Ran_Chat 프로젝트 성능 최적화
1. 회원 참여 채팅방 리스트 조회 API
- 회원이 참여하고 있는 채팅방 목록을 조회하는 API (정렬 포함)
1. 쿼리튜닝 진행
기존쿼리
/* com.rand.chat.mapper.ChatRoomMapper.selectChatRoomList 회원이 참여하고있는 채팅방 리스트 (채팅방은 수만개 되지않으니 별도의 성능개선 페이징은 필요없어보임 )*/
WITH LatestMessage AS (
SELECT chat_room_id,
MAX(msg_cr_date_ms) AS latest_msg_date_ms
FROM CHAT_MESSAGE
GROUP BY chat_room_id
),
UnreadCount AS (
SELECT chat_room_id,
COUNT(*) AS unread_count
FROM CHAT_MESSAGE
WHERE usr_id != #{usrId} AND is_read = 0
GROUP BY chat_room_id
),
OpsInfo AS (
SELECT SUB_CRM.chat_room_id,
MEM.profile_img,
MEM.nick_name
FROM CHAT_ROOM_MEMBERS SUB_CRM
INNER JOIN MEMBERS MEM
ON SUB_CRM.usr_id = MEM.usr_id
WHERE SUB_CRM.usr_id != #{usrId}
)
SELECT CR.chat_room_id
, OPS_INFO.profile_img AS opsProfileImg
, OPS_INFO.nick_name AS opsNickName
, CM.message AS curMsg
, CM.msg_cr_date AS curMSgCrDate
, CM.chat_type AS curChatType
, COALESCE(UC.unread_count, 0) AS unread_count
, CR.room_state
, CASE
WHEN OPS_INFO.nick_name IS NULL AND CR.room_state = 'ACTIVE' THEN 1
ELSE 0
END AS abNormalFlag
FROM CHAT_ROOM CR
INNER JOIN CHAT_ROOM_MEMBERS CRM
ON CR.chat_room_id = CRM.chat_room_id
AND CRM.usr_id = #{usrId}
LEFT JOIN LatestMessage LM
ON CR.chat_room_id = LM.chat_room_id
LEFT JOIN CHAT_MESSAGE CM
ON CR.chat_room_id = CM.chat_room_id
AND CM.msg_cr_date_ms = LM.latest_msg_date_ms
LEFT JOIN OpsInfo OPS_INFO
ON CR.chat_room_id = OPS_INFO.chat_room_id
LEFT JOIN UnreadCount UC
ON CR.chat_room_id = UC.chat_room_id
ORDER BY
CASE
WHEN CM.message IS NULL THEN 0 /* 새로 생성된 채팅방 이거나 상대방이 탈퇴한 채팅방은 상위에 표시 */
ELSE 1
END ASC,
CASE
WHEN CM.message IS NULL THEN CR.room_cr_date
ELSE CM.msg_cr_date_ms
END DESC /* 최근 메시지가 있는 경우 최신 순서로 정렬 */
쿼리 실행계획분석
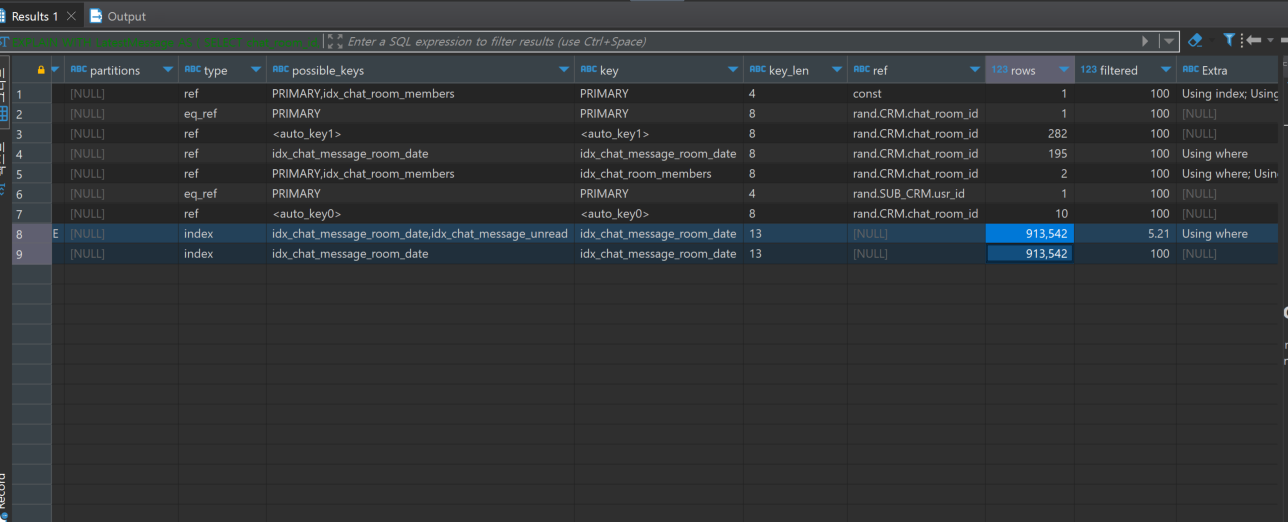
튜닝 포인트
WITH LatestMessage AS (
SELECT chat_room_id,
MAX(msg_cr_date_ms) AS latest_msg_date_ms
FROM CHAT_MESSAGE
GROUP BY chat_room_id
),
UnreadCount AS (
SELECT chat_room_id,
COUNT(*) AS unread_count
FROM CHAT_MESSAGE
WHERE usr_id != #{usrId} AND is_read = 0
GROUP BY chat_room_id
)위 두가지 서브쿼리는 채팅방 리스트 조회시에 가장 최근메시지와 읽지않은 메시지 개수를 가져오기 위한 서브쿼리이면 LEFT JOIN을 통해 결과값을 얻고 있다.
하지만 사진에서 보이다시피 서브쿼리에서 풀스캔이 일어난뒤 LEFT JOIN을 하기때문에
Data Swell(1:N 관계의 조인에서 불필요한 조인까지 수행) 이 일어나 쿼리 응답속도가 매우느려지는 상황이다.
1차적으로 서브쿼리 조인 시 Data Swell을 피하기 위해 아래와 같이 서브쿼리를 수정해 준다.
WITH LatestMessage AS (
SELECT CM.chat_room_id,
MAX(msg_cr_date_ms) AS latest_msg_date_ms
FROM CHAT_MESSAGE CM
WHERE CM.chat_room_id IN (
SELECT CR2.chat_room_id
FROM CHAT_ROOM_MEMBERS CR2
WHERE CR2.chat_room_id IN (
SELECT CR3.chat_room_id
FROM CHAT_ROOM_MEMBERS CR3
WHERE CR3.usr_id = #{usrId}
)
)
GROUP BY CM.chat_room_id
),
UnreadCount AS (
SELECT CM.chat_room_id,
COUNT(*) AS unread_count
FROM CHAT_MESSAGE CM
WHERE 1=1
AND CM.chat_room_id IN (
SELECT CR2.chat_room_id
FROM CHAT_ROOM_MEMBERS CR2
WHERE CR2.chat_room_id IN (
SELECT CR3.chat_room_id
FROM CHAT_ROOM_MEMBERS CR3
WHERE CR3.usr_id = #{usrId}
)
)
AND CM.usr_id != #{usrId}
AND CM.is_read = 0
GROUP BY CM.chat_room_id
)Data Swell을 피하기위해 채팅방 마스터 테이블에서 LEFT JOIN을 걸고있는 서브쿼리에서 현재 조회하는 세션의 아이디 고유번호가 참여하고 있는 채팅방정보에 대해서만 필터링하여 결과집합을 조인하도록 변경하였다.
튜닝후 실행계획
- 아래와 같이 LEFT JOIN을 보다 효율적이게 변경하였다.
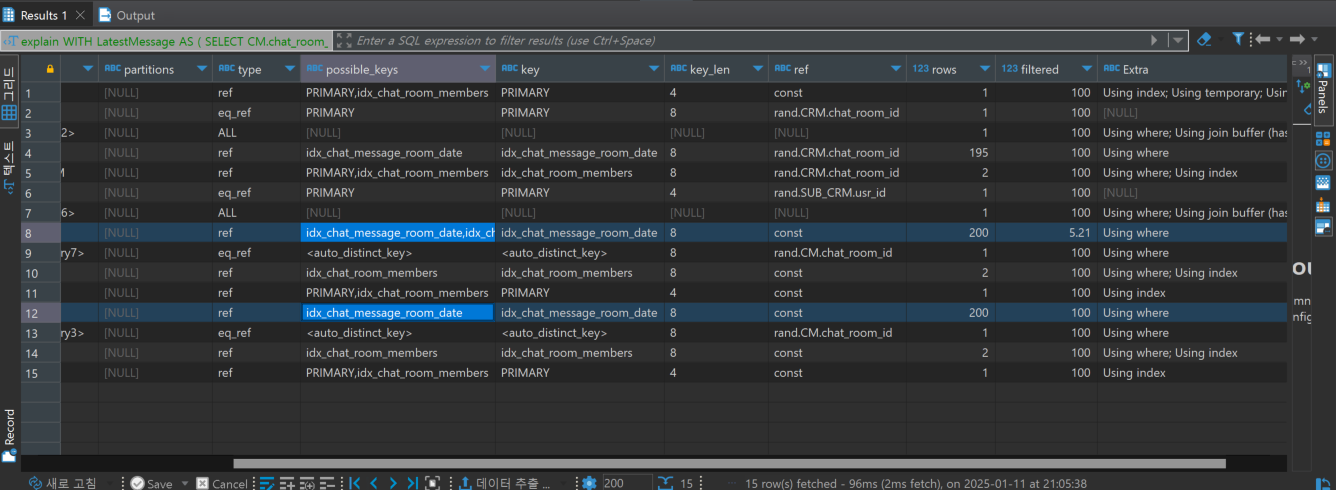
응답시간도 약 13초에서 평균20ms로 대폭 상승하였다.
대량의 더미데이터가 없었다면 성능저하 포인트를 찾을 수 없었을거라고 예상한다.
실제 TPS와 Letancy가 얼마나 증가하였는지 측정해본다.
쿼리 튜닝전
-
사용 툴 :
JMETERCASE 1: Threads : 100 , Loop Count : 2 - >ERROR: 0 %
CASE 2: Threads : 200 , Loop Count : 2 - >ERROR: 0 %
CASE 3: Threads : 300 , Loop Count : 2 - >ERROR: 0 %
CASE 4: Threads : 400 , Loop Count : 2 - >ERROR: 52.12%
-> NGINX 502 : 느린 응답시간때문에 타임아웃이 발생한것으로 판단됌.
CASE 3 , 4 에 대한 정확한 TPS 및 Latency 재측정CASE 3X 3회수행
-
TPS: 6.2 -
Average Latency: 35485 -
Min Latency: 1589 -
Max Latency: 50215
CASE 4X 1회수행
-
TPS: 6.6 (에러로 인한 비정확한 수치) -
Average Latency: 44967 -
Min Latency: 23 -
Max Latency: 120028 -
ERROR: 49.62 %
쿼리 튜닝 후
-
사용 툴 :
JMETERCASE 1: Threads : 100 , Loop Count : 2 - >ERROR: 0 %
CASE 2: Threads : 200 , Loop Count : 2 - >ERROR: 0 %
CASE 3: Threads : 300 , Loop Count : 2 - >ERROR: 0 %
CASE 4: Threads : 400 , Loop Count : 2 - >ERROR: 0%CASE 3

-
TPS: 206.8 -
Average Latency: 711 -
Min Latency: 61 -
Max Latency: 1360
CASE 4

-
TPS: 263.8 -
Average Latency: 656 -
Min Latency: 48 -
Max Latency: 1287
1차 최적화 결과
- TPS 약 6 - > 약 230 정도로 증가하였고 , Latency 또한 40000 - > 600언저리로 감소하였다.
BUT
욕심이 난다. 내 예상이 맞다면 Min Latency : 48 이고, Max Latency : 1287 이라면 특정 지점에서 지연이 발생하였고 이 이유는 스레드풀 큐에서의 대기현상으로 인해 발생했을거라고 생각한다.
특히 그 이유는 EC2 t2.micro를 사용하고 있기 때문이라고 생각한다.
스케일 업을 통해서 Latency의 폭을 줄일 수 있을까?
2차 최적화 결과
채팅 I/O 서버 t2.micro - > t3.large 스케일업
CASE 1 : Threads : 400 , Loop Count : 2 - > ERROR : 0 %
CASE 2 : Threads : 500 , Loop Count : 2 - > ERROR : 0%
CASE 3 : Threads : 1000 , Loop Count : 2 - > ERROR : 0%
CASE 1

TPS: 631.9Average Latency: 39Min Latency: 13Max Latency: 124
CASE 2

TPS: 521.20Average Latency: 160Min Latency: 14Max Latency: 311
CASE 3

TPS: 662.7Average Latency: 718Min Latency: 57Max Latency: 1283
스케일 업을 통해 1차 최적화에 비해 TPS도 약 3배정도 증가하였고 , Min Latency 와 Max Latency의 격차를 줄임으로서 평균 Latency도 대폭 감소하였다.
예상이 맞았던것 같다. 1차적으로 쿼리튜닝을 통해 I/O접근시간을 감소시켰고, 평균 12ms라는 수치에서 더이상 감소할수 없다고 판단한 뒤 스케일업을 통해 스레드풀 대기시간을 감소시킴으로서 Latency를 감소 및 TPS를 증가 시켰다.
물론 스케일업도 동일한 결과를 냈을거라 생각한다.
2. 채팅메시지 리스트 조회 (오래된 메시지 조회) API
- 채팅메시지 리스트 조회 API (이전 메시지 조회)
해당 API는 I/O성능보다는 리버스프록시, 로드밸런싱을 해주는 NGINX spec 자체에 문제가 많을 것이라 판단한 API이다. 이유는 다음과 같다.
- 적절한 TPS와 Latency
- 점진적인 TPS감소 및 Latency증가가 아닌 특정 지점에서의 요청거부 발생
- Min Latency가 0인 현상 ( 요청 자체를 라우팅 안했을 가능성)
기존 API 부하테스트 결과
-
사용 툴 :
JMETERCASE 1: Threads : 300 , Loop Count : 2 - >ERROR: 0 %
CASE 2: Threads : 500 , Loop Count : 2 - >ERROR: 0 %
CASE 3: Threads : 700 , Loop Count : 2 - >ERROR: 1.79 %
CASE 4: Threads : 1000 , Loop Count : 2 - >ERROR: 22.40%
-> EC2 메모리와 성능부족 현상으로 판단됌
CASE 3 , 4 에 대한 정확한 TPS 및 Latency 재측정CASE 3수행
-
TPS: 369.1 -
Average Latency: 756 -
Min Latency: 0 -
Max Latency: 2377 -
ERROR: 1.79%
CASE 4수행
TPS: 501.4 (에러로 인한 비정확한 수치)Average Latency: 659Min Latency: 0Max Latency: 2250ERROR: 21.40 %
NGINX 스케일업 t2.micro - > t3.large 후 부하테스트 결과
-
사용 툴 :
JMETERCASE 1: Threads : 300 , Loop Count : 2 - >ERROR: 0 %
CASE 2: Threads : 500 , Loop Count : 2 - >ERROR: 0 %
CASE 3: Threads : 700 , Loop Count : 2 - >ERROR: 0%
CASE 4: Threads : 1000 , Loop Count : 2 - >ERROR: 0%
CASE 3수행
-
TPS: 690.7 -
Average Latency: 522 -
Min Latency: 12 -
Max Latency: 1584
CASE 4수행
-
TPS: 781.9 -
Average Latency: 548 -
Min Latency: 29 -
Max Latency: 973
ERROR 율 - > 0%
TPS 약 400 - > 약 700
평균 Latency 약 800 - > 약 550
물론 I/O작업의 처리속도를 높였어도 좋았겠지만 , NGINX 백로그큐(대기큐) 초과 현상이 원인이었다는 내 예상은 어느정도 맞았던 것 같다.
