huggingface_hub/snapshot_download 메소드로 사전에 fine-tuning해 huggingface에 push된 내 모델을 다운로드받고
- 1번: llama-cpp/convert-hf-to-gguf.py 프로그램을 통해 gguf 포맷으로 변환 / api call 또는 curl을 통해 inference
- 2번: huggingface 리포지토리를 통해 llama-cpp 서버를 띄워 requests 패키지로 통신
위 두 가지 방법을 시도 예정
결과적으로, 아래의 절차로 서버 구동
- snapshot_download로
safetensors등 ec2 인스턴스에 다운로드 - llama-cpp 레포지토리의 convert-hf-to-gguf.py 프로그램을 통해 gguf 포맷으로 변환
8비트 양자화 - brew를 통해 설치한 llama-cpp의 cli로 바로 inference
- llama-cpp의 llama-server 명령어로 http 서버를 8080포트에 구동
- curl/python request패키지로 통신
[Model load/gguf formatting]
from huggingface_hub import snapshot_download
import os
snapshot_download(
repo_id="beomi/gemma-ko-2b",
local_dir="/home/ec2-user/models/",
token=os.environ.get('HF_TOKEN'),
local_dir_use_symlinks=False,
ignore_patterns=["original/*"],
)
인스턴스 유형은 t2 micro로 메모리 1GiB(1024MB) .. 프리티어라 많이 낮다.
우선 llama.cpp 초기화 후 'q8_0'옵션으로 gguf 포맷으로 변환해본다.
- f32: 32비트 부동소수점
- f16: 16비트 부동소수점
- bf16: f16과 유사하지만 더 넓은 범위. TPU에서의 연산
- q8_0: 8비트 양자화 정수. 정확도가 매우 낮음. 주로
모델 압축에 사용
$ git clone https://github.com/ggerganov/llama.cpp.git
$ cd llama.cpp
# 반복적인 빌드를 효율적으로 수행하는 make 도구 .. 여기서 서버가 다운되었다.
$ make -j
$ python convert-hf-to-gguf.py \
/home/ec2-user/models/beomi.gemma-ko-2b \
--outtype q8_0Cannot allocate memory (12) 발생
$ free -h -w메모리 확인해보니 1GB도 없다.
아래의 절차로 스왑파일을 이용해 증설 시도.
$ sudo dd if=/dev/zero of=/swapfile bs=128M count=16
$ sudo chmod 600 /swapfile
$ sudo mkswap /swapfile
$ sudo swapon /swapfile
$ sudo swapon -s
$ sudo vi /etc/fstab
# vi 편집기로 해당 디렉토리 파일에 들어가서 가장 아래 다음 내용을 추가하고 저장한다.
$ /swapfile swap swap defaults 0 0
$ free -h -w그래도 메모리가 부족하다.
그냥 micro에서 다른 유형으로 변경해본다 .. 얼마 과금될지는 모르겠다.
3일간 작업후
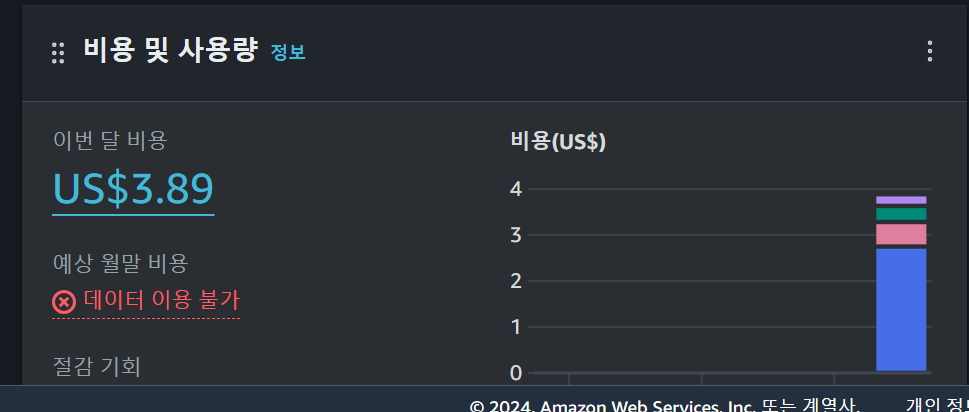
아래 링크를 참조해 t2 medium으로 결정 vCPU=2, RAM=4
INFO:gguf.gguf_writer:/home/ec2-user/models/beomi.gemma-ko-2b/ggml-model-q8_0.gguf: n_tensors = 164, total_size = 2.7G
Writing: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2.66G/2.66G [01:31<00:00, 29.0Mbyte/s]
INFO:hf-to-gguf:Model successfully exported to /home/ec2-user/models/beomi.gemma-ko-2b/ggml-model-q8_0.gguf드디어 완료되었다. 상대적으로 작은 모델로 파인튜닝된 beomi님의 모델로 성공했으니, 인스턴스 바꿔보면서 더 큰 모델을 try 해봐야겠다.
(뻘짓) 폴더 안의 gguf파일로 추론해야한다. 밖의 디렉토리에 생긴 gguf는 하등 쓸모없다 (..)
[brew]
홈브루는 자유-오픈 소스 소프트웨어 패키지 관리 시스템의 하나로서 애플의 macOS 운영 체제의 소프트웨어 설치를 단순하게 만들어준다.
linux에서 홈브루 패키지 관리자를 사용해 llama-cpp 설치
brew는 소스를 다운받아서 컴파일하는 방식으로 동작하므로, 사전에 개발도구를 설치해야 함: ruby git curl file Development Tools
$ sudo passwd root
$ sudo passwd ec2-user
$ sudo yum groupinstall 'Development Tools' && sudo yum install curl file git ruby
$ sh -c "$(curl -fsSL https://raw.githubusercontent.com/Linuxbrew/install/master/install.sh)"
# 초기화 파일에 반영
$ echo 'eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)"') >> /home/ec2-user/.bashrc
$ eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)"
# 초기화 파일 read
$ source ~/.bash_profile
# 정상동작 확인
$ brew install hello
# No space ...
$ export HOMEBREW_TEMP=/var/tmp

이제 brew로 llama.cpp 설치해서, 추론할 것이다.
$ brew install llama.cpp[llama-cpp]
- -m: 모델지정
- -p: 프롬프트
- -n: 생성 토큰 수
$ llama-cli -m ../models/**.gguf -p "드디어 너를 만났구나" -n 128
# Output:
드디어 너를 만났구나너무너무 좋았던 기억들너무너무너무너무너무너무너무너무너무너무너무너무너무너무너무너무너무너무너무너무너무너무너무너무너무너무너무너무너무너무너무너무너무 좋았던 그냥 100만원정도의 혜택을 받을수있는 방법을 알려드릴게요!!가입할때 추천인코드를 입력해주시면 10
llama_print_timings: load time = 42345.53 ms
llama_print_timings: sample time = 25.50 ms / 128 runs ( 0.20 ms per token, 5020.59 tokens per second)
llama_print_timings: prompt eval time = 6062.35 ms / 9 tokens ( 673.59 ms per token, 1.48 tokens per second)
llama_print_timings: eval time = 112512.89 ms / 127 runs ( 885.93 ms per token, 1.13 tokens per second)
llama_print_timings: total time = 118694.37 ms / 136 tokens
Log end
꽤나 기괴한 시퀀스를 생성해준다.
좀더 큰 모델을 로드해서 더 높은 사양으로 포맷팅 해야겠다.
llama-cpp 서버 구동
# http서버 구동, c: size of the prompt context
$ ./llama-server -m models/7B/ggml-model.gguf -c 2048
# curl
$ curl --request POST \
--url http://localhost:8080/completion \
--header "Content-Type: application/json" \
--data '{"prompt": "Building a website can be done in 10 simple steps:","n_predict": 128}'
# Response
{"content":"1. First of all, you need a domain name, like \"mywebsite.com\".2. You need a host, like \"mywebsite.com\".3. You need a web design company to design a website and install it on the host4. You need a hosting company to host your website5. You need a web hosting company to host your website6. You need to know how to use your web hosting company7. You need to know how to use your web browser8. You need to know how to use your web page design software9. You need to know how to use your web page layout software1",
"id_slot":0,
"stop":true,
"model":"ggml-model-q8_0.gguf",
"tokens_predicted":128,
"tokens_evaluated":14,
"generation_settings":{"n_ctx":1024,"n_predict":-1,"model":"ggml-model-q8_0.gguf","seed":4294967295,"temperature":0.800000011920929,"dynatemp_range":0.0,"dynatemp_exponent":1.0,"top_k":40,"top_p":0.949999988079071,"min_p":0.05000000074505806,"tfs_z":1.0,"typical_p":1.0,"repeat_last_n":64,"repeat_penalty":1.0,"presence_penalty":0.0,"frequency_penalty":0.0,"penalty_prompt_tokens":[],"use_penalty_prompt_tokens":false,"mirostat":0,"mirostat_tau":5.0,"mirostat_eta":0.10000000149011612,"penalize_nl":false,"stop":[],"n_keep":0,"n_discard":0,"ignore_eos":false,"stream":false,"logit_bias":[],"n_probs":0,"min_keep":0,"grammar":"","samplers":["top_k","tfs_z","typical_p","top_p","min_p","temperature"]},"prompt":"Building a website can be done in 10 simple steps:","truncated":false,"stopped_eos":false,"stopped_word":false,"stopped_limit":true,"stopping_word":"","tokens_cached":141,"timings":{"prompt_n":14,"prompt_ms":9256.026,"prompt_per_token_ms":661.1447142857143,"prompt_per_second":1.5125281627342015,"predicted_n":128,"predicted_ms":111292.324,"predicted_per_token_ms":869.47128125,"predicted_per_second":1.150124243파이썬의 request 패키지로 try
import gradio as gr
import requests
def llama_cpp_server_call(name):
url = "http://localhost:8080/completions"
headers = {"Content-Type": "application/json"}
prompt = f"Hello, I'm {name}. What is my name?"
data = {
"prompt": prompt,
"max_tokens": 50
}
response = requests.post(url, headers=headers, json=data)
return response.json()
demo = gr.Interface(fn=llama_cpp_server_call, inputs="text", outputs="text")
demo.launch(server_name="0.0.0.0")
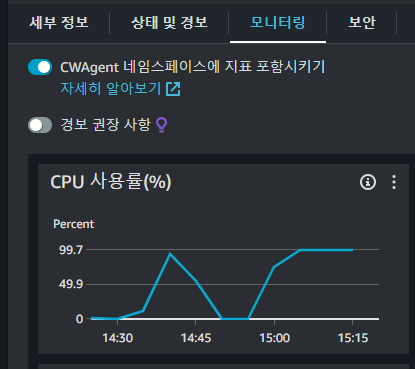
CPU 한계치에 도달했다.
CPU 코어가 증가된 새 인스턴스 유형으로 변경하거나, GPU 인스턴스로 변경하는 것을 고려해 봐야겠다.
이는 docker 배포를 마치고 ..
[URL]
brew package manager
https://www.lesstif.com/lpt/linux-brew-package-manager-54952258.html
llama-cpp gguf
https://dytis.tistory.com/72
https://github.com/Linuxbrew/brew/issues/923
허깅페이스 모델 beomi님
https://huggingface.co/beomi/gemma-ko-2b/tree/main
llama.cpp github
https://github.com/ggerganov/llama.cpp
