AI Paper Review
1.LoRA

LoRA https://arxiv.org/abs/2106.09685 🌟 나름의 요약 실제로 학습하고 있는 정보, 두 가지: pre-trained weight(W0)와 A*B LoRA: pre-trained는 고정시키고, 여기서 전체 정보 말고, 좀 더 적은 정보
2025년 7월 9일
2.Chain-of-Thought Prompting
Chain-of-Thought Prompting ABSTRACT 사고의 사슬(chain of thought)은 사고의 사슬 프롬프팅(chain-of-thought prompting)을 통해 구현한다 세 가지 대규모 언어 모델에 대한 실험을 통해 사고의 사슬 프롬프트
2025년 7월 23일
3.Alpaca
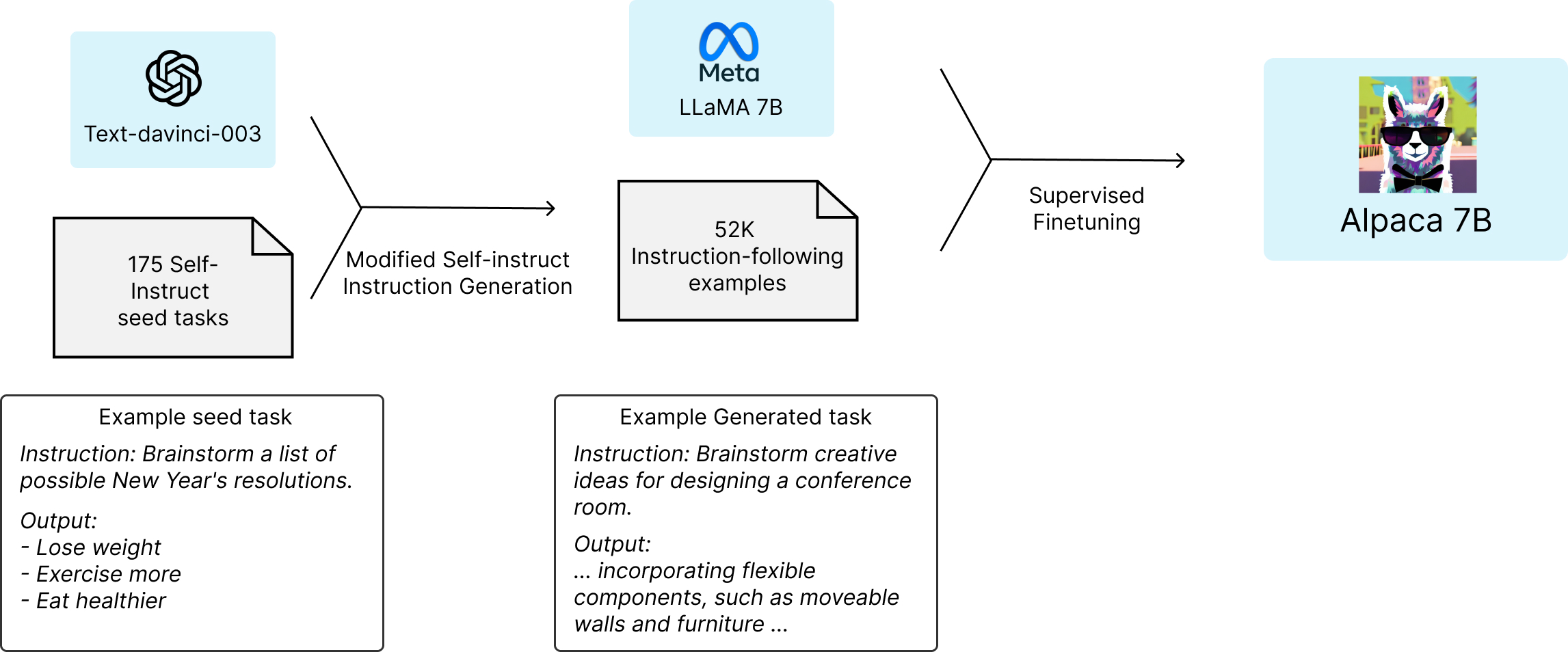
Meta의 LLaMA 7B 기반 모델instruction-following 능력을 가진 LLM을 학계가 재현할 수 있도록 만든 공개 프로젝트Meta의 LLaMA 7B 모델을 기반으로, OpenAI text-davinci-003이 생성한 52K instruction 데이
2025년 7월 30일
4.LLaMA 논문 리뷰
https://arxiv.org/abs/2302.13971LLaMA는 비교적 가벼운 모델, 오픈 소스 데이터만 사용한 모델LLaMA-13B는 대부분의 벤치마크에서 GPT-3(175B)보다 뛰어난 성능LLaMA-65B는 Chinchilla-70B 및 PaLM-5
2025년 8월 6일
5.DPO : A Differential and Pointwise Control Approach to Reinforcement Learning
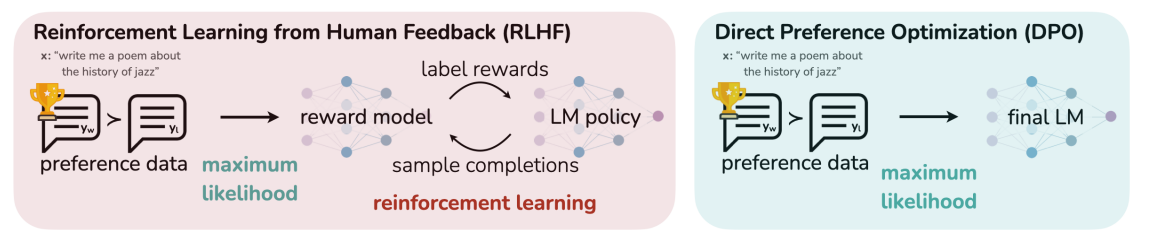
2023.05https://arxiv.org/abs/2305.18290RM와 RL 없이 LLM policy model만을 학습하여, 사람의 선호도를 반영한 문장을 생성하도록 LLM을 직접적으로 최적화 하는 알고리즘본 논문은 대규모 언어 모델(LM)의 동작을 제
2025년 8월 13일