서비스
데이터 보안
- 사용할 데이터의 현재 상태와 흐름, 프로세스 고려
AI 앱
- 배포, 프론트엔드 고려
시스템 통합
- 기존 시스템의 요구사항 및 데이터 상황 고려
파인튜닝
- 데이터셋 보유 여부, 학습 관리/업데이트/테스트 프로세스 자동화 고려
반복업무를 LLM에게 훈련
- 데이터셋, 회사의 의도, tool 고려
LLM 특성
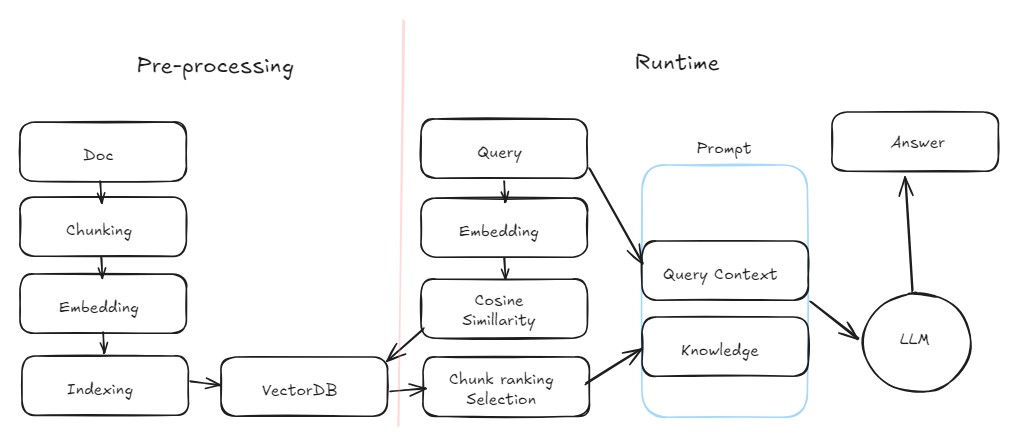
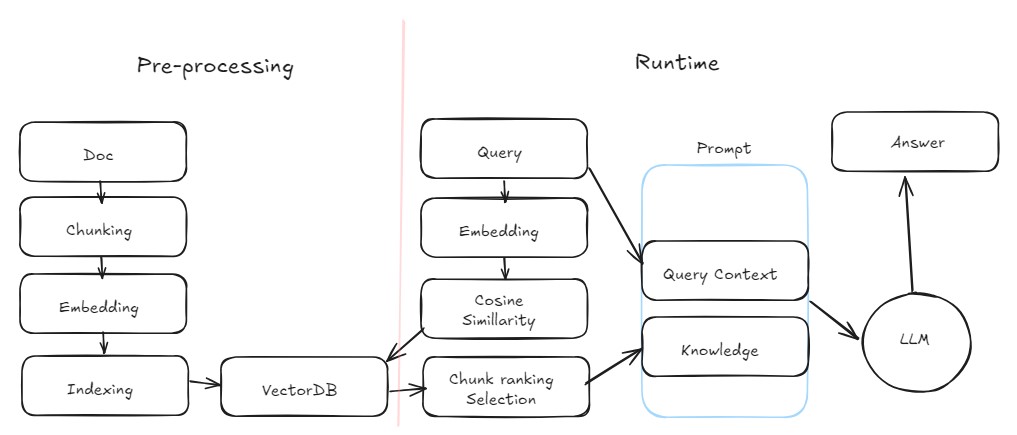
왜 RAG인가?
언어모델/사람의 뇌는 데이터베이스가 아니지만, 정확하게 기억한다고 착각할 수 있음.
오픈북 시험으로 바꾸면, 답변에 가이드라인을 제시함으로써 환각 현상 등을 줄일 수 있음.(모르는 것을 만들어내는 현상 방지)
RAG
AWS
대규모 언어 모델의 출력을 최적화하여 응답을 생성하기 전에 학습 데이터 소스 외부의 신뢰할 수 있는 지식 베이스를 참조하도록 하는 프로세스
대규모 언어 모델(LLM)은 방대한 양의 데이터를 기반으로 학습되며 수십억 개의 매개 변수를 사용하여 질문에 대한 답변, 언어 번역, 문장 완성과 같은 작업에 대한 독창적인 결과를 생성
RAG는 이미 강력한 LLM의 기능을 특정 도메인이나 조직의 내부 지식 기반으로 확장하므로 모델을 다시 교육할 필요가 없으며, LLM 결과를 개선하여 다양한 상황에서 관련성, 정확성 및 유용성을 유지하기 위한 비용 효율적인 접근 방식
Grouning
LLM이 사실(ground)에 기반해 답변할 수 있도록
Retrieval
- 외부 지식데이터로부터 지식을 가져옴
Augmented
- LLM에게 더 나아진 프롬프트 전달
Generation
- 답변 생성
프롬프트 엔지니어링의 일부.
데이터 자체를 프롬프트에 포함시킨다.
데이터는 여러 소스(PDF, 마크다운, 텍스트 파일 등)이므로 그것을 어떻게 가져오는가?
Embeddings
Embed
- 일반적 의미: 어떤 것을 다른 것에 삽입하거나 통합 ex) 웹 페이지에 비디오나 지도 등의 외부 콘텐츠를 '임베드'
- 기술적 의미: 특정 데이터/기능을 한 시스템 또는 장치 안에 내장
Embeding
- 삽입되거나 통합된 결과물
AI에서의 Embedding
- 단어와 문장과 같은 텍스트 데이터를 벡터의 형태로 표현
- LLM 내부에서 어떤 위치에 있는지
embedding_model = SentenceTransformer("thenlper/gte-large")
"""get embedding vector"""
def get_embedding(text: str) -> list[float]:
if not text.strip():
print("empty")
return []
return embedding_model.encode(text).tolist()Cosine 유사도
- 벡터공간 내에서 두 벡터 사이의 거리가 얼마나 가까운지(얼마나 유사한 의미를 가지는지)
- 두 벡터 사이의 코사인 각을 이용
- 방향이 비슷할수록 1에 가까워지고, 반대일수록 -1에 가까워짐
Semantic search
- 문서를 의미적 표현을 통해 색인화
- 검색 시 쿼리의 의미적 표현에서 가장 관련성 높은 문서를 찾기 위해 유사도 검색
- 텍스트 일치가 아닌 문맥을 고려한 일치 정도를 확인
Vector indexing
통상 DB에서는 인덱스/PK 활용
"key" 를 임베딩, "value" 를 원본 텍스트로 지정 -> vector DB
- Pinecone
- Weaviate
- FAISS
- AMZ: ElasticSearch
- MS: Cognitive Search
Ranking, cutoff
- 쓸데없는 내용 검색될 수 있음
- 검색 내용이 너무 많으면 토큰 수가 늘어나고 부정확
- 가장 유사도가 높은 검색 결과 n개를 이용해 메타 프롬프트를 생성
Chunking
정해진 사이즈로 청킹하면 의미가 손실되어 잘릴 수 있음.(보통 1024 토큰)
겹치는 부분을 설정하더라도, 문맥을 반영해야 하는 문제가 해결되지 않음.
문단으로 자르더라도, 꼭 문단으로 되어있지 않으며 각 문단의 길이가 다를 수 있음.
논문과 같이 정해진 포맷의 문서를 처리한다면 메타데이터를 포함해 청킹할 수 있지만 논문이 아닌 다른 타입 문서에는 적용하기 힘듦.
LlamaIndex
PDF, DB, API로 데이터를 전송해 청킹/인덱싱
study간 아래 URL참고
https://www.deeplearning.ai/short-courses/building-applications-vector-databases/
https://www.deeplearning.ai/short-courses/advanced-retrieval-for-ai/
https://www.deeplearning.ai/short-courses/preprocessing-unstructured-data-for-llm-applications/
https://wikidocs.net/231147
https://www.youtube.com/@AI-km1yn/videos
후처리[Post Processing]
답변이 문제가 있거나 처리가 필요할 때
Relevance: 관련성, 동문서답
moderation: 내용 검열 API. 사용자 쿼리에도 적용. 기존에는 긴 프롬프트로 적용했음
RAI: responsible, 윤리적
groundedness: 사실 기반
메타 프롬프트가 너무 길어지다 보니, moderation API로 프롬프트 확인.
Groundedness
https://docs.ragas.io/en/stable/concepts/metrics/index.html
RAGAS: RAG 파이프라인 평가하는 python framework
def ragas_eval(eval_sets):
return evaluate(
eval_sets,
metrics=[
context_precision,
faithfulness,
answer_relevancy,
context_recall,
answer_correctness
]
)
busan_context_right = [
"부산광역시는 한반도 남동부에 위치한 광역시이다. 대한민국 제 2의 도시이다."
]
eval_set = {
"question": ["대한민국에서 두 번째로 큰 도시가 어디야?"],
"answer": ["대한민국에서 가장 두번째로 큰 도시는 부산입니다."],
"contexts": [busan_context_right],
"ground_truth": ["부산"]
}
eval_sets = Dataset.from_dict(eval_set)
ragas_eval(eval_sets)
Evaluating: 100%
5/5 [00:04<00:00, 1.34it/s]
{'context_precision': 1.0000, 'faithfulness': 1.0000, 'answer_relevancy': 0.9044, 'context_recall': 1.0000, 'answer_correctness': 0.9725}파인튜닝과의 비교
정의
대규모 언어 모델의 출력을 최적화하여 응답을 생성하기 전에 학습 데이터 소스 외부의 신뢰할 수 있는 지식 베이스를 참조하도록 하는 프로세스 vs
특정 작업이나 도메인에 높은 적합성을 확보하기 위해, 이미 훈련된 대규모 언어 모델에 특정 데이터셋을 사용하여 추가적인 학습을 수행하는 프로세스
정확성
신뢰할 수 있는 소스에서 관련 정보를 검색하여 결과의 정확성 높임 vs
모델을 특정 작업이나 도메인에 맞게 최적화하여 효율성 증가
의존성
데이터에 기반해 응답을 생성하므로 신뢰도가 높음 vs
광범위한 데이터를 통해 모델 재학습
업데이트 가능성
참조 데이터셋을 새로운 정보로 업데이트 vs
모델을 업데이트
연산 비용
데이터를 검색하는 추가 단계 필요 vs
파인튜닝 과정이 자원을 많이 소모
데이터 품질 의존성
부족한 데이터는 효과를 제한 vs
학습 데이터의 품질에 따라 모델 성능이 좌우됨
확장성
데이터베이스 확장이 어렵고 자원 집약적 vs
모델을 바꿔야 함
소스 데이터에 대한 과도한 의존
새로운 응답을 생성하는 능력이 제한될 수 있음 vs
그런거 없음
정보의 오류 가능성
검색 오류/구식 정보 vs
트레이닝대로 답을 생성하지 않을 수 있음
개인정보 보호
데이터의 개인정보 유지 vs
개인정보 문제 야기 가능성
특화 task
작은 데이터셋, 모델의 잦은 업데이트 vs
새로운 장르, 분야, 특정한 업무의 퍼포먼스, 아웃풋 방식이 특수, 새로운 데이터
