[Self-Attention]
입력 시퀀스 내에서 각 단어가 다른 단어와 얼마나 관련되어 있는지를 계산하는 메커니즘
-
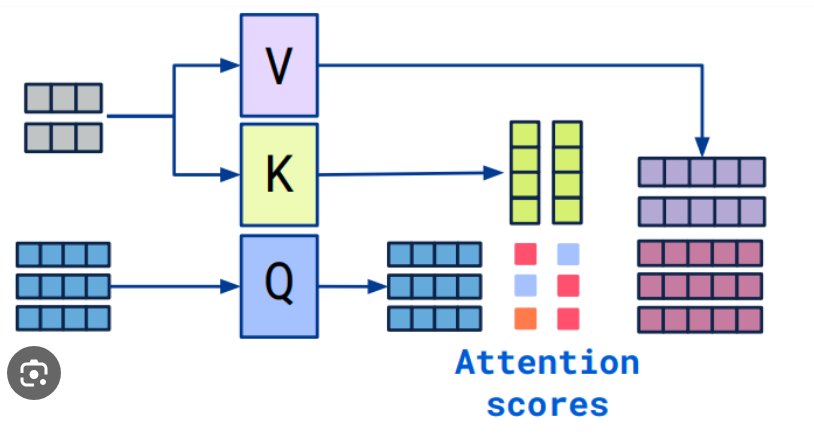
주어진 쿼리(시퀀스의 특정 시점 t에서의 임베딩 값)에 대해 모든 키(시퀀스의 모든 시점에서의 임베딩 값)와의 유사도를 계산
-
이 유사도를 기반으로 각 키의 가중합(단어가 임베딩된 값에 더해 문장 내에서의 Attention을 반영한 더 좋은 representation)을 계산
-
Weighted Sum을 통해 모델은 입력의 각 부분에 대한 정보를 포괄적으로 고려 가능
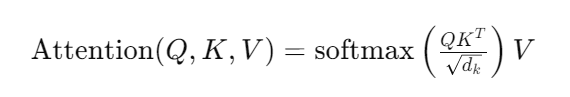
-
Q, K, V는 각각 쿼리(Query), 키(Key), 밸류(Value) 행렬
-
softmax 함수를 통해 각 행의 합이 1이 되도록 Attention Score -> Attention Distribution 변환
