AI
1.# [논문리뷰] LLaMA: Open and Efficient Foundation Language Models

모델의 크기(매개변수)와 데이터가 많아질수록 일반적으로 모델의 성능이 올라간다는 사실이 증명되었으나, 이는 학습비용만 고려했을 뿐 추론비용에 대해서는 고려하지 않음LAMMA : 7B-65B 규모의 LLM 모델라마의 크기(매개변수 수)를 67억개, 130억개, 325억개
2.# [작성중_논문리뷰] Attention is All you Need
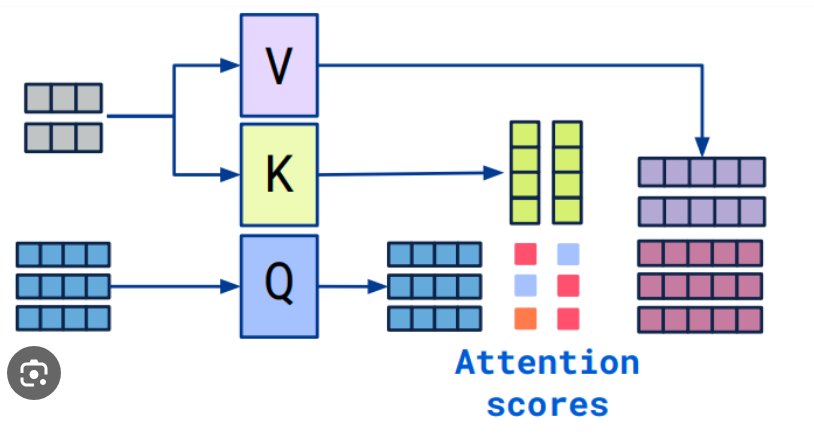
Q, K, V는 각각 쿼리(Query), 키(Key), 밸류(Value) 행렬softmax 함수를 통해 각 행의 합이 1이 되도록 Attention Score -> Attention Distribution 변환
3.# [세미나] ChatGPT 기반 어플리케이션 개발 과정
openAI platform에서의 playground/chat,comletion(deprecated)기본적으로 completion은 프롬프트부터 auto regressive인데, 대화라는 task에 맞게 파인튜닝해서 chat.completion으로 사용temperatu
4.# [세미나] 생성형 인공지능 모델과 프롬프트 엔지니어링
23.1.10. 오픈Scholar GPT/AllTrails 등 다양한 타스크의 서비스 GPT1,2는 해당없음. 3부터는 프롬프트의 중요성단어를 통해 영어공부하는 것보다 책을 통해 영어공부하는 것이 좋음처음엔 그 성능이 높지 않지만, 책을 이해하면 이해할수록 잘해짐GPT
5.# [Local LLM] 개념정리
ollma
6.# [세미나] AutoRAG
[Intro]
7.# [이슈] LLM의 내부구조 이해

블랙박스 먼저 블랙박스 개념에 대해 정리하겠습니다. 테스트 기법에서도 사용되는 용어이며, 의미는 비슷(??)합니다. 선형회귀, 의사결정 트리와 같은 전통적인 머신러닝 기법은 입력벡터에서 각 특성의 영향도를 확인할 수 있습니다. 즉 결과값에 대한 해석이 가능하며, 타
8.# [작성중_논문리뷰] LoRA: Low-Rank Adaptation of Large Language Models
모델이 커질수록 학습에 대한 비용이 증가하며 모든 파라미터에 대한 파인튜닝 또한 마찬가지다.Low-Rank Adaptation 는 사전학습된 모델의 파라미터를 freezing해 다운스트림 작업에 대한 학습 파라미터의 수를 크게 줄인다.We propose Low-Rank
9.# [기술] 학습시 메모리사용량 감소
[Quantization] [Flash Attention] [PEFT] [URL]
10.# [코드리뷰] Instruction Tuning
[개발환경]
11.# [기술] Instruction tuning
모델이 학습 과정에서 배우지 않은 작업을 수행하는 것을 의미한다. Vision에서는 새로운 클래스가 되겠고, NLP에서는 새로운 유형의 task가 되겠다. 예시 없이 바로 대답이 가능한 경우.유인나의 목소리로 음성을 생성하도록 학습한 TTS 모델이 예시 샘플을 이용하여
12.# [기술] Batch/Epoch
학습데이터를 한번에 신경망에 통과시키면 모든 학습 데이터를 사용해 파라미터를 업데이트하면 리소스 사용에 있어 비효율적이고 학습 시간이 오래 걸린다. 메모리가 부족해진다.\+---------------------------+| 전체 데이터셋(100%) |\+-
13.# [기술] 손실함수와 최적화함수
손실함수는 모델의 예측값과 실제값 사이의 차이를 측정해 모델이 얼마나 정확한지 평가하는데 사용됨Binary Cross-Entropy Loss의 약자로, 이진 분류 문제에서 사용됨.예측값이 0과 1 사이의 확률일 때, 그 확률과 실제 라벨(0 또는 1) 간의 차이를 측정
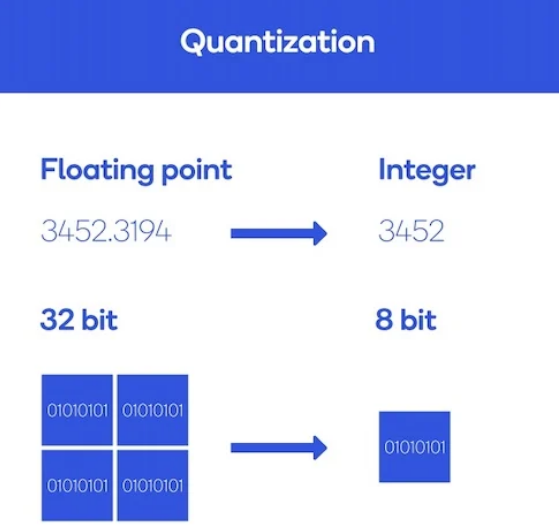
14.# [기술] PEFT/양자화
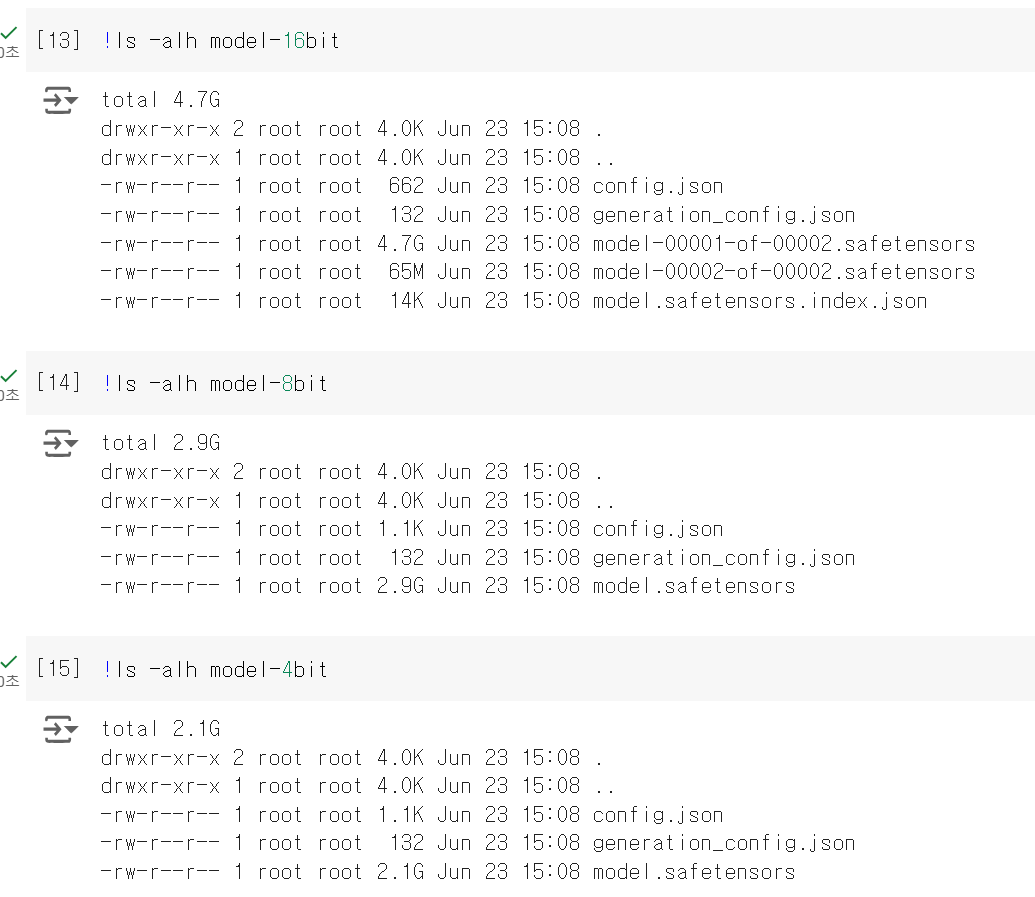
PEFT(Parameter-efficient fine-tuning) 적은 양의 매개변수 학습으로도 새로운 문제를 거의 비슷한 성능으로 해결할 수 있는 파인튜닝 방법론각각의 도메인 또는 언어에 대한 작은 체크포인트 파일만 로컬로 저장하면 되므로 효율적이며, 사전학습된 L
15.# [작성중_논문리뷰] Gemma: Open Models Based on Gemini Research and Technology
https://arxiv.org/pdf/2403.08295
16.# [기술] 딥러닝 프레임워크 비교
텐서플로 또는 텐서플로우는 다양한 작업에 대해 데이터 흐름 프로그래밍을 위한 오픈소스 소프트웨어 라이브러리이다. 심볼릭 수학 라이브러리이자, 인공 신경망같은 기계 학습 응용프로그램 및 딥러닝에도 사용된다.구글이 개발한 오픈소스 소프트웨어 라이브러리머신러닝과 딥러닝을 쉽
17.# [기술] RNN
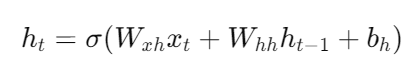
순환 신경망은 인공 신경망의 한 종류로, 유닛간의 연결이 순환적 구조를 갖는 특징을 갖고 있다. 이러한 구조는 시변적 동적 특징을 모델링 할 수 있도록 신경망 내부에 상태를 저장할 수 있게 해주므로, 순방향 신경망과 달리 내부의 메모리를 이용해 시퀀스 형태의 입력을 처
18.# [토크나이징/임베딩]
[Tokenizer]
19.# [이슈] LLM에서 토큰 별 활성화 측정
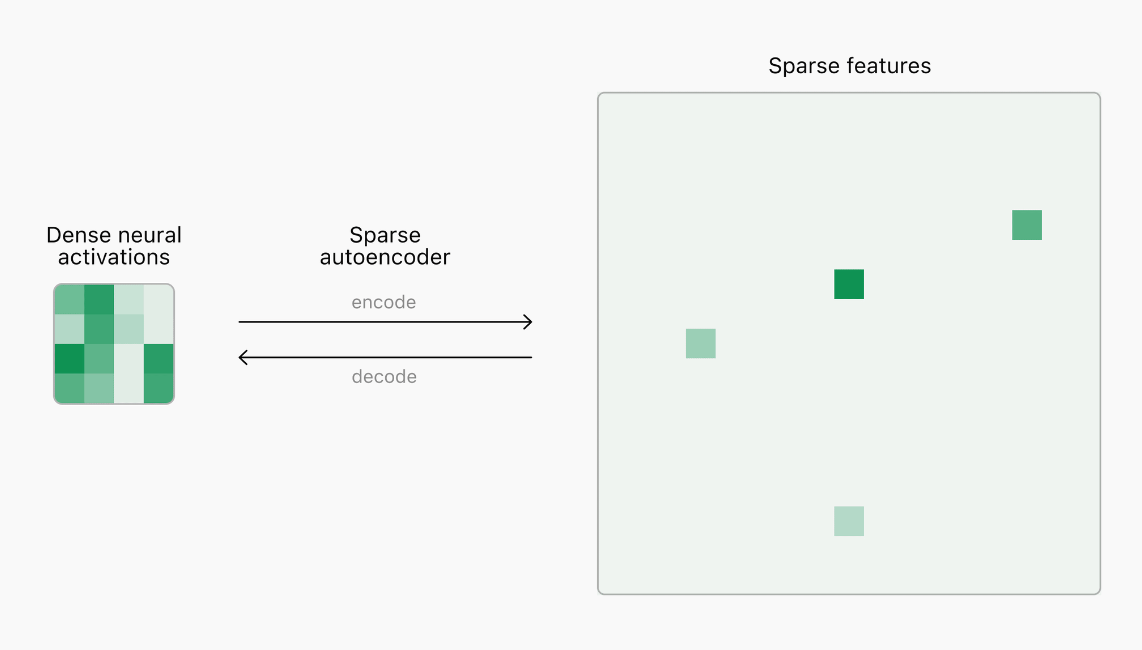
[신경망 해석의 한계] 현재 우리는 언어 모델 내의 신경 활동을 이해하는 방법을 이해하지 못합니다. 자동차 엔지니어는 구성 요소의 사양을 기반으로 자동차를 직접 설계, 평가 및 수리하여 안전과 성능을 보장할 수 있으나, 신경망은 직접 설계되지 않습니다. AI 엔지니
20.# [기술] Knowledge Distillation

In machine learning, knowledge distillation or model distillation is the process of transferring knowledge from a large model to a smaller one. While
21.# [기술] Rouge Score
ROUGE, or Recall-Oriented Understudy for Gisting Evaluation, is a set of metrics and a software package used for evaluating automatic summarization an
22.# LLM Service:RAG
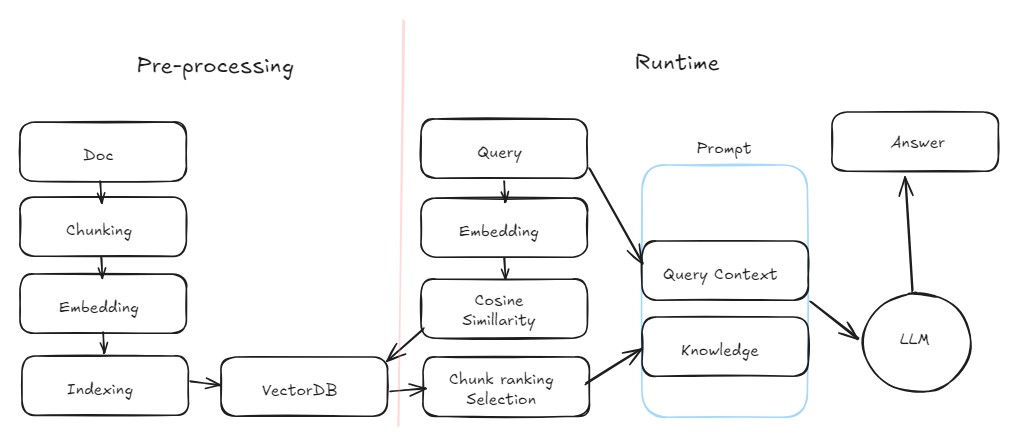
데이터 보안사용할 데이터의 현재 상태와 흐름, 프로세스 고려AI 앱배포, 프론트엔드 고려시스템 통합기존 시스템의 요구사항 및 데이터 상황 고려파인튜닝데이터셋 보유 여부, 학습 관리/업데이트/테스트 프로세스 자동화 고려반복업무를 LLM에게 훈련데이터셋, 회사의 의도, t