
머신러닝 모델을 만드는 과정

1. 과거의 데이터를 준비한다.
2. 모델의 구조를 만든다.
3. 데이터로 모델을 학습(FIT)한다.
4. 모델을 이용한다.
Loss(손실)

위 사진의 하늘색 부분은 몇번째 학습인지 알려주는 부분이고, 노란색 부분은 각 학습마다 걸린 시간, 연두색 부분은 각 학습이 끝날 때마다 얼마나 정답에 잘 맞추고 있는지 알려주는 부분이다.
학습이 되면 될수록 정답을 더 정확하게 맞추게 된다. Loss가 0에 가까워질수록 학습이 더 잘된 모델이다.
실습
라이브러리 사용
import tensorflow as tf
import pandas as pd데이터 준비
파일경로 = 'https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/lemonade.csv'
데이터 = pd.read_csv(파일경로)
데이터.head()실행결과
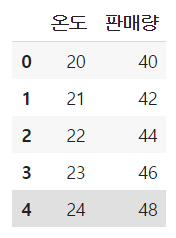
독립변수, 종속변수
독립 = 데이터[['온도']]
종속 = 데이터[['판매량']]
print(독립.shape, 종속.shape)실행결과
(6, 1) (6, 1)
모델 만들기
X = tf.keras.layers.Input(shape=[1])
Y = tf.keras.layers.Dense(1)(X)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')모델 학습하기
model.fit(독립, 종속, epochs=10)실행결과
Epoch 1/10 1/1 [==============================] - 0s 273ms/step - loss: 2067.5740 Epoch 2/10 1/1 [==============================] - 0s 10ms/step - loss: 2060.8035 Epoch 3/10 1/1 [==============================] - 0s 5ms/step - loss: 2055.9023 Epoch 4/10 1/1 [==============================] - 0s 6ms/step - loss: 2051.8054 Epoch 5/10 1/1 [==============================] - 0s 6ms/step - loss: 2048.1726 Epoch 6/10 1/1 [==============================] - 0s 5ms/step - loss: 2044.8477 Epoch 7/10 1/1 [==============================] - 0s 5ms/step - loss: 2041.7422 Epoch 8/10 1/1 [==============================] - 0s 5ms/step - loss: 2038.8022 Epoch 9/10 1/1 [==============================] - 0s 5ms/step - loss: 2035.9907 Epoch 10/10 1/1 [==============================] - 0s 4ms/step - loss: 2033.2821 <tensorflow.python.keras.callbacks.History at 0x7fbbee8b4470>
처음엔 loss값이 굉장히 크게 나온다. 더 정확한 결과를 도출하기 위해 학습횟수를 늘린다. 학습횟수가 많이 늘어나게 되면 실행결과 또한 매우 많이 뜨기 때문에, verbose=0 를 추가하여 실행결과를 띄우지 않도록 한다.
model.fit(독립, 종속, epochs=10000, verbose=0)실행결과
<tensorflow.python.keras.callbacks.History at 0x7fbbed7f2eb8>
실행 후, 실행횟수를 10회로 하여 다시 실행시켜보면,
model.fit(독립, 종속, epochs=10)실행결과
Epoch 1/10 1/1 [==============================] - 0s 3ms/step - loss: 1.6329e-04 Epoch 2/10 1/1 [==============================] - 0s 5ms/step - loss: 1.6319e-04 Epoch 3/10 1/1 [==============================] - 0s 4ms/step - loss: 1.6313e-04 Epoch 4/10 1/1 [==============================] - 0s 4ms/step - loss: 1.6306e-04 Epoch 5/10 1/1 [==============================] - 0s 4ms/step - loss: 1.6297e-04 Epoch 6/10 1/1 [==============================] - 0s 4ms/step - loss: 1.6286e-04 Epoch 7/10 1/1 [==============================] - 0s 4ms/step - loss: 1.6283e-04 Epoch 8/10 1/1 [==============================] - 0s 3ms/step - loss: 1.6280e-04 Epoch 9/10 1/1 [==============================] - 0s 3ms/step - loss: 1.6278e-04 Epoch 10/10 1/1 [==============================] - 0s 3ms/step - loss: 1.6281e-04 <tensorflow.python.keras.callbacks.History at 0x7fbbecf1a0b8>loss값이 0에 가까워진 것을 볼 수 있다.
모델 이용하기
model.predict(독립)실행결과
array([[39.99256 ], [41.990894], [43.98923 ], [45.987564], [47.9859 ], [49.984234]], dtype=float32)
새로운 독립변수를 대입하여 결과 예측해보기
model.predict([15])실행결과
array([[30.000885]], dtype=float32)-> 온도가 15도 일 때, 레몬을 30개 준비하면 된다는 사실을 알 수 있다.

자율주행 개발자가 되고싶은 대학생입니다.