소트 튜닝2
5.3 인덱스를 이용한 소트 연산 생략
인덱스는 항상 키 컬럼 순으로 정렬된 상태를 유지한다.
5.3.1 Sort Order By 생략
- 부분범위 처리를 활용한 튜닝 기법이 3-Tier 환경에서도 유효할까??
- 3-Tier 구조에서 단위 작업을 마치면 DB 커넥션을 바로 커넥션 풀에 반환해야 하므로 그 전에 쿼리 조회 결과를 클라이언트에게 '모두' 전송하고 커서를 닫아야한다.
-> 쿼리 결과 집합을 조금씩 나눠서 전송하는 방식이 불가능 - Top N 쿼리를 사용하면 3-Tier 환경에서도 부분범위 처리가 가능하다.
- 3-Tier 구조에서 단위 작업을 마치면 DB 커넥션을 바로 커넥션 풀에 반환해야 하므로 그 전에 쿼리 조회 결과를 클라이언트에게 '모두' 전송하고 커서를 닫아야한다.
5.3.2 Top N 쿼리
Top N 쿼리는 전체 결과집합 중 상위 N개 레코드만 선택하는 쿼리다.
select * from (
select 거래일시, 체결건수, 체결수량, 거래 대금
from 종목거래
where 종목코드 = 'KR123456'
and 거래일시 >= '20180304'
order by 거래일시
)
where rownum <= 10- 인라인 뷰로 정의한 집합을 모두 읽어 거래일시 순으로 정렬한 중간 집합을 우선 만드고, 거기서 상위 열 개 레코드를 취하는 형태다.
- Top N StopKey 알고리즘
-> [종목코드 + 거래일시]순으로 구성된 인덱스를 사용하면 소트 연산 을 생략하고 인덱스를 스캔하다가 열 개 레코드를 읽는 순간 멈춘다. 
- Top N StopKey 알고리즘
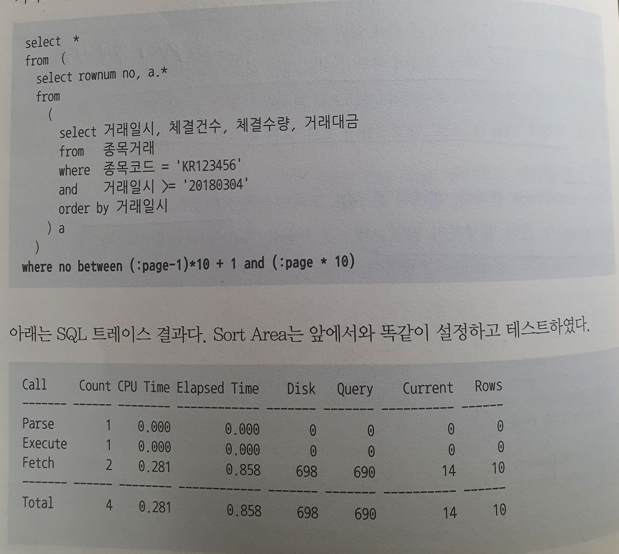
페이징 처리
select *
from (
select rownum no, a.*
from
(
/* SQL Body */
) a
where rownum <= (:page * 10)
)
where no >= (:page - 1) * 10 + 1Top N 쿼리이므로 ROWNUM으로 지정한 건수만큼 결과 레코드를 얻으면 거기서 바로 멈춘다. 뒤쪽 페이지로 이동할수록 읽는 데이터량도 많아지는 단점이 있지만, 보통 앞쪽 일부 데이터만 확인
부분범위 처리 가능하도록 SQL을 작성한다?
- 인덱스 사용 가능하도록 조건절 구사
- 조인은 NL 조인 위주로 처리
- Order By 절이 있어도 소트 연산을 생략하도록 인덱스를 구성

페이징 처리 ANTI 패턴
select *
from (
select rownum no, a.*
from
(
/* SQL Body */
) a
)
where no between (:page - 1) * 10 + 1 and (:page * 10) 
- Sort Order By 오퍼레이션은 나타나지 않지만, Count 옆에 Stopkey가 없다.
- Rownum을 사용하지 않고 Between을 사용하면 만족하는 데이터를 전부 찾았음에도 남은 데이터를 확인해야한다.
5.3.3 최소값/최대값 구하기
-
최소값 또는 최대값을 구하는 SQL 실행계획을 보면, 아래와 같이 Sort Aggregate 오퍼레이션이 나타난다.
- Sort Aggregate이란 전체 데이터를 정렬하지는 않지만, 전체 데이터를 읽으면서 값을 비교한다고 앞에서 설명
-
전체 데이터를 읽지 않고 인덱스를 이용해서 최소 또는 최대 값을 구하려면, 조건절 컬럼과 MIX/MAX 함수 인자 컬럼이 모두 인덱스에 포함돼 있어야한다. => 테이블 액세스가 발생하지 않아야한다.
인덱스 구성 별 실행 계획
- [DEPTNO + MGR + SAL]순

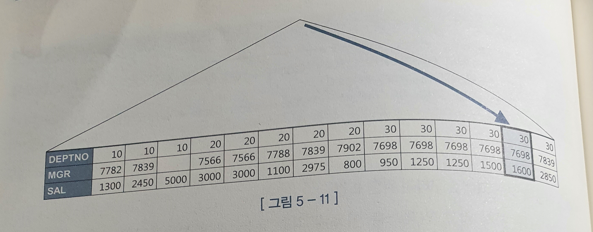
- DEPTNO, MGR이 인덱스 선두 컬럼이고 모두 '=' 조건이므로 FRIST ROW 조건을 만족하는 레코드 하나를 찾았을 때 바로 멈춘다.
- [DEPTNO + SAL + MGR]순

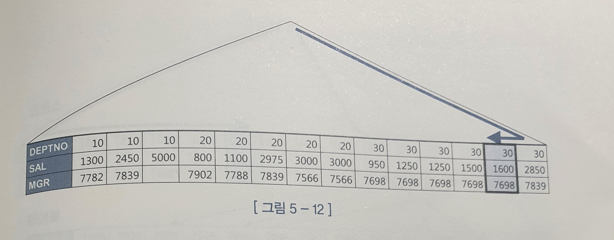
- DEPTNO는 액세스 조건, MGR 필터 조건으로 사용되며
DEPTNO = 30 조건을 만족하는 범위 가장 오른쪽으로 내려가면서 가장 큰 SAL 값을 읽게 된다. 거기서 부터 스캔을 시작해 MGR = 7698 조건을 만족하는 레코드 하나를 찾았을 때 멈춘다.
- [SAL + DEPTNO + MGR]순

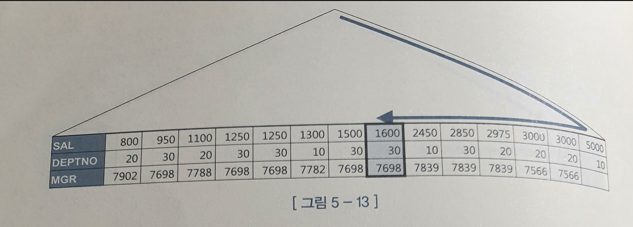
- DEPTNO는 필터 조건, MGR 필터 조건이며 조건절 컬럼과 MAX 컬럼이 모두 인덱스에 포함되어 있어서 First Row Stopkey 알고리즘이 작동한다.
조건절 컬럼이 둘다 인덱스 선두 컬럼이 아니라서 Index Range Scan은 불가능하다. 대신 Index Full Scan 방식으로 인덱스 전체 레코드 중 가장 오른쪽에서 스캔을 시작해 DEPTNO와 MGR 조건을 만족하는 레코드 하나를 찾았을 때 멈추면 된다.
- [DEPTNO + SAL]순
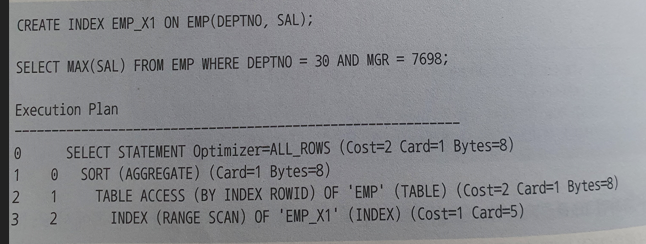
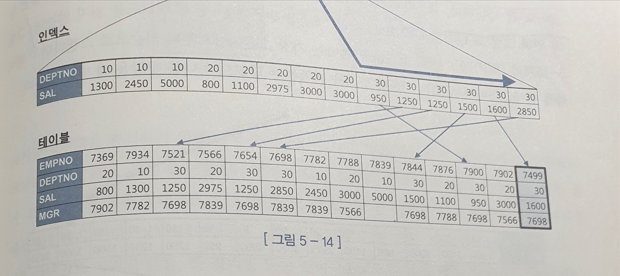
- DEPTNO = 30 조건을 만족하는 전체 레코드를 읽어서 테이블에서 MGR = 7698 조건을 필터리한 후 MAX(SAL) 값을 구한다. 즉, First Row Stopkey 알고리즘이 작동하지 않는다.
- TOP N 쿼리 이용해 최소/최대값 구하기

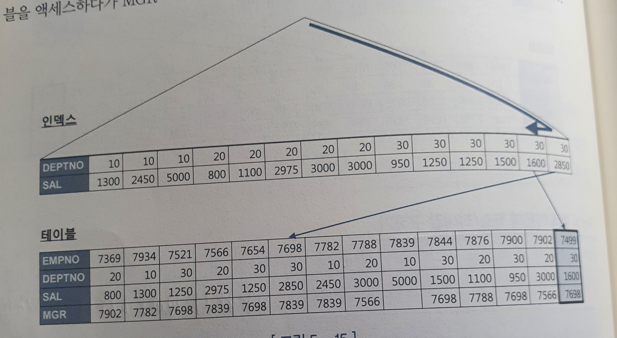
- Top N 쿼리에 작동하는 Top N stopkey 알고리즘은 모든 컬럼이 인덱스에 포함되어 있지 않아도 잘 작동한다. DEPTNO = 30 조건을 만족하는 전체 레코드를 읽지 않고 가장 오른쪽에서부터 역순으로 스캔하면서 테이블 액세스를 하면서 MGR 조건을 만족하는 레코드 하나를 찾으면 바로 멈춘다.
- [DEPTNO + MGR + SAL]순
5.3.4 이력 조회
- 이력 데이터를 조회할 때 [First Row StopKey] 또는 [Top N Stopkey] 알고리즘을 작동할 수 있게 인덱스 설계 및 SQL 구현을 해야한다.
- 가장 단순한 이력 조회
- 인덱스가 [장비번호 + 변경일자 + 변경순번] 구성
- First Row Stopkey 알고리즘 작동
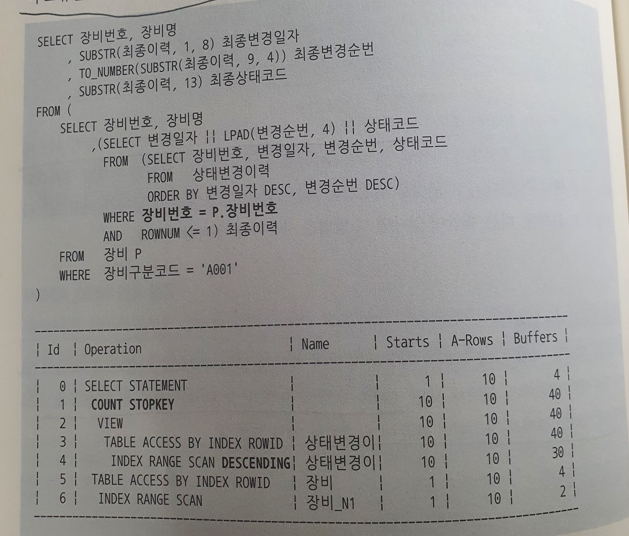
SELECT 장비번호, 장비명, 상태코드
,(SELECT MAX(변경일자)
FROM 상태변경이력
WHERE 장비번호 = P.장비번호) 최종변경일자
FROM 장비 P
WHERE 장비구분코드 = 'A001'- 마지막 변경일자와 변경순번 이력 조회
- 2 - 1
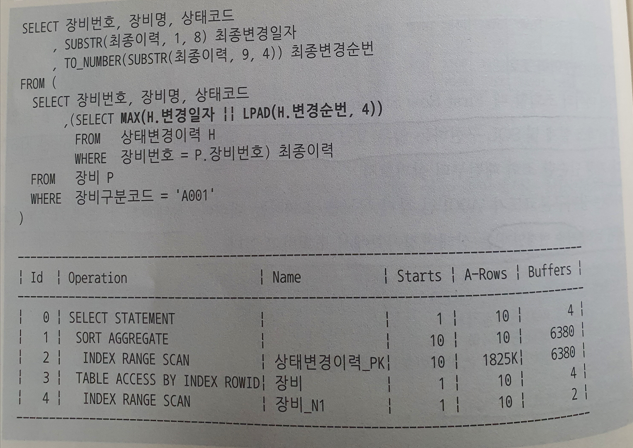
- 인덱스 컬럼을 가공해서 First Row Stopkey 알고리즘 작동 X
- 2 - 2.
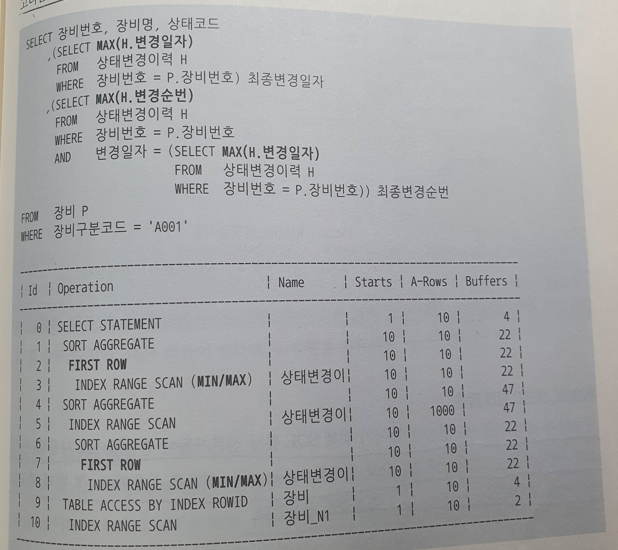
- 상태변경이력을 세 번 조회하지만 First Row Stopkey 알고리즘이 잘 작동하므로 성능은 비교적 좋다.
- 2 - 1
- INDEX_DESC 힌트 활용
- 인덱스 구성이 완벽할 경우 쿼리가 좋은 성능을 내지만 인덱스 구성이 바뀌면 언제든 결과집합에 문제가 생길 수 있다.
- INDEX_DESC와 ROWNUM <= 1을 사용하면 바로 조회가능.
SELECT 장비번호, 장비명
, SUBSTR(최종이력, 1, 8) 최종변경일자
, TO_NUMBER(SUBSTR(최종이력, 9, 4)) 최종변경순번
, SUBSTR(최종이력, 13) 최종상태코드
FROM (
SELECT 장비번호, 장비명
,(
SELECT /*+ INDEX_DESC(X 상태변경이력_PK) */
변경일자 || LPAD(변경순번, 4) || 상태코드
FROM 상태변경이력 X
WHERE 장비번호 = P.장비번호
AND ROWNUM <= 1) 최종이력
)
WHERE 장비구분코드 = 'A001'- 11g 부터 사용 가능한 Top N 쿼리
- 12c 부터 사용 가능한 Top N 쿼리
- 전체 장비를 대상으로 조회하거나, 최종이력이 아닌 직전 이력을 조회하는 대용량 데이터 조회 방식에는 윈도우 함수를 이용하는 것이 효과적이다.
- Full Scan과 해시 조인 방식

5.3.5 Sort Group By 생략
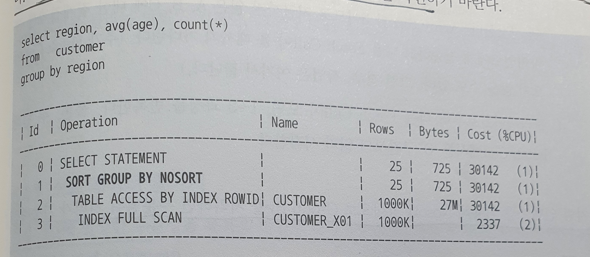
- Sort Group By Nosort
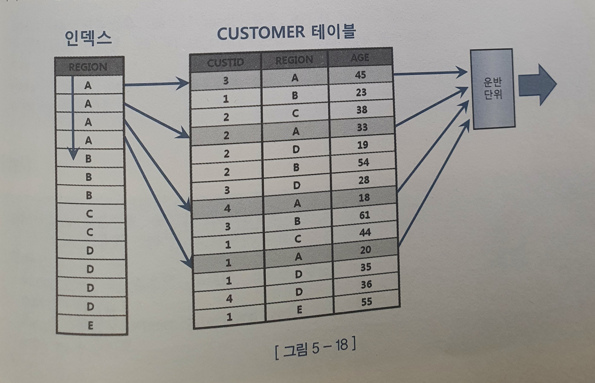
- 동작 방식 확인
- Array Size 3일 때 Group by의 컬럼이 Index로 사용된다면 Index는 정렬되어 있기 때문에 A, B, C에 대한 집계결과를 클라이언트에게 전송하고 다음 Fetch Call이 올 때까지 기다린다.
5.4 Sort Area를 적게 사용하도록 SQL 작성
5.4.1 소트 데이터 줄이기
[1 - 1]
select lpad(상품번호, 30) || lpad(상품명, 30) || lpad(고객ID, 10)
|| lpad(고객명, 20) || to_char(주문일시, 'yyyymmdd hh24:mi:ss')
from 주문 상품
where 주문일시 between :start and :end
order by 상품번호[1 - 2]
select lpad(상품번호, 30) || lpad(상품명, 30) || lpad(고객ID, 10)
|| lpad(고객명, 20) || to_char(주문일시, 'yyyymmdd hh24:mi:ss')
from (
select 상품번호, 상품명, 고객ID, 고객명, 주문일시
from 주문 상품
where 주문일시 between :start and :end
order by 상품번호
)- 1번 SQL은 레코드당 (30 + 30 + 10 + 20 + 17) 바이트로 가공한 결과 집합을 Sort Area에 담는다. 반면, 2번 SQL은 가공하지 않은 상태로 정렬을 완료하고 나서 최종 출력할 때 가공한다. 2번 SQL이 Sort Area를 훨씬 적게 사용한다.
[2 - 1]
select *
from 예수금원장
order by 총예수금 desc[2 - 2]
select 계좌번호, 총 예수금
from 예수금원장
order by 총예수금 desc- 1번 SQL은 모든 컬럼을 Sort Area에 저장하는 반면, 2번 SQL은 계좌번호와 총 예수금만 저장하기 때문이다. 두 SQL 모두 테이블을 Full Scan 했으므로 읽은 데이터량은 똑같지만, 소트한 데이터량이 다르므로 성능도 다르다.
5.4.2 Top N 쿼리의 소트 부하 경감 원리
- Top N 쿼리를 사용하게 된다면 소트 연산 횟수와 Sort Area 사용량을 최소화 해준다.
- Top N 소트의 동작 과정
=> 정렬되지 않은 1000명중에서 가장 큰 학생 열명을 선발하는 과정- 전교생을 운동장에 집합
- 맨 앞줄 맨 왼쪽에 있는 학생 열명을 선발 키 순서로 세운다.
- 나머지 990명을 한 명씩 교실로 들여보내면서 현재 Top 10 위치에 있는 학생과 비교한다. 더 큰 한생이 나타나면, 현재 Top 10 위치에 있는 학생을 교실로 들여보낸다.
- Top 10에 새로 진입한 학생 키에 맟춰 자리를 재배치한다.
- Top N 소트의 동작 과정
- 실행계획에 SORT ORDER BY STOPKEY 존재

5.4.3 Top N 쿼리가 아닐 때 발생하는 소트 부하
- Top N 쿼리가 아니라면 디스크를 사용한 예시
5.4.4 분석함수에서의 Top N 소트
- 윈도우 함수 RANK나 Row_number 함수는 max 함수보다 소트 부하가 적다. Top N 소트 알고리즘이 작동하기 때문이다.

DIVI