Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors(TCAV) Review
Paper_Review
Abstract
Traditional Convolutional Neural Network operate on low-level features. The problem is that low-level features are not human friendly. To handel these problem, author suggest Concept Activation Vectors and Testings with s method.
Introduction
Most ML models operate on low-level features, such as pixel values, that do not correspond to high-level concepts that humans easily understood. Also, a model's internal values, such as neural activations, can seem incomprehensible. To handle these problem, author first express this problem as a mathematically. Machine Learning model's vector space is denoted spanned by basis vector . And Human's understandable vector space is denotted as spanned by basis vector . From this point, an "interpretation" of an ML model can be seen as function
This paper show us new concept : as a way of translating beetween and . In other words, is that make low-level features to human understandable concepts. After generating s, then check that how such image much using for prediction. This method called Testing with Concept Activation Vectors. was pursed with the following goals.
: Requires little to no ML expertise of user.
: Adapts to any concept ans is not limited to concepts considered during training.
: Works without any retraining or modification of the ML model.
: Can interpret entire classes or sets of examples with a single quantiatative measure, and not just explain individual data inputs.
Backgrounds
There are two ways to interpret deep neural networks. First is only use interpretable models. And second is post-process our models in way that yields insights. With increasing demands for more explainable ML, there is an growing need for methods that can be applied without retraining or modifying the network. is capable of interpreting networks without modifying them.
Saliency methods are one of the most popular local explanation methods for image classification. However, Saliency map method shows limitation when compare two diffrent sailency maps. If one of cat image shows cat's ear much brighter then other picture, could we assess how important the ears were in the prediction of "cats"?
Linear combinations of neurons include meaningful and insightful information. extends this idea and computes directional derivatives along these learned directions in order to gather the importance of each direction for a model's prediction.
Methods
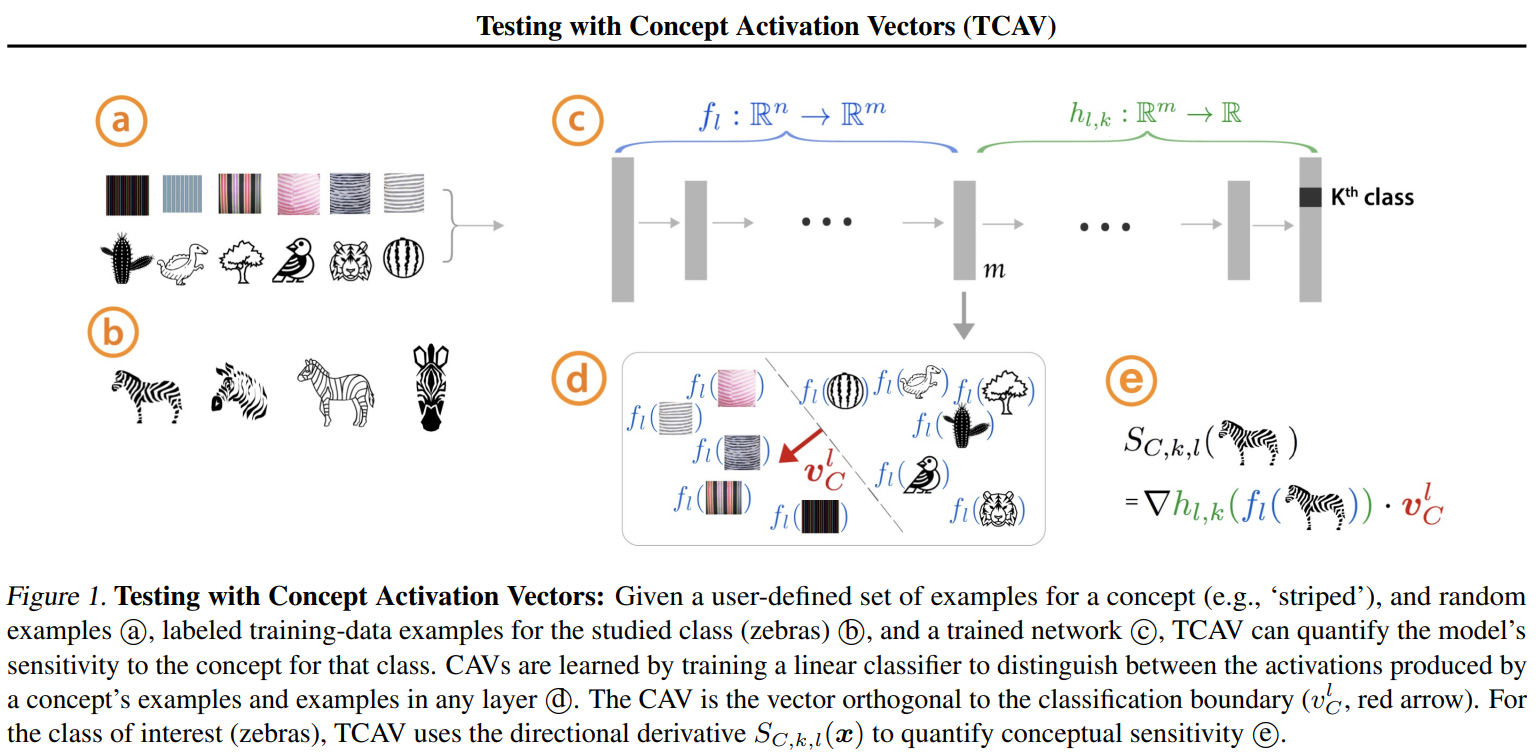
In order to understand the method, a concept that users can understand must be defined first. As a concept, edge information such as color or texture of an image can be used. For example, when analyzing a picture of a zebra, we can use the concept of stripes. A set of data that conforms to a specific concept is called . And the set of random data different from the concept is called .
In order to separate these two concepts for a specific network, the distribution of vectors of and should be divided in the th layer. Learn a linear classifier that divides the distribution of these two vectors, and define a direction orthogonal to the linear classifier as . Here, the orthogonal direction defines the direction of as the positive direction of the linear classifier.
Through the above process, the vector that classifies the specific concept we are interested in can be obtained.
The new linear interpretation method using presented here is called (Testing with Conceptual Activation Vector). calculates the prediction sensitivity of the model for the defined concept using the directional derivative.
The saliency map method calculates the effect of each pixel point on logit and uses the following formula.
Similarly, Conceptual Sensitivity through is obtained as follows.
Through the dot product between and obtained after passing the input image through the network, between the concept and the input image k}(x)$ can be found.
And when obtained in this way is 'striped' and class is 'zebra', is the entire input image related to class . After finding for all the related images, the total can be obtained with a positive value over 0.
If the ratio of Conceptual Sensitivity data related to concept is obtained from this data, the global influence of concept on the label can be calculated.
Results

We can classify images by concept using and cosine similarity. In Figure 2 above, the concept of "Stripes" is classified using learned with the concept of "CEO". If you check the picture, you can see that the most similar striped images have patterns suitable for the suit or tie that the CEO will use, and the least similar striped images have patterns that are unlikely to match the CEO.
The right side is the result of classifying "Necktie" using trained as "Model Women". Again, it can be seen that a woman wearing a tie appears in the most similar necktie images, and a man wearing a tie appears in the least similar images.

You can also use to check your Empirical Deepdream. Empirical Deepdream is a method of optimizing the pattern that activates as much as possible and comparing it with the semantic concept of the concept. In Figure 3 above, the first image is "Knitted Texture", the second image is "Corgis", and the last image is Deepdream using "Siberian Huskey". From the above figures, it can be seen that can define and visualize features or patterns within an image.
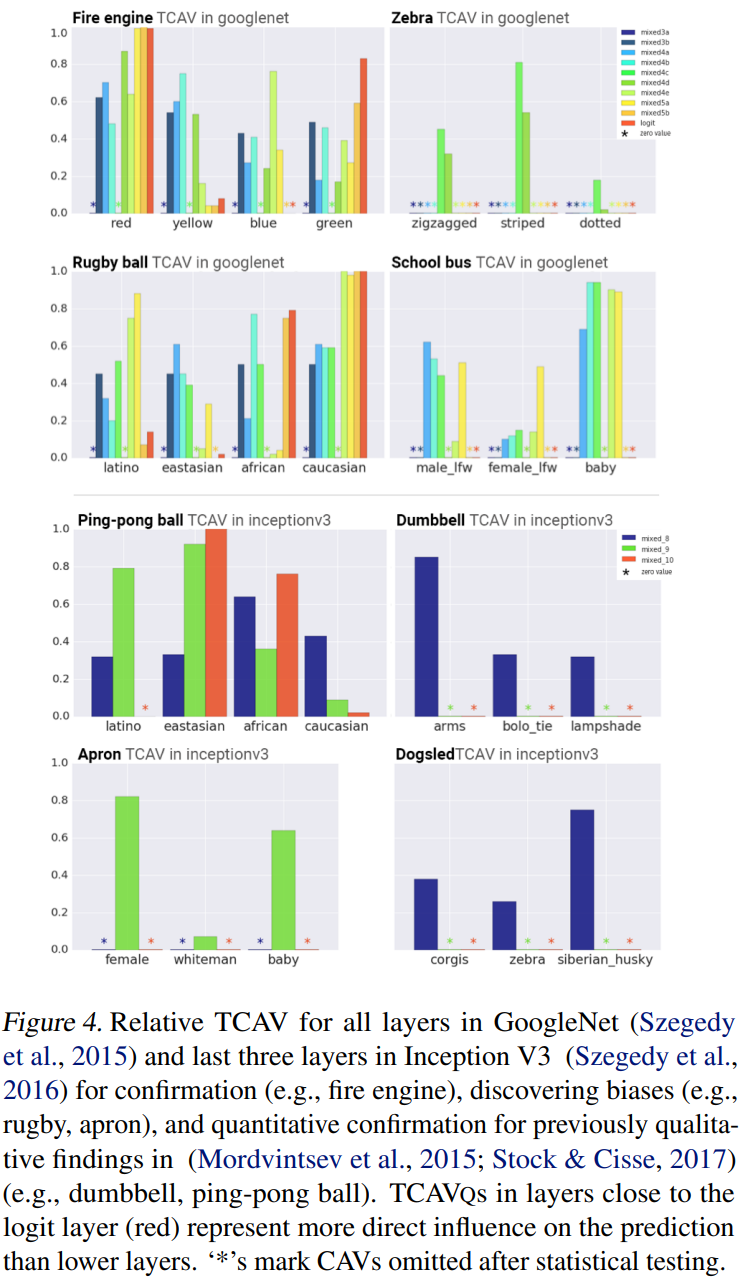
confirms that the results we thought are important. For example, when considering a fire engine, it can be confirmed that the expected result and the actual result that red is likely to act as an important cup concept are the same. not only obtains a relative value for each concept, but also shows a result that is sensitive to gender and race even without explicit training. If you look at the ping-pong ball in the picture above, you can see that the eastasian has a higher value than the african or latino. It can also be seen that Apron has a higher value in women than in Caucasians or babies.
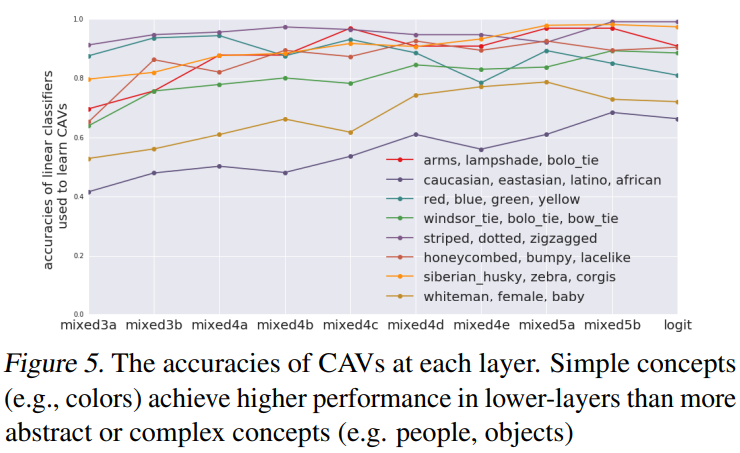
Figure 5 is a graph organized about which layer each concept is well learned. It can be seen that high level concepts are learned well in the rear layer, and low level concepts such as colors and patterns are learned well in the front layer.
Conclusion
Using a new concept called , , which calculates how much influence the concept has on predicting the model's results, numerically tells the result of how well the appropriate domain concept was selected. The method can be considered to have adequate interpretability as it provides an explanation that is convincing enough even for people who have not majored in artificial intelligence.
Own Review
This paper presented a new concept to explain what part of the model's prediction process is based on which prediction is made. I think this is a very well-written thesis in that it expands new concepts with appropriate logic and allows for quantitative calculation of ambiguous concepts. In addition, this paper demonstrated the validity of the logic by presenting appropriate experimental results to support the logic. Personally, I was most impressed with the way the logic was developed so that the reader could fully understand it using the concept of .
References
[1] Been Kim, Martin Wattenberg, Justin Glimer, Carrie Cai, James Wexler, Fernanda Viegas and Rory Sayres. Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors(TCAV)
