며, 화살표의 길이는 히스토그램 항목 크기를 나타낸다.
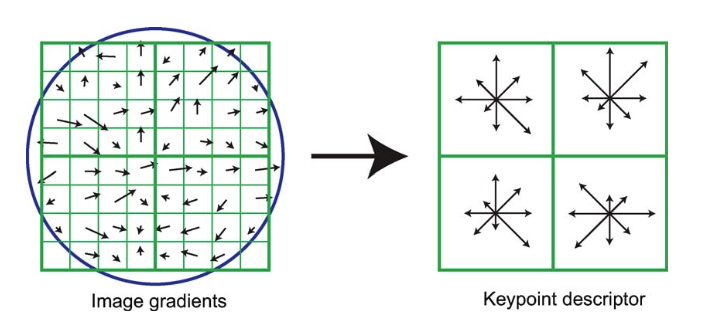
Trilinear interpolation(삼선형 보간)을 사용하여 gradient 샘플 값을 인접한 히스토그램 항목으로 분배한다. descriptor는 모든 방향 히스토그램 항목 값으로 구성되어 있다. 실험적으로, 4 × 4 배열의 히스토그램과 각각 8개의 방향 항목으로 총 128개의 특징 벡터를 사용하는 것이 좋은 결과를 나타낸다.
마지막으로, 조명 변화의 영향을 줄이기 위해 특징 벡터를 수정한다. 픽셀 값에 상수를 곱하는 대비 변경은 벡터 정규화로 취소될 수 있다. 하지만 비선형 조명 변화는 gradient크기에 영향을 줄 수 있어서, 큰 gradient의 영향을 줄이기 위해 임계값을 설정하고 방향 분포를 강조하는 방향으로 벡터를 다시 정규화한다. 0.2의 임계값은 실험적으로 결정되었다.
6.2. Descriptor Testing
Descriptor의 복잡성(complexity)를 확인하기 위해 2개의 파라미터를 활용할 수 있는데, 히스토그램의 방향 수 r과 방향 히스토그램의 n × n 배열 너비 n이다. Result descriptor의 크기는 rn^2이다. 복잡성이 증가함에 따라 대규모 데이터에 대해 더 잘 식별할 수 있지만, 왜곡과 occuusion에 대해 더욱 민감해진다.
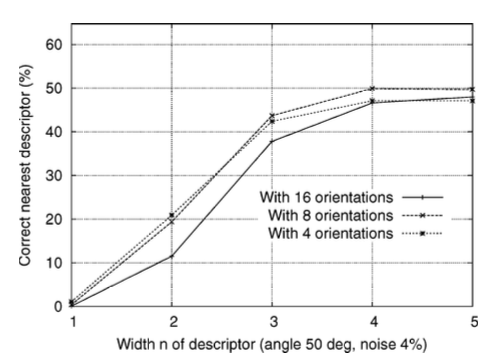
위의 그래프를 통해 n=1일 때는 성능이 매우 좋지 않지만 n=4까지는 성능이 효과적으로 향상했으며, 그 이후에는 왜곡에 민감해져 매칭을 방해할 수 있다는 것을 보여준다. 따라서 이 논문에서는 4 × 4 descriptor with 8 orientations 총 128 dimension을 이용한다. 차원이 다소 높아보일 수 있지만, 저차원 descriptor보다 지속적으로 성능이 더 좋으며 아래에 기술된 nearest-neighbor 방법을 사용할 때 계산 비용이 낮게 유지된다.
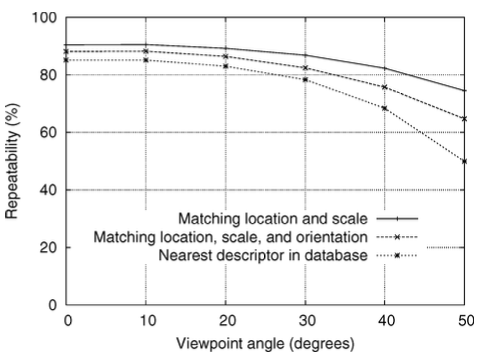
6.3. Sensitivity to Affine Change
아래 그래프는 affine 변환에 대한 descriptor의 민감도(sensitivity)에 대해 보여준다. Affine 변환이 증가함에 따라 반복성이 감소했지만, 최종 매칭 정확도는 시점이 50도 변경되는 경우에도 50% 이상을 유지함을 알 수 있다.
6.4. Matching to Large Databases
데이터베이스에 있는 특징점 수에 따라 매칭의 신뢰도가 어떻게 변하는지 알아내는 문제는 feature 구분을 측정하기 위한 중요한 문제이다.
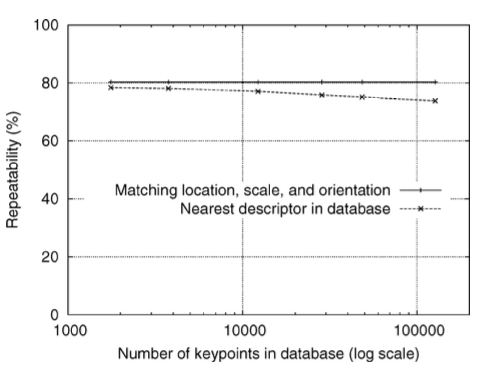
데이터베이스의 수가 증가함에 따라 매칭 신뢰성이 감소하지만, 많은 올바른 매치가 매우 큰 데이터베이스 크기에서도 계속해서 발견될 것으로 보인다.
변환된 이미지에서 올바른 매칭 위치와 방향으로 식별된 키포인트의 백분율을 나타내는 실선이 평평한 이유는 각 값에 대해 전체 데이터베이스에서 테스트를 실행했지만, 분산 데이터베이스만 변경했기 때문이다. 두 선 사이의 간격이 작다는 것은 매칭 실패가 초기 특징 지역화와 방향 할당 문제보다는 특징의 독창성 문제보다 발생한다는 것을 나타낸다. 이러한 문제는 매우 큰 데이터베이스 크기에서도 계속된다.
7. Application to Object Recognition
객체 인식은 먼저 각 keypoint를 train 이미지에서 추출된 keypoint 데이터베이스와 독립적으로 매칭하는 것으로 이루어진다. 초기 매치 중 많은 부분은 모호한 특징이나 배경 혼잡으로 인해 잘못될 수 있으므로 객체와 그 포즈에 동의하는 적어도 3개 이상의 특징들의 clusters를 먼저 식별한다. 이러한 클러스터는 개별 특징 매치보다 올바를 확률이 훨씬 높다. 각 클러스터는 모델에 대한 자세한 기하학적 적합성을 확인함으로써 검증된다.
7.1. Keypoint Matching
Train 이미지의 keypoint database에서 각 keypoint의 nearest neigbor를 찾아야하는데, 이는 invariant descriptor vector의 Euclidean 거리가 최소인 keypoint를 의미한다.
그러나 배경 noise에서 비롯되거나 train 이미지에서 감지되지 않은 feature들은 올바른 매치가 아닐 수 있으므로, 이들을 제거해야한다. 이를 위해 가장 가까운 이웃과 두 번째로 가까운 이웃 간의 거리를 비교한다. 이 때, 동일한 object에 대해 여러개의 train 이미지가 있다면, 두 번째로 가까운 이웃은 첫 번째와 다른 객체에서 온 것으로 정의한다.
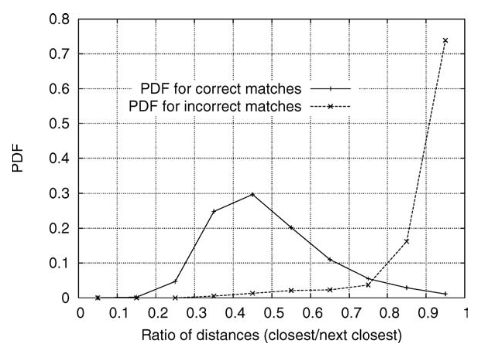
위 그래프는 각 keypoint의 가장 가까운 이웃과 두 번째로 가까운 이웃의 비율로 나타낸 올바른 매치와 잘못된 매치의 확률 밀도 함수(PDF)를 보여준다. Object recognition 구현에서는 가장 가까운 이웃과 두 번째로 가까운 이웃 간의 거리 비율이 0.8보다 큰 매치를 모두 거부하여 거짓 매치의 90%를 제거하고 올바른 매치의 5% 미만을 제거한다. 이와 같은 방식으로 이미지를 처리하면서, 스케일 및 방향 변경, 30도의 깊이 회전, 그리고 이미지에 2%의 노이즈를 추가하여 데이터베이스의 40,000개 키포인트와 매칭시킨다.
7.2. Efficient Nearest Neighbor Indexing
Keypoint descriptor가 128차원이므로 계산 속도 향상을 위해 Best-Bin-First (BBF) algorithm (Beis and Lowe, 1997) 근사 알고리즘을 이용한다. 높은 확률로 가장 가까운 이웃을 반환하지만 근사적인 방법이다.
BBF 알고리즘은 k-d 트리 알고리즘의 수정된 검색 순서를 사용하여 특징 공간에서의 bin들을 쿼리 위치로부터 가장 가까운 거리 순으로 검색한다. 이 우선 순위 검색 순서는 Arya와 Mount (1993)에 의해 처음으로 조사되었으며, 그들은 이를 효율적인 계산 속성에 대해 더 연구했다(Arya et al., 1998).
BBF 알고리즘이 이 문제에 특히 잘 작동하는 이유 중 하나는 가장 가까운 이웃이 두 번째로 가까운 이웃의 거리보다 0.8배 미만인 경우에만 일치를 고려하기 때문에 매우 유사한 거리에 있는 많은 이웃들을 정확하게 해결할 필요가 없기 때문이다.
7.3. Clustering with the Hough Transform
작거나 가려진 객체를 인식하기 위해 최소한의 feature matching으로 객체 인식의 성능을 극대화해야 한다. 배경 noise에서 비롯된 거짓 매칭을 걸러내는 것은 가능하지만 다른 유효한 객체에서 비롯된 매칭을 제거하는 데 어려움이 있다. RANSAC 또는 최소 중앙 제곱과 같은 흔히 알려진 견고한 적합 방법은 이상치의 비율이 50% 이하로 떨어질 때 성능이 저하될 수 있다. 그러나 Hough 변환을 사용하여 특징을 포즈 공간에서 클러스터화함으로써 훨씬 뛰어난 성능을 얻을 수 있다.
Hough 변환은 각 특징이 해당 특징과 일치하는 모든 객체 포즈에 투표함으로써 일관된 해석을 가진 특징 클러스터를 식별한다. 이는 여러 특징 클러스터가 동일한 객체의 포즈를 지지할 때 해석이 올바를 확률이 단일 특징보다 훨씬 높다는 것을 의미한다. 각 keypoint는 2D 위치, 크기 및 방향을 지정하며, 데이터베이스의 각 일치하는 keypoint는 해당 트레이닝 이미지에 상대적인 keypoint parameter를 가지고 있다.
그러나 이러한 방식의 예측은 큰 오차 범위를 가지며 근사치에 불과하다. 따라서 방향에 대해 30도의 넓은 bin 크기, 크기에 대해서는 2배의 범위, 위치에 대해서는 최대 투영 트레이닝 이미지 차원의 0.25배를 사용하여 큰 오차 경계를 가지게 하며 각 keypoint match를 각 차원에서 가장 가까운 2개의 bin에 투표하여 가설당 총 16개의 항목을 만들고 포즈 범위를 더욱 넓혀준다.
8. Recognition Examples


