completion <-> chat.completion
- openAI platform에서의 playground/chat,comletion(deprecated)
- 기본적으로 completion은 프롬프트부터 auto regressive인데, 대화라는 task에 맞게 파인튜닝해서 chat.completion으로 사용
하이퍼파라미터
-
temperature: 높을수록 답변의 다양성 증가(0~1), 낮으면 확정적
-
max tokens: 생성된 텍스트의 최대 토큰 수
-
stop token: 종료 토큰 리스트(줄바꿈시 끝내고싶다)
-
top_p: 다음단어 선택시 고려되는 확률분포의 크기를 지정(0~1, 0.8이면 상위 80%의 확률을 가진 token 중 다음단어 선택
-
frequency_penalty: 단어 반복에 대해서 페널티를 주어 반복하지 않게 함
-
presence_penalty: 새 토큰에 대한 출현빈도를 낮추기 위함
-
top-k보다는 top-p
-
system prompt: 룰을 정의하고 질의시 더 높은 품질의 답변 생성. 서비스를 한다면 매우 구체적으로 작성필요
-
function prompt: 함수의 이름과 역할 정의(accumulator, 주어진 값들을 더해서 돌려줍니다, user_content: accumulator(1,3,5))
-
(중요) stream: True로 주면 요청의 결과를 실시간으로. 사용자입장에서 서비스 품질 보장. while:True문을 별도 작성. generator가 도착함
zero-shot
- LLM의 성능 측정의 중요한 지표
- 오직 질의만.
few-shot
- 페르소나 지정
- user-assistant의 대화이력을 프롬프트
- context prompting
컨텍스트(문맥)
- 추가적으로 LLM에 전달하는 데이터(LLM이 참고할만한)
- 질문과 같이 주는 데이터
- 프롬프트의 일부임
프롬프트/Chat completion
- 모델에게 전달하는 전체 데이터
- gpt 3.5는 의미 없음. 더 작은 모델(로컬LLM gemma,sola 10B 등)에 적합
- 원하는 형식을 적어줘도 좋음( Place: <comma_seperated_list_of_names> )
- """는 복수개의 줄을 나타냄
- system: LLM이 작동해야 하는 원칙
- user/assistant 는 !!!chat completion!!!이므로 이 다음에 어떤 답변이 올지. user-assistant-user의 순서이므로 다음은 assistant이다. multi-turn 챗봇을 만드는 기법.
- system만 있다가, 채팅을 할수록 추가되는 것
최초 상태에서 user가 질의하고, 이후 assistant가 답변한 history를 임의로 만들어(의도하는 방향으로) 프롬프트로 전달하는 방식이군요. 중간에 컨텍스트를 추가할 수도 있구요.
실제로 이렇게 답변했는지는 모르지만요.. 불친절한 챗봇 히스토리를 주면서 그 다음 답변을 유도하는 거죠. 일관성을 유지하는 겁니다. few-shot의 예시 죠.
- 주석을 넣어줌
"content":
"""
/*
...에 대한 쿼리를 작성해 줘.
*/
"""LLM은 숫자계산 잘 못함
- function 사용
Copilot
- VS Code에서 다음 코드 생성
개발환경
- open ai는 API call이기 때문에 WSL 위에서 작동하지 않아도 괜찮음
- git for window 정도는 설치해줘야함
- 오히려 GPU가 필요할 때 colab을 사용하는 것이 좋음
RAG
- 사용자 질의 + 질의에서 얻은 추가적인 정보(context) -> 환각을 줄인 답변
- (실습) 1차로 아래 데이터를 분석해줘. 2차로 csv를 user Data로 전달
- LLM이 충분한 파인튜닝이 되있는게 아니므로, 특정 도메인/타스크의 컨텍스트를 주는 것
- 사전 데이터의 개수가 one-shot, few-shot 등: 프롬프트로 설명하기 어려우면 예시를 주는 것
role:"system"
content:"몇글자로..어느정도.."
role:"user"
content: """
-### 문맥: 컨텍스트
-### 질문: 유저질문"""
API
- urllib: get메소드로 REST call(url): 한글이 안되서 깨지지 않도록 인코딩해서 전달
프롬프트 엔지니어링 기법
- COT: Let's think step by step
- few-shot: 이상적인 Input-Knowledge pair을 함께 전달. 마지막은 Input만.
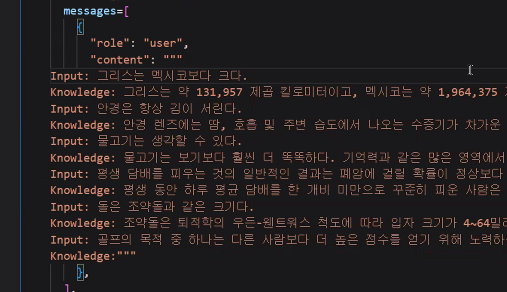
- system prompt로 function을 자연어로 정의해서 사용 가능
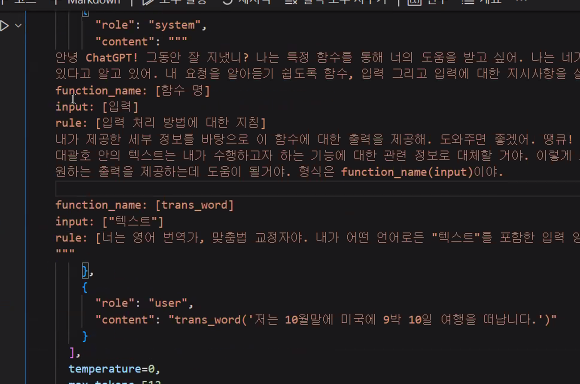
custom 모델을 위한 test set이 필요
function(depricated) -> tool
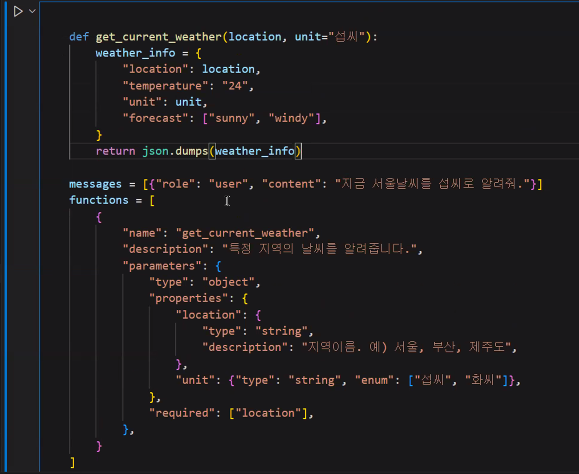
- 자연어가 아닌, 외부의 함수를 사용하고 싶다면
- function은 항상 실행되는 것이 아님
- tool_call_id 를 통해 두 번째 호출을 통해 tool을 사용해 답변생성
- tool_call 은 Auto로, llm에게 일반적으로 일임함
- tool 역시 토큰이다. call할 때 토큰의 양이 많이 늘어날 수 있음.
LLM이 판단해 사전에 정의된 tool을 사용하겠다고 답변이 온 건가요? 그러고 나서 로컬에 정의된 function을 사용한 거죠?
AI는 이렇게 사용해야 성공해요가 없다. 실험/검증해야함.
Gradio
- 통상 as gr
- 내부 데모 또는 대쉬보드 구현에 용이
- huggingface/spaces 샘플 많음
- Gradio
- Interface 모듈의 세 개 파라미터(함수/input/output) -> 여러개면 block
- ChatBot Interface: chat history까지 관리해줌 -> chatbot에 활용
- 바로 여기에서 Stream 구현 -> Gradio로 0.05 하드코딩 X,, 파이썬 통해 generation해야함
- 사진/파일 등 업로드 가능
- 생성답변에 대해 좋아요/싫어요도 가능
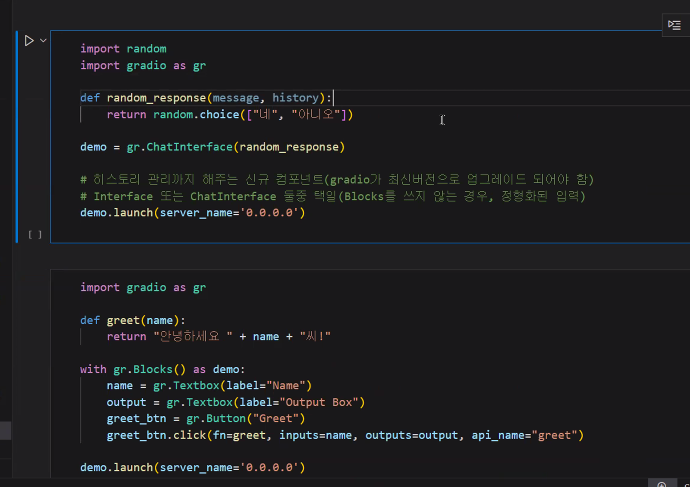
- gradio 명령어로 구동시 소스 변경 자동 반영
- share 옵션으로 외부에서 요청 가능하도록
- stream=True를 어떻게 구현할까?
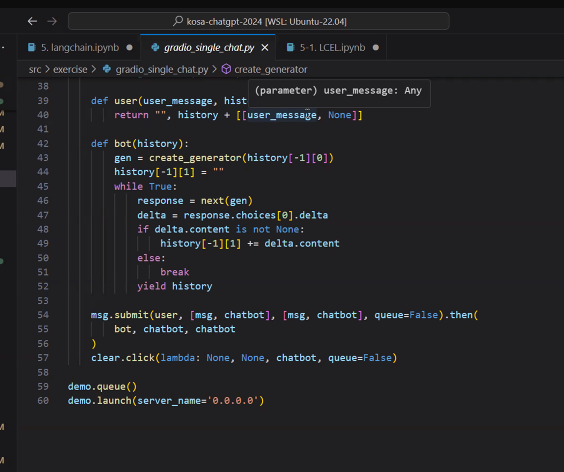
- chatbot인터페이스
- history[-1] <- 마지막 건
Gradio 기본
- function, input, output 으로만 이루어진 작업은 쉬움
- inputs/outputs는 입출력 컴포넌트(복수개 가능)
- user function
[msg, chatbot]이 입력 -> 사용자 발화, history
출력 -> 빈 문자열, history+[[사용자 메시지,None]] - bot function
입력 -> chatbot,
gen = history의 마지막 이력의 0번=직전 사용자 발화
history[-1][1] = placeholder = ""
history[-1][1] += delta.content - queue=False: app에 이벤트 쌓아두지 않음. 앞의 이벤트 해소될 때
- 고 EventHandler가 종료될 때까지 Event를 발생시키지 않음
- yield history
- 파이썬은 멀티스레드가 아니라, 하나가 끝나야 다음 작업 가능
- 이번 질문에 대해 사용자질문에 generation중인데, 언어때문에 멀티가 안되니까 프로그램의 제어권을 넘긴다. (그 전까지 통제권을 잡고있다가)
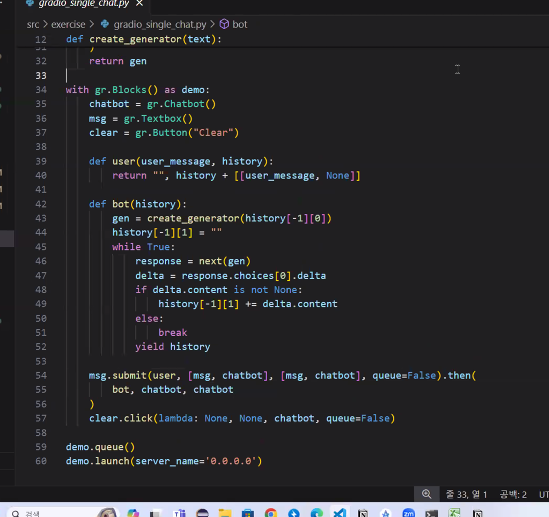
multi-turn App
- 일반적으로 single-turn은 사용되지 않음
- multi-turn은 few-shot으로 구현됨(앞에 이런 대화가 있었어)
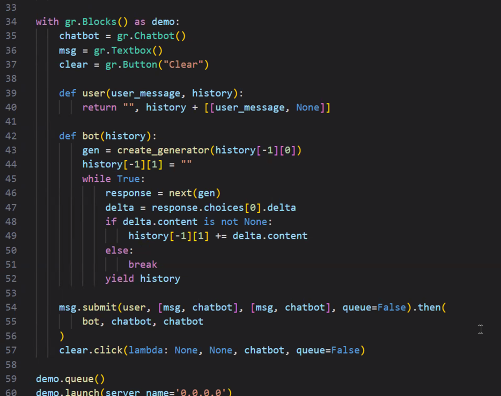
- create_generator의 파라미터를 history를 전체 전달! single은 [-1:1]
- create_generator 함수도 변경: chat_logs=[] <- 일종의 few_shot
git
- git add, git commit, git pull, git push
langchain
-
언어모델을 기반으로 한 APP개발하기 위한 오픈소스 프레임워크
-
LLM에 컨텍스트를 전달할 때, 실제로 서비스를 한다면 훨씬 많은 데이터가 필요(pdf 문서 등)
-
따라서 pdf 문서 등 자료를 변환해야 함
-
코드를 짤 수도 있으나, langchain을 이용하는 것이 편함
-
언어모델을 가지고 여러 어플리케이션을 만들기 위한 도구를 합친 프레임워크
-
툴, 프롬프트로도 구현할 수 있는데 굳이 이걸 써야 하는가?
-
결국 프롬프트의 덩어리
-
prompt format -> local LLM에서 자주 사용됨: HuggingFace/mistral/File and versions -> tokenizer_config.json
-
openai 사용하는게 클라우드처럼 될 것임
-
여러 모델에 endpoint을 두고 상황에 따라 돌려쓸수 있도록(성능 이슈). 그래서 langchain을 써서 범용성 확보
-
한번에 원하는것 못 얻어...서 사용
-
하나의 모델에 lock-in되지 않음
-
사실 RAG때문에 씀.
-
주석에 참고URL 넣어놓는거 좋은듯
-
웹페이지 통째로 load 가능
-
LCEL: Streaming지원
strea:입력에 대해 청크 스트리밍
invoke: 입력에 대해 체인을 한번에 호출하는 기본적인 방법
batch:입력목록에 대해 체인을 배치로 호출(['아이스크림', '피자']
- 문학작품: RAG최악. 애매하고 중복단어가 많음
Chunking
- chunk_size: 1000글자 단위로 자른다
- 문장을 정교하게 안 자르면, 앞뒤 짤릴수도.
- 그래서 overlap 옵션으로 적절히 겹치게 해서 앞뒤 모두 쓸 수 있도록
- 34개의 chunk
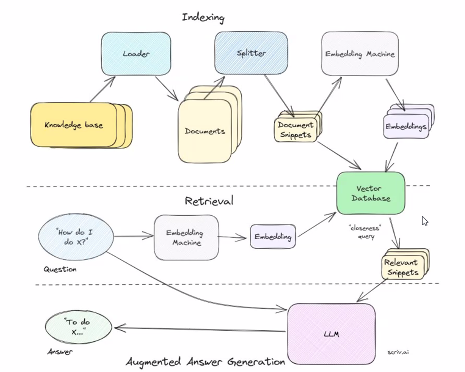
- 문서 splitter -> chunk 생성 -> embedding -> 어떠한 차원의 벡터 -> db 적재
- 질문도 embedding -> 어떠한 차원의 벡터 -> 유사도검색으로 거리가 가까운 것을 구함 -> 사용자 질문의 벡터와 비슷한 벡터가 가리키는 chunk 구함 -> 사용자가 원하는 답을 가지고 있을 것이다 -> chunk를 프롬프트화 해서 유저질문과 같이 LLM에 전달
- 허깅페이스 embedding 사용해도 좋다. 가벼워서 CPU에서도 돌아감.
아래사진이 전부 설명해준다. Indexing, Retrival.
agent
- 지금까지는 단순히 사용자의 질문에 답하는 것
- agent는 주어진 도구를 이용해 스스로 프롬프트를 만들고 추론하며 목표를 달성앟고자 노력. 실제 사람의 작업의 일부 또는 전부를 수행하도록
- ReAct(Reason+Act): 추론,결과가지고 생각, 답을 알 때까지 반복
