알고리즘
1.선택 정렬(Selection Sort)
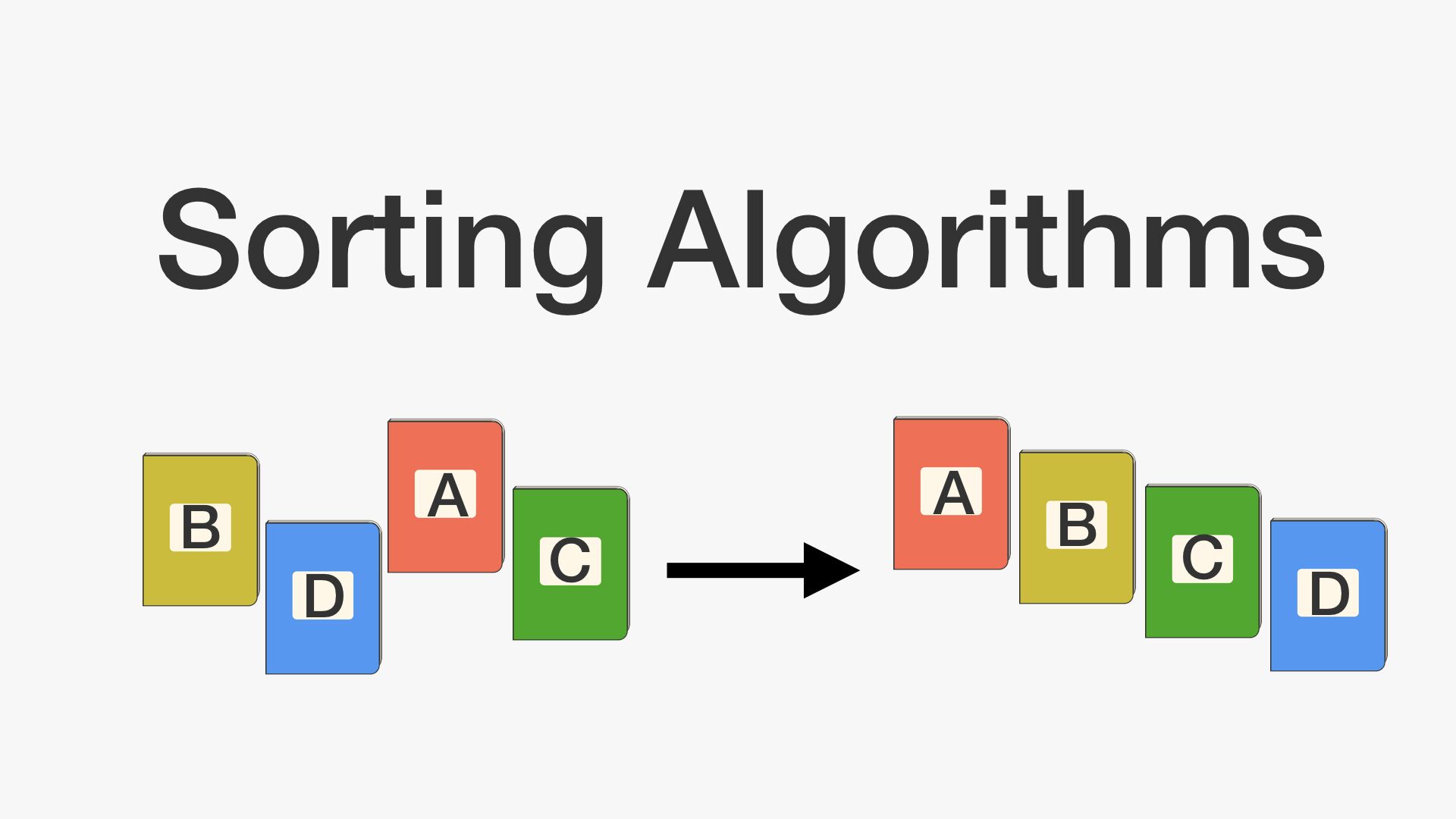
선택정렬이란? 다음과 같은 순서를 반복하며 정렬하는 알고리즘 주어진 데이터 중, 최소값을 찾음 해당 최소값을 데이터 맨 앞에 위치한 값과 교체함 맨 앞의 위치를 뺀 나머지 데이터를 동일한 방법으로 반복함 알고리즘 구현 for stand in range(le
2.버블정렬(Bubble Sort)
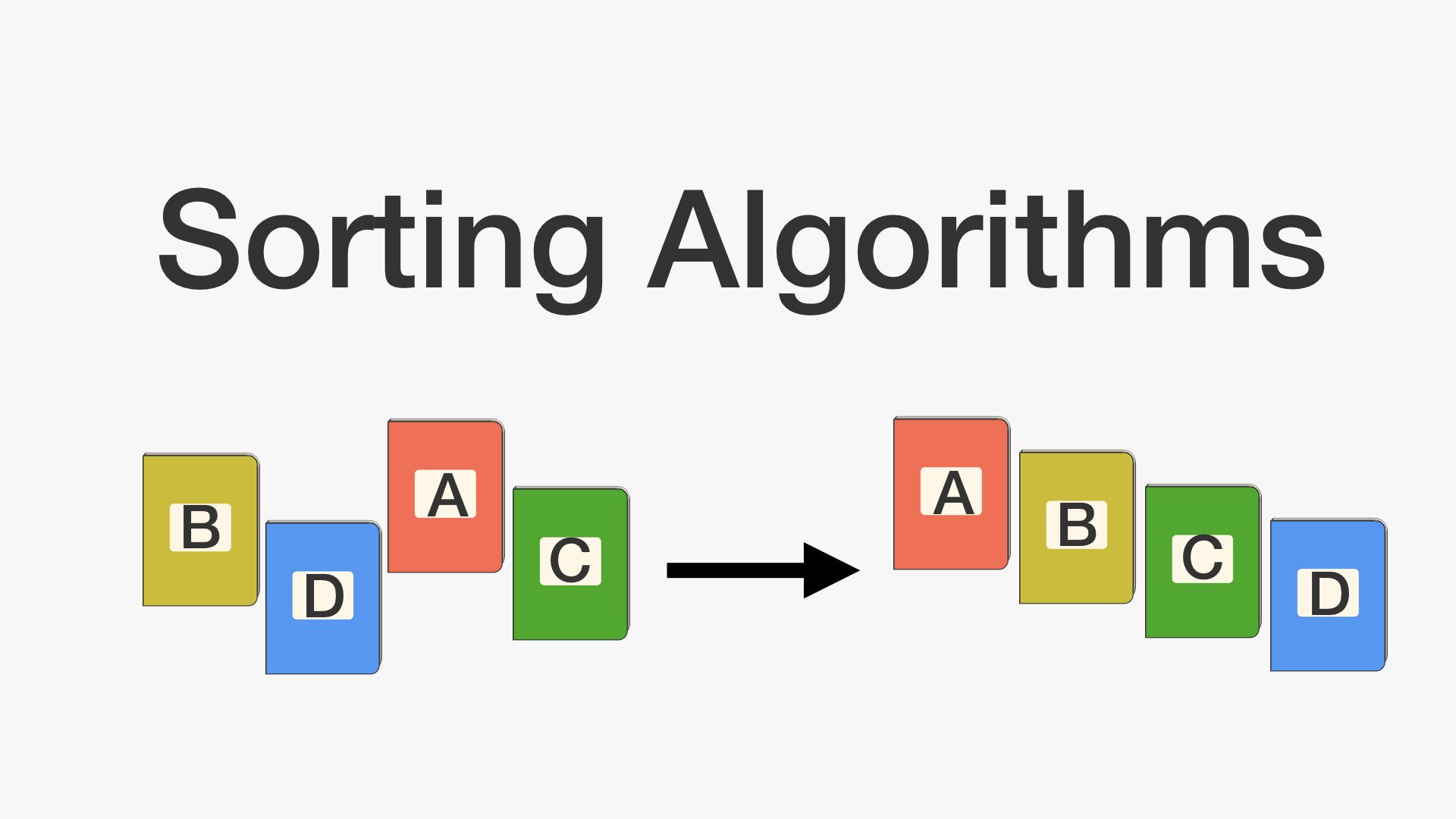
버블정렬이란? 두 인접한 데이터를 비교하여, 앞에 있는 데이터가 뒤에 있는 데이터보다 크면, 자리를 바꾸는 정렬 알고리즘 n개의 리스트가 있는 경우 최대 (n-1)번의 로직을 적용한다. 로직을 1번 적용할 때마다 가장 큰 숫자가 뒤에서부터 1개씩 결정된다. 로직이 경우
3.공간복잡도
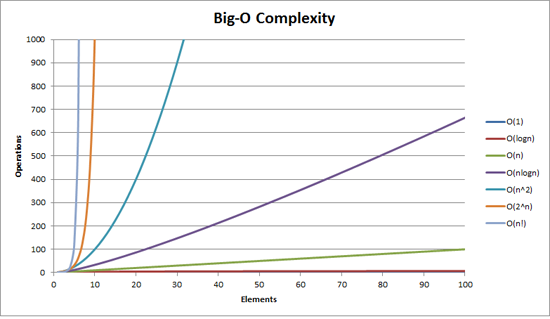
알고리즘 계산 복잡도는 다음 두 가지 척도로 표현될 수 있음시간 복잡도: 얼마나 빠르게 실행되는지공간 복잡도: 얼마나 많은 저장 공간이 필요한지프로그램을 실행 및 완료하는데 필요한 저장공간의 양을 뜻함총 필요 저장 공간고정 공간 (알고리즘과 무관한 공간): 코드 저장
4.삽입정렬(Insertion Sort)
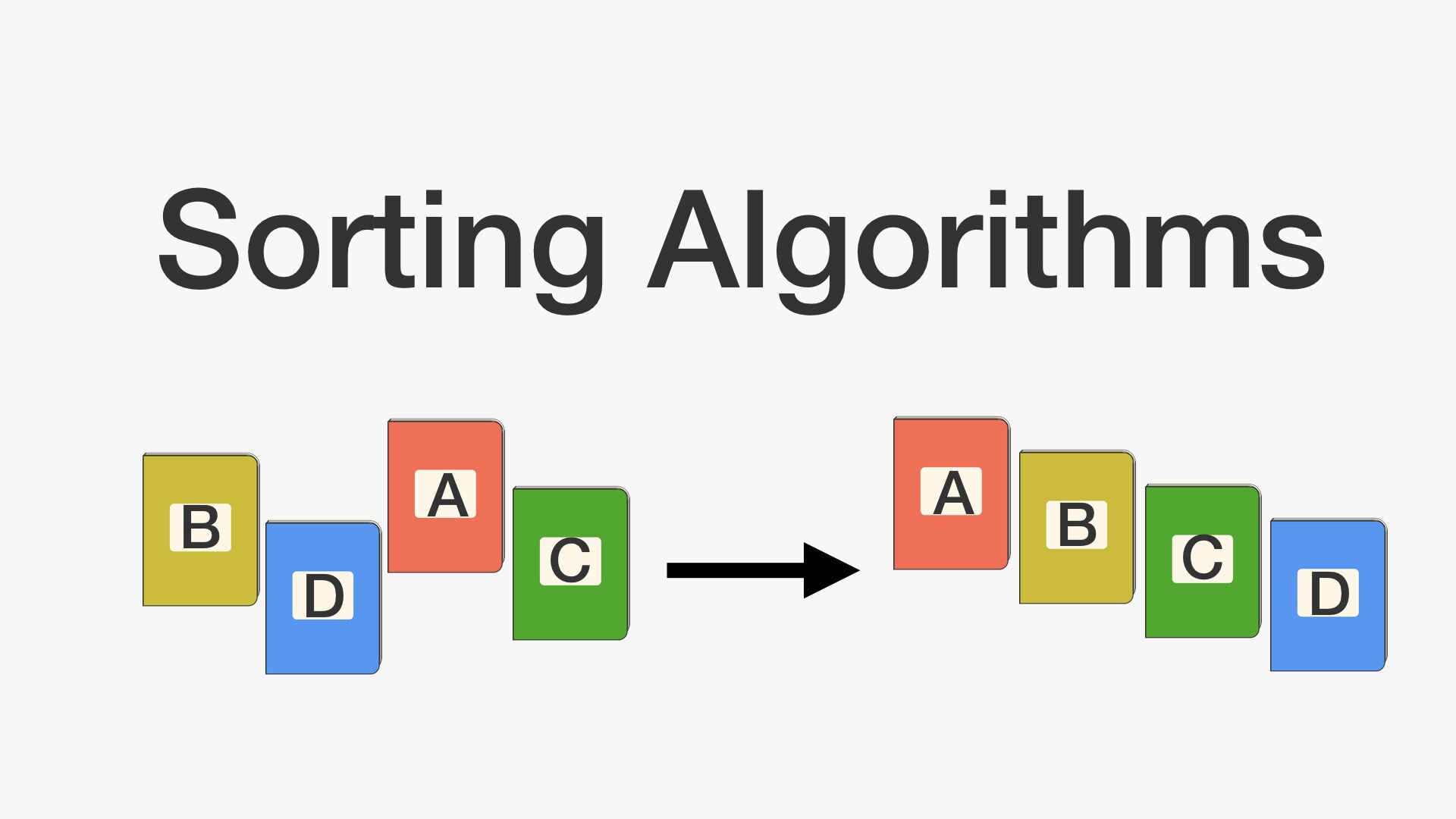
삽입 정렬은 두 번째 인덱스부터 시작해당 인덱스(key 값) 앞에 있는 데이터(B)부터 비교해서 key 값이 더 작으면, B값을 뒤 인덱스로 복사이를 key 값이 더 큰 데이터를 만날때까지 반복, 그리고 큰 데이터를 만난 위치 바로 뒤에 key 값을 이동출처: http
5.알고리즘 - 동적계획법과 분할정복
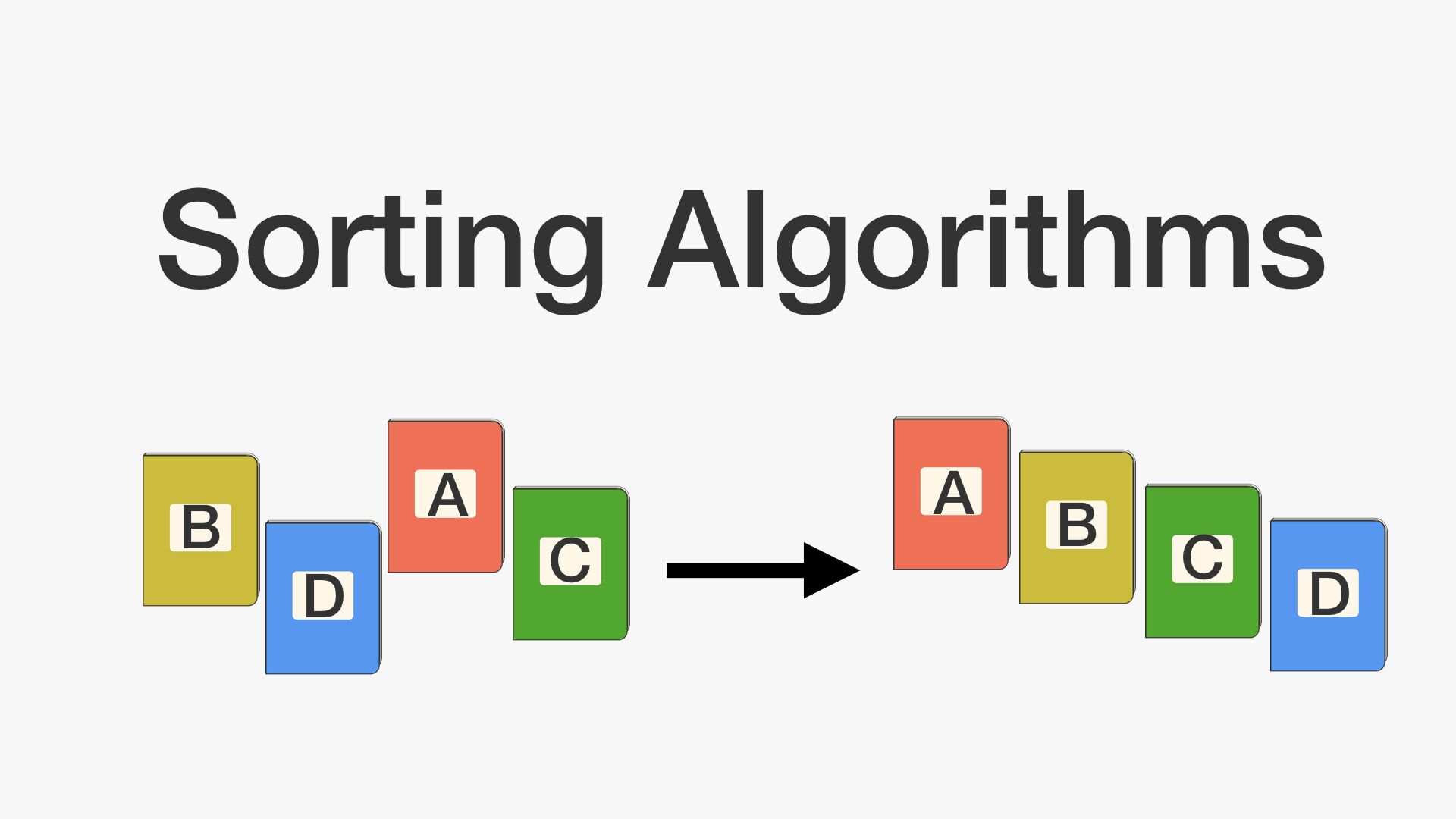
입력 크기가 작은 부분 문제들을 해결한 후, 해당 부분 문제의 해를 활용해서, 보다 큰 크기의 부분 문제를 해결, 최종적으로 전체 문제를 해결하는 알고리즘상향식 접근법으로, 가장 최하위 해답을 구한 후, 이를 저장하고, 해당 결과값을 이용해서 상위 문제를 풀어가는 방식
6.알고리즘 - 퀵 정렬
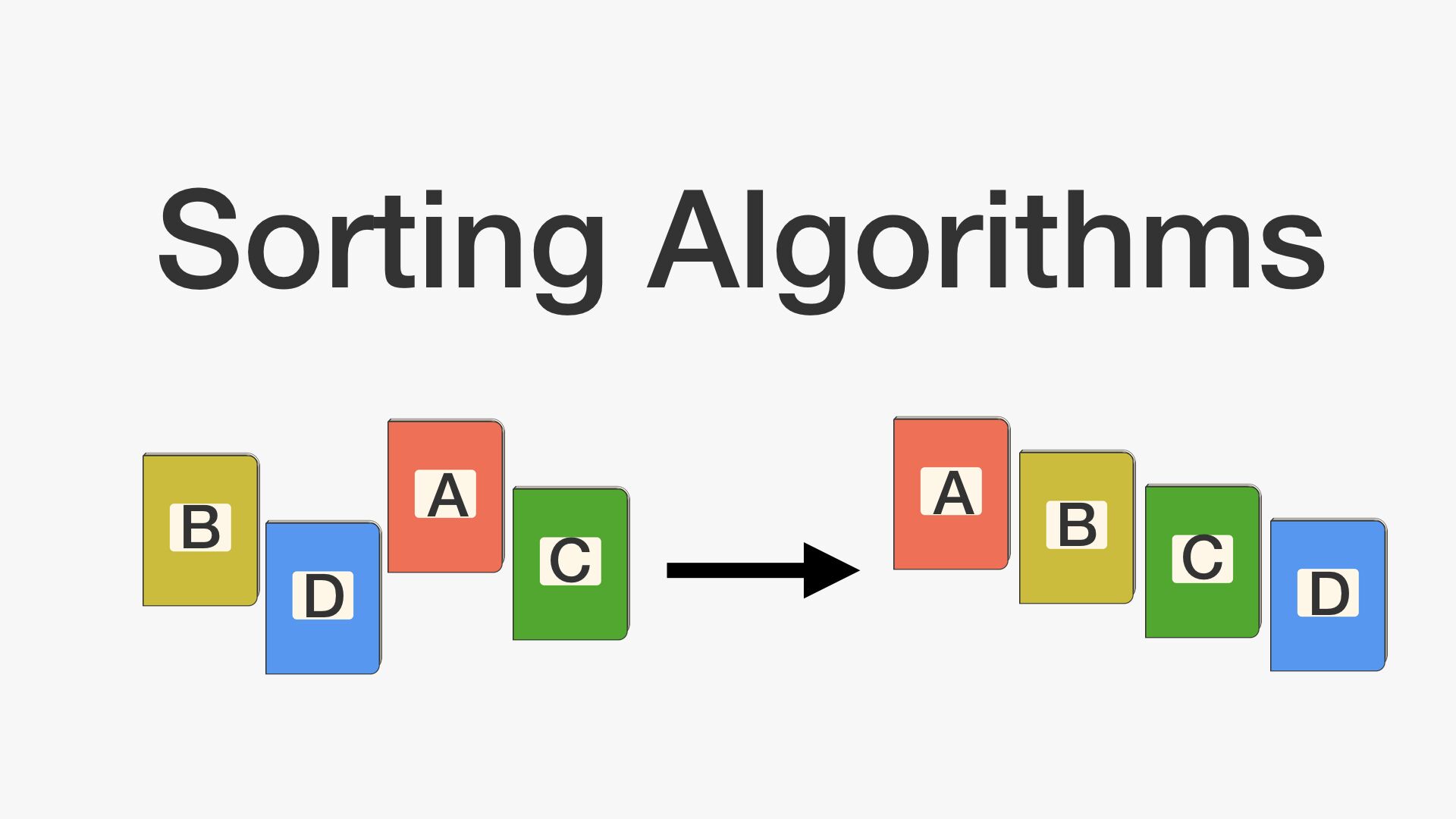
기준점(pivot)을 정해서, 기준점보다 작은 데이터는 왼쪽, 큰 데이터는 오른쪽으로 모으는 함수를 작성한다.각 왼쪽, 오른쪽은 재귀용법을 사용해서 다시 동일 함수를 호출하여 위 작업을 반복한다.함수는 왼쪽 + 기준점(pivot) + 오른쪽을 리턴한다.quicksort
7.알고리즘 - 병합정렬
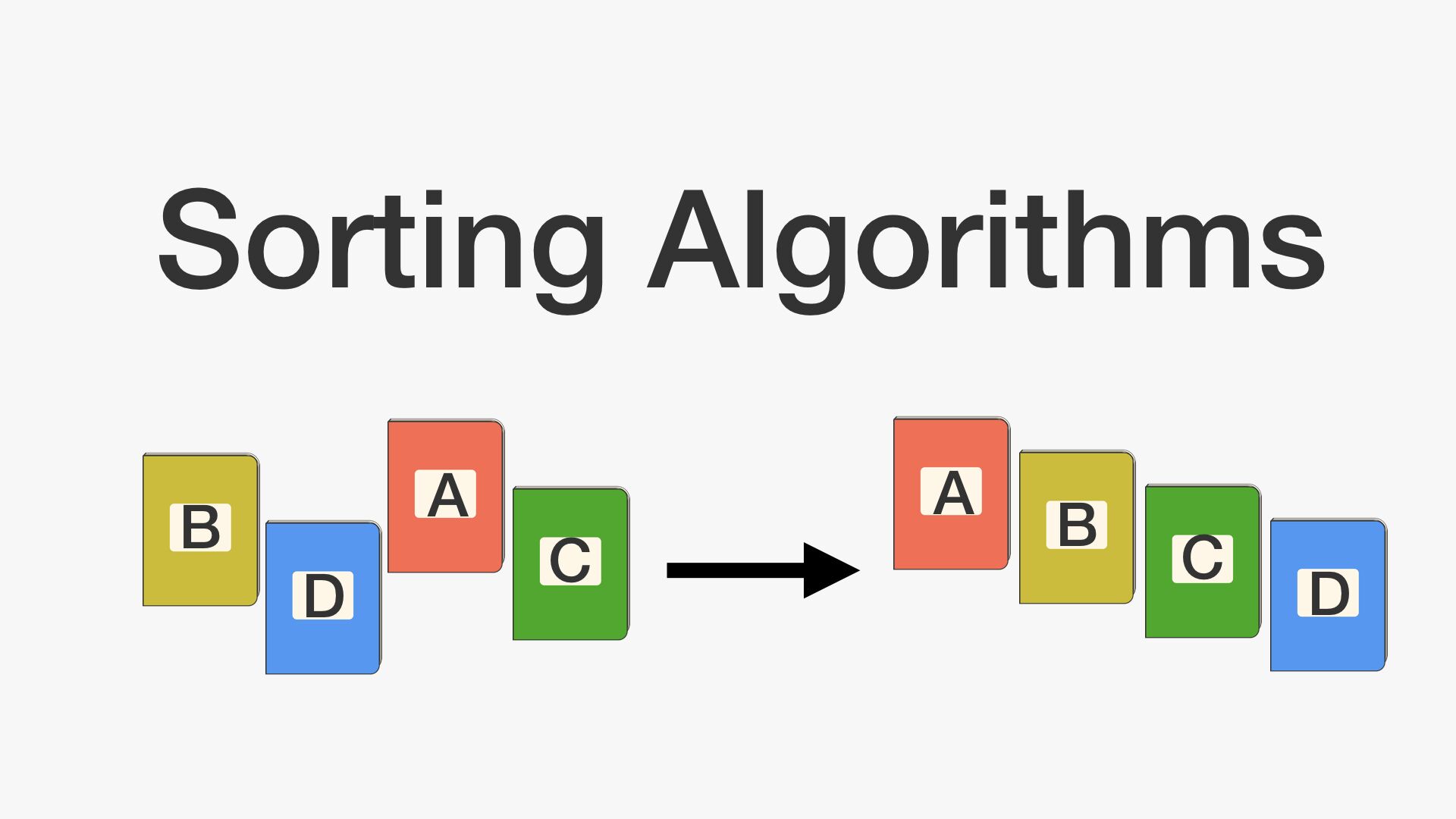
재귀용법을 활용한 정렬 알고리즘이다. 리스트를 절반으로 잘라 비슷한 크기의 두 부분 리스트로 나눈다.각 부분 리스트를 재귀적으로 합병 정렬을 이용해 정렬한다.두 부분 리스트를 다시 하나의 정렬된 리스트로 합병한다.데이터가 네 개 일때.ex) data_list = 1,