7.1 통계정보와 비용 계산 원리
7.1.1 선택도와 카디널리티
- 선택도: 전체 레코드 중에서 조건절에 의해 선택되는 레코드 비율
- 선택도 = 1 / NDV(Number Of Distinct Values) % -> 컬럼 값 종류 개수
- 조건절 선택된 컬럼 수 / 전체 컬럼 수 => 아닌지??
- 하나의 컬럼이 선택되는 확률 (모든 컬럼 데이터가 동일하다는 가정)
- 선택도 = 1 / NDV(Number Of Distinct Values) % -> 컬럼 값 종류 개수
- 카디널리티: 전체 레코드 중에서 조건절에 의해 선택되는 레코드 개수
- 카디널리티 = 총 로우 수 x 선택도 = 총 로우 수 / NDV
- 예시
- 상품분류 컬럼: (가전, 의류, 식음료, 생활용품)
- 조건: WHERE 상품분류 = '가전'
- 전체 레코드: 10만건
-> 선택도는 25%,카디널리티는 25000
- 옵티마이저의 데이터 엑세스 비용 계산 순서
- 선택도 -> 카디널리티 -> 테이블 액세스 방식, 조인 순서, 조인 방식 결정
7.1.2 통계정보
-
통계 정보 = 오브젝트 통계, 시스템 통계
-
오브젝트 통계 = 테이블 통계, 인덱스 통계, 컬럼 통계
-
테이블 통계
-
테이블 통계 수집
begin dbms_stats.gather_table_stats('scott', 'emp'); end; / -
테이블 통계 조회
select num_rows, blocks, avg_row_len, sample_size, last_analyzed from all_tables where owner = 'SCOTT' // 테이블 소유자 and table_name = 'EMP';통계항목 설명 NUM_ROWS 테이블에 저장된 총 레코드 개수 BLOCKS 테이블 블록수 = 사용된 익스텐트에 속한 총 블록 수 AVG_ROW_LEN 레코드당 평균 길이(Bytes) SAMPLE_SIZE 샘플링한 레코드 수 LAST_ANALYZED 통계정보 수집일시
-
-
인덱스 통계
-
인덱스 통계 수집
-- 인덱스 통계만 수집 begin dbms_stats.gather_table_stats( ownname => 'scott', indname => 'emp_x01'); end; / -- 테이블 통계를 수집하면서 인덱스 통계도 같이 수집 begin dbms_stats.gather_table_stats( 'scott', 'emp', cascade=> true); end; / -
인덱스 통계 조회
select blevel, leaf_blocks, num_rows, distinct_keys, avg_leaf_blocks_per_key, avg_data_blocks_per_key, clustering_factor, sample_size, last_analyzed from all_tables where owner = 'SCOTT' // 분석할 테이블 소유자 and table_name = 'EMP' and index_name = 'EMP_X01';통계항목 설명 용도 BLEVEL 인덱스 루트에서 리프 블록에 도달하기 직전까지 읽게되는 블록 수 인덱스 수직적 탐색 비용 계산 LEAF_BLOCKS 인덱스 리프 블록 총 개수 인덱스 수평적 탐색 비용 계산 NUM_ROWS 인덱스에 저장된 레코드 개수 인덱스 수평적 탐색 비용 계산 DISTINCT_KEYS 인덱스 키값의 조합으로 만들어지는 값의 종류 개수 => 인덱스에 저장된 데이터 기준으로 실제 입력된 값의 종류 개수를 구해 놓은 수치 인덱스 수평적 탐색 비용 계산 AVG_LEAF_BLOCKS_PER_KEY 인덱스 키값을 모두 '=' 조건으로 조회할 때 읽게 될 리프 블록 개수 인덱스 수평적 탐색 비용 계산 AVG_DATA_BLOCKS_PER_KEY 인덱스 키값을 모두 '=' 조건으로 조회할 때 읽게 될 테이블 블록 개수 인덱스 수평적 탐색 비용 계산 CLUSTERING_FACTOR 인덱스 키값 기준으로 테이블 데이터가 모여 있는 정도 테이블 액세스 비용 계산
-
-
컬럼 통계
-
컬럼 통계 수집
- 컬럼 통계는 테이블 통계 수집할 때 함께 수집된다.
select num_distinct, density, avg_col_len, low_value, high_value, num_nulls, last_analyzed, sample_size from all_tab_columns where owner = 'SCOTT' and table_name = 'EMP'; and column_name = 'DEPTNO';통계항목 설명 NUM_DISTINCT 컬럼 값의 종류 개수(NDV) DENSITY '=' 조건으로 검색할 때의 선택도를 미리 구해놓은 값 AVG_COL_LEN 컬럼 평균 길이(Bytes) LOW_VALUE 최소 값 HIGH_VALUE 최대 값 NUM_NULLS 값이 NULL인 레코드 수 -
컬럼 히스토그램
-
'=' 조건에 대한 선택도는 1/NUM_DISTINCT 공식으로 구하거나 미리 구해 놓은 DENSITY값을 이용하면 된다. 단, 데이터 분포가 균일하지 않은 컬럼에는 적합하지 않다.
=> 히스토그램은 컬럼 값별로 데이터 비중 또는 빈도를 미리 계산해 놓은 통계정보다. 실제 데이터를 기반으로 계산해서 데이터 분포가 거의 정확하다.
통계항목 설명 도수분포 값별로 빈도수 저장 높이균형 각 버킷의 높이가 동일하도록 데이터 분포 관리 상위도수분포 많은 레코드를 가진 상위 n개 값에 대한 빈도수 저장 하이브리드 도수분포와 높이균형 히스토그램의 특성 결합 -
히스토그램 데이터 수집
begin dbms_stats.gather_table_stats('scott', 'emp', cascade=> false, method_opt=> 'for columns ename size 10', deptno size 4); end; / begin dbms_stats.gather_table_stats('scott', 'emp', cascade=> false, method_opt=> 'for all columns size 75'); => 모든 컬럼에 대해서 Histogram bucket 의 수를 75로 한다. end; / begin dbms_stats.gather_table_stats('scott', 'emp', cascade=> false, method_opt=> 'for all columns size auto'); => 즉, Histogram 의 생성여부를 Oracle 이 알아서 판단하게 된다. end; / -
히스토그램 통계 데이터 조회
select endpoint_value // endpoint_value : 버킷이 담당하는 가장 큰 값 , endpoint_number // endpoint_number : 버킷 번호 from all_histograms where owner = 'SCOTT' and table_name = 'EMP' and column_name = 'DEPTNO' order by endpoint_value;
-
-
-
시스템 통계
- 시스템 통계는 애플리케이션 및 하드웨어 성능 특성을 측정
- CPU 속도
- 평균적인 Single Block I/O 속도
- 평균적인 Multi Block I/O 속도
- 평균적인 Multi Block I/O 개수
- I/O 서브시스템의 최대 처리량 (Throughput)
- 병렬 Slave의 평균적인 처리량 (Throughput)
- 시스템 통계는 애플리케이션 및 하드웨어 성능 특성을 측정
-
-
7.1.3 비용 계산 원리
-
옵티마이저의 통계정보 활용방법
- 인덱스 키값을 모두 '=' 조건으로 검색할 때 인덱스 통계 방식
- 비용 = BLEVEL -- 인덱스 수직적 탐색 비용
+ AVG_LEAF_BLOCKS_PER_KEY -- 인덱스 수평적 탐색 비용
+ AVG_DATA_BLOCKS_PER_KEY -- 테이블 랜덤 액세스 비용
- 비용 = BLEVEL -- 인덱스 수직적 탐색 비용
- 인덱스 키값을 모두 '=' 조건이 아닐 때는 아래와 같이 컬럼 통계까지 활용한다.
- 비용 = BLEVEL -- 인덱스 수직적 탐색 비용
+ LEAF_BLOCKS x 유효 인덱스 선택도 -- 인덱스 수평적 탐색 비용
+ CLUSTERING_FACTOR x 유효 테이블 선택도 -- 테이블 랜덤 액세스 비용
- 비용 = BLEVEL -- 인덱스 수직적 탐색 비용
- BLEVEL, LEAF_BLOCKS, CLUSTERING_FACTOR는 인덱스 통계에서 얻을 수 있고,
유효 인덱스 선택도와 유효 테이블 선택도는 컬럼 통계 및 히스토그램을 이용해 계산한다.- 유효 인덱스 선택도: 전체 인덱스 레코드 중 액세스 조건에 의해 선택될 것으로 예상되는 레코드 비중
=> 1번 - 유효 테이블 선택도: 전체 인덱스 레코드 중 인덱스 컬럼에 대한 모든 조건절에 의해 선택될 것으로 예상되는 레코드 비중
=> 1번 + 2번
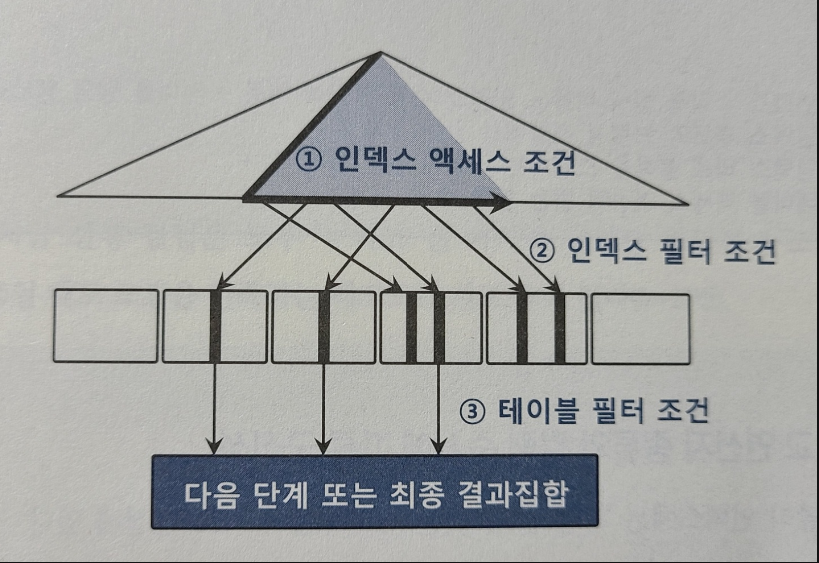
- 유효 인덱스 선택도: 전체 인덱스 레코드 중 액세스 조건에 의해 선택될 것으로 예상되는 레코드 비중
- 인덱스 키값을 모두 '=' 조건으로 검색할 때 인덱스 통계 방식
-
COST의 의미
- I/O 비용 모델을 사용할 때 실행계획에 나타나는 Cost는 '예상 I/O Call 횟수'
- CPU 비용 모델에서 Cost는 Single Block I/O를 기준으로 한 상대적 시간을 표현
=> Cost가 100이라면 현재 시스템에서 Single Block I/O를 100번 하는 정도의 시간으로 해석
=> 상대적인 시간으로 표현하는 이유는 같은 실행계획이여서 애플리케이션 및 하드웨어 성능 특성에 따라 시간이 다르고 I/O방식(Single Block I/O), I/O속도(Multi Block I/O)가 모두 다르기 때문이다.
7.2 옵티마이저에 대한 이해
7.2.1 옵티마이저 종류
-
비용기반(Cost-Based) 옵티마이저는 사용자 쿼리를 위해 후본군이 될만한 실행계획들을 도출하고, 데이터 딕셔너리에 미리 수집해 둔 통계정보를 이용해 각 실행계획의 예상비용을 산정하고, 그중 가장 낮은 비용의 실행계획 하나를 선택하는 옵티마이저
- CBO가 사용하는 통계정보: 데이터량, 컬럼 값의 수, 컬럼 값 분포, 인덱스 높이, 클러스터링 팩터
-
규칙기반(Rule-Based) 옵티마이저는 데이터 특성을 타나태는 통계정보를 전혀 활용하지 않고 단순한 규칙에만 의존하기 때문에 대량 데이터를 처리하는 부적합하다.
-
인덱스 구조, 연산자, 조건절 형태가 순위 결정
-
순위 액세스 경로 1 Single Row By Rowid 2 Single Row By Cluster Join 3 Single Row By Hash Cluster Key with Unique or Primary Key 4 Single Row By Unique or Primary Key 5 Clustered Join 6 Hash Cluster Key 7 Indexed Cluster Key 8 Composite Index 9 Single-Column Indexes 10 Bounded Range Search on Indexed Columns 11 UnBounded Range Search on Indexed Columns 12 Sort Merge Join 13 Max or Min of Indexed Column 14 ORDER BY on Indexed Column 15 Full Table Scan -
RBO의 좋지 않은 예시
- 인덱스가 있다면 무조건 인덱스 사용
=> 조회하는 데이터가 전체에서 90%인 경우 인덱스는 비효율적인 선택. SELECT * FROM 고객 ORDER BY 고객명;
=> ORDER BY가 Full Table Scan보다 높은 우선순위인 상황이기 때문에 전체 조회에도 불구하고 인덱스로 전체 레코드를 엑세스 하는 상황 발생.SELECT * FROM 사원 WHERE 연령 >= 60 AND 연봉 BETWEEN 3000 AND 6000;
=> BETWEEN이 우선순위가 더 높기 때문에 BETWEEN 조건에 있는 연봉 컬럼의 인덱스를 사용하게된다. BETWEEN은 닫힌 범위검색 조건이고, 부등호는 열린 범위검색 조건이므로 BETWEEN이 더 유리하다는 규칙은 어느 정도 타당하다. 하지만 현실적으로 60세 이상보다는 3000 ~ 6000만원의 연봉 받는 사원이 훨씬 많기 때문에 범위를 선정하는데 비효율적인 상황 발생.
- 인덱스가 있다면 무조건 인덱스 사용
-
결론적으로 대용량 데이터, 빅데이터 조회시에 CBO 선택은 필수이고 오라클 조차 CBO만 지원한다고 선언했다.
-
7.2.2 옵티마이저 모드
- 비용기반 옵티마이저 모드
- ALL_ROWS : 전체 처리속도 최적화
- 쿼리 결과집합 '전체를 읽는 것을 전제로' 시스템 리소스를 가장 적게 사용하는 실행계획을 선택
- FIRST_ROWS : 최초 응답속도 최적화
- 전체 결과집합 중 '앞쪽 일부만 읽다가 멈추는 것을 전제로' 응답 속도가 가장 빠른 실행계획을 선택. 즉, 최초 응답속도 최적화가 목표이며 Tabla Full Scan 보다 인덱스를 더 많이 선택하고, 해시조인, 소트 머지 조인보다 NL 조인을 더 많이 선택하는 경향
=> 앞으로 사라지게 될 옵티마이저 모드
- 전체 결과집합 중 '앞쪽 일부만 읽다가 멈추는 것을 전제로' 응답 속도가 가장 빠른 실행계획을 선택. 즉, 최초 응답속도 최적화가 목표이며 Tabla Full Scan 보다 인덱스를 더 많이 선택하고, 해시조인, 소트 머지 조인보다 NL 조인을 더 많이 선택하는 경향
- FIRST_ROWS_N : 최초 N건 응답속도 최적화
- 사용자가 '앞쪽 N개 로우만 읽고 멈추는 것을 전제로' 응답 속도가 가장 빠른 실행계획을 선택한다. alter system 또는 alter session 명령어로 옵티마이저 모드 설정
alter session set optimize_mode = first_rows_1; alter session set optimize_mode = first_rows_10; alter session set optimize_mode = first_rows_100; alter session set optimize_mode = first_rows_1000;- FIRST_ROWS(n) 힌트 설정
SELECT /*+ first_rows(30)*/ col1, col2, col3 from t where ~~
- ALL_ROWS : 전체 처리속도 최적화
7.2.3 옵티마이저에 영향을 미치는 요소
- SQL과 연산자 형태
- 결과가 같더라도 SQL을 어떤 형태로 작성했는지 OR 어떤 연산자(=, LIKE, BETWEEN)를 사용했는지에 따라 옵티마이저가 다른 선택 가능
=> 쿼리 성능 영향 미친다.
- 결과가 같더라도 SQL을 어떤 형태로 작성했는지 OR 어떤 연산자(=, LIKE, BETWEEN)를 사용했는지에 따라 옵티마이저가 다른 선택 가능
- 인덱스, IOT, 클러스터, 파티션, MV 등 옵티마이징 팩터
- 쿼리를 똑같이 작성해도 인덱스, IOT, 클러스터, 파티션, MV 등을 구성했는지, 어떤식으로 구성했는지에 따라 실행계획과 성능이 크게 달라진다.
- 제약 설정
- DBMS에 설정한 PK, FK, Check, Not Null 같은 제약들은 데이터 무결성을 보장해 줄뿐만 아니라 옵티마이저가 쿼리 성능을 최적화하는데 매우 중요한 메타 정보 활용
- 통계 정보
- 통계정보에 문제가 생기면 애플리케이션 성능이 느려지고 장애 발생 가능성이 생긴다.
- 특정 테이블 통계정보를 갑자기 삭제
- 대량 데이터를 지웠다가 다시 입력하기 직전, 데이터가 없는 상태에서 자동으로 통계정보가 수집
- 3년간 갱신하지 않던 특정 테이블 통계정보를 어느 날 갑자기 재수집
- 통계정보 없이 관리하던 테이블에 인덱스를 재생성
- 테이블이나 인덱스를 재생성하면서 파티션 단위로만 통계정보를 수집
- 통계정보에 문제가 생기면 애플리케이션 성능이 느려지고 장애 발생 가능성이 생긴다.
- 옵티마이저 힌트
- 옵티마이저에 가장 절대적인 영향을 미치는 요소는 힌트
- 문법적으로 맞지 않게 힌트를 기술
- 잘못된 참조 사용
- 의미적으로 맞지 않게 힌트를 기술
- 논리적으로 불가능한 액세스 경로
- 버그
- 옵티마이저에 가장 절대적인 영향을 미치는 요소는 힌트
- 옵티마이저 관련 파라미터
SELECT NAME, VALUE, ISDEFAULT, DEFAULT_VALUE FROM V$SYS_OPTIMIZER_ENV
7.2.4 옵티마이저의 한계
- 옵티마이저 행동에 가장 큰 영향을 미치는 통계정보를 '필요한 만큼 충분히' 확보하는 것부터가 불가능한 일이다. 정보가 많으면 많을수록 좋지만, 그것을 수집하고 관리하는 데 어마어마한 시간과 비용이 들기 때문이다.
- 통계정보를 완벽하게 수집해도 바인드 변수(외부에서 입력받는 변수)를 사용한 SQL에 컬럼 히스토그램을 활용할 수 없다는 치명적인 단점이 있다.
=> 바인드 변수를 사용하면 정확한 컬럼 히스토그램에 근거하지 않고 카디널리티를 구하는 정해진 계산식에 기초해 비용을 계산하므로 최적이 아닌 실행계획을 수립할 가능성이 커짐 - 비용 기반으로 작동해도, 내부적으로 여러 가정과 정해진 규칙을 이용해 기계적인 선택을 한다는 사실도 옵티마이저가 한계를 보이는 원인 중 하나다.
- 최적화에 허용되는 시간이 매우 짧은 것도 중요한 제약 중 하나다.
7.2.5 개발자의 역할
- 고성능, 고효율 DB 애플리케이션을 구축하려면, 소수 DBA나 튜너보다 다수 개발자 역할이 더 중요하다. => SQL 수행원리와 튜닝방법을 익히는 데도 많은 노력과 시간을 할당해야한다.
- 필요한 최소 블록만 읽도록 쿼리 작성
- 최적의 옵티마이팅 팩터를 제공한다.
- 필요하다면, 옵티마이저 힌트를 사용해 최적의 액세스 경로로 유도한다.
- 필요한 최소 블록만 읽도록 쿼리 작성
SELECT *
FROM (
SELECT ROWNUM NO, 등록일자, 번호, 제목, 회원명, 게시판유형명, 질문유형명, 아이콘, 댓글개수
FROM (
SELECT A.등록일자, A.번호, A.제목, B.회원명, C.게시판유형명, D.질문유형명
, GET_ICON(D.질문유형코드) 아이콘, ( SELECT ~ FROM ~) 댓글개수
FROM 게시판 A, 회원 B, 게시판 유형 C, 질문유형 D
WHERE A.게시판유형 = :TYPE
AND B.회원번호 = A.작성자번호
AND C.게시판유형 = A.게시판유형
AND D.질문유형 = A.질문유형
ORDER BY A.등록일자 DESC, A.질문유형, A.번호
)
WHERE ROWNUM <= (:page * 10)
)
WHERE NO >= (:page-1) * 10 + 1- 위 쿼리의 문제점
- 화면에 출력할 대상이 아닌 게시물에 대해서도 GET_ICON 함수와 댓글개수 세는 스칼라 서브쿼리 수행
- 회원, 게시판유형, 질문유형 테이블과 조인하는 순서
SELECT /*+ ORDERED USE_NL(B), USE_NL(C), USE_NL(D) */
A.등록일자, A.번호, A.제목, B.회원명, C.게시판유형명, D.질문유형명
, GET_ICON(D.질문유형코드) 아이콘, ( SELECT ~ FROM ~) 댓글개수
FROM (
SELECT
A.*, ROWNUM NO
FROM (
SELECT 등록일자, 번호, 제목, 작성자번호, 게시판유형, 질문유형
, GET_ICON(D.질문유형코드) 아이콘, ( SELECT ~ FROM ~) 댓글개수
FROM 게시판
WHERE A.게시판유형 = :TYPE
AND 작성자번호 IS NOT NULL
AND 게시판유형 IS NOT NULL
AND 질문유형 IS NOT NULL
ORDER BY 등록일자 DESC, 질문유형, 번호
) A
WHERE ROWNUM <= (:page * 10)
) A, 회원 B, 게시판유형 C, 질문유형 D
WHERE NO >= (:page-1) * 10 + 1
AND B.회원번호 = A.작성자번호
AND C.게시판유형 = A.게시판유형
AND D.질문유형 = A.질문유형
ORDER BY A.등록일자 DESC, A.질문유형, A.번호=> 게시판 테이블에서 필요한 데이터만 조회 후 최종 결과 집합 10건에 대해서만 NL 조인 수행, 최종 결과집합 10건에 대해서만 함수를 호출하고 스칼라 서브 쿼리 수행
- 최적의 옵티마이징 팩터 제공
- 전략적인 인덱스 구성
- 인덱스를 전략적으로 구성하는 책임은 DBA가 아닌 개발팀에 있다. 인덱스는 항상 SQL 조건절을 기준으로 설계해야하는데, 어떤 테이블을 어떤 조건으로 자주 액세스하는지 DBA보다 개발자가 훨씬 잘 알기 때문이다.
- DBMS가 제공하는 다양한 기능 활용
- 인덱스, 파티션, 클러스터, IOT, MV, Result Cache 등 DBMS가 제공하는 기능들을 적극적으로 활용
- 옵티마이저 모드 설정
- 정확하고 안정적인 통계정보
- 전략적인 인덱스 구성
=> 결론
- 옵티마이저 모드를 포함해 각종 파라미터를 적절한 값으로 설정하고, 통계정보를 잘 수집해 주는 것이 무엇보다 중요
- 전략적인 인덱스 구성이 필수적
- DBMS가 제공하는 기능을 적극적으로 활용해 옵티마이저가 최적의 선택을 할 수 있도록 다양한 수단 제공
- 필요하다면, 옵티마이저 힌트를 사용해 최적의 액세스 경로로 유도한다.
- 힌트를 사용해서 최적의 액세스 경로로 유도할 수 있어야한다.
7.2.6 튜닝 전문가 되는 공부방법
- 데이터베이스 튜닝이란 성능 튜닝을 말한다. 즉, 파일에 데이터를 읽고 쓰는 소프트웨어 애플리케이션인 DBMS가 대상이다. => DBMS 성능 튜닝이 더 정확하다.
- SQL이 병목이나 지연없이 빠르고 안정적으로 수행되도록 조치하는 조치하는 것을 의미
- SQL 튜닝: I/O 효융ㄹ화, DB Call 최소화, SQL 파싱 최소화
- DB 설계: 논리적 데이터 구조 설계, 물리적 저장 구조 설계
- 인스턴스 튜닝: Lock/Latch 모니터링 및 해소, 메모리 설정, 프로레스 설정 등
- SQL이 병목이나 지연없이 빠르고 안정적으로 수행되도록 조치하는 조치하는 것을 의미
-
데이터 베이스 튜닝
- 데이터베이스에서 좋은 소스란, 옵티마이저가 효율적으로 처리할 수 있게 작성한 SQL을 말하며 좋은 공간이란 효과적인 데이터 구조를 의미한다.
-
DBA가 되고 싶다면
- 데이터 베이스 설치, 백업/복구, 오브젝트 생성/변경, 보안
-
SQL 튜닝을 잘하고 싶다면 SQL 중심으로 공부해야한다.
- 옵티마이저가 SQL을 파싱하고 통계정보를 활용해 실행계획을 생성하는 원리
- 옵티마이저가 쿼리변환 원리를 바탕으로 실행계획을 분석하는 방법
- 옵티마이저가 힌트를 이용해 실행계획을 제어하는 방법
- 옵티마이저가 좋은 실행계획을 생성하도록 유도하기 위한 효과적인 SQL 작성버
- 애플리케이션에서 SQL을 실행할 때 사용하는 프로그래밍 인터페이스
- SQL을 빠르게 처리할 수 있는 좋은 데이터 구조와 파티션/인덱스 설계
- 정확성과 안정성을 확보할 수 있는 통계정보 수집 정책
- 디버깅 능력
