개념 로드맵
참고자료
개요
Upper bound 와 Lower bound 를 이해하기 위해서는 Binary Search에 대한 개념을 반드시 알아야합니다!
정렬되어 있는 수열에서 어떤 수 K를 추가하려고 할 때 유용하게 사용됩니다.
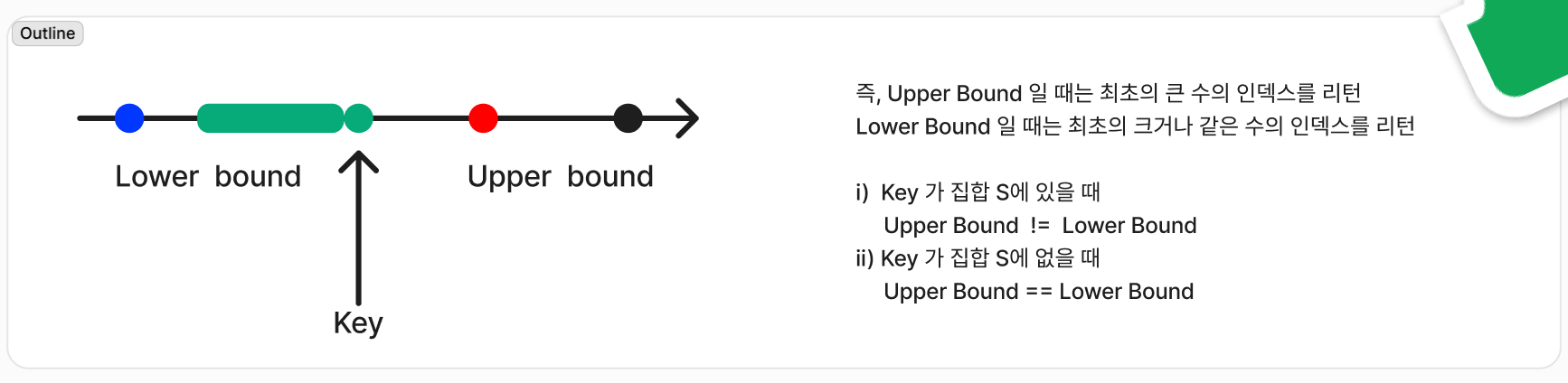
단순하게 생각하면 Upper bound, Lower bound는 추가되는 위치를 찾을 때 원하는 위치를 조정하기 위한 개념입니다.
즉, 수열에서 정렬을 유지하여 숫자를 추가하려고 할 때 어느 위치에 추가할지 결정하는데 사용합니다.
- 정렬을 유지하면서 K를 넣을때, 내가 원하는 위치는 어떤 것이 있을까?
1. 최초의 K<S[i] 인 i를 찾고 싶다.
2. 최초의 K==S[i] 인 i를 찾고 싶다.
3. 최초의 K>S[i] 인 i를 찾고 싶다. => 이 케이스는 정렬을 유지하지 못한다.
즉, 두 가지 케이스만 존재한다! 이 두 가지 케이스에서 K가 들어가는 위치가 같을 수도 있고 다를 수도 있다. 이 이유는 밑에서 그림과 함께 설명한다.
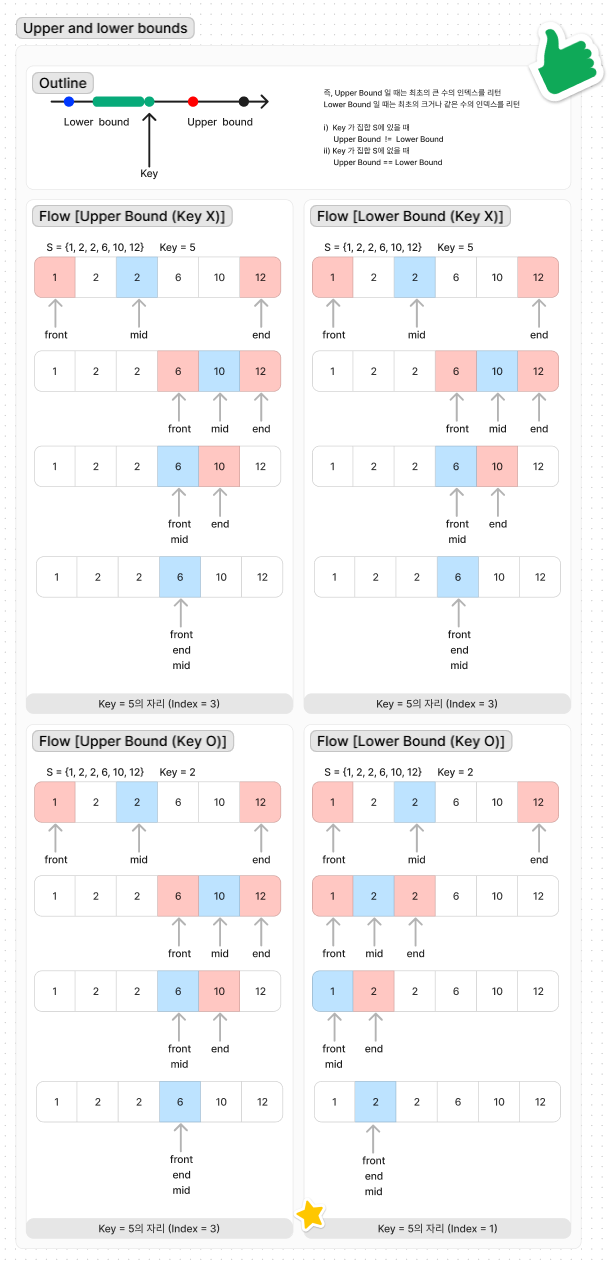
Upper Bound, Lower Bound 예시
// key 보다 큰 첫번째 위치 반환
int UpperBound(int front, int end, int key, int arr[]) {
while (front < end) {
int mid = (front+end)/2;
if (arr[mid] <= key)
front = mid + 1;
else
end = mid;
}
return end;
}//key 보다 크거나 같은 첫번째 위치 반환
int LowerBound(int front, int end, int key, int arr[]) {
while (front < end) {
int mid = (front+end)/2;
if (arr[mid] < key)
front = mid + 1;
else
end = mid;
}
return end;
}두 코드의 차이점은 if문에서 등호가 있냐 없냐의 차이 뿐이다.
위에서 말했던 두 가지 케이스를 정확히 구현한 것이다.
첫 번째 케이스는 Upper Bound를 의미하고, 두 번째 케이스는 Lower Bound를 의미하는 것이다.(두 번째 케이스의 경우 K==S[i]가 없을 때는 K보다 큰 첫번째 위치를 찾는다.)
이렇게 Binary Search를 직접 구현하여도 좋지만 C++ 등 언어에서 지원하는 함수를 사용하는 것도 좋다.


결국 Upper Bound 와 Lower Bound의 차이는 K가 S 안에 있을 때 달라진다.
결론 : key 값이 정렬을 유지하며 S에 추가할 때 어느 곳에 넣어야 하는지에 따라 Upper bound, Lower Bound를 선택하여 사용하면 됩니다.
