TMI
우리 팀은 당장 한달, 늦으면 두달 안에 실전에서 코드를 읽고 적용해야 하는 입장이라서 기존에 진행하던 딥러닝 스터디의 진행 방법과 도서를 수정했다. 기존에 선정했던 책이 이론 위주, 수식 위주였다면 이번에 고른 <머신 러닝 교과서 with 파이썬>은 조금 더 실습이 많다. 진행 방법은 일주일에 두 챕터씩 각자 강의를 듣고 블로그에 내용을 포스팅 하기로 했음. 그리고 추가 학습은 Github Issue를 활용하기로 했다. 레포지토리를 하나 파서 1주일에 무조건 질문 하나와 답변 하나를 Issue에 작성하기로! 사실 깃헙 사용해서 1년 내내 프로젝트 하면서도 Issue 항목은 사용 안했어서 그 나름대로 익숙해지는데에도 의미가 있을 것 같다.
활발한 참여를 위해 금주의 답변왕도 선정하기루 함. ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ 보상은? 명예 그 자체^_^,, 4명끼리 잘노네
1장은 오버뷰에 가까워서 간단하게 작성하고 끝내겠음
머신 러닝 교과서 with 파이썬 1장
머신러닝
(알고 있겠지만) 집합관계로 따지면 인공지능>머신러닝>딥러닝 순서다.
그리고 머신러닝의 종류에는 지도학습(Supervised Learning)과 비지도학습(Unsupervised Learning), 그리고 강화학습(Reinforcement Learning)으로 세가지가 있다.
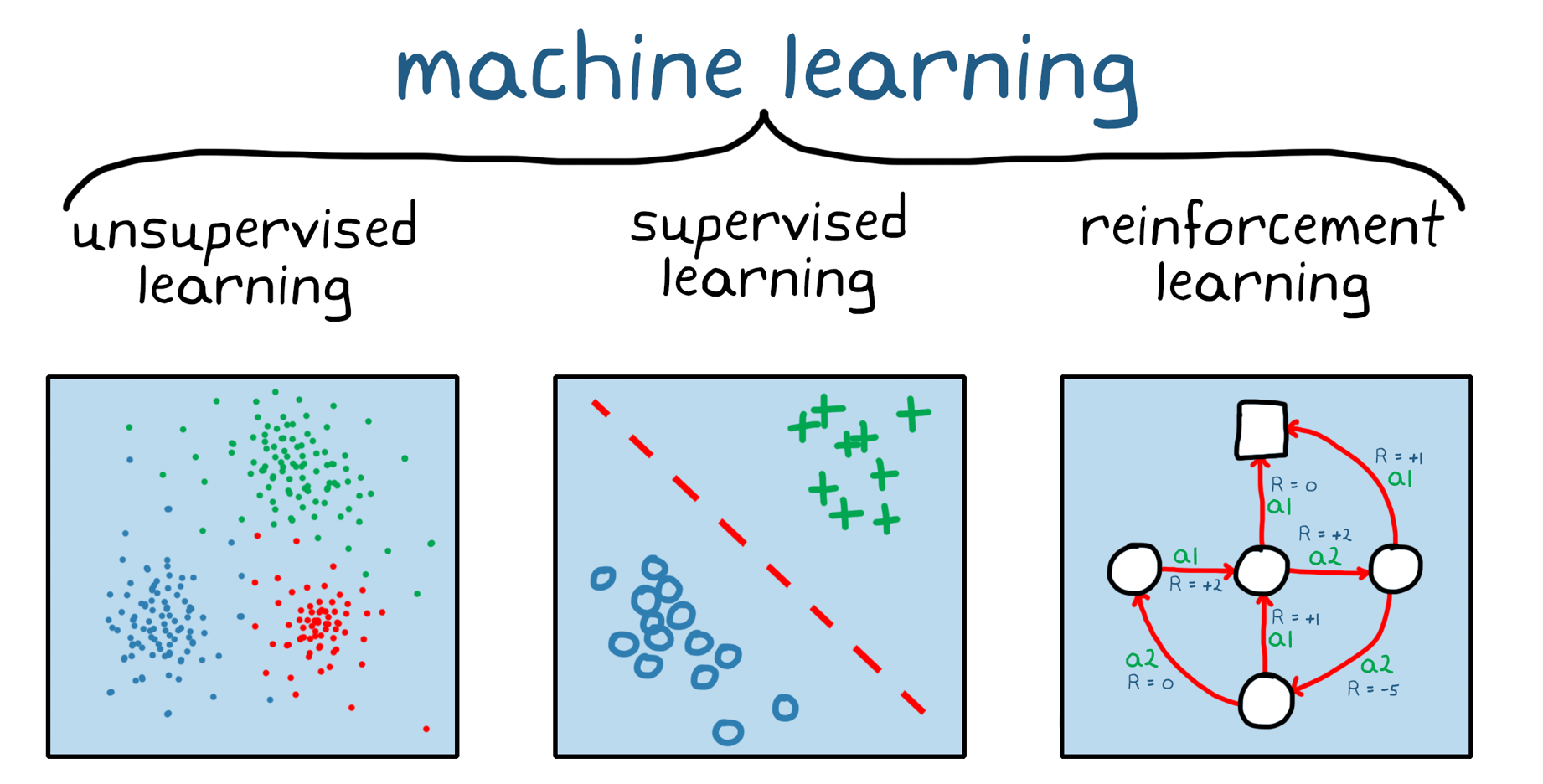
셋의 특징이 한눈에 들어오는 그림을 가져왔다.
지도학습은 입력값과 레이블 데이터가 존재한다. 쉽게 말해 정답이 있는 데이터를 학습 시키는 방식.
반면에 비지도학습은 레이블 데이터가 없다. 때문에 라벨링 되어 있지 않은 입력 데이터에서 패턴이나 형태를 찾아내 비슷한 데이터끼리 클러스터링 즉 군집화 한다. 최근에 각광받고 있는 (그리고 우리 팀을 아주 괴롭혔던,,) GAN 알고리즘도 비지도학습에 해당한다. 강화학습 역시 라벨링 되어 있지 않은 데이터를 학습시킨다. 강화학습의 원리는 아래 그림이 더 이해하기가 쉽다. '보상' 이 존재하는 점이 가장 큰 특징이다. (그래서 그런가 강화학습은 강아지 훈련에 빗대어 설명하는 경우가 굉장히 많더라 ㅋㅋㅋㅋㅋ 뜬금없이 귀여움...)
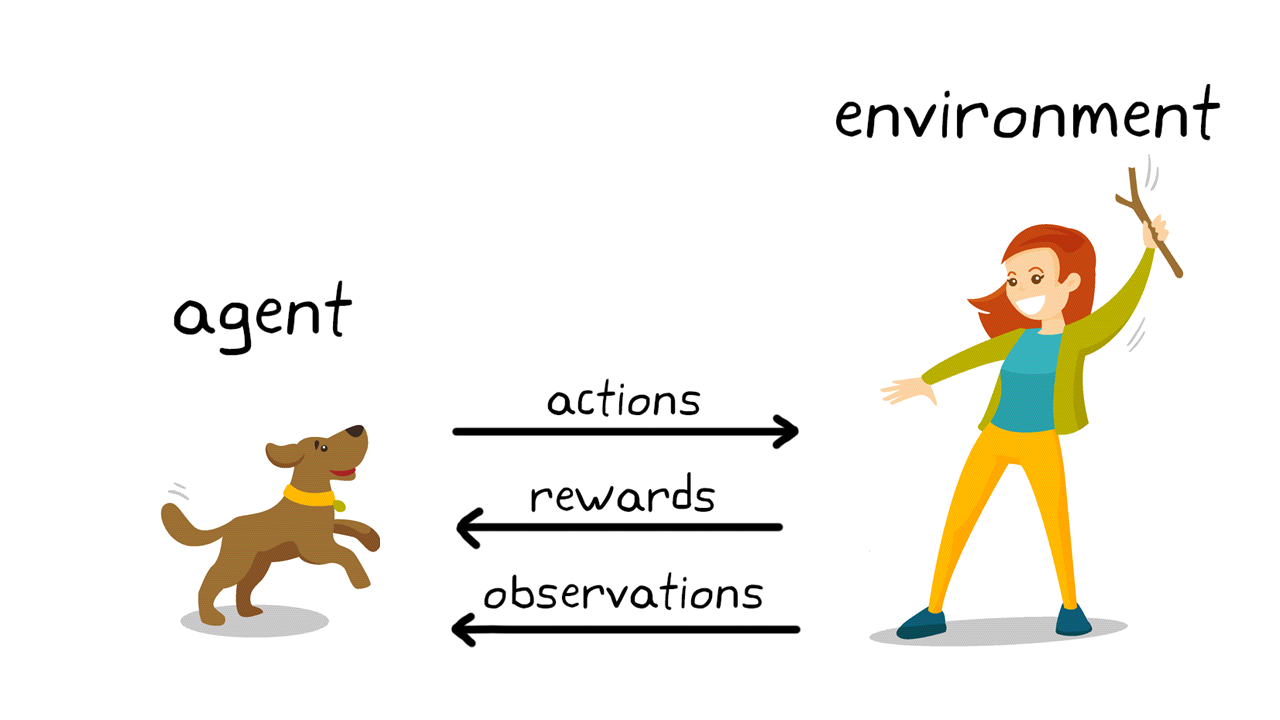
지도학습
지도학습의 종류에는 두가지가 있다.
- 분류 : 말그대로 데이터를 분류..
이진 분류(binary classification)와 다중 분류(multiclass classification)가 있겠다. 이진 분류일 때는 두 분류의 데이터를 양성 클래스(positive class)와 음성 클래스 (negative class) 로 부르기도 한다.
당연한 소리지만 수학적인 플러스 마이너스가 아닌 단지 구분을 위한 명칭이다. 데이터 분석 할 때 직관적으로 남성은 0 여성은 1로 정수화 라벨링 하는 것 처럼.. 두 데이터를 구분하는 기준 선은 '결정 경계' 라고 부른다.
- 회귀 : 임의의 실수 값을 예측
예측 변수(특성)와 반응 변수(타깃)가 존재한다. 회귀 모델이 나왔다고 해서 반가워 하기에는 통계학의 세부 수업 안에서도 기본 회귀 모델을 이리 변형하고 저리 변형한 모델이 이미 너무 많았다. 모르는데서 마주쳤다고 반가워 하기에는 너무 많이 본거지 우리..


즐거운 스터디 같네요~ 다음 글 기대할게요~^^