Alpaca: A Strong, Replicable Instruction-Following Model
Meta의 LLaMA 7B 기반 모델
ABSTRACT
- instruction-following 능력을 가진 LLM을 학계가 재현할 수 있도록 만든 공개 프로젝트
- Meta의 LLaMA 7B 모델을 기반으로, OpenAI text-davinci-003이 생성한 52K instruction 데이터를 이용해 supervised fine-tuning함
- 예비 평가에서 text-davinci-003과 유사한 품질을 보이며, 생성비용은 약 $600 미만으로 저렴함
- 학계 연구자들이 접근 가능한 instruction model로서 의미 있음
1. INTRODUCTION
- instruction-following LLM(GPT-3.5, ChatGPT, Claude 등)은 점점 강력해지고 있음
- 하지만 오류(hallucination), 편향(stereotype), 유해 언어 등 여전히 한계 존재함
- 학계에서 이에 대한 연구 필요성이 크지만, 강력한 오픈소스 모델이 부족하여 연구 어려움
- 해결책으로 Stanford는 공개된 LLaMA 7B에 instruction 데이터셋을 활용하여 Alpaca 모델을 구축함
- 목표는 text-davinci-003과 유사한 성능을 가진 모델을 누구나 재현할 수 있게 만드는 것
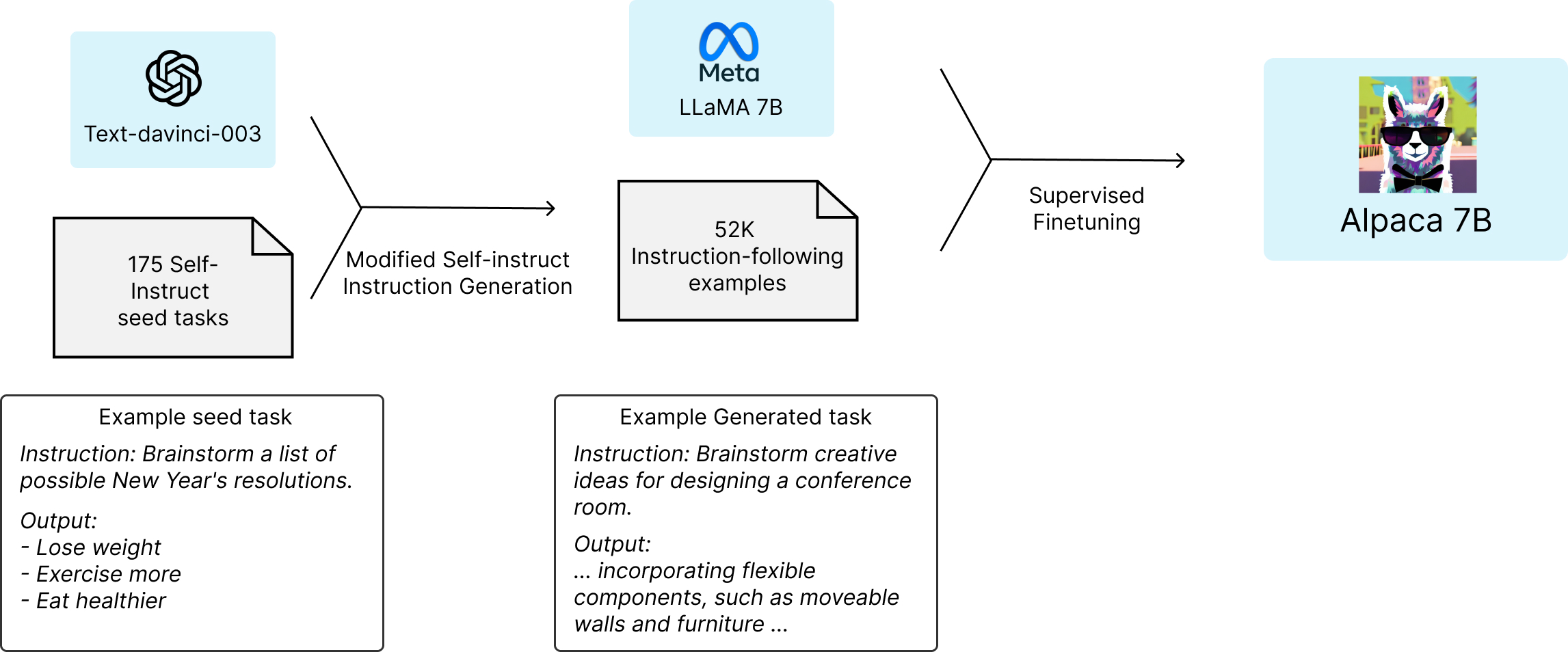
2. TRAINING RECIPE
-
학술적 예산 하에 고성능 instruction 모델을 훈련하려면:
- 강력한 사전학습 언어 모델 필요 → Meta의 LLaMA 시리즈 활용
- 고품질 instruction 데이터 필요 → Self-Instruct 방식을 기반으로 text-davinci-003이 생성한 데이터 사용
데이터 생성 방식
- self-instruct seed로 제공된 175개 human-written instruction-output 쌍 활용
- 이를 기반으로 text-davinci-003에 in-context prompting으로 instruction 예시 생성
- 프롬프트 구조 단순화로 비용을 절감하며, 총 52K 쌍 생성 (OpenAI API 비용 약 $500)
모델 튜닝
- Hugging Face Transformers로 LLaMA 7B 모델을 fine-tuning
- Fully Sharded Data Parallel + mixed precision 훈련 적용
- 80GB A100 GPU 8개로 약 3시간 소요, 비용 약 $100
병렬 학습(Fully Sharded Data Parallel) 및 혼합 정밀도 학습(Mixed Precision Training)
3. PRELIMINARY EVALUATION
평가 방법
- self-instruct 벤치마크 세트에 대해 human 평가 수행
- 5명의 공동 저자가 blind pairwise 비교 (Alpaca vs text-davinci-003)
- 90 vs 89로 유사한 성능 결과 확인
분석 결과
- 작은 데이터와 모델 크기에도 text-davinci-003 수준의 성능을 보인 점이 인상적
- 상호작용 테스트에서도 다수의 입력에 대해 유사한 품질의 응답 생성 확인
- 다만, 평가 범위의 한계 존재하므로 대중과의 상호작용을 통해 피드백 수집이 중요하다고 판단함
4. KNOWN LIMITATIONS
- hallucination: 예) 탄자니아의 수도를 Dar es Salaam으로 잘못 응답함
- misinformation: 말은 그럴듯하나 잘못된 정보 생성 가능
- 기존 대형 언어 모델과 유사한 한계 포함됨
- instruction data 자체가 text-davinci-003 기반이므로 편향 전이 가능성 존재
5. ASSETS RELEASED
이미 공개됨
- Alpaca 7B 데모 (현재는 비활성화됨)
- 학습 데이터(52K instruction-output 쌍)
- 데이터 생성 코드
- 학습 코드 (Hugging Face 기반)
향후 공개 예정
- 모델 가중치 (Meta 측과 협의 중)
사용 조건
- LLaMA의 비상업 라이선스를 따르므로 상업적 이용 금지
- OpenAI text-davinci-003 기반 데이터 사용 → OpenAI 경쟁 모델 개발 금지
- Alpaca는 연구 목적에 한해 사용 가능
6. RELEASE DECISION
-
공개의 위험성도 고려함 (악용, 스팸, 허위정보 등)
-
하지만 학술적 연구의 재현성, 투명성, 안전성 향상이 더 큰 이점이라 판단
-
완전한 오픈 전에도 다음과 같은 위험 최소화 장치 마련함:
- OpenAI content moderation API 활용한 필터 적용
- Kirchenbauer et al. (2023) 방식의 워터마크 삽입
- 명시적 이용 조건 설정
7. FUTURE DIRECTIONS
- HELM 등의 벤치마크로 더욱 정량적 평가 수행 예정
- red-teaming, auditing, adaptive testing 통한 안전성 향상 목표
- instruction 데이터 구성 요소의 중요성, base model 특성 등 체계적으로 분석할 예정
- Alpaca를 시작으로 다양한 open instruction LLM 연구를 촉진하고자 함

서비스기획/.AI/데이터분석