목표
- Merge Sort 알고리즘 이해
- Merge Sort 알고리즘 구현
- Merge Sort 알고리즘 특징과 시간복잡도 이해
Merge Sort 알고리즘
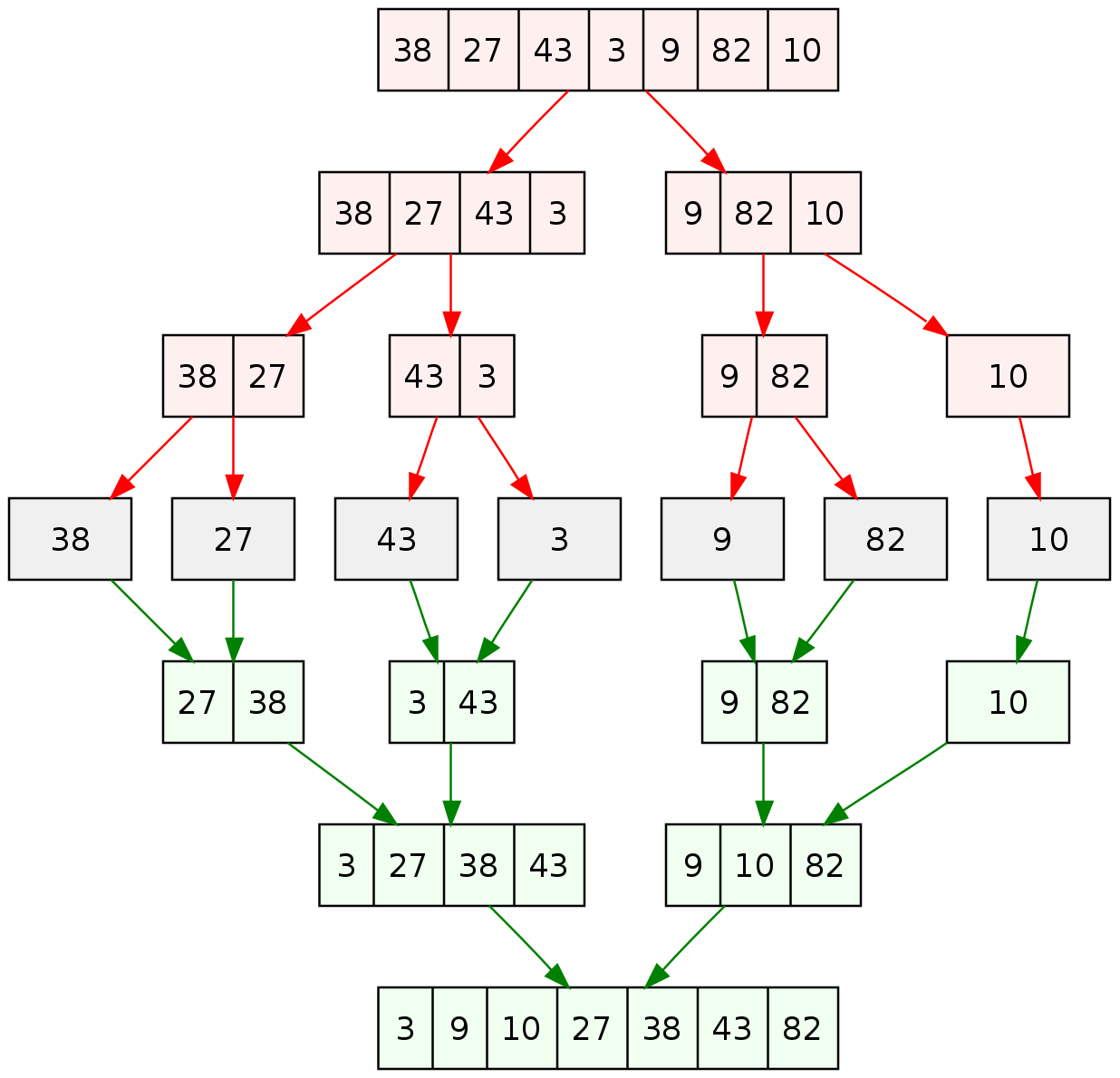
- 가장 기본적인 재귀정렬 알고리즘
- 비교 연산을 사용하는 안정 정렬
- Divide and Conquer(분할정복) 기법을 사용
하나의 큰 문제를 각각의 작은 문제로 분할하여 해결한 뒤 결과를 모아서 해결하는 기법
recursive call(재귀호출)을 통해 구현 - 0 또는 1이 될 때까지 리스트를 분할
- 정렬은 분할이 아닌 정복 시 발생
Merge Sort 알고리즘 구현
Top-down 방식 구현
- Pivot(mid)를 기준으로 전체 리스트를 분할
- 크기가 0 또는 1이라면 정렬된 리스트로 판단
- 길이가 0 또는 1이 될 때까지 리스트를 분할
- 분할된 리스트들을 재귀를 이용하여 정렬
- 정렬된 리스트를 합병
- 정렬된 리스트를 원본으로 복사
실패 코드 : 값이 1 2 3 4 5 6 7 8 8 로 나오는 현상
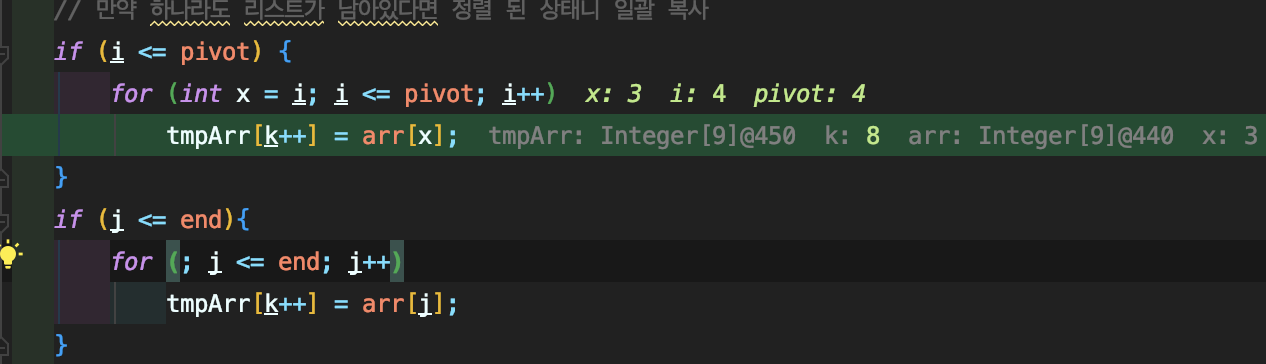
- 50분 정도 걸려서 해결
- 전혀 눈치를 못채고 있던 부분으로 for문의 대입 연산은 for-loop식이 종료되고 일어난다는 것
남아있는 리스트에서 마지막 인덱스인 4까지 도달 시 마지막 값인 9가 복사 되는데
실제로는 for( x = 0; ) for ( x = 1) for ( x = 2 ) for ( x = 3 ) 으로 대입연산이 실행됨
대입연산은 식이 종료된 뒤 다음 식이 실행될 때 일어나기 때문에 발생한 일
성공 코드 : array
// 만약 하나라도 리스트가 남아있다면 정렬 된 상태니 일괄 복사
if (i <= pivot) {
for (; i <= pivot; i++)
tmpArr[k++] = arr[i];
}
if (j <= end){
for (; j <= end; j++)
tmpArr[k++] = arr[j];
}- 대입연산을 수행하지 않고 인덱스 i 자체를 사용
while (i <= pivot) {
tmp[k++] = arr[i++];
}
while (j <= end) {
tmp[k++] = arr[j++];
}- while-loop와 i 를 이용
성공 코드 : linked list
Merge Sort 알고리즘 특징과 시간복잡도
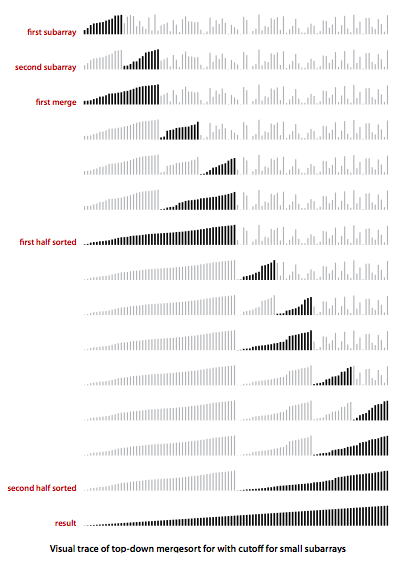
특징
- 입력 데이터의 크기와 관계없이 시간은 언제나 O(N log N)의 시간을 가짐
- 입력 데이터의 크기에 따라 공간복잡도는 O(n)까지 증가(동일 크기 사본 리스트를 사용하여 정렬)
- 데이터의 비교 연산은 분할 횟수에 따른 Stack 깊이는 n/2까지 증가
- 연결리스트로 사용 시 데이터의 순서는 보장되어 있어 연결리스트의 검색시간 단점 상쇄
데이터 순서에 따른 인덱스만 변경하기때문에 큰 데이터 정렬에 있어서 가장 효율적
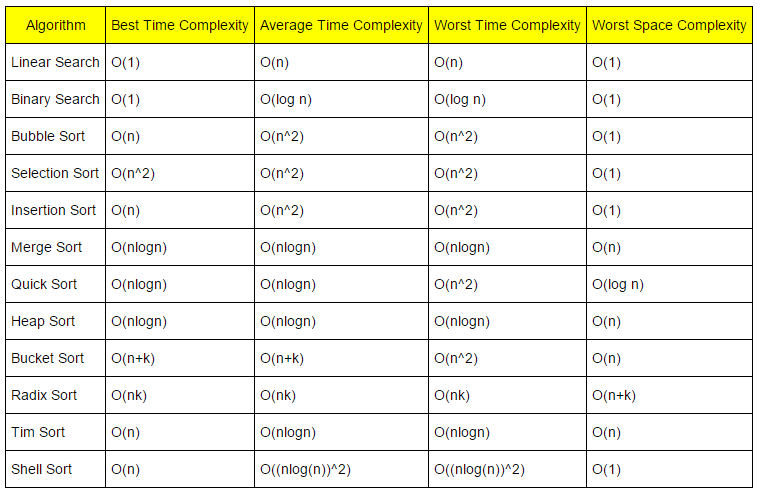
시간복잡도
- 분할에서는 연산이 없음
- 분할 된 리스트를 정렬 시 연산 발생
- 평균과 최악에서 O(N log N)
문제점과 개선
문제점
- 제자리 정렬이 아닌 새로운 메모리를 통해 데이터를 정렬하고 원본 메모리에 저장
이는 원본 메모리 + 사본 메모리가 필요, 10만개의 리스트면 10만개의 리스트가 더 필요하다.
개선
- 대체 알고리즘 사용
공부한 결과 mergesort의 가장 확실한 개선점 대체 알고리즘의 사용이다.
이는 하드웨어적 특징인 참조의 지역성(Locality of Referance)에 따른 이유인데
간단하게 말하면 프로세서가 메모리를 가장 효율적으로 사용하기 위해 짧은 시간, 가까운 공간 내의 데이터에 메모리에 반복적으로 접근하려한다는 원리다.
모든 메모리를 절반으로 분할하고 별도의 메모리까지 생성해야하는 mergesort는 O(n log n)을 보장한다고 했음에도 불구하고 이러한 특징에 의해 실제로는 quicksort보다도 더 느리게 작동할 수 있다.
이러한 이유에 의해 머지소트를 굳이 개선해서 사용하기보다는 퀵과 힙, 삽입정렬을 통해 대체하여 사용한다.
참조의 지역성 영문위키
참조의 지역성에 따라 퀵소트가 더 빠른 이유
참고

안아줘요