1. 시리즈 연산
같은 인덱스를 갖는 데이터끼리 연산을 수행함
1-1. 덧셈
from pandas import Series
x = Series([10, 20, 30], index=['A', 'B', 'C'])
y = Series([11, 22, 33], index=['B', 'C', 'A'])
z = x + y
print('z : \n', z)
1-2. 곱셈
print('x * 10 : \n', x * 10)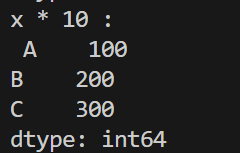
1-3. 뺄셈
high = Series([10, 20, 30, 40, 50])
low = Series([1, 2, 3, 4, 5])
res = high - low
print('res : \n', res)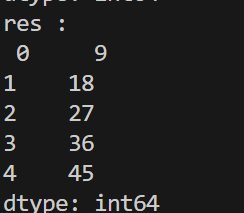
1-4. 최대값 찾기 - 반복문 사용
max_val = 0
max_idx = 0
for i in range(len(res)) :
if res[i] > max_val :
max_val = res[i]
max_idx = i
print('max_idx : ', max_idx)
print('max_val : ', max_val)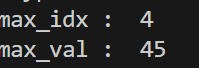
1-5. 최대값, 최소값의 index 찾기 - idxmax, idxmin 메서드 사용
print('res.idxmax() : ', res.idxmax())
print('res.idxmin() : ', res.idxmin())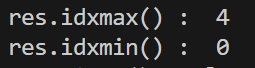
1-6. 시리즈 value의 중복값 제거하기
data1 = {
'red' : 'a',
'green' : 'a',
'blue' : 'b',
'purple' : 'c',
'yellow' : 'c'
}
s1 = Series(data1)
print('s1.unique() : ', s1.unique())
1-7. 시리즈의 중복되는 값이 몇 개 있는지 세어보기
print('s1.value_counts() : \n', s1.value_counts())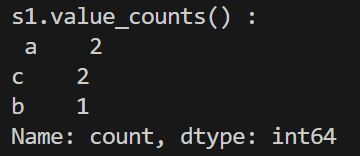
2. 시리즈와 Map
s2 = Series(["1,234", "5,678", "9,012"])
def remove_comma(x) :
print(x, 'in function')
return int(x.replace(",", ""))
result2 = s2.map(remove_comma)
print('result2 : \n', result2)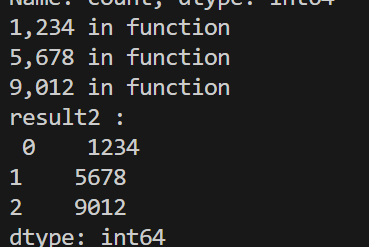
3. 시리즈 필터링
3-1. 값 비교 후 조건에 맞는지 boolean값으로 받기
data3 = [10, 20, 30, 40, 50]
index3 = ['a', 'b', 'c', 'd', 'e']
s3 = Series(data = data3, index = index3)
cond3 = s3 > 30
print('cond3 : \n', cond3)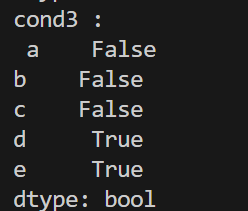
3-2. 조건에 맞는 값만 출력하기
data4 = [11, 19, 31, 39, 51]
s4 = Series(data=data4, index=index3)
# s4값이 더 커서 true인경우에만 출력
print('s4[cond4] : \n', s4[s4 > s3])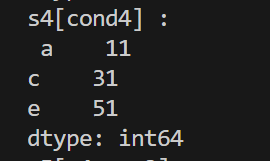
3-3. 필터 두개 걸기
s5 = s4-s3
print('s5[s4 > s3] : \n', s5[s4 > s3])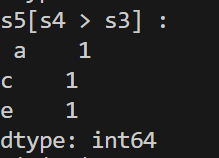
4. 정렬
data5 = [31, 41, 59, 26]
index5 = ['a', 'b', 'c', 'd']
s6 = Series(data=data5, index=index5)
print('정렬 전 s6 : \n', s6)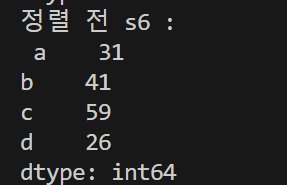
4-1. 오름차순 정렬
s7 = s6.sort_values()
print('오름차수 정렬 후 s7 : \n', s7)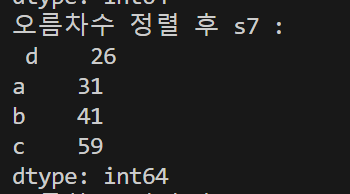
4-2. 내림차순 정렬
s8 = s6.sort_values(ascending=False)
print('오름차수 정렬 후 s8 : \n', s8)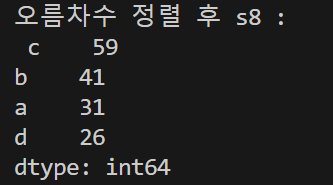

개인 공부 기록용.