[PEFT]
PEFT(Parameter-efficient fine-tuning) 적은 양의 매개변수 학습으로도 새로운 문제를 거의 비슷한 성능으로 해결할 수 있는 파인튜닝 방법론
각각의 도메인 또는 언어에 대한 작은 체크포인트 파일만 로컬로 저장하면 되므로 효율적이며, 사전학습된 LLM 위에 얇은 레이어 층을 추가
[LoRA]
LORA(Low Rank Adaption) 레이어 내에 존재하는 여러 은닉층에 특정 값을 추가해 모델의 출력을 조절하는 파라미터를 통해 모델의 출력값을 원하는 타겟 레이블에 맞게 튜닝
큰 행렬을 근사화하는 두 개의 작은 행렬을 미세 조정
[Quantization]
양자화(Quantization] 언어모델의 매개변수를 실수형 변수에서 정수형 변수로 변환하는 과정을 통해 더 작은 비트로 변환하는 과정을 거쳐 실제 사이즈보다 작은 모델로 로드
[고려사항]
- 학습에 필요한 GPU와 시간을 줄여줌
- 성능에 대한 고려 필요
- 실험에 의해 최적 양자화 파라미터와 사용 방법론을 결정해야함
- 도메인에 따라 PEFT가 아닌 전체 파라미터 학습이 필요할 수 있음. 엔지니어의 역량
[실험]
물리학에서 양자화(quantization)는 특정 물리적 속성(예: 에너지 수준, 전자의 위치 등)이 연속적이지 않고 이산적(discrete)이라는 것을 의미합니다.
컴퓨터 과학에서 양자화(quantization)는 연속적인 값(보통은 부동 소수점 수)을 이산적인 값(정수)으로 변환하는 과정입니다.
언어모델의 매개변수는 통상 32바이트 부동소수점입니다. 이를 N바이트 정수로 변환하는 과정을 통해 실제 사이즈보다 작은 모델로 로드합니다.
당연히 정보손실이 발생합니다. 메모리와 컴퓨팅 자원에 있어서 굉장히 빈곤하기(...) 때문에 사용하는 기법이라고 이해됩니다.
실험을 통해 이를 확인해보고자 했습니다.
input = """
1호선에서 9호선으로 갈아타고 다시 4호선으로 환승하면 뱅크웨어글로벌에 출근할 수 있어.
이 때 지하철을 몇 번 갈아탔을까?
"""16비트 양자화 모델
1호선에서 9호선으로 갈아타고 다시 4호선으로 환승하면 5번 지하철을 갈아타야 합니다.
16비트 모델 추론 시간: 372.8378초
8비트 양자화 모델
1호선에서 9호선으로 갈아타고 다시 4호선으로 환승하면 3번 지하철을 갈아타야 합니다.
8비트 모델 추론 시간: 9.0137초
4비트 양자화 모델
1호선에서 9호선으로 갈아타고 다시 4호선으로 환승하면 뱅크웨어글로벌에 출근할 수 있는 지하철 회선은 3번입니다.
4비트 모델 추론 시간: 2.5397초
[실험 스펙]
| 구분 | 내용 |
|---|---|
| 환경 | Google Colab |
| 모델 | google/gemma-2b-it |
| GPU | T4(15GB) |
| 사용 VRAM | 약 50GB |
[모델별 크기 비교]
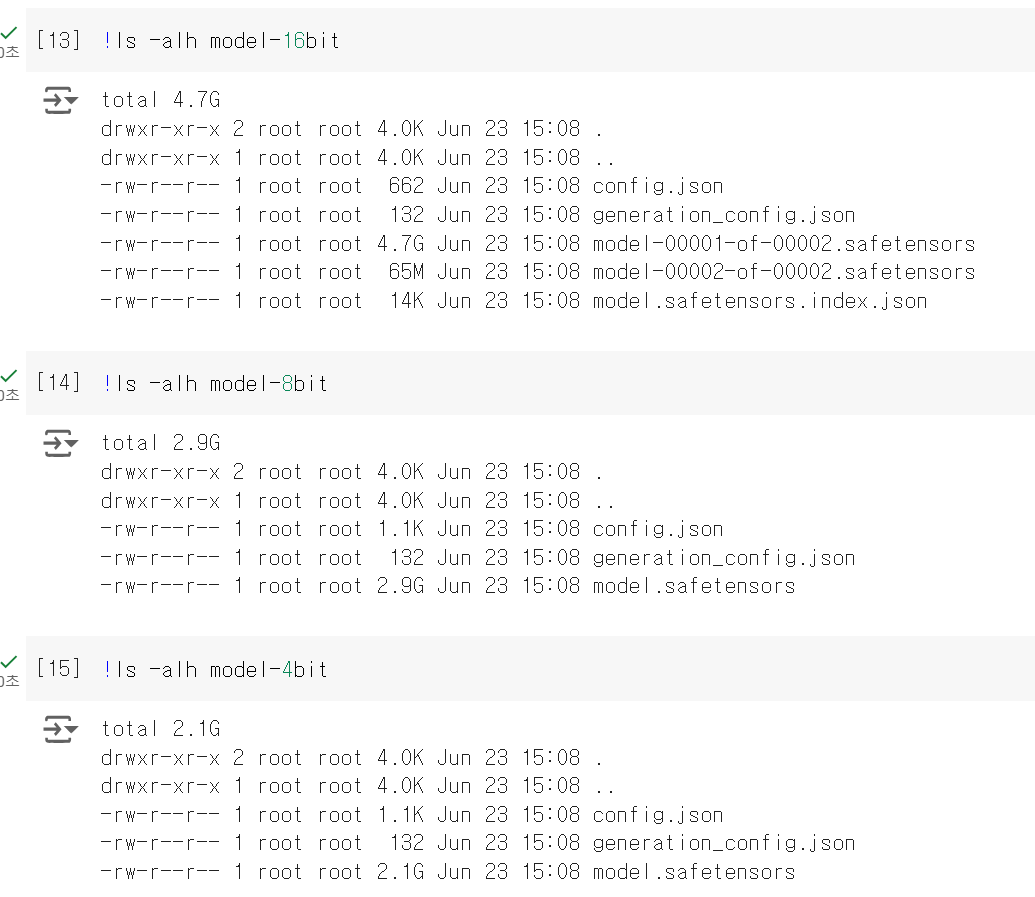
[결론]
애초에 2B모델을 사용했기 때문에 16비트에서도 좋은 성능은 기대하기 힘듭니다.
4비트 모델이 가장 좋은 답변을 만들어 준 것은 기분탓일까요 ..
다만 파일 크기가 약 1.5배 축소되었고, 추론 시간에서는 40배 이상 차이가 발생합니다. 16비트와 8비트의 답변이 거의 유사한 것을 생각하면, 서비스에 있어 추론 시간을 줄이는 것은 큰 어드밴티지가 아닐까 합니다. 실제로 우리는 유저로서 AI 서비스에 대해 1분 이상 기다리지 못합니다.
양자화로 모델을 로드해도 거의 동일한 성능을 낼 수 있다는 연구결과가 많습니다. LLM의 크기는 갈수록 거대해지고, 운용하는 환경이 제한적인 만큼 양자화와 파인튜닝에 있어 여러 실험을 통해 우리 타스크에 최적화된 모델을 만드는 것이 중요해질 것 같습니다.
