Abstract
Model Distillation은 복잡한 모델의 지식을 간단한 모델에게 증류하는 것이 목적이다. 이 논문에서는 모델을 고정하고 큰 dataset에서 작은 dataset으로 지식을 증류하는 dataset distillation 방법을 제안한다. 이 논문의 핵심 아이디어는 적은 수의 데이터 포인트를 합성하는 것인데, 이 데이터 포인트는 정확한 데이터 분포로부터 가져올 필요는 없지만, 원본 데이터에 대해서 학습된 모델과 근사한 형태로 학습 알고리즘에 훈련 데이터로 제공되어야 한다. 예를 들어, 우리는 60,000개의 MNIST 훈련 이미지를 10개의 합성 이미지로 증류하여 소수의 경사 하강 단계를 거쳐 원본과 비슷한 성능을 달성하였다. 우리는 다양한 초기값들과 다른 objective로의 학습에 대해서 우리의 방법을 평가했다. 여러 데이터셋에 대해서 실험해 본 결과는 우리의 접근법이 다른 방법들에 비해 장점을 가지는 것을 보여준다.
1. Introdutcion
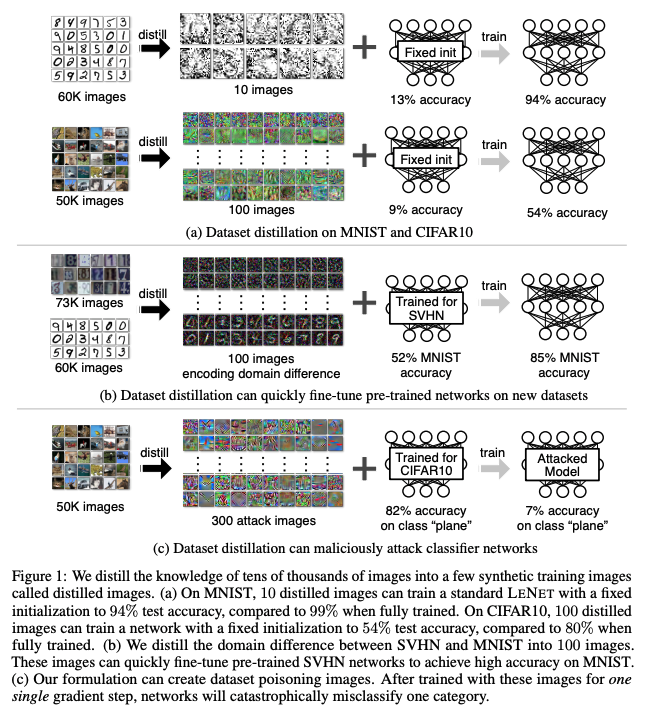
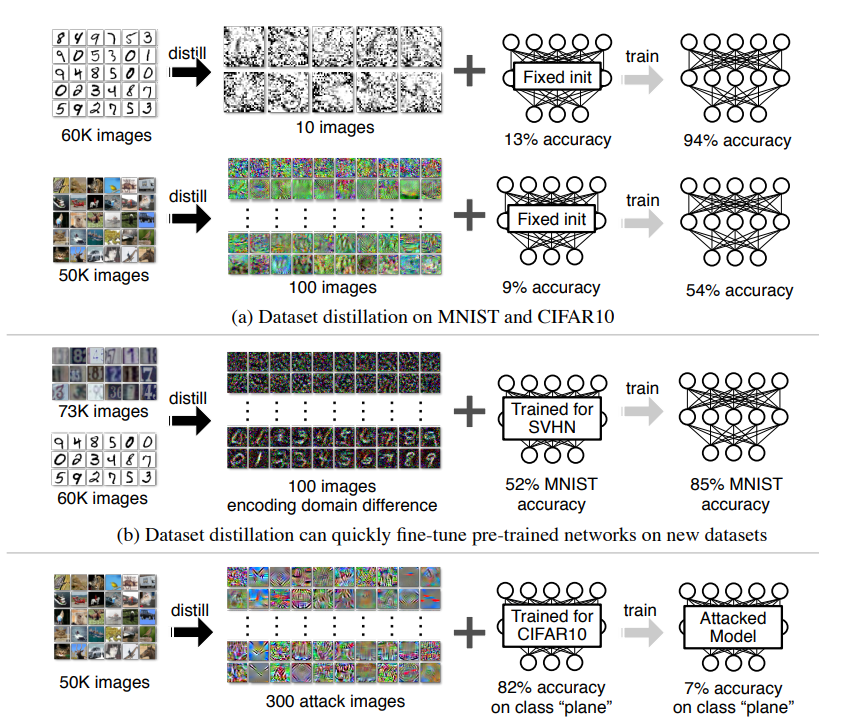
Hinton et al.(2015)는 여러가지의 개별 훈련된 네트워크들의 앙상블로부터 얻은 지식을 하나의 (일반적으로 가벼운)네트워크에 전수하는 network distillation을 제안했다. 이 논문에서는 이와 연관되어있지만, 수직 방향의 task : 모델을 증류하는 대신 데이터셋을 증류하는 방법을 고려한다. network distillaion과는 다르게, 우리의 방법은 모델은 고정하고 전체 데이터셋의 지식만을 캡슐화한다. 적은 수의 합성 훈련 이미지를 만들기 위한 전체 데이터셋은 수 천 ~ 수 만개의 이미지를 포함한다. 우리는 한 카테고리당 한개의 합성된 이미지 수준까지 작게 만들 수 있다는 것과, 합성된 이미지를 적용해 같은 모델을 훈련했을 때 놀라울만큼 좋은 성능을 낸다는 것을 보인다. 예를 들어 그림 1에서, 우리는 고정된 네트워크 초기값을 가지고 60,000개의 MNIST 훈련 이미지를 한 클래스당 10개의 이미지로 합성했다. 이 10개의 이미지를 standard LeNet을 통해서 훈련하고 테스트 한 결과 94%의 정확도를 얻을 수 있었다(원본 데이터에 대한 정확도는 99%이다). 알려지지 않은 random weight로 훈련된 네트워크에 대해서는, 소수의 경사 하강 단계를 지났을 때, 100개의 합성 이미지를 훈련해서 80%의 정확도를 얻을 수 있었다. 우리는 우리의 방법을 Dataset Distillaion이라고 이름했고, 이 이미지들을 distilled images라고 정했다.
그런데 "왜 dataset distillation이 유용한가?", "주어진 데이터에 대해 얼마나 encoded 되어 있는지?" 그리고 "얼마나 압축이 가능한지?"에 대한 순전히 과학적인 질문이 있다. 또한 주어진 소수의 distilled images를 사용하면, 종종 수만 개의 경사 하단 단계를 사용해야하는 기존의 훈련에 비해 더 효율적인 방법으로 전체 데이터셋의 가치의 지식을 가져올 수 있다.
핵심 질문은 데이터셋을 합성 데이터 샘플의 작은 셋으로 압축하는 것이 가능한지 여부이다. 예를 들어 합성된 이미지를 통해 훈련된 이미지 분류 모델이 다양한 자연의 이미지를 잘 구분할 수 있는가? 합성 훈련 데이터는 실제 테스트 데이터의 분포를 따르지 않기 때문에 전통적인 지식에 따르면 대답은 No일 것이다. 그러나 이 작업에서, 우리는 이것이 실제로 가능함을 보인다. 우리는 합성을 위한 새로운 최적화 알고리즘을 제시하는데 이 방법은 적은 수의 합성 데이터 샘플은 원본 훈련 데이터의 많은 부분을 capturing할 뿐만 아니라, 소수의 경사 단계만을 거치는 빠른 모델 훈련을 위해서도 사용될 수 있도록 명시적으로 맞추어져있다. 우리의 목표를 달성하기 위해 먼저 합성 훈련 데이터의 미분 가능한 함수를 네트워크 가중치로 도출한다. 주어진 연결을 사용해, 특정 훈련 objective에 대한 네트워크 가중치를 최적화하는 대신 증류된 이미지의 픽셀 값을 최적화한다. 그러나 이러한 공식은 네트워크의 초기 가중치에 대한 접근을 필요로한다. 이러한 가정을 해결하기 위해서, 우리는 랜덤으로 초기화된 네트워크에서 증류된 이미지를 생성하는 방법을 개발했다. 성능을 더욱 향상시키기 위해 일련의 증류된 이미지를 얻고, 증류된 이미지를 여러 에폭으로 훈련할 수 있는 iterative version을 제안한다. 마지막으로 전체 데이터 세트에 대한 훈련과 동일한 성능을 달성하는데 필요한 증류된 데이터의 lower bound를 유도하는 간단한 선형 모델을 연구한다.
우리는 소수의 증류된 이미지를 사용하여 고정된 초기값으로 모델을 훈련했을 때 놀라울정도의 높은 성능을 달성할 수 있음을 보여준다. 다른 task에 대해 사전 훈련된 네트워크의 경우, 우리의 방법은 빠른 fine-tuning을 가능하게 해주는 증류된 이미지를 찾아준다. 우리는 우리의 방법을 fixed initialization, random initialization, fixed pre-trained weights, random pre-trained weights 등의 여러가지 초기화 방법들에 대해서 두 개의 잘 알려진 목적 : 이미지 분류, 악성 데이터셋 중독 공격 에 대해 실험했다. 네 개의 공개된 데이터셋 MNIST, CIFAR10, PASCAL-VOC, CUB-200에 대해 광범위한 실험을 한 결과 우리의 접근 방식이 종종 기존의 방식을 능가함을 보인다.
2. Related Work
Knowledge Distillation 이 논문의 주된 영감은 앙상블 학습과 모델 압축에 주로 사용되는 network distillaion에서 왔다. network distillaion이 여러 네트워크들의 지식을 단일 모델에 증류하는 반면에, 우리의 목표는 전체 데이터셋에 대한 지식을 압축하여 작은 합성 훈련 이미지들로 만드는 것이다. 우리의 방식과 비슷하게, data-free knowledge distillation 또한 합성 데이터 샘플을 최적화한다, 그러나 다른 objective로 teacher model의 활성화 통계와 매칭시킨다. 우리의 방법은 또한 대상 모델을 학습자에게 가르치는데 필요한 데이터 셋의 크기를 지정해주는 teaching dimension의 이론적인 컨셉과 연관이 있다. 반면에 이 방법은 target model이 필요하지만 우리의 방법은 target model이 필요하지 않다.
Dataset pruning, Core-set construction, and Instance selection 지식을 증류하는 다른 방법으로는 전체 데이터셋을 작은 subset으로 요약하는 방법이다, 즉 오직 "가치있는" 데이터만을 모델 훈련에 사용하거나, active learning의 경우 오직 "가치있는" 데이터만 라벨링하는 것이다. 비슷하게, core-set construction과 instance selection 방법들은 전체 데이터셋에서 골라낸 subset이, 전체 데이터셋에 대해 훈련한 것과 비슷한 성능을 내도록 subset을 고르는것이 목표이다. 예를들어 전통적 선형 학습 알고리즘의 해결법인 퍼셉트론과 SVM은 training example들의 subset들의 가중치를 합한것이라는 점에서 core-set처럼 보인다. 그러나 이러한 subsets을 만들어 내는 알고리즘을 만들기 위해서는, 우리가 만든 방법에 비해 각 카테고리당 더 많은 training examples가 필요하다. 그리고 그들의 "가치있는" 이미지는 실제해야 하지만, 우리의 diatilled images는 실제하지 않아도 된다.
Gradient-based Hyperparameter Optimization 우리의 방법은 전체 훈련 절차를 역전시켜 구한 최종 validation loss에 대해 그래디언트를 계산하는 그래디언트 기반 하이퍼 파라미터 최적화 기술과 비슷하다. 우리 또한 최적화 단계를 통해 오류를 역전파 한다. 하지만 우리는 오직 트레이닝셋 데이터 만을 사용하며, 하이퍼 파라미터를 조정하는것보다 합성 트레이닝 데이터를 만드는 것에 중점을 둔다. 우리가 아는 한 이 방향의 연구는 우리 이전엔 조금만 다루어졌다. 우리는 더 깊고 다양한 설정에서 dataset distillaion의 아이디어를 보여준다. 결정적으로, 우리의 distilled images는 이전 연구로는 불가능했던 임의의 초기화 가중치에서도 잘 동작한다.
Understanding Datasets 과거의 연구원들은 학습된 모델을 이해하고 시각화하기 위한 다양한 접근 방식을 제시했다. 이러한 접근 방법과는 다르게, 우리는 특정 훈련된 모델보다는 훈련 데이터의 고유한 속성을 이해하는데 관심이 있다. 과거에 훈련 데이트셋 분석은 대부분 데이터셋의 편향 조사에 초점을 맞추었다. 예를들어, Torralba & Efros가 제안한 데이터셋 간의 일반화를 통하여 데이터셋 샘플의 "가치"를 정량화한 방법이 있다. 우리의 방법은 전체 데이터셋을 몇 개의 합성 샘플로 증류하여 데이터셋을 이해하는 새로운 관점을 제시한다.
3. Approach
모델과 데이터셋이 주어지면, 우리는 새롭고 크기가 매우 줄어든(그러면서 원본 데이터셋만큼의 성능을 낼 수 있는) 합성 데이터셋을 얻는 것에 집중한다. 먼저 우리는 고정된 초기값을 가지고 하나의 경사 하강 단계를 가지는 네트워크에 대해 최적화하는 main 알고리즘을 보인다(3.1절). 3.2절에서, 우리는 가중치 초기화에 대해 고정된 값 대신 랜덤한 값을 주는 더 어려운 경우에 대한 해결책을 도출한다. 3.3절에서는, 우리 방법의 적절성과 한계에 대한 독자들의 이해를 돕기 위해, 단일 선형 네트워크에 대해서 공부한다. 또한 우리의 방법이 잘 동작할 수 있는 가중치 초기화 분포에 대해서 토론한다. 3.4절에서, 우리는 우리의 방법을 확장하여 더 많은 경사 하강 단계와 에폭을 사용한다. 마지막으로 3.5절과 3.6절에서 다른 초기화 분포와 다른 objectives로부터 증류된 이미지를 얻는 방법을 설명한다.
훈련 데이터셋 를 라고 했을 때, 우리는 신경망 네트워크를 파라미터화 하여 로 표시한다, 그리고 데이터 포인트 에 대한 loss function을 로 표기한다. 우리의 일은 전체 훈련 데이터에 대한 경험적 오류의 최소점을 찾는 것이다.
표기를 간결하게 하기 위해서 를 덮어써서 가 전체 데이터셋의 에 대한 평균 에러를 나타낸다. 우리는 대부분의 최신 기계학습 모델 및 작업에 적용되는 것과 같이 이 두 번 미분 가능한것을 가정한다.
3.1 Optimizing Distilled Data
일반적인 훈련에서는 보통 미니배치를 사용한 stochastic 경사하강법이나 그의 변형을 사용한다. 각 step을 라고 했을 때, 훈련 데이터의 미니배치 는 현재의 파라미터를 업데이트하기 위해 다음과 같이 샘플된다.
는 학습률이다. 이러한 훈련은 수 만에서 수백만의 업데이트 단계를 거쳐 수렴한다. 대신에, 우리는 적은 셋으로 합성된 증류 훈련 데이터 와 그에 상응하는 학습률 로 다음의 식과 같이 하나의 경사 하강 단계를 거쳐 학습한다,
이렇게 학습한 합성 데이터 는 실제 테스트 셋에서 성능을 대단히 증폭한다. 주어진 초기치 를 사용해, 아래 공식의 을 최소화 하여 합성 데이터 와 학습률 를 얻을 수 있다.
우리가 식(2)를 통해 새로운 가중치 을 증류된 데이터 와 학습률 의 함수로 유도해낸 뒤, 새로운 가중치 을 전체 훈련 데이터 에 대해서 평가한다. 손실함수 은 와 에 대해서 미분 가능하고, 표준 gradient-based 모델에 최적화될 수 있다. 많은 분류 작업에서, 데이터 는 class label과 data-label이 짝으로 있는 것처럼 이산적인 부분을 포함하고 있다. 이러한 경우엔, 우리는 이산적인 부분을 학습하지 않고 수정했다.
3.2 Distillation for Random Initializations
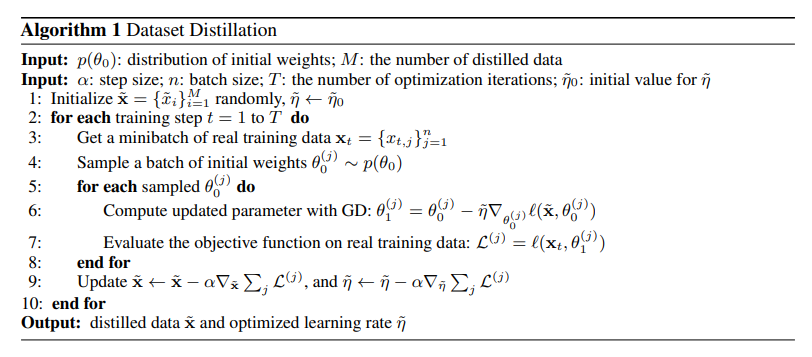
불행히도, 위에서 나온 주어진 초기치에 대해서 증류된 데이터는 또다른 초기치에 대해서는 일반화 되지 않는다. 훈련 데이터셋 와 특정 네트워크 초기치 에 대한 정보를 인코딩하여 증류된 데이터는 종종 랜덤한 노이즈로 보인다(그림2a). 이 문제를 해결하기 위해, 특정 분포에 따른 랜덤한 초기값에 따라서도 네트워크가 동작할 수 있는 방향으로 적은 수의 증류된 데이터를 합성하도록 하였다. 우리는 다음으로 최적화 문제를 공식화 하였다:
네트워크 초기값 는 분포 에 따라 무작위로 샘플된다. 우리의 최적화방법을 따르면, 증류된 데이터는 무작위로 초기화된 네트워크에 대해서도 잘 동작하게 된다. 알고리즘 1은 우리의 main method를 나타낸다. 실제로, 우리는 최종적으로 증류된 데이터가 한번도 보지 못했던 초기치에 대해서 잘 일반화 되었음을 관찰했다. 추가로 이렇게 증류된 이미지는 종종 보기에도 정보가 있어 보이고, 각 카테고리의 차별적 특징들을 잘 인코딩했다(그림 3).

증류된 데이터를 적절히 학습하기 위해서는, 로 부터 샘플된 초기치 전반에 걸쳐서 가 비슷한 local condition(output values, gradient magnitudes)을 공유해야 하는것이 결정적인 것으로 밝혀졌다. 다음 절에서, 우리는 임의의 초기값 로 초기화된 간단한 모델을 위해 필요한 증류된 이미지 사이즈의 lower bound를 유도해낸다. 그리고 위 방법을 로 부터 나온 초기값들에 적용하는 방법도 논의한다.
3.3 Analysis of a Simple Linear Case
이 절에서는 우리의 공식을 이차 손실함수를 가지는 단일 선형 회귀 문제로 공부한다. 우리는 임의의 초기값을 가지고 한 개의 경사 하강 단계를 거쳐 증류된 이미지가 전체 데이터셋에 대해서 훈련된 것과 같은 성능을 내는데 필요한 증류된 이미지 사이즈의 lower bound를 유도한다. 데이터셋 가 개의 데이터-타겟 쌍을 가지고 있다고 생각하자 , , , 두 개의 행렬을 표현할 때: 의 데이터 행렬 와 의 타겟 행렬 . 평균 제곱 오차가 주어지고 가중치 행렬 가 주어졌을 때, 우리는 다음을 얻는다.
우리는 합성 데이터-타켓 쌍인 을 학습하는데 목표를 둔다. 이고, 는 행렬이다, 는 행렬이다(), 그리고 는 학습률이고, 를 최소화한다. 이러한 증류된 데이터의 경사 하강 단계가 지난 뒤 가중치 행렬의 업데이트는 다음과 같이 진행된다.
이차 loss에 의해, 전체 데이터셋 와 같은 성능을 달성하는 학습된 증류 데이터 는 어떠한 초기값 에 대해서든 항상 존재한다(global minimum 달성). 예를 들어, global minimum solution이 로 주어졌을 때, 우리는 그리고 로 선택할 수 있다. 그러나 증류된 데이터의 크기는 얼마나 작을 수 있을까? 이러한 모델에선, global minimum은 어떤 에 대해서도 를 달성한다. 식(6)에 위의 조건을 대입하면 우리는 다음 식을 얻는다,
여기서 우리는 데이터 행렬 의 특징 columns 가 독립이라고 가정한다(는 full rank를 가진다). 가 어떤 에 대해서든 위의 식을 만족하려면, 우리는 반드시 다음 식을 가져야한다,
는 full rank를 가져야 하고 .
Discussion 위의 분석은 단순한 경우만을 고려하지만 소수의 증류된 데이터가 임의의 초기 로 일반화되지 않는다는 것을 암시한다. 이것은 직관적으로 타겟 을 최적화 하는 것이 에 걸친 의 local behavior에 달려있음을 예상하게 한다. 실제 데이터셋이 종종 수 천 심지어 수 십만 차원을 가지는 것을 고려했을때, lower bound 는 상당히 제한적이다, . 이러한 분석은 우리가 비슷한 local conditions를 가지도록 하는 분포에 집중하도록 동기부여한다. 3.5절에서 몇몇의 실제적인 선택들을 탐구한다. 단일 경사 하강 단계를 쓰는 한계를 다루기 위해, 우리는 다음 절에서 우리의 방법을 여러 경사 하강 단계로 확장한다.
3.4 Multiple Gradient Descent Steps and Multiple Epochs
우리는 알고리즘1의 라인6을 한 개 이상의 경사 하강 단계인 multiple sequential GD steps로 확장하여 각각 다른 증류된 이미지 배치와 학습률에 적용했다. 각 step이 일 때,
그리고 라인9를 수정하여 전체 단계를 역전파한다. 하지만 순전히 gradient를 계산하는 것은 메모리와 계산적으로 비싸다. 그러므로, 우리는 최근 기술인 back-gradient optimization을 적용한다. back-gradient optimization은 역방향 모드로 미분을 업데이트 할 때 상당히 빠르게 계산할 수 있는 방법이다.
Multiple Epochs 성능을 더 향상시키기 위해서, 우리는 네트워크에 multiple epochs를 같은 sequence의 증류된 데이터에 적용했다. 달리 말하면, 각 epoch마다, 우리의 방법은 증류된 데이터의 배치사이즈에 따라 모든 경사 하강 단계의 사이클을 돌았다. 후반의 epochs 에서는 종종 작은 학습률을 사용하기 때문에 우리는 epochs 전체에 걸쳐서 훈련된 학습률을 연결하지 않는다.
4.1절에서, 우리는 증류된 이미지의 전체 양이 고정되어있을 때, multiple steps와 multiple epochs를 사용하는 것이 하나의 신경망을 사용하는 것보다 효과적인 것을 밝힌다.
3.5 Distillation with Diffrent Initializations
3.3절의 간단한 선형 케이스에 영감받아, 우리는 전체 데이터 분포와 비슷한 local condition을 가지는 초기 가중치 분포 에 집중한다. 이 실험에서, 우리는 다음 4가지의 실용적인 선택지에 집중한다:
-
Random initialization: 랜덤한 초기 가중치의 분포이다. 예를 들어 신경망에서의 HE Initialization과 Xavier Initialization이 있다.
-
Fixed initialization: 위에서 나온 특정하게 고정된 네트워크 초기화 방법이다.
-
Random pre-trained weights: 다른 task나 dataset에 대해서 pre-trained된 모델의 분포이다. 예를 들어 ImageNet에 대해서 pre-trained된 AlexNet이 있다.
-
Fixed pre-trained weights: 다른 task나 dataset에 대해서 pre-trained 되었으며, 특정하게 고정된 네트워크이다.
Distillation with pre-trained weights 하나의 데이터셋에서 pre-trained된 학습된 증류 데이터가 다른 데이터셋에 대해 잘 동작하기(두 도메인 사이에 간극을 연결하기 위해서는) 위해서는 fine-tuning이 필수적이다. 도메인 불일치 문제와 데이터셋 바이어스 문제는 오늘날 머신러닝의 도전적인 문제들을 대표한다. 이 연구에서, 우리는 도메인 불일치 문제를 데이터 증류문제로 구체화했다. 4.2절에서, 우리는 적은 수의 증류된 이미지가 새로운 dataset과 task의 CNN모델에 충분하고 빠르게 적용되는 것을 보인다.
3.6 Distillation with Diffrent Objectives
다양한 학습 objective로 학습된 증류 데이터는 원하는 다양한 행동을 나타내도록 모델을 훈련할 수 있다. 우리는 증류된 이미지가 정확한 분류기를 훈련하는데 도움을 주는 경우인 "이미지 분류"가 하나의 적용이라고 이미 언급한 바 있다. 아래에서는 우리의 방법의 유연성을 보여주기 위해, 다른 학습 objective를 소개한다.
Distillation for malicious data poisoning 예를 들어, 우리의 방법은 새로운 폼의 데이터 중독 공격방법을 만들어 낼 수 있다. 이 아이디어를 그리기 위해, 우리는 다음의 시나리오를 따른다. 단일 경사 하강 단계가 적용된 우리의 합성된 공격적인 데이터는, 잘 동작하는 이미지 분류기를 공격해 한 카테고리에 대해서 파국적 망각을 일으키지만 다른 카테고리에 대해서는 여전히 높은 정확도를 보여주도록 할 수 있다.
정형적으로, 공격받은 카테고리 그리고 목표 카테고리 가 주어졌을 때, 우리는 새로운 목적함수 : 다른 이미지에 대해서 정확한 예측을 하는동안 K 카테고리의 이미지를 T라고 잘못 분류하도록 하는 손실함수를 최소화한다. 그러면 우리는 최적화를 통해 악성 증류 이미지들을 얻을 수 있다.
는 잘 최적화 된 분류기의 랜덤 초기값이다. 이러한 분류기의 분포에서 학습된 증류 이미지들은 모델의 정확한 가중치에 접근하는 것이 필요하지 않다, 그리고 보지 못했던 모델에 대해서 일반화가 가능하다. 우리의 실험에서, 증류된 악성 이미지들은 2000개의 잘 최적화된 모델에서 훈련된 후, 200개의 교차검증 모델에 대해 평가되었다.
과거의 데이터 중독 공격과 비교해보면, 우리의 접근 방식은 결정적으로 중독된 훈련 데이터를 반복적으로 저장하고 훈련할 필요가 없다. 우리의 방법은 훈련중인 모델을 한 번의 시도와 적은 데이터로도 공격이 가능하다. 이러한 이점으로 인해 우리의 방법은 온라인 교육 알고리즘에 잠재적으로 효과적이며, 악의적인 사용자가 하나의 경사 하강 단계에 대해 데이터 공급 파이프라인을 가로채는 경우에 유용하다. 4.2절에서, 우리는 한 경사 하강 단계가 적용된 증류 데이터의 한 배치로도 잘 최적화된 신경망 모델을 성공적으로 공격하는 것을 보인다. 이 설정은 특정 카테고리에 대한 지식을 데이터로 추출하는 것으로 볼 수 있다.
4. Experiments
우리는 MNIST와 CIFAR10의 image classification 결과를 보고한다. MNIST의 경우, 완전히 훈련시켰을때 99% 의 테스트 정확도를 보인 LeNet으로 증류된 이미지를 훈련시켰다. CIFAR10의 경우, 완전히 훈련했을때 80% 정도의 테스트 정확도를 보인 네트워크 구조를 사용했다. random initializations와 random pre-trained weights의 경우, 특별히 명시되어 있지 않는 한 200개의 보류 모델에 대한 평균 및 표준편차를 보고한다.
Baselines 각 실험마다, 설정과 관련된 baselines 외에도, 우리는 일반적으로 실제 훈련 이미지에서 파생되거나 선택된 데이터로 훈련된 baselines와 방법을 비교한다.
Random real images: 실제 이미지로부터 카테고리당 같은 수의 랜덤한 샘플을 취한다.
Optimized real images: 위에서 정한 기준으로 여러 랜덤한 셋을 구성한 뒤, 상위 20%의 성능을 내는 셋을 선택한다.
k-means: 각 카테고리별로 k-means clustering을 적용하고, 클러스터 중심을 훈련 이미지로 사용한다.
Average real images: 다른 경사 하강 단계에서 재사용되는 평균 이미지를 각 카테고리별로 계산한다.
이러한 baselines를 따라, 우리는 200개의 교차검증 모델에 대해서 성능을 평가하였다(학습률 = {우리의 방법으로 학습된 lr, 0.001, 0.003, 0.01, 0.03, 0.1, 0.3}, epochs = {1, 3, 5}의 각각의 조합에 따라서), 그리고 좋은 성능을 내는 조합을 보고하였다.
4.1 Dataset Distillation
Fixed initialization 초기 네트워크 가중치를 통해, 증류된 이미지는 고정 네트워크를 직접 훈련시켜 고성능에 도달할 수 있다. 예를 들어, MNIST에서 10개의 증류된 이미지는 초기 정확도 12.9% 의 신경망을 최종 정확도 93.76% 까지 성능을 boost할 수 있다(그림 2a). 이와 유사하게, CIFAR10에서 100개의 이미지로 네트워크를 훈련해서 초기 정확도 8.82% 에서 54.03% 의 테스트 정확도까지 훈련할 수 있다(그림 2b). 이러한 결과는 몇 개의 증류된 이미지로도 전체 데이터셋을 증류할 수 있음을 시사한다.
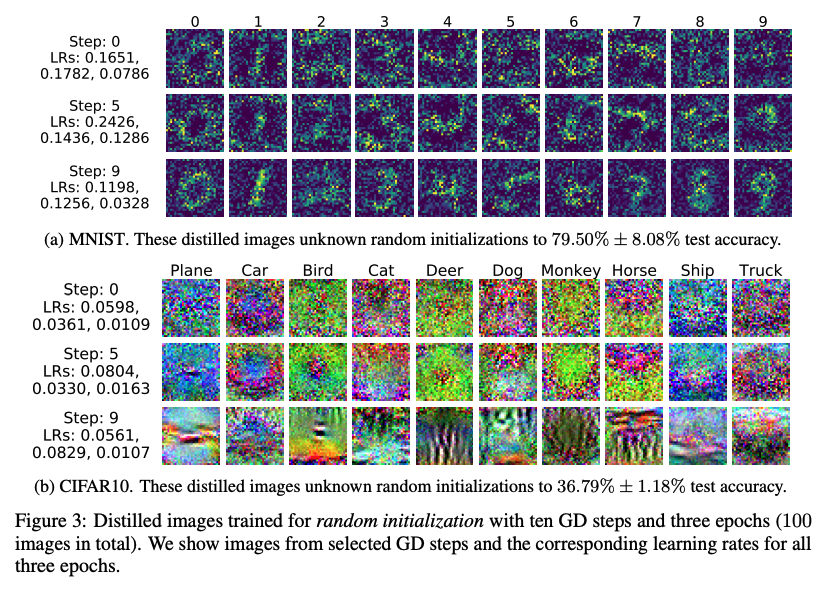
Random intialization 랜덤 샘플 초기화는 Xavier Initialization을 사용했다, 학습된 증류 이미지는 특정 시작점에 맞게 정보를 인코딩할 필요가 없으므로 네트워크 초기화와 독립적으로 의미 있는 콘텐츠를 나타낼 수 있다. 그림3에서, 우리는 증류된 이미지가 해당 카테고리의 특징을 드러냄을 볼 수 있다. CIFAR10 에서 이러한 100개의 이미지는 랜덤하게 초기화된 네트워크를 36.79% 의 테스트 정확도로 훈련할 수 있다. 이와 비슷하게, MNIST에서는, 100개의 증류된 이미지를 사용하면 랜덤하게 초기화된 네트워크에 대해서 79.50% 의 테스트 정확도를 낼 수 있다(그림 3a).
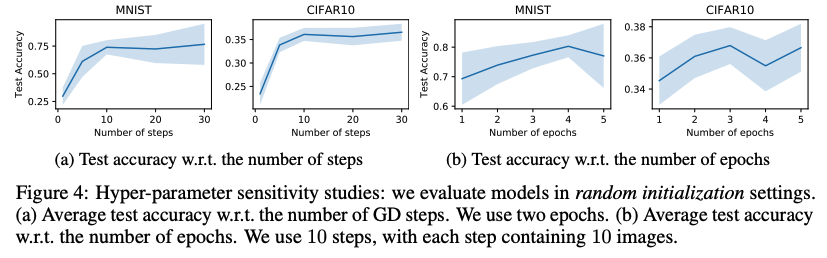
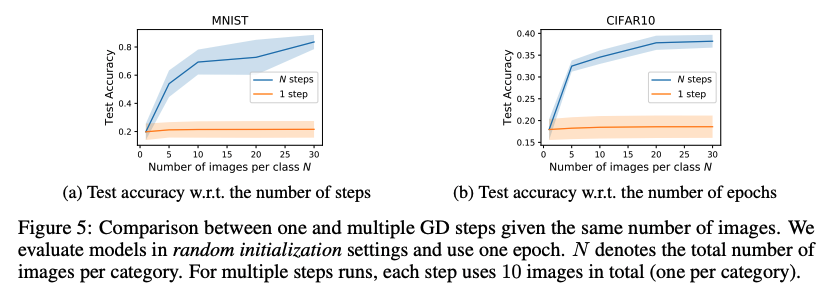
Multiple gradient descent steps and multiple epochs 그림 3에서, 총 100개의 이미지로 이어지는 증류된 이미지는 10번의 경사 하강 단계를 3번의 epoch에 걸쳐 학습했다(각 단계마다 카테고리당 하나의 이미지를 포함한다). 초기의 단계에서 사용된 이미지는 노이즈하게 보이는 경향이 있다. 그러나, 뒤의 단계로 갈수록, 증류된 이미지는 점차 실제 데이터처럼 보이며 각 카테고리에 대한 식별 기능을 공유한다. 그림4a에서는 단계를 더 많이 사용할 수록 상당한 개선의 결과를 보여준다. 그림4b는 에폭의 수가 증가할 때의 변화인데, 단계가 늘어나는(위의) 경우와 비슷하지만 더 느린 경향성을 보여준다. 우리는 더 긴 훈련(더 많은 epochs)은 모델이 증류된 이미지에서 모든 지식을 배우는 데 도움이 될 수 있지만 성능은 결국 총 이미지 수에 의해 제한된다는 것을 관찰했다. 대안으로, 우리는 큰 배치 사이즈를 사용해 하나의 경사 하강 단계를 거치는 모델을 훈련할 수 있다. 3.3절에서 간단한 선형 예시를 들어 하나의 단계가 가지는 이론적 한계를 이미 설명했다. 그림5에서 확인할 수 있듯이 우리는 같은 수의 증류된 이미지가 주어졌을 때, multiple steps를 쓰는것이 single step을 쓰는 것 보다 성능이 크게 향상됨을 관찰했다.
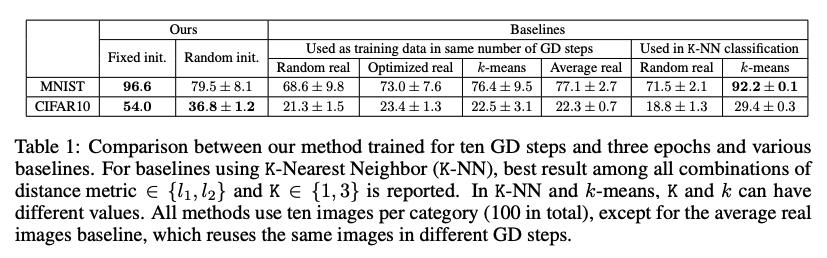
표1에 우리의 방법과 모든 baselines가 요약되어있다. 우리의 방법은 고정/랜덤 초기화 모두 CIFAR10에서 baselines를 뛰어넘었고, MNIST baselines에 대해서도 대부분 성능이 좋았다.
4.2 Distillation with different initializations and objective
다음으로, 3.5절 3.6절에서 언급했던 우리의 메인 알고리즘의 두 가지 확장된 세팅을 다룬다. 두 케이스 모두 가중치 초기화는 랜덤하지만, 같은 데이터셋에 대해서 pre-trained 되었음을 가정한다. 우리는 2000개의 랜덤 pre-trained 모델에서 증류된 이미지를 가지고 그들이 보지 못했던 모델에 대해서 평가했다.
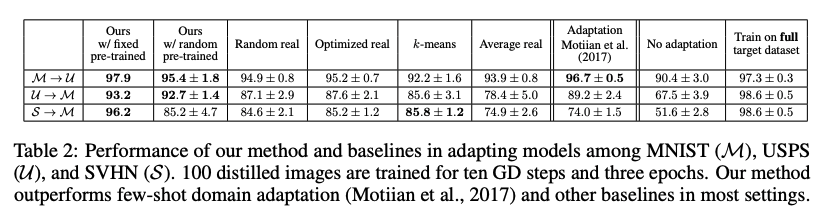
Fixed and random pre-trained weights on digits 3.5절에서 보였듯이, 우리는 새로운 데이터셋에 대해 사전 훈련된 모델을 빠르게 fine-tuning할 수 있도록 증류된 이미지를 최적화할 수 있다. 표2는 우리의 방법이 다른 baselines보다, 3개의 다른 숫자 데이터셋(MNIST, SVHN, USPS)을 서로 적용하는데 있어서, 더 효과적인 것을 보여준다. 우리는 또한 우리의 방법과 few-shot domain adaptation에서 sota를 비교했다. 우리의 방법은 전체 훈련 셋을 사용하여 증류된 이미지를 계산하지만, 두 방법 모두 동일한 수의 이미지를 사용하여 target 데이터셋의 지식을 증류한다. 과거의 업적은 모든 task에서 고정된 pre-trained weights를 쓴 우리의 방법에 압도되었다, 그리고 세 가지 task중 두 가지의 task가 random pre-trained weights를 쓴 우리의 방법에 압도되었다. 이 결과는 우리의 증류된 이미지가 target 데이터셋의 정보를 효과적으로 압축한다는 것을 보여준다.

Fixed pre-trained weights on ImageNet 표3에 보면, 우리는 널리 사용되는 ImageNet에 대해 pre-trained된 AlexNet을 적용해서 PASCAL-VOC와 CUB-200 데이터셋에 대해 이미지 분류를 진행했다. 카테고리당 하나의 증류된 이미지를 사용했을때, 우리의 방법은 baselines를 상당히 뛰어넘었다. 우리의 방법은 수천장의 이미지를 포함한 전체 데이터셋을 사용하여 fine-tune한 성능과 동등한 결과를 냈다.
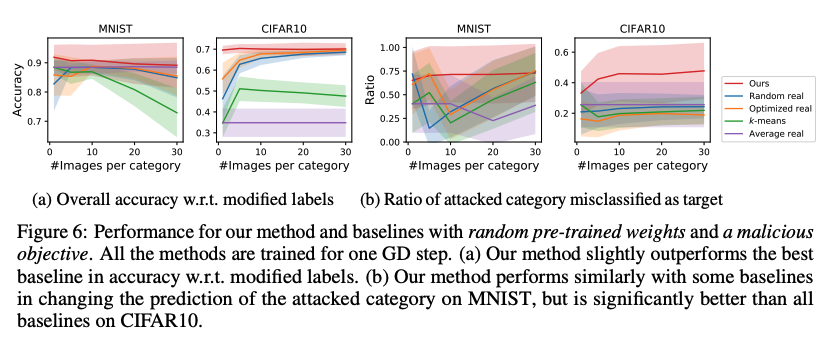
Random pre-trained weights and a malicious data-poisoning objective 3.6절은 우리의 방법이 새로운 형태의 데이터 중독을 구성할 수 있음을 보였다. 공격자는 잘 훈련된 모델을 조작하기 위해 소수의 악성 데이터로 단 하나의 경사 하강 단계만 거쳐 공격할 수 있다. 우리는 잘 최적화된 신경망이, 공격받은 카테고리를 다른 카테고리로 잘못 분류하도록 증류 이미지를 훈련할 수 있다(단 한번의 경사 하강 단계로도). 우리의 방법은 모델의 정확한 가중치에 대한 접근이 필요하지 않다. 그림 6b에서, 우리는 우리의 방법을 200개의 교차검증 모델에 대해서, 실제 이미지와 잘못된 레이블에서 파생된 데이터를 사용해서 다양한 baselines와 평가했다. baselines에서는 한번의 경사 하강 단계와 같은 수의 이미지, 수정된 레이블을 사용했고(공격받은 카테고리의 이미지는 target 카테고리로 레이블 되었다), 가장 높은 전체 정확도를 보고했다(정확도는 수정된 레이블이 공격받은 카테고리를 타겟 카테고리로 여전히 10% 이상 오분류 할 경우이다). 반면에 몇 baselines는 MNIST에서 우리의 방법과 비슷한 성능을 냈고, CIFAR10에서는 우리의 방법의 성능이 baselines를 월등히 뛰어넘었다.
5. Discussion
이 논문에서는, 전체 훈련 데이터의 지식을 작은 합성 훈련 이미지들에 압축하는 dataset distillaion 방법을 제안했다. 우리는 적은 수의 증류된 이미지와 소수의 경사하강 단계로 네트워크의 최대 성능을 달성하도록 훈련할 수 있다. 마침내, 우리는 pre-trained model을 새로운 데이터셋에 적용하는 것과 악성 데이터 중독 공격으로서의 기능의 두 가지 확장된 설정을 설명했다. 미래에는, ImageNet과 같은 큰 규모의 visual dataset들이나 오디오, 텍스트와 같은 다른 타입의 데이터를 압축할 계획이다. 또한, 우리의 방법은 현재 초기화의 분포에 민감한 편이다. 어떤 dataset distillaion이든 잘 동작하도록, 우리는 다른 초기화 전략을 연구할 것이다.
논문 출처 : https://arxiv.org/pdf/1811.10959.pdf
Dataset Distillation에 대한 논문 번역입니다.
잘못된 내용이 있다면 댓글로 남겨주세요. 감사합니다 :)
