
기존에는 장난스러운 말투를 썼지만 말투나 글 쓸때 뉘앙스에 많은 시간을 들이는게 비효율적인 것 같아 이제부터 드라이하게 글을 쓰고자 합니다 ㅎㅎ...
Java는 객체지향 프로그래밍 언어로, 메모리 관리를 위해 Garbage Collection(GC)이라는 자동화된 메커니즘을 사용합니다. 이 글에서는 Java의 컴파일 과정부터 시작하여 JVM의 구조, 메모리 관리 방식, 그리고 Garbage Collection의 다양한 알고리즘까지 배우고 공부한 내용을 정리하고자 합니다.
Java 소스 코드 컴파일 과정
Java의 가장 큰 장점 중 하나는 "Write Once, Run Anywhere" 철학입니다. 이를 가능하게 하는 것이 Java의 컴파일 과정과 JVM(Java Virtual Machine)입니다.
저와 같은 자바 개발자가 .java 확장자를 가진 소스 코드 파일을 작성합니다. => 이 소스 코드는 Java 컴파일러(javac)에 의해 바이트코드(.class)로 변환됩니다. => 바이트코드는 기계어가 아닌 중간 코드 형태로, JVM이 이해할 수 있는 형태입니다. => 그리고 JVM이 이 바이트코드를 로드하고 실행하는 과정을 거칩니다.
// HelloWorld.java
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}위 코드를 컴파일하고 실행하는 과정은 다음과 같습니다.
javac HelloWorld.java # HelloWorld.class 생성
java HelloWorld # JVM이 바이트코드를 로드하고 실행핵심: Java 소스 코드는 컴파일되어 JVM이 이해할 수 있는 바이트코드로 변환되고, 이 바이트코드는 어떤 플랫폼에서든 JVM 위에서 실행될 수 있습니다.
JVM의 구조
JVM은 Java 애플리케이션을 실행하기 위한 가상 머신으로, 크게 세 가지 주요 컴포넌트로 구성되어 있습니다.
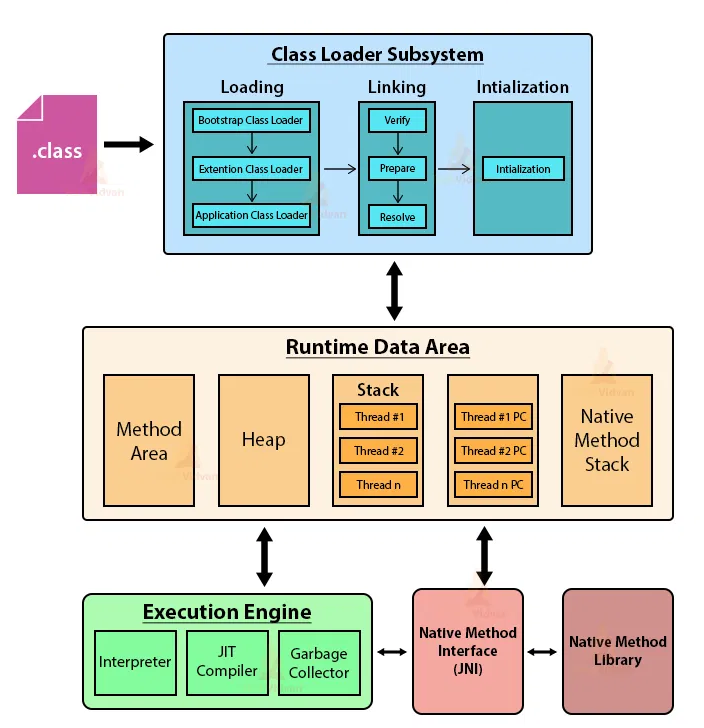
클래스 로더(Class Loader)는 바이트코드를 JVM으로 로드하는 역할을 담당합니다. 클래스 로더는 로딩(Loading), 링킹(Linking), 초기화(Initialization) 단계를 거쳐 클래스를 JVM에 로드하게됩니다.
로딩 단계에서는 클래스 파일을 찾아 메모리에 로드하고, 링킹 단계에서는 클래스 파일의 바이트코드를 검증하며, 초기화 단계에서는 클래스 변수를 초기화하는 역할을 수행하게 됩니다.
실행 엔진(Execution Engine)은 로드된 바이트코드를 기계어로 변환하고 실행하는 역할을 수행합니다. 실행 엔진에는 인터프리터와 JIT 컴파일러가 포함되어 있습니다. 인터프리터는 바이트코드를 한 줄씩 해석하고 실행하는 반면, JIT 컴파일러(Just-In-Time Compiler)는 자주 실행되는 코드(핫스팟)를 탐지하여 네이티브 코드로 컴파일합니다.
네이티브 코드는 특정 컴퓨터 하드웨어(CPU)가 직접 실행할 수 있는 기계어 명령어를 의미합니다.
Java의 바이트코드가 플랫폼 독립적인 중간 코드인 반면, 네이티브 코드는 특정 운영체제와 하드웨어 아키텍처(x86, ARM 등)에 맞게 최적화된 코드입니다.
그럼 여기서 왜 네이티브 코드로 핫스팟을 탐지하는 것이 일반 인터프린팅보다 빠른지 궁금하실 수 있습니다. 이유는 JIT 컴파일러가 바이트코드를 네이티브 코드로 변환하면 JVM의 인터프리터 과정을 거치지 않고 CPU에서 직접 실행되므로 실행 속도가 크게 향상됩니다.
런타임 데이터 영역(Runtime Data Area)은 JVM이 프로그램을 실행하기 위해 OS로부터 할당받은 메모리 영역입니다. 조금 뒤에 정리할 Garbage Collection 알고리즘이 수행되는 장소이기도 합니다.
이 영역은 다시 여러 하위 영역으로 나뉘며, 다음 섹션에서 자세히 알아보겠습니다.
JIT 컴파일러의 역할
JIT 컴파일러는 JVM 성능의 핵심 요소로, 자주 실행되는 코드를 감지하고 최적화합니다.
JIT 컴파일러는 인터프리터가 바이트코드를 실행하면서 핫스팟(Hot Spot)이라 불리는 자주 실행되는 코드를 모니터링합니다. 언뜻 들으면 Garbage Collection의 Old generation이 떠오르기도 합니다.
특정 메소드가 임계값 이상 호출되면 JIT 컴파일러가 해당 메소드를 네이티브 코드로 컴파일합니다. 컴파일된 네이티브 코드는 다음 호출 시 재사용되어 성능이 향상됩니다.
중요: JIT 컴파일러 덕분에 Java 애플리케이션은 초기에는 느리게 시작할 수 있지만, 실행 시간이 길어질수록 성능이 최적화됩니다.
JVM 메모리 구조 (Runtime Data Area)
JVM 메모리는 크게 Heap 영역과 Non-Heap 영역으로 나눌 수 있습니다. 이 구조를 이해하는 것은 효율적인 Java 프로그래밍과 메모리 최적화에 필수적이며 면접 단골 질문이기도 합니다.
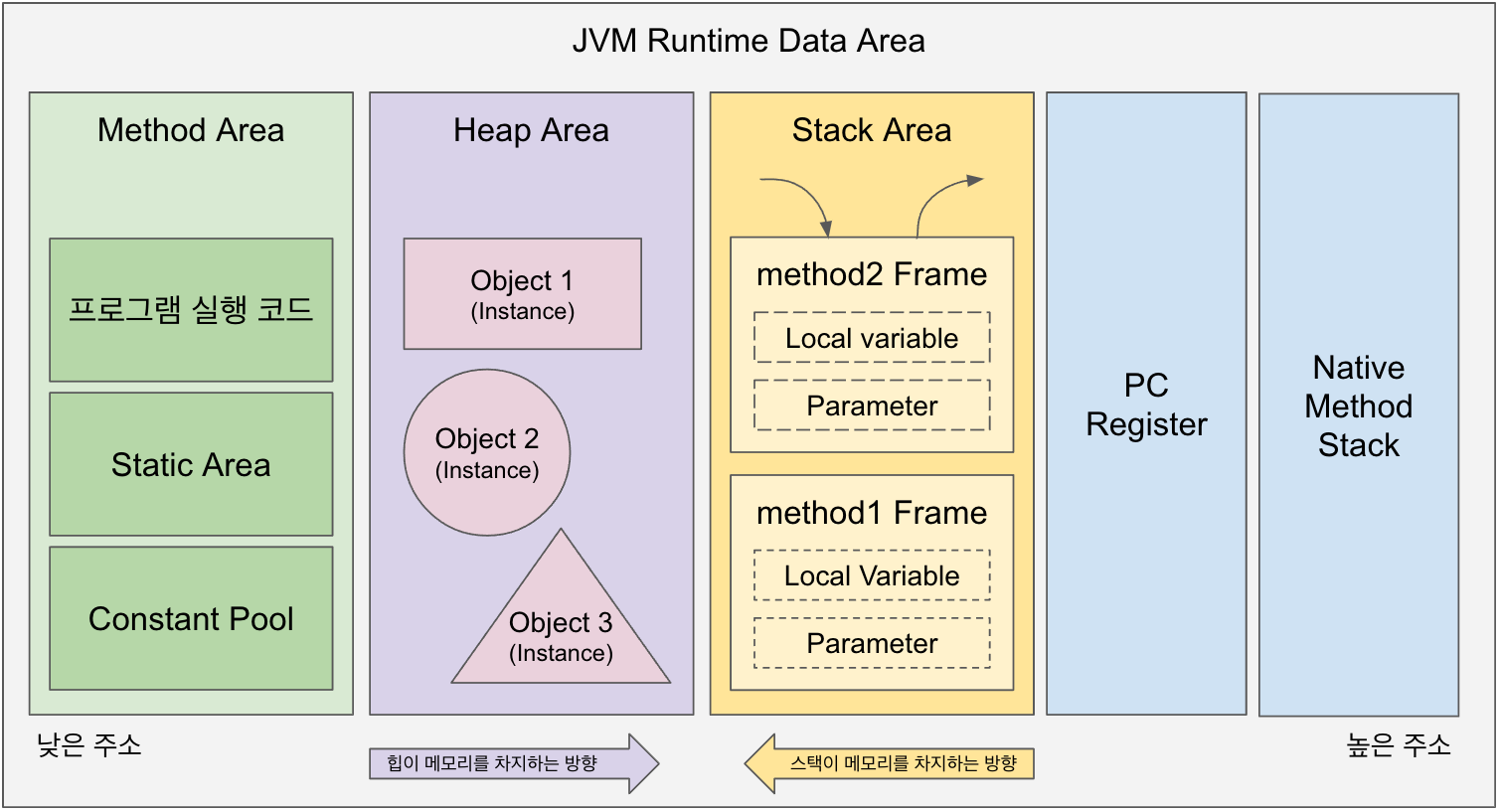
Heap 영역
Heap은 모든 객체 인스턴스와 배열이 할당되는 영역입니다. 이 영역은 JVM 메모리 중에서 가장 큰 영역을 차지하며, 애플리케이션에서 사용하는 대부분의 데이터가 저장됩니다. Heap은 아래 두 세대(Generation)별로 구분되어 관리됩니다.
Young Generation(신생 영역)은 새로 생성된 객체가 처음 할당되는 영역입니다. 이 영역은 다시 Eden 영역과 두 개의 Survivor Space(S0, S1)로 구성됩니다.
Java 애플리케이션에서 생성되는 모든 새로운 객체는 처음에 Eden 영역에 할당됩니다. Eden 영역이 가득 차면 메모리 정리 작업이 수행되는데, 이때 아직 참조되고 있는(살아있는) 객체들은 두 Survivor Space 중 하나로 이동합니다.
Survivor Space는 두 영역(S0, S1)이 번갈아가며 사용됩니다. 한 Survivor 영역에서 살아남은 객체들은 다음 메모리 정리 작업 때 다른 Survivor 영역으로 이동합니다. 이 과정에서 여러 번 살아남은 객체들은 특정 기준을 충족하면 Old Generation으로 이동 즉 승격(Promotion)하게 되는 구조가 특징입니다.
Old Generation(구 영역)은 Young Generation에서 오랫동안 살아남은 객체들이 저장되는 영역입니다. 이 영역은 Young Generation보다 크기가 크며, 메모리 정리 작업의 빈도가 적습니다.
// 새로운 객체 생성 - Eden 영역에 할당됨
Person person = new Person("Kim", 30);Old Generation(구 영역)은 Young Generation에서 오랫동안 살아남은 객체들이 이동하는 영역입니다. Young Generation보다 크기가 크며, GC 빈도가 적고, 더 많은 시간이 소요되는 GC 알고리즘을 사용합니다. 여기서 GC 알고리즘은 뒤에서 더 자세히 배워보겠습니다.
Non-Heap 영역
Method Area(메소드 영역)는 클래스 구조, 메소드 데이터, 필드 데이터, 메소드와 생성자 코드 등이 저장되는 영역입니다. Java 8 이전에는 PermGen 영역으로 불렸으며, Java 8 이후에는 Metaspace 영역(OS의 네이티브 메모리 사용)으로 대체되었습니다.
// 클래스 정보, 정적 변수 등이 Method Area에 저장됨
public class Example {
static int counter = 0; // 메소드 영역에 저장
static final String CONSTANT = "Hello"; // 메소드 영역에 저장
}Stack은 각 스레드마다 독립적으로 생성되는 영역입니다. 메소드가 호출될 때마다 프레임(Frame)이 생성되어 해당 메소드의 지역 변수, 매개변수, 반환 값 등이 저장됩니다. 메소드 호출이 완료되면 해당 프레임은 제거됩니다.
public void calculate() {
int x = 10; // 스택에 저장
int y = 20; // 스택에 저장
Person p = new Person("Lee", 25); // 참조는 스택에, 객체는 힙에 저장
}위 예시에서 가장 중요한 점은 "Person" 객체는 Heap 메모리에서 관리되게 되지만 그 객체를 참조하는 변수 ("p")는 지역 변수이기 때문에 stack에서 관리된다는 것입니다.
PC Register는 각 스레드마다 생성되며, 현재 실행 중인 JVM 명령어의 주소를 저장합니다.
Native Method Stack은 네이티브 메소드 정보가 저장되는 영역으로, C/C++ 등으로 작성된 코드를 위한 스택입니다.
핵심 요약: JVM 메모리는 객체가 저장되는 Heap 영역과 메소드, 스택 등이 저장되는 Non-Heap 영역으로 구분됩니다. Garbage Collection은 주로 Heap 영역을 대상으로 수행되며, 특히 Young Generation에서 더 자주 발생합니다.
Garbage Collection의 기본 원리
Garbage Collection(GC)는 자바의 메모리를 자동으로 관리해주기 위해 JVM의 실행엔진(Execution Engine)에 위치한 소프트웨어입니다.
여기서 중요한 점은 GC가 메모리를 관리하기 위해 CPU 자원을 사용하므로, GC가 수행될 때는 메모리에서 참조되지 않는 객체를 안전하게 식별하고 제거하기 위해 모든 애플리케이션 스레드의 실행을 일시 중지하는 일시적인 정지(stop-the-world)가 발생합니다.
하지만 모든 스레드를 중단 시킨 다는 리스크도 존재하기 때문에 애플리케이션의 응답성과 처리량에 직접적인 영향을 미칩니다. 특히 웹 서버, 금융 거래 시스템, 게임 서버와 같은 실시간 응답이 중요한 시스템에서는 GC로 인한 긴 일시 중지가 때로는 서비스 불능 상태를 초래할 수 있습니다.
그렇다면 Garbage를 정확히 뭘 의미하는가.
Garbage란 더 이상 애플리케이션에서 참조되지 않는 객체를 의미합니다. Java에서는 개발자가 명시적으로 메모리를 해제하지 않고, 위에서 얘기한 GC가 이러한 가비지 객체를 자동으로 감지하고 제거합니다.
Person person = new Person("Park", 40); // 객체 생성
person = null; // 참조 제거 - 이제 이 객체는 가비지가 됨
// 또는
{
Person tempPerson = new Person("Choi", 35); // 블록 내에서 객체 생성
} // 블록을 벗어나면 tempPerson의 참조가 사라지고 객체는 가비지가 됨약한 세대 가설(weak generational hypothesis)
GC는 weak generational hypothesis라는 두 가지 가정을 기반으로 설계되었습니다. 첫째, 대부분의 객체는 생성 직후 빠르게 가비지가 된다는 것입니다. 둘째, 오래된 객체에서 젊은 객체로의 참조는 상대적으로 적다는 것입니다. 이 가정을 바탕으로 JVM은 메모리를 세대(Generation)로 나누고, 각 세대별로 다른 GC 알고리즘을 적용합니다.
Stop-the-World
위에서 잠깐 언급했는데 GC 작업이 수행될 때 JVM은 애플리케이션 실행을 일시적으로 멈추는데, 이를 Stop-the-World(STW) 이벤트라고 합니다.
Stop-the-World 동안 GC 관련 스레드를 제외한 모든 스레드의 작업이 중단되며, 이는 애플리케이션의 응답성에 영향을 줄 수 있습니다.
STW 시간은 GC 알고리즘, 힙 크기, 객체 수 등 여러 요소에 따라 달라집니다.
Throughput과 Latency 트레이드오프
GC 성능은 주로 두 가지 측면에서 평가됩니다.
-
Throughput(처리량)은 애플리케이션이 GC가 아닌 실제 작업에 사용하는 시간의 비율을 의미합니다.
-
Latency(지연 시간)은 GC로 인한 애플리케이션 중단 시간을 의미합니다.
이 두 요소는 일반적으로 트레이드오프 관계에 있습니다. 높은 처리량을 우선시하면 지연 시간이 증가할 수 있고, 짧은 지연 시간을 우선시하면 처리량이 감소할 수 있습니다.
중요 포인트: 애플리케이션의 특성에 따라 적절한 GC 알고리즘과 설정을 선택해야 합니다. 실시간 처리가 중요한 시스템은 낮은 지연 시간을, 배치 작업은 높은 처리량을 우선시할 수 있습니다.
예를 들어 Spring 프로젝트를 진행할 때 보통 진행하는 웹 애플리케이션이나 REST API 서버에서는 응답 시간이 중요하므로 G1 GC나 ZGC와 같은 낮은 지연 시간을 제공하는 GC를 선택하고 설정할 수 있습니다.
java -XX:+UseG1GC -XX:MaxGCPauseMillis=50 -Xms2g -Xmx2g -jar my-web-app.jarSpring Batch를 사용한 대용량 데이터 처리나 야간 일괄 처리 작업과 같은 배치 애플리케이션에서는 처리량이 중요하므로 Parallel GC를 선택하고 다음과 같이 설정하는 것이 유리할 때도 있습니다.
java -XX:+UseParallelGC -XX:ParallelGCThreads=8 -Xms4g -Xmx4g -jar my-batch-app.jar
정리하면 stop-the-world가 짧으면 GC 스레드가 차지하는 메모리가 커져 어플리케이션의 처리율이 좋지 않아지고, stop-the-world가 길면 GC 스레드가 차지하는 메모리가 작아서 어플리케이션의 처리율이 좋아지는 것입니다
처리율을 증가시키기 위해서 Heap(대부분 Young) 영역의 크기를 키우면, 스캔하고 관리해야하는 메모리의 크기가 커져 GC 작업 시간(stop-the-world)이 증가하게 됩니다. 반대로 stop-the-world를 최소화시키면, 짧은 GC가 자주 발생하게 되며 처리율이 떨어지게 됩니다.
여기서, 처리율은 Garbage Collection에 소요되지 않은 총 시간의 백분율입니다.
공식 문서: "Throughput is the percentage of total time not spent in garbage collection considered over long periods of time"
5. Garbage Collection 알고리즘
효율적인 메모리 관리를 위해 다양한 GC 알고리즘이 개발되었습니다. 각 알고리즘은 고유한 장단점을 가지고 있습니다.
Mark-Sweep-Compact
가장 기본적인 GC 알고리즘으로, 세 단계로 진행됩니다. Mark 단계에서는 GC 루트(Root)에서 시작하여 도달 가능한 모든 객체를 표시합니다. Sweep 단계에서는 표시되지 않은 객체(가비지)를 제거합니다. 마지막으로 Compact 단계에서는 남은 객체들을 힙의 시작 부분으로 모아 메모리 단편화를 방지합니다.
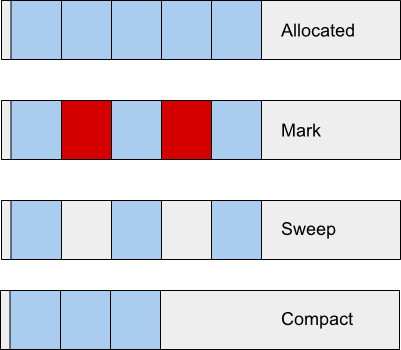
이 알고리즘의 단점은 전체 프로세스 동안 애플리케이션이 중지된다는 점입니다.
Copying Collection
이 알고리즘은 힙을 두 영역으로 나누고, 살아있는 객체를 다른 영역으로 복사합니다. 메모리를 동일한 크기의 두 영역(From, To)으로 나누며, 객체는 From 영역에만 할당됩니다. GC 발생 시 From 영역에서 살아있는 객체를 To 영역으로 복사하고, From 영역을 비웁니다. 그런 다음 From과 To 영역의 역할을 교체합니다. 이 방식은 Young Generation의 Survivor 영역에서 주로 사용됩니다.
Generational Collection
앞서 설명한 weak generational hypothesis를 기반으로 하는 알고리즘입니다. 메모리를 Young Generation과 Old Generation으로 나누고, Young Generation에서는 자주, 빠르게 GC를 수행하는 Minor GC를, Old Generation에서는 덜 자주, 더 철저하게 GC를 수행하는 Major GC를 실행합니다.
Incremental Collection
전체 힙을 한 번에 처리하지 않고, 작은 부분으로 나누어 점진적으로 GC를 수행합니다. 이를 통해 긴 STW 시간을 여러 개의 짧은 STW로 분산시켜 애플리케이션의 응답성을 향상시킵니다.
6. Java의 다양한 GC 종류
Java는 다양한 워크로드와 환경에 맞게 여러 GC 구현체를 제공합니다.
Serial GC
가장 단순한 GC 구현체로, 싱글 스레드로 동작합니다. 작은 힙과 단일 CPU 환경에 적합하며, -XX:+UseSerialGC 옵션으로 활성화할 수 있습니다.
java -XX:+UseSerialGC MyApplicationParallel GC
다중 스레드를 사용하여 GC를 수행하는 방식으로, 높은 처리량(Throughput)이 목표입니다. Java 8의 기본 GC이며, -XX:+UseParallelGC 옵션으로 활성화할 수 있습니다.
java -XX:+UseParallelGC -XX:ParallelGCThreads=4 MyApplicationCMS(Concurrent Mark Sweep) GC
애플리케이션 스레드와 동시에 작동하여 STW 시간을 최소화하는 방식입니다. 응답 시간이 중요한 애플리케이션에 적합하지만, Java 9에서 deprecated되었고 Java 14에서는 완전히 제거되었습니다. -XX:+UseConcMarkSweepGC 옵션으로 활성화할 수 있습니다.
java -XX:+UseConcMarkSweepGC MyApplication참고: CMS GC는 압축(Compaction) 단계가 없어 메모리 단편화 문제가 발생할 수 있습니다.
G1(Garbage-First) GC
Java 9부터 기본 GC로 채택되었으며, 대용량 힙(4GB 이상)에 최적화 되어있는 특징이 있습니다. 힙을 균등한 크기의 영역(Region)으로 나누어 관리하고, 예측 가능한 일시 중지 시간을 제공합니다. -XX:+UseG1GC 옵션으로 활성화할 수 있습니다.
java -XX:+UseG1GC -XX:MaxGCPauseMillis=200 MyApplicationZ GC
Java 11에서 실험적 기능으로 도입되어 Java 15에서 프로덕션 준비 상태로 업그레이드되었습니다. 테라바이트 규모의 힙 처리에 최적화되었으며, 10ms 이하의 최대 일시 중지 시간을 목표로 합니다. 동시(Concurrent) 작업에 중점을 두며, -XX:+UseZGC 옵션으로 활성화할 수 있습니다.
java -XX:+UseZGC MyApplicationShenandoah GC
Red Hat이 개발한 저지연 GC로, Java 12에서 실험적 기능으로 도입되어 Java 15에서 프로덕션 준비 상태로 업그레이드되었습니다. 동시 압축 기능을 제공하며, -XX:+UseShenandoahGC 옵션으로 활성화할 수 있습니다.
java -XX:+UseShenandoahGC MyApplicationJDK 버전별 기본 GC: Java 8: Parallel GC, Java 9+: G1 GC
7. G1 GC 심층 분석
사실 위에서 다룬 여러개의 GC중 현재 가장 대중적으로 사용되는 것은 G1(Garbage-First) GC라고 생각합니다. Java 9부터 기본 GC로 채택되었으며, 대용량 메모리 환경에서 예측 가능한 일시 중지 시간을 제공하는 것이 우리가 개발하는 어플리케이션에 큰 이점을 가져다 줍니다.
G1 GC 개념과 설계 목표
G1 GC의 주요 설계 목표는 예측 가능한 일시 중지 시간, 높은 처리량 유지, 그리고 힙 조각화 방지입니다. 사용자가 지정한 일시 중지 시간 목표(예: -XX:MaxGCPauseMillis=200)를 달성하기 위해 노력하며, 일시 중지 시간을 줄이면서도 좋은 처리량을 제공합니다. 또한 압축을 효과적으로 수행하여 메모리 단편화를 최소화합니다.
Region 기반 메모리 구조
G1 GC의 가장 큰 특징은 힙을 고정 크기의 Region으로 나누는 것입니다.
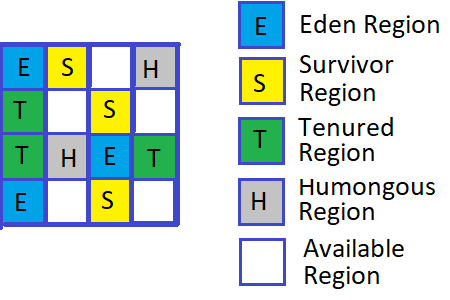
각 Region은 일반적으로 1MB~32MB 크기이며, 동적으로 역할이 바뀔 수 있습니다. Eden Region은 새 객체가 할당되는 영역이고, Survivor Region은 Minor GC에서 살아남은 객체가 이동하는 영역입니다. Old Region은 오래된 객체들이 저장되며, Humongous Region은 Region 크기의 50% 이상을 차지하는 큰 객체가 저장되는 영역입니다.
// 일반 객체 - Eden Region에 할당
Person person = new Person("Kim", 30);
// 큰 객체 - Humongous Region에 할당
byte[] largeArray = new byte[20 * 1024 * 1024];Garbage Collection Cycle
G1 GC는 Young-only Phase와 Space Reclamation Phase라는 두 가지 주요 단계로 작동합니다.
Young-only Phase에서는 Minor GC(Young GC)가 발생합니다. Eden Region의 살아있는 객체를 Survivor Region으로 이동시키고, Survivor Region의 살아있는 객체를 다른 Survivor Region으로 이동시킵니다. 충분히 오래된 객체는 Old Region으로 승격(Promotion)되며, 비워진 Region은 재사용을 위해 반환됩니다.
Space Reclamation Phase는 Old Generation이 특정 임계값인 IHOP(Initiating Heap Occupancy Percent)에 도달하면 시작됩니다. 이 단계는 Initial Mark, Concurrent Marking, Remark, Cleanup, Mixed Collection의 단계로 구성됩니다. Initial Mark 단계에서는 Old Region의 참조를 표시하고, Concurrent Marking 단계에서는 애플리케이션 실행과 동시에 살아있는 객체를 추적합니다. Remark 단계에서는 최종 참조를 확인하고, Cleanup 단계에서는 가비지로만 구성된 Region을 정리합니다. 마지막으로 Mixed Collection 단계에서는 가비지가 많은 Old Region과 Young Region을 함께 수집합니다.
SATB(Snapshot-At-The-Beginning)
G1 GC는 SATB라는 동시 마킹 알고리즘을 사용합니다. 이 알고리즘은 마킹 시작 시점의 객체 그래프 스냅샷을 유지하여 일관성을 보장합니다.
IHOP(Initiating Heap Occupancy Percent)
G1 GC는 IHOP라는 임계값을 사용하여 동시 마킹 단계를 시작하는 시점을 결정합니다. 기본값은 힙의 45%이며, Adaptive IHOP 기능을 통해 JVM이 GC 통계를 기반으로 자동 조정할 수 있습니다. -XX:InitiatingHeapOccupancyPercent=<N> 옵션으로 설정할 수 있습니다.
java -XX:+UseG1GC -XX:InitiatingHeapOccupancyPercent=35 MyApplicationMixed GC vs Full GC
G1 GC에서는 Mixed GC와 Full GC라는 두 가지 GC 유형이 있습니다. Mixed GC는 일부 Old Region과 Young Region을 함께 수집하는 방식이고, Full GC는 전체 힙을 대상으로 하는 STW 컬렉션입니다. Full GC는 구현 성능이 좋지 않아 최소화하는 것이 좋습니다.
핵심: G1 GC는 일반적으로 Full GC를 피하고 Mixed GC를 통해 점진적으로 Old Generation을 정리합니다. Full GC가 자주 발생한다면 힙 크기 조정이 필요할 수 있습니다.
8. G1 GC의 적합한 사용 시나리오
G1 GC는 모든 상황에 최적인 것은 아니며, 다음과 같은 특정 시나리오에서 더 효과적으로 동작합니다.
대용량 힙 메모리 환경
G1 GC는 4GB 이상의 힙 메모리와 많은 프로세서 코어가 있는 환경에서 좋은 성능을 발휘합니다.
# 대용량 힙 설정 예시
java -XX:+UseG1GC -Xms6g -Xmx6g MyApplication일관된 응답 시간을 요구하는 애플리케이션
지연 시간에 민감한 애플리케이션(웹 서버, 금융 거래 시스템 등)과 예측 가능한 일시 중지 시간이 중요한 경우에 적합합니다.
# 최대 일시 중지 시간을 100ms로 설정
java -XX:+UseG1GC -XX:MaxGCPauseMillis=100 MyApplication기존 GC와 비교했을 때의 장단점
G1 GC의 장점으로는 예측 가능한 일시 중지 시간, 힙 단편화 최소화, 대용량 힙에서 효율적인 작동, 그리고 GC 부하의 점진적 분산 등이 있습니다. 반면 단점으로는 CPU 및 메모리 오버헤드 증가, 작은 힙에서는 성능 이점이 적음, 그리고 복잡한 내부 메커니즘으로 인한 튜닝 어려움 등이 있습니다.
CMS와 비교했을 때, G1은 압축 기능을 제공하여 메모리 단편화 문제를 해결합니다.
Parallel GC와 비교했을 때, G1은 처리량이 약간 낮을 수 있지만 더 짧고 예측 가능한 일시 중지 시간을 제공합니다.
선택 기준: 고성능 시스템이 필요하고 예측 가능한 응답 시간이 중요하다면 G1 GC가 좋은 선택입니다. 단순한 배치 작업이나 작은 힙을 사용하는 경우 Parallel GC가 더 효율적일 수 있습니다.
9. GC 모니터링과 튜닝 팁
효율적인 Java 애플리케이션 운영을 위해 GC 모니터링과 튜닝은 필수적입니다.
주요 GC 파라미터 설정
일반적인 GC 파라미터로는 힙 크기 설정(-Xms<size>, -Xmx<size>)과 GC 로깅 설정(-Xlog:gc*=info:file=gc.log:time,uptime,level,tags)이 있습니다. G1 GC 특화 파라미터로는 G1 GC 활성화(-XX:+UseG1GC), 목표 일시 중지 시간 설정(-XX:MaxGCPauseMillis=200), Region 크기 설정(-XX:G1HeapRegionSize=<1-32>M), 그리고 IHOP 설정(-XX:InitiatingHeapOccupancyPercent=45) 등이 있습니다.
GC 로그 분석 방법
GC 로그는 메모리 사용 패턴과 성능 문제를 이해하는 데 중요한 정보를 제공합니다. Java 9 이상에서는 다음과 같은 형태로 GC 로그가 출력됩니다.
[0.051s][info][gc] Using G1
[2.245s][info][gc] GC(0) Pause Young (Normal) (G1 Evacuation Pause) 24M->3M(256M) 6.919ms
[3.785s][info][gc] GC(1) Pause Young (Normal) (G1 Evacuation Pause) 27M->5M(256M) 8.171msGC 로그 분석을 위한 도구로는 GCViewer, GCeasy, VisualVM, JConsole 등이 있습니다.
성능 튜닝 전략
적절한 힙 크기 설정은 GC 성능에 큰 영향을 미칩니다. 동일한 초기 및 최대 힙 크기 설정으로 불필요한 재조정을 방지할 수 있습니다.
# 동일한 초기 및 최대 힙 크기 설정
java -Xms4g -Xmx4g MyApplication애플리케이션 특성에 맞는 GC 선택도 중요합니다. 처리량이 중요하다면 Parallel GC를, 지연 시간이 중요하다면 G1 GC, ZGC, Shenandoah GC를 선택하는 것이 좋습니다.
Old Generation으로의 객체 승격을 최소화하는 것도 좋은 전략입니다. 예를 들어, 캐시 크기를 제한하여 너무 많은 객체가 Old Generation으로 승격되는 것을 방지할 수 있습니다.
// 캐시 크기 제한
cache.setMaxSize(10000);불필요한 객체 생성을 줄이는 것도 중요합니다. 예를 들어, 문자열 연결 작업에는 String 연산자(+) 대신 StringBuilder를 사용하는 것이 좋습니다.
// 대량의 임시 객체 생성 방지
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 1000; i++) {
sb.append(i); // String + String 대신 StringBuilder 사용
}
String result = sb.toString();G1 GC 튜닝을 위한 예시 설정은 다음과 같습니다.
java -XX:+UseG1GC \
-Xms4g -Xmx4g \
-XX:MaxGCPauseMillis=100 \
-XX:+ParallelRefProcEnabled \
-XX:G1HeapWastePercent=5 \
-XX:G1MixedGCCountTarget=8 \
MyApplication핵심 원칙: GC 튜닝은 항상 측정(Measure), 분석(Analyze), 조정(Tune), 검증(Verify)의 반복적인 과정을 통해 수행해야 합니다.
마무리
Java의 메모리 관리와 Garbage Collection에 대해 공부하면서 정리한 내용을 장황하게 끄적여 봤습니다... 처음에는 단순히 '사용하지 않는 객체를 제거하는 기능'정도로만 알고 있었지만, 깊이 공부할수록 JVM의 구조부터 다양한 GC 알고리즘까지 정말 방대한 내용임에 놀라고 공부하는데 놀라고...
특히 실무에서 애플리케이션의 성능 이슈가 발생했을 때 GC 로그를 분석하고 적절한 튜닝을 할 수 있는 능력은 자바 개발자로서 큰 경쟁력이 된다고 생각합니다. 이번 정리를 통해 기본 개념을 다지고, 앞으로 실제 프로젝트에 적용하면서 더 깊이 있는 이해와 경험을 쌓아가야겠다는 생각이 드네요 ㅎㅎ
아직 배울 것이 많지만, 이렇게 정리하는 과정이 제 자신의 성장에 도움이 되었고, 이 글이 조금이나마 도움이 되었으면 좋겠습니다. 다음에는 직접 GC 튜닝을 해보고 그 경험도 시간이 허락한다면 적어봐야 겠습니다. 그럼 다시 공부하러!!
참고 자료
- Understanding Java Garbage Collection - Oracle
- Java Platform, Standard Edition HotSpot Virtual Machine Garbage Collection Tuning Guide
- G1 GC에 대해 - 땡글이
- Java Garbage Collection - NAVER D2
- 가비지 컬렉션 동작 원리 & GC 종류 총정리 - 인파
- Java 메모리 관리 - 가비지 컬렉션 - yaboong
- JVM Memory Structure: https://www.devkuma.com/docs/java/jvm/java_jvm_runtime_data_area.png
- JVM Architecture: https://miro.medium.com/v2/resize:fit:1400/1*H1Kp4y5nfIK5wQ9r_DYtbA.png
- G1 GC Regions: https://www.perfmatrix.com/wp-content/uploads/2019/11/GC-G1-Type.png
- Mark-Sweep-Compact: https://velog.velcdn.com/images%2Ftkadks123%2Fpost%2Fd60f4c41-860f-4dce-9457-a72e5af4209f%2Fmsc.png
- Garbage Collection 과정: https://blog.kakaocdn.net/dn/btcGIh/btqu2IC8DKn/5JMU0KKnKNlTivRedAKYlk/img.png

안녕하세요 글 너무 잘 읽었습니다! 한 가지 궁금하게 있는데 혹시 어떤 상황에서 ZGC보다 Shenandoah ,GC를 선택하면 좋은지 알 수 있을까요?