단순 코드 백업용. 예측과 실제 값이 정반대로 나온 실패 케이스
2차원?
학습시간, 수면시간에 따른 시험점수의 값을 예측
모델을 만들고 학습시킨 뒤, 그래프로 표시 하려함.
그래프가 정반대로 나와 실패.
코드 백업용
import numpy as np
import pandas as pd
# 회귀 모델 만들기에 사용
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 그래프 그리는데 사용
import matplotlib.pyplot as plt
import matplotlib
# 데이터셋 (딕셔너리 형태)
data = [
{'학습시간': 2, '수면시간': 6, '시험점수': 65},
{'학습시간': 3, '수면시간': 7, '시험점수': 75},
{'학습시간': 4, '수면시간': 6, '시험점수': 85},
{'학습시간': 5, '수면시간': 8, '시험점수': 95},
{'학습시간': 6, '수면시간': 7, '시험점수': 100}
]
# 데이터에서 X와 y 추출하기
X = np.array([[d['학습시간'], d['수면시간']] for d in data])
y = np.array([d['시험점수'] for d in data])
# 모델 구성 - 은닉층2개(64, 32), 출력층 1개개
model = Sequential()
# input_dim = 1 > 1차원데이터/ input_dim = 2 > 2차원 데이터
model.add(Dense(64, input_dim=2, activation='relu')) # 은닉층
model.add(Dense(32, activation='relu')) # 은닉층
model.add(Dense(1, activation='linear')) # 출력층 (회귀이므로 선형 활성화 함수)
# 모델 컴파일
# loss='mean_squared_error'을 사용해 예층값과 실제값 간 차이를 최소화
# 최적화 알고리즘으로는 adan을 사용함
model.compile(loss='mean_squared_error', optimizer='adam')
# 모델 훈련
# epochs=200 훈련을 200번 반복함
# verbose가 0인 경우 훈련 상태가 출력되지 않음
# verbose가 1인 경우 훈련 상태가 출력됨
# verbose가 2인 경우 더 많은 정보를 출력하며, 세부적인 로그가 표시됨
model.fit(X, y, epochs=200, verbose=1)
# 사용자 예측
# 딕셔너리 형태로 입력 데이터를 정의
input_data_dict = [
{'학습시간': 4, '수면시간': 7}, # 첫 번째 입력
{'학습시간': 5, '수면시간': 6} # 두 번째 입력
]
input_data = np.array([[d['학습시간'], d['수면시간']] for d in input_data_dict])
predictions = model.predict(input_data).flatten() # 예측 값
# 예측 결과와 실제값을 pandas DataFrame으로 출력
df = pd.DataFrame({
'입력 (학습 시간, 수면 시간)': [[4, 7], [5, 6]],
'예측된 시험 점수': predictions.tolist()
})
print(df)
# 예측 결과
predictions = model.predict(np.array([[4, 7], [5, 6]]))
# 실제 값과 예측 값을 그래프에 표시
plt.scatter([d['학습시간'] for d in data], y, color='blue', label='Actual') # 실제 값
plt.scatter(input_data[:, 0], predictions, color='red', label='Predicted') # 예측 값
# 한글 폰트 설정 (예: 나눔고딕)
# matplotlib.rcParams['font.family'] = 'NanumGothic'
# 그래프 제목과 레이블 추가
plt.title("시험 점수 예측")
plt.xlabel("학습 시간 (시간)")
plt.ylabel("시험 점수 (점수)")
plt.legend() # 그래프레 범례 추가 (빨간값이 뭔지, 파란값이 뭔지 알려주는거)
# 그래프 표시
plt.show()
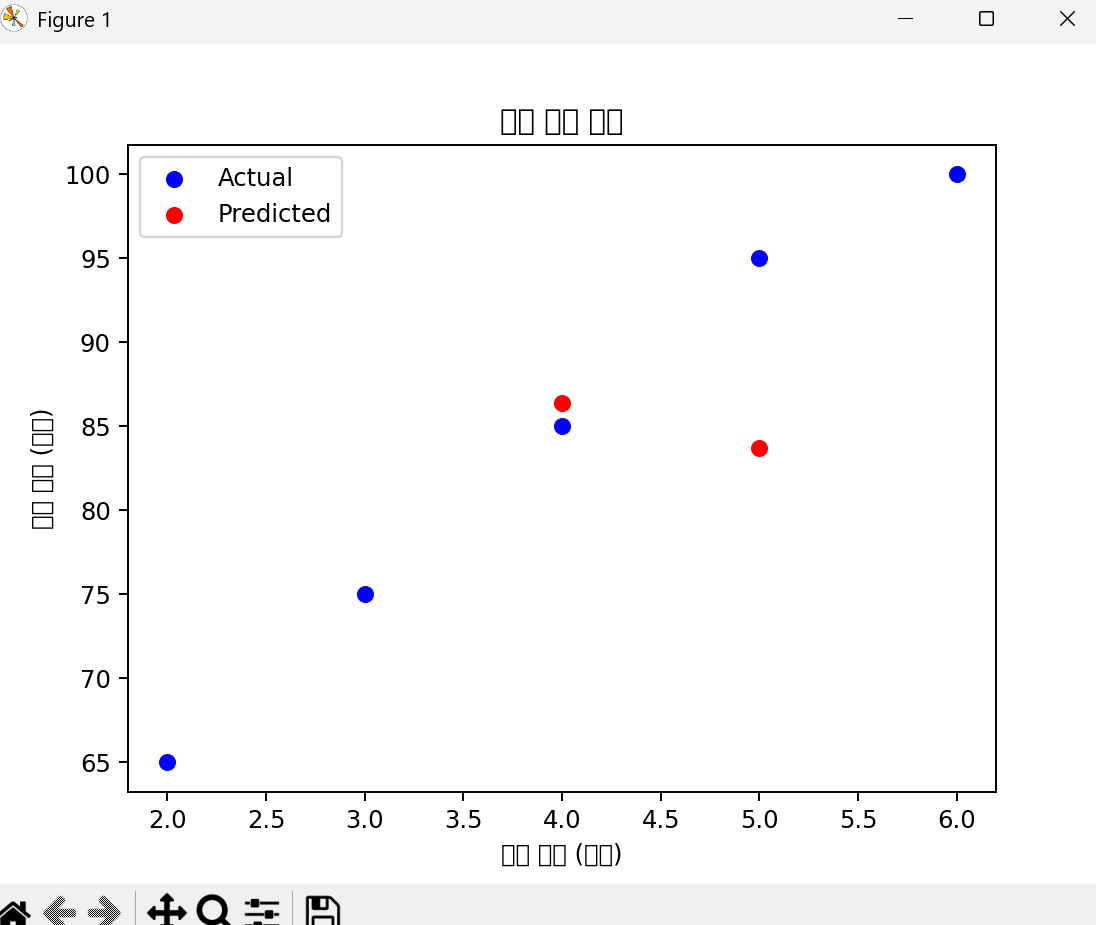
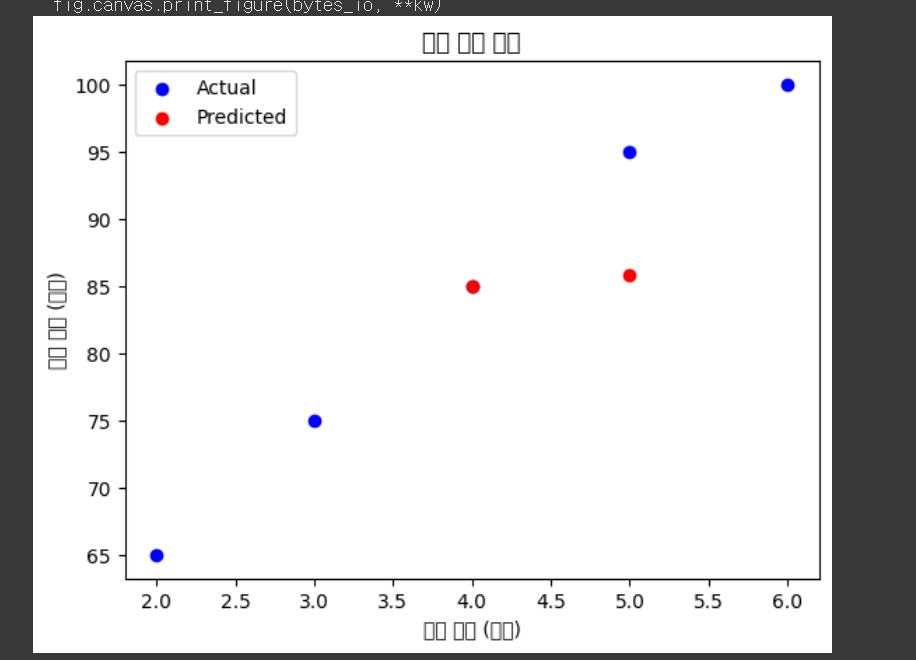
++)2000번 학습시켰더니 조금... 비슷해졌나
1차원?
import numpy as np
import pandas as pd
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import matplotlib.pyplot as plt
import matplotlib
# python -m venv myenv # 가상 환경 생성
# Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser
# myenv\Scripts\activate # 가상 환경 활성화 (Windows)
# setData
data = [
{"car_speed": 20, "fuel": 80},
{"car_speed": 40, "fuel": 75},
{"car_speed": 60, "fuel": 70},
{"car_speed": 80, "fuel": 65},
{"car_speed": 100, "fuel": 60},
{"car_speed": 120, "fuel": 55},
{"car_speed": 140, "fuel": 50},
{"car_speed": 160, "fuel": 45},
{"car_speed": 180, "fuel": 40},
{"car_speed": 200, "fuel": 35},
]
# 1차원 데이터를 2차원 데이터로 수정 > reshape(-1, 1)
x = np.array([d['car_speed'] for d in data]).reshape(-1, 1)
y = np.array([d['fuel'] for d in data])
# create mode
model = Sequential()
# 1차원 데이터라서 input_dim을 1로 수정
model.add(Dense(64, input_dim=1, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='linear'))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(x, y, epochs=500, verbose=1)
loss = model.evaluate(x, y)
print(f"모델의 손실값: {loss}")
# 값 리스트로 확인하기
input_data = []
for i in range(3, 20) :
input_data.append(i*5)
input_data = np.array(input_data).reshape(-1, 1) # 2D 배열로 변환
print('input_data:', input_data)
# 값 예측
predictions = model.predict(input_data).flatten()
predictions = -predictions
df = pd.DataFrame({
'입력 : ' : input_data.flatten(),
'예측된 연료 값' : predictions.tolist()
})
print('df : ', df)
pred_result = model.predict(input_data)
# 그래프 그리기
plt.scatter([d['car_speed'] for d in data], y, color='#000', label='Actual')
plt.scatter(input_data.flatten(), pred_result.flatten(), color='#ddd', label='Predicted')
plt.title('Fuel Consumption Prediction')
plt.xlabel('Car Speed')
plt.ylabel('Fuel Consumption')
plt.legend()
plt.show()
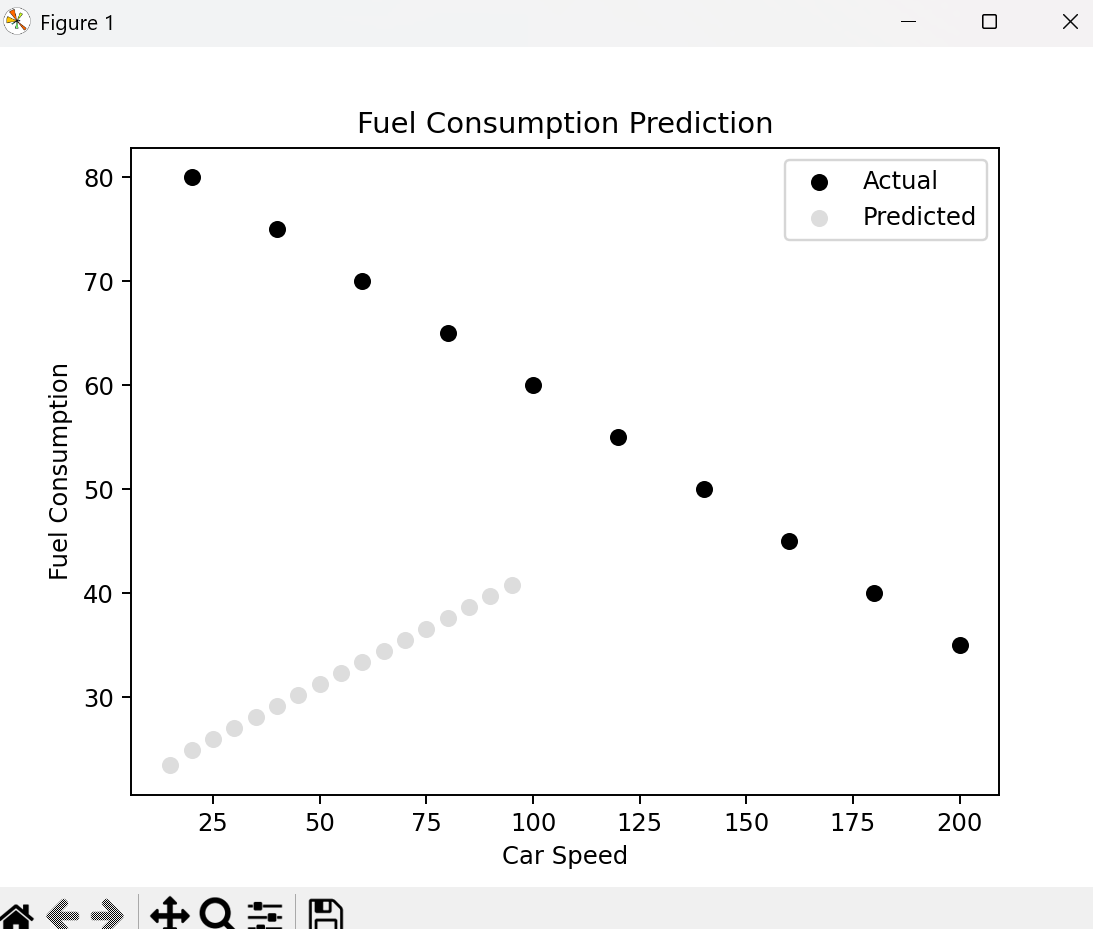
결과값 진짜 반대로 나옴...왜지 진짜
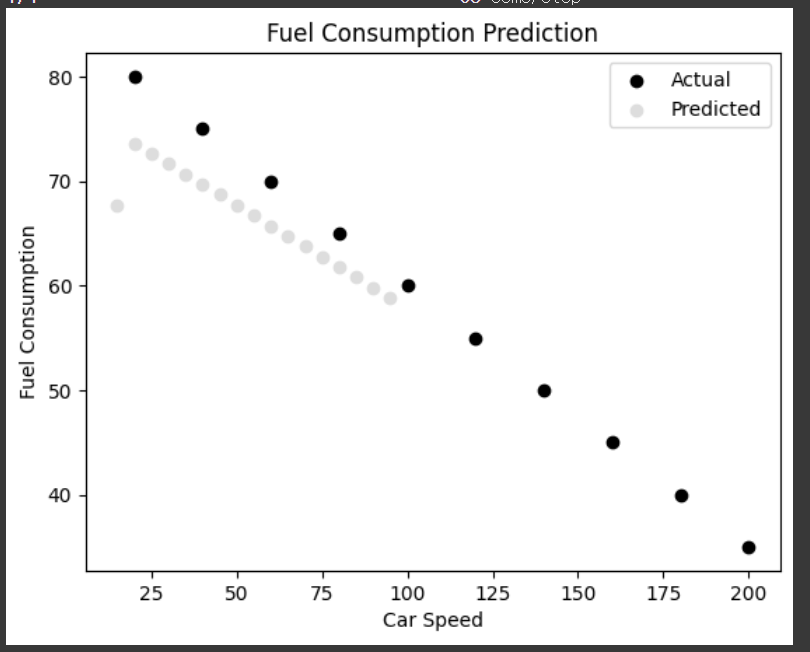
++) Colab에서 1000번 학습시키니 괜찮게 나옴

개인 공부 기록용.