목차
1. 추천시스템 분류
2. 추천시스템 Overview
- 2.1 Challenges
- 2.2 Data
- 2.3 Models
- 2.4 Evaluation
추천시스템을 처음 접했던 건 고3..
빅데이터나 AI가 지금만큼은 아니지만 막 화두되고 있던 시기
이쪽으로 입시를 하기로 맘먹고, 관련 도서를 뒤적거리다가
원래 광고나 마케팅에도 관심이 있어서 자연스럽게 추천시스템이 끌렸다.
한창 넷플릭스의 추천 알고리즘이 떠올랐을 때라 넷플릭스 알고리즘 '시네매치'랑 아마존 추천 시스템을 비교하는 활동을 했었던 것 같다.
그러면서 collaborative filtering, cold start, long tail 등 용어를 처음 알게 됐었다.
그리고 휴학하면서는 서비스(모각작)를 만들었는데, 우리가 뭐 이커머스 같은 추천이 필요한 서비스는 아니지만, 그럼에도 이를 홍보하거나 SEO최적화를 할 때는 추천시스템에 대한 이해가 있으면 좋겠다는 생각을 하곤 했다.
그러다, 드디어 4-1인 이번에 "추천시스템 설계"라는 교과를 수강하게 되었다!! ㄷㄱㄷㄱ
대학교 내내 가장 로망이던 수업이라 무척 기대가 된다.
교수님도 휴학 전에 수업 들었던 교수님인데, 넘 좋아하는 교수님이라 너무 기대된다.
짧고 굵게, 동시에 재밌고 이해 쏙쏙 되게 설명해주시는 교수님이다~~ 아자스!!

앞으로 복습겸 주요 내용을 리뷰해보겠다.
오늘은 추천시스템에 대한 전반적인 개요!
1. 추천시스템 분류
여러 기준에 따라 분류가 가능하다
- 추천 형식
- 별점/평점 예측, 추천 목록 나열 (순위 매기기)
- 사용 데이터
- 별점 데이터, 간접 피드백 데이터
- 유저 정보, 아이템 정보, 상황 정보
- 관계 정보
- 추천 방법
- collaboraitve filtering, content-based filtering
- memory-base, model-based
2. 추천시스템 Overview
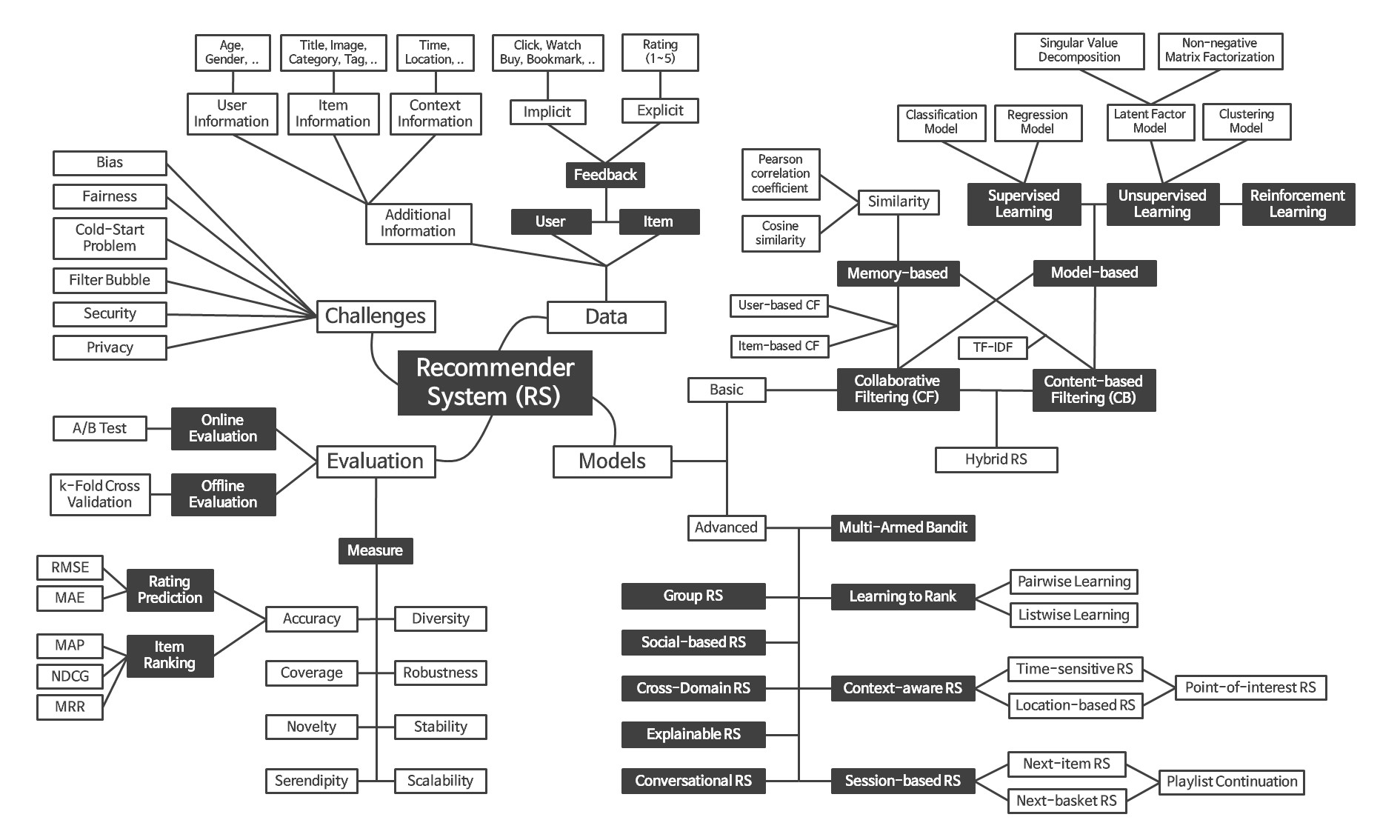
출처 : https://github.com/jihoo-kim/awesome-RecSys
2.1 Challenges
추천 시스템에서 고려해야 하는 challenge
- Bias : 한쪽으로 너무 치우치는 추천. 정확도가 높더라도 너무 한쪽 (e.g. 한 브랜드)만 하는 건 좋은 추천이 아님
- Fairness :
- 사용자 측면: 성별, 인종, 연령 등에 따라 차별적인 추천을 하지 않는가?
- 아이템 측면: 신규 판매자나 소외된 카테고리에도 노출 기회를 균등하게 제공하는가?
- Cold-Start problem : 처음 데이터가 충분치 않아서 적절한 추천을 하지 못하는 상황
- Filter Bubble : 확증편향, 점점 특정 분야로만 추천 (e.g. 강아지 릴스 시청 → 강아지 관련밖에 안뜸. 인스타는 커뮤니티 보다 강아지 앱이 되어버림)
- Security, Privacy
2.2 Data
데이터들의 유형
- User : 나이, 성별,,,
- Item : 제목, 이미지, 카테고리, 키워드,,,
- Context : 시간, 위치,,,
- User-Item Feedback
- Explicit Feedback: 사용자가 직접적으로 자신의 선호도나 평가를 표현한 데이터
- 예) 별점,리뷰,좋아요/싫어요
- Implicit Feedback: 사용자의 직접적인 평가나 선호도 표현없이, 사용자의 행동으로부터 간접적으로 추론할 수 있는데이터
- 예) 페이지조회수,구매이력,장바구니추가,스트리밍시간, 클릭기록User-Item Interaction Matrix (상호작용 행렬)
위에서 언급한 User와 Item 간의 피드백 데이터를 수학적으로 구조화한 것을
"User-Item Interaction Matrix, Utility Matrix, Rating Matrix" 등으로 부른다.
- Explicit Feedback: 사용자가 직접적으로 자신의 선호도나 평가를 표현한 데이터
2.3 Models
알고리즘의 복잡도, 데이터 활용의 범위 등에 따라 Basic, Advanced 로 분류할 수 있다.
Basic
이번 학기엔 대부분 Basic models을 주로 배우게 된다
Basic 모델을 분류하는 기준에는 크게 두 가지 관점이 있다.
-
관점 1 : "어떤 정보를 사용"해서 선호를 추정하는지
-
Collaborative Filteirng (CF) : ‘사용자-아이템 상호작용 데이터’를 사용해서 추천.
"나와 비슷한 사람(User)은 이것도 좋아하겠지?" 혹은 "이 아이템을 산 사람은 저것도 사더라(Item)"왜 'collaborative' 라고 이름 붙였을까 생각해보면,
내가 영화 A를 보고 남긴 별점이 나와 취향이 비슷한 다른 사람에게 영화 A를 추천할지 말지 결정하는 중요한 근거가 되듯이, 데이터들이 서로의 추천을 돕는(collaborate) 구조라는 의미 같다. -
Content-base Filtering (CBF) : 아이템 속성(카테고리, 설명, 키워드, 장르)만을 사용해서 추천
-
-
관점 2 : "학습의 유무"
-
memory-based Approach : 이전에 사용자가 봤던 영화와 비슷한 영화를 추천.
사용자/아이템 속성 간의 유사성을 직접 계산하여 추천Similarities
- Cosine Similarity: 두 벡터 사잇각의 cosine 값.
같은 방향(가까울수록) 1, 다른 반대 방향(유사도가 멀수록) 0 - Pearson Correlation Coefficient (CenteredCosineSimilarity): ???
- Jaccard Similarity : 두집합의 합집합 크기 대비 교집합 크기 비율
→ 이 3가지는 다음 포스팅에서 자세히 다루겠다!
- Cosine Similarity: 두 벡터 사잇각의 cosine 값.
-
model-based : 인공지능이 파라미터를 학습해서 추천
-
Advanced
- Multi-Amed Bandit (MAB) : 이건 베이지안 통계 수업 때 자세히 배웠었는데, 활용과 탐색 두 가지 중 하나를 선택하며 최적을 찾는 모델이다.
- 활용 : 지금까지의 데이터상 반응이 가장 좋았던 아이템을 보여주는 것.
- 탐색 : 확신하기에 아직 데이터가 부족하지만 잠재력이 있는 새로운 아이템을 보여주는 것.
2.4 Evaluation
(1) 평가 환경 및 방법
-
Offline evaluation
사용중에 말고, 나중에 떼와서. 즉, 이미 수집된 과거 데이터를 사용하여 평가하는 방식 -
Online evaluation
실제 운영 중인 서비스 환경에서 '실제 사용자'를 대상으로 평가하는 방식- A/B test : 여러 유저에게 다양한 버전으로 보여주고 → '어떤 버전이 클릭률이 더 높다더라' 하는 등의 분석 방법
ex) 넷플릭스 썸네일, UI/UX 등 여러 버전으로 배포.
실제로 서비스 기획 과정 중에, UT에서부터 MAZE 등을 사용해서 많이 했었다.
- A/B test : 여러 유저에게 다양한 버전으로 보여주고 → '어떤 버전이 클릭률이 더 높다더라' 하는 등의 분석 방법
(2) Evaluation Measure_평가 지표 및 속성
- Acurracy
- Rating Prediction (별점/평점 오차 측정 방법)
사용자가 특정 아이템에 부여할 구체적인 수치를 정확하게 예측하는 것이 목표- RMSE (Root Mean Square Error)
- MAE (Mean Absolute Error)
- Item Ranking (추천 순서를 고려한 오차 측정 방법)
사용자가 좋아할 만한 아이템을 순서대로 나열하는 것이 목표
추천은 기존 머신러닝보다 “순서”가 훨씬 중요하다는 차이점이 있음- MAP (Mean Average Precision ) : 모든k에 대한 Precision@k의평균
- NDCG (NormalizedDiscountedCumulativeGain)
- MRR (Mean Reciprocal Rank)
- Rating Prediction (별점/평점 오차 측정 방법)
- Diversity : 얼마나 다양한가
- Novelty : 얼마나 새로운가
- Serendipity : 예상치 못한 즐거움을 주는가
- Stability: 시스템이 얼마나 안정적인가
끝!
