
머신러닝 모델을 만드는 과정

1. 과거의 데이터를 준비한다.
2. 모델의 구조를 만든다.
3. 데이터로 모델을 학습(FIT)한다.
4. 모델을 이용한다.
퍼셉트론
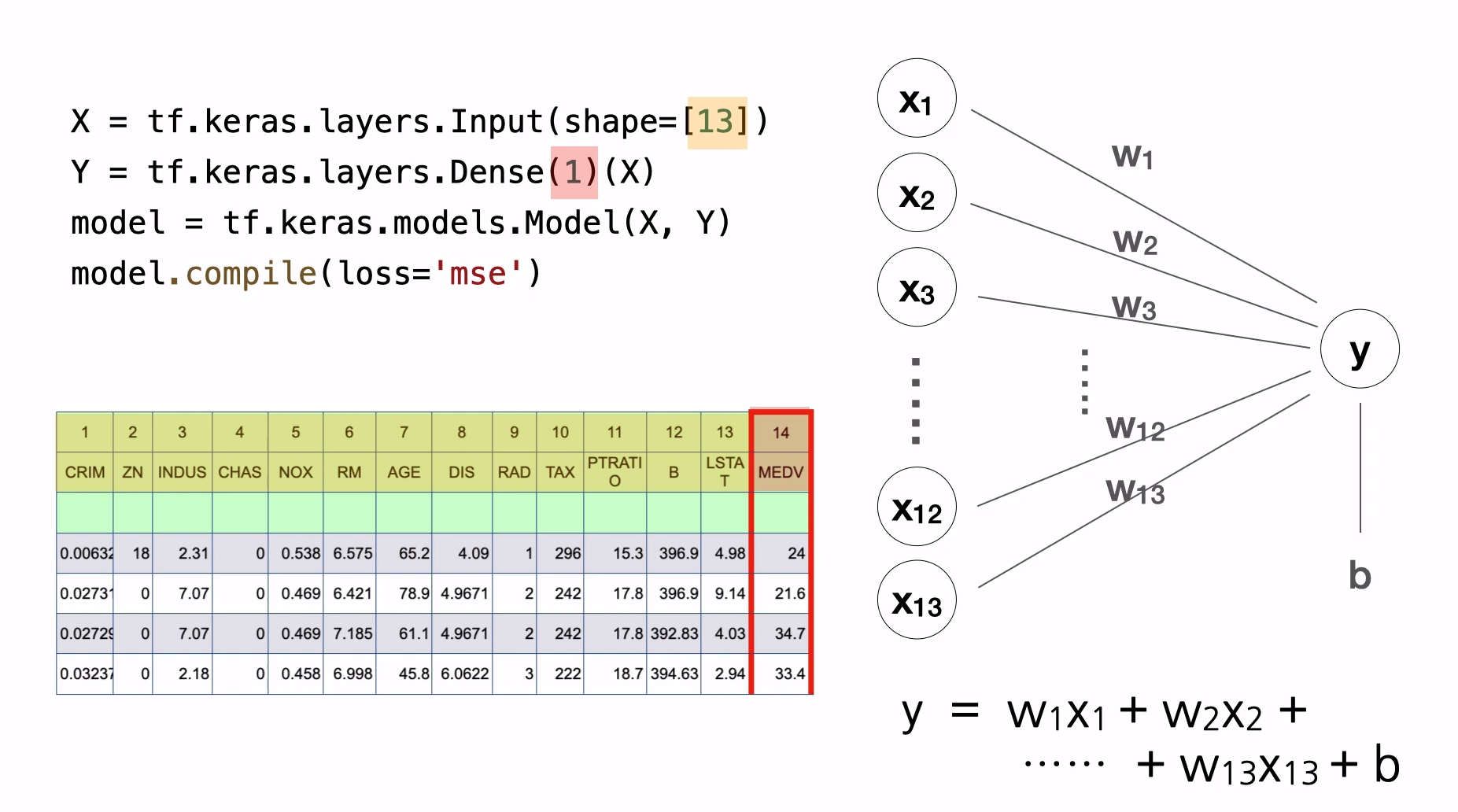
컴퓨터는 학습과정에서 입력되는 데이터를 보고 이 수식의 w들과 b값을 찾는다. 우리가 만든 이 모델은 뉴런 하나로 이루어져 있는데, 뉴런은 실제 두뇌세포의 이름이고, 인공신경망에서 이런 뉴런의 역할을 하는것이 우리가 만든 모형과 수식이다. 그리고 이 모형을 '퍼셉트론'이라고 한다.
그리고 w값은 '가중치'(weight)라고 하고, b는 '편향'(bias)이라고 부른다.
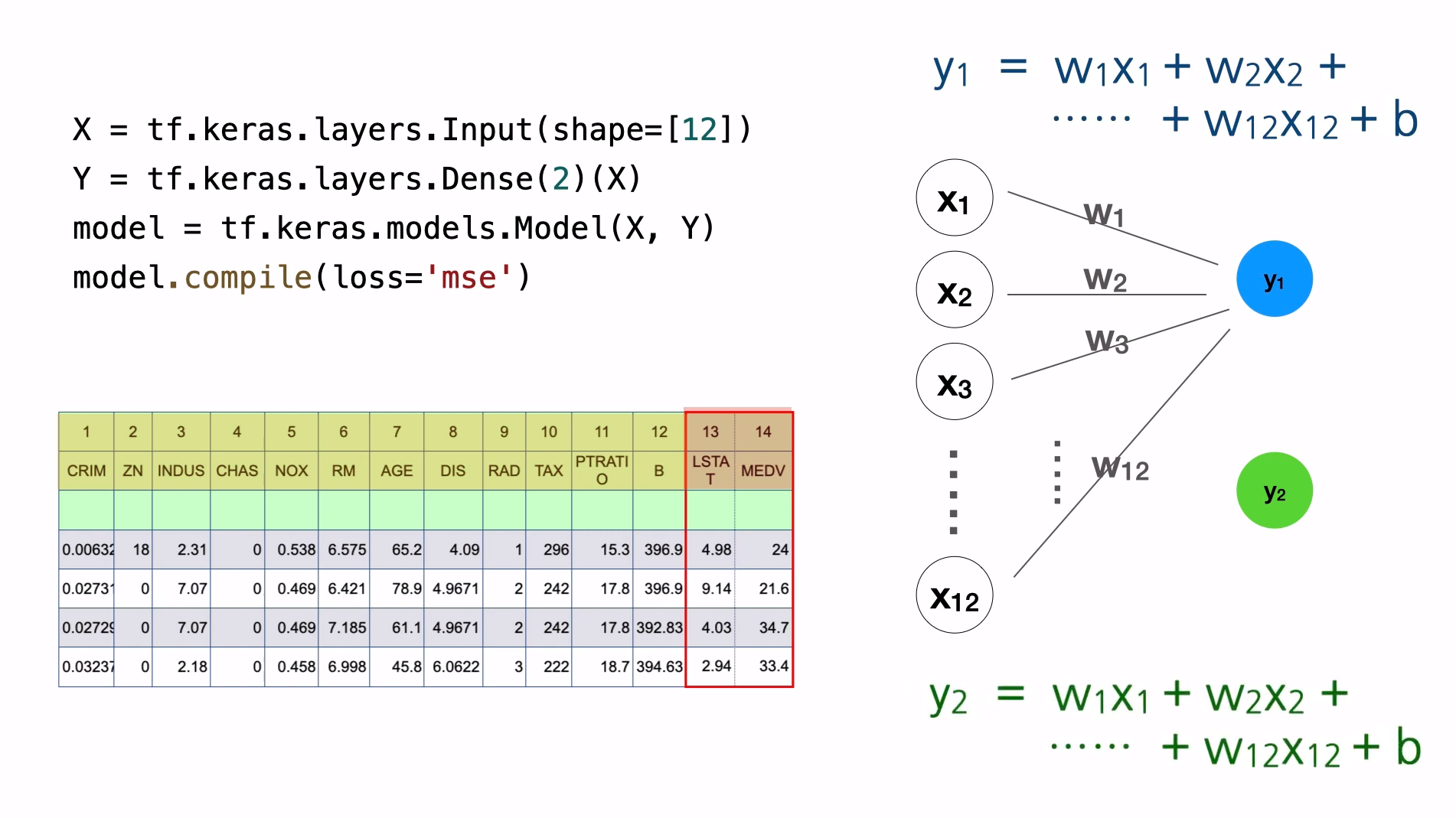
위 모델은 퍼셉트론 두개가 병렬로 연결된 모습이다. 다음과 같이 결과(종속변수)가 두개라면 수식도 두개가 필요하다. 찾아야 하는 가중치의 개수는 첫번째 수식에서 w 12개, b 하나, 두번째 수식에서도 w 12개, b 하나로 총 26개의 가중치가 필요하다.
실습
라이브러리 사용
import tensorflow as tf
import pandas as pd1. 과거의 데이터를 준비한다.
파일경로 = 'https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/boston.csv'
보스턴 = pd.read_csv(파일경로)
print(보스턴.columns)
보스턴.head()실행결과
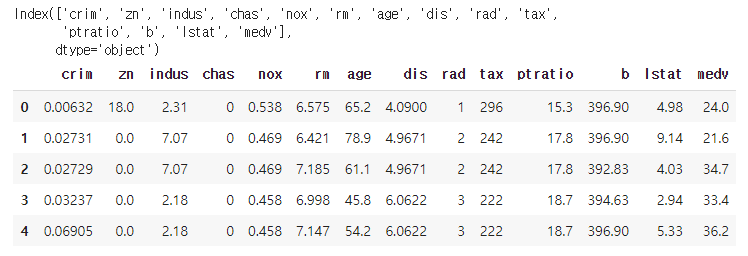
독립변수, 종속변수 분리
독립 = 보스턴[['crim', 'zn', 'indus', 'chas', 'nox', 'rm', 'age', 'dis', 'rad', 'tax',
'ptratio', 'b', 'lstat']]
종속 = 보스턴[['medv']]
print(독립.shape, 종속.shape)실행결과
(506, 13) (506, 1)
2. 모델의 구조를 만든다.
X = tf.keras.layers.Input(shape=[13])
Y = tf.keras.layers.Dense(1)(X)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')3. 데이터로 모델을 학습(FIT)한다.
model.fit(독립, 종속, epochs=1000, verbose=0)
model.fit(독립, 종속, epochs=10)실행결과
Epoch 1/10 16/16 [==============================] - 0s 1ms/step - loss: 26.6930 Epoch 2/10 16/16 [==============================] - 0s 1ms/step - loss: 26.9651 Epoch 3/10 16/16 [==============================] - 0s 1ms/step - loss: 26.9636 Epoch 4/10 16/16 [==============================] - 0s 1ms/step - loss: 26.9042 Epoch 5/10 16/16 [==============================] - 0s 934us/step - loss: 27.0323 Epoch 6/10 16/16 [==============================] - 0s 893us/step - loss: 26.7503 Epoch 7/10 16/16 [==============================] - 0s 884us/step - loss: 26.8491 Epoch 8/10 16/16 [==============================] - 0s 913us/step - loss: 27.0424 Epoch 9/10 16/16 [==============================] - 0s 916us/step - loss: 26.5457 Epoch 10/10 16/16 [==============================] - 0s 958us/step - loss: 27.2101 <tensorflow.python.keras.callbacks.History at 0x7f113dc316d8>학습을 하면 할수록 loss값이 낮아진다. 즉, 정답을 맞출 확률이 높아진다.
4. 모델을 이용한다.
print(model.predict(독립[0:5]))
print(종속[0:5])실행결과
[[28.644255] [24.095812] [29.634169] [29.062792] [28.384825]] medv 0 24.0 1 21.6 2 34.7 3 33.4 4 36.2정답에 꽤 근접한 것을 볼 수 있다.

자율주행 개발자가 되고싶은 대학생입니다.