Neural Architecture Search는 지금껏 사람이 직접 Heuristic하게 디자인 해 왔던 네트워크의 구조를 사람이 아닌 기계가 스스로 학습을 통해서 찾아내는 알고리즘을 말합니다. NAS는 네트워크를 이루는 각 구성 요소들을 다양한 조합으로 섞어 최적의 네트워크를 찾아내야 하는데, 이 과정에서 많은 훈련시간과 Computational Resource를 소모하게 됩니다. 따라서 적절한 알고리즘과 방법들을 통해서 높은 성능을 내는 방향으로 경우의 수를 줄여 가는것이 중요합니다.
최적의 성능을 내는 네트워크를 찾아가는 과정에는 강화학습을 사용한 방법, 진화의 요소를 사용하는 방법등이 있지만 해당 논문에서는 진화의 요소를 사용하는 방법을 소개합니다.
1. Binary Network Representation
먼저 네트워크 구조를 찾는데 유전적 진화의 과정을 사용하려면, 네트워크 구조를 임베딩 하는 과정이 필요합니다. 해당 논문에서는 binary string으로 네트워크를 표현했습니다. 또한 Sota의 성능을 보이는 모델들이 여러 Stage로 구성되어있음에서 착안해 각 Stage를 쌓아서 네트워크를 구성했습니다. 네트워크의 한 Stage가 개의 노드로 구성되어있다면, 상위 노드는 하위의 노드만 연결될 수 있다는 규칙에 의해 개의 경우의 수를 가지게 됩니다. 전체 binary string의 길이 은 전체 Stage 에 대해서 모든 경우의 수를 더해준 값이 됩니다. 즉 가 됩니다. 각 bit는 0과1로 표현될 수 있기에 최종적으로 네트워크의 경우의 수는 개가 됩니다.
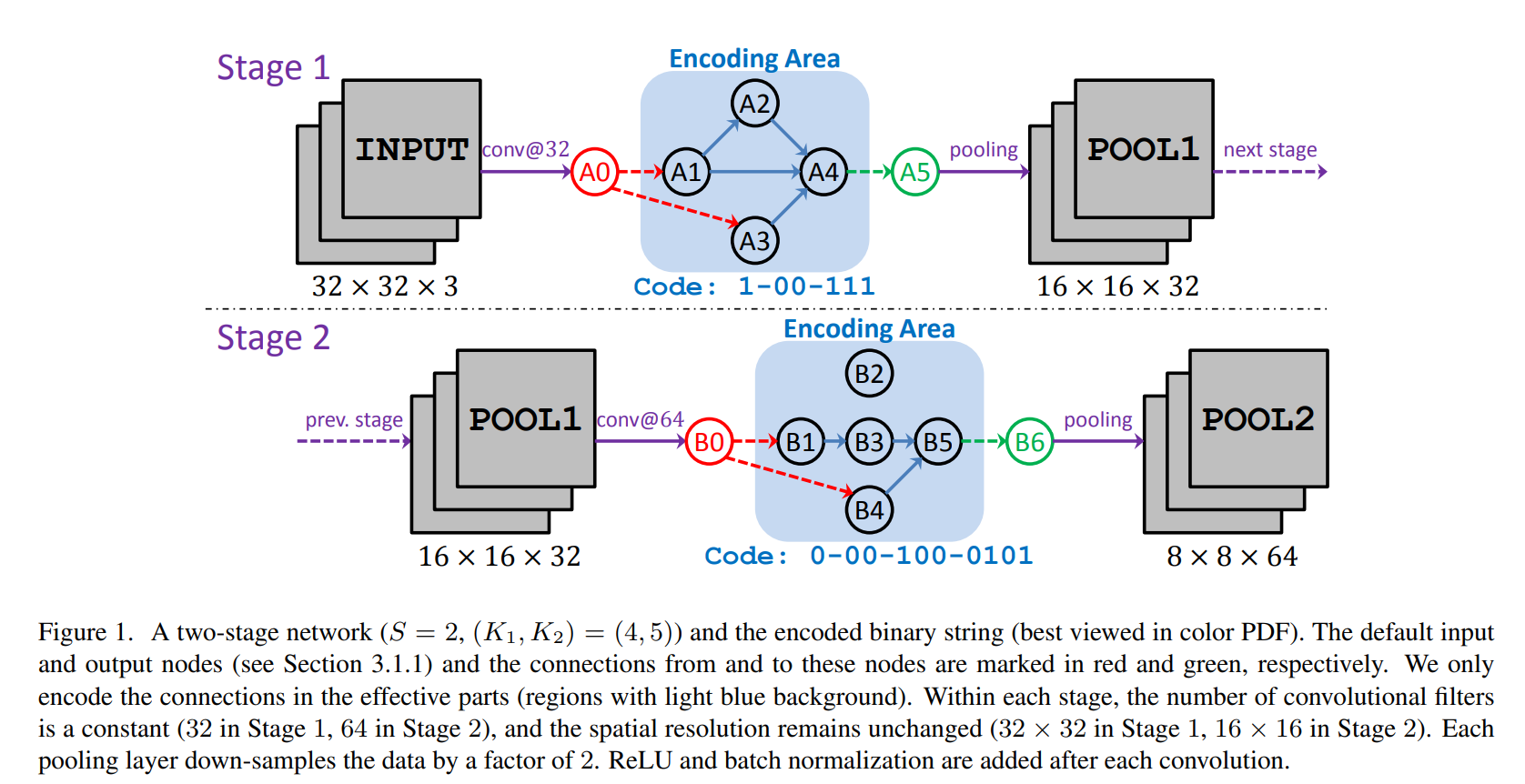
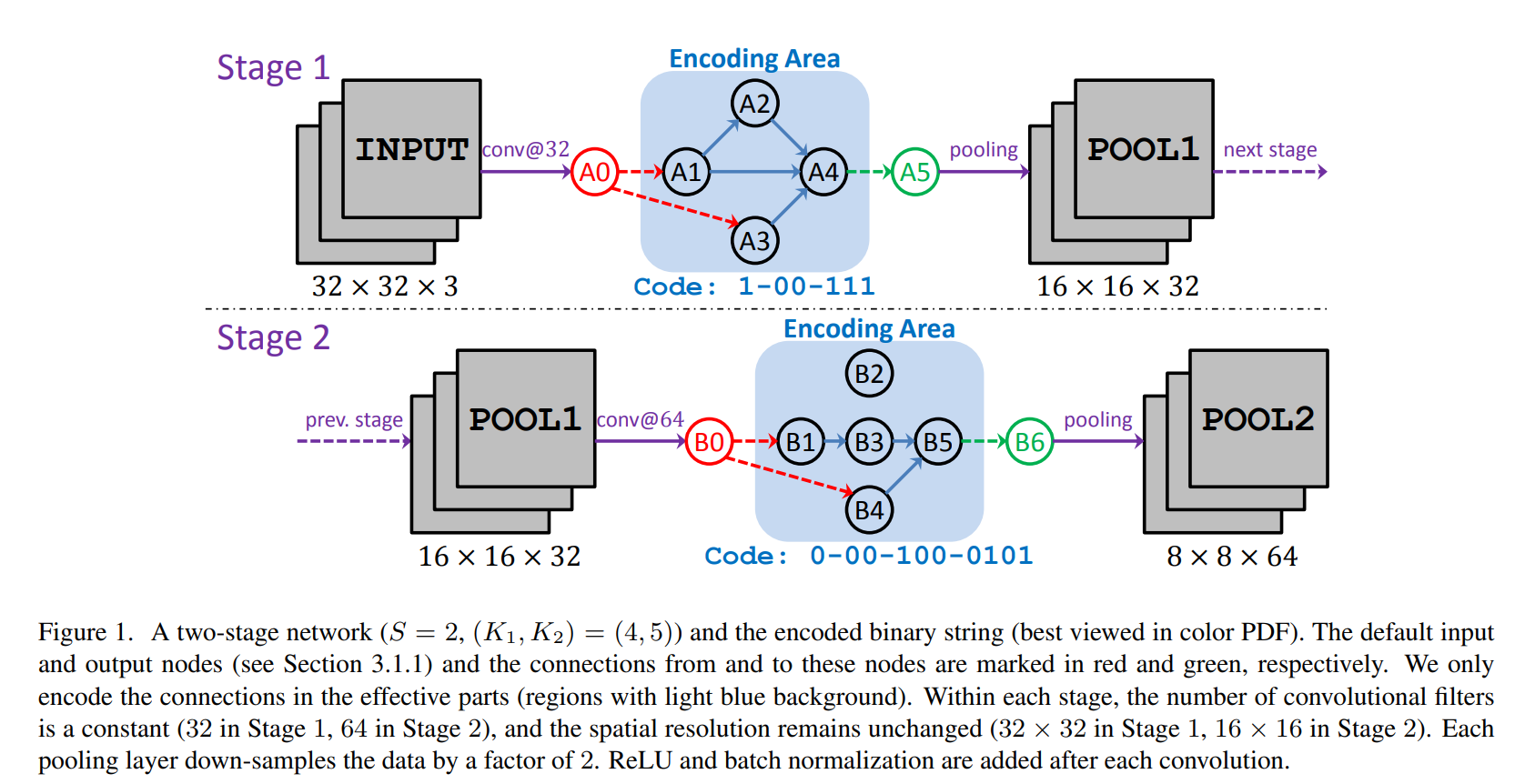
binary string으로 나타내는 규칙을 그림1을 통해서 살펴보도록 하겠습니다. 그림의 Stage-1에서 노드의 개수 는 4개입니다. 따라서 각 노드의 연결은 최대 3개까지 표현할 수 있습니다. A1 노드의 경우 하위 노드가 없으므로 binary string 표현에서 제외됩니다. A2 노드의 경우 A1으로부터 입력을 받기 때문에 1로 표기됩니다. A3 노드의 경우 A1, A2로부터의 입력이 없기 때문에 00으로 표현됩니다. 마지막 A4 노드의 경우 A1, A2, A3 모두로부터 입력을 받기에 111로 표현됩니다. 즉 현재 Stage를 binary string으로 나타내게 되면 1-00-111이 되는 것입니다. 그림에서 붉은색과 초록색으로 표시된 노드는 input node, output node로 binary string에서 제외 됩니다. 각 Stage에서는 Convolution Filter의 수는 고정됩니다. 그리고 각 Convolution 연산 이후에는 ReLU와 Batch Normalization이 진행됩니다.
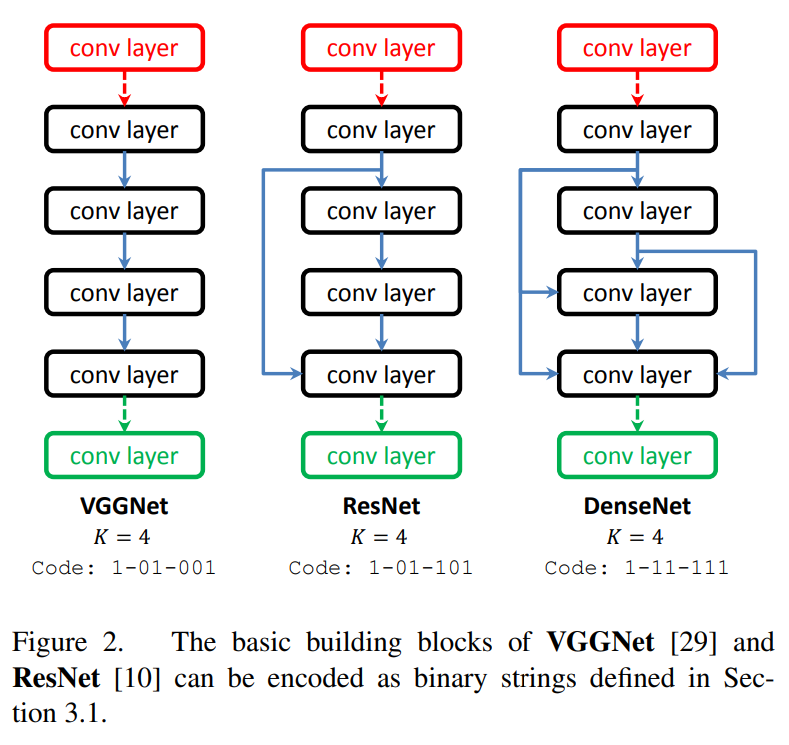
이 논문에서 제시한 binary string 방법으로 VGGNet, ResNet, DenseNet을 각각 표현한 것을 그림2에서 확인할 수 있습니다.
binary string 방법으로 네트워크를 표현하는 것은 한 Stage 내에서는 필터의 개수와 채널의 수가 같아야 하는 한계가 있습니다. 그래서 다양한 크기의 필터를 사용하는 inception module을 사용하는 GoogleNet과 같은 네트워크는 표현할 수 없습니다. 하지만 binary string 표현을 사용하면, 작은 데이터셋에 대해서 학습된 구조를 큰 데이터셋에 전이하여 학습하는 방법에 쉽게 적용할 수 있습니다.
2. Genetic Operations
유전 알고리즘은 selection, mutation, crossover의 동작을 통해 알고리즘은 진화시키는 방법입니다. 이 논문에서는 유전 알고리즘의 특징을 사용해서 수 많은 네트워크의 경우의 수 중 경쟁력 있는 네트워크를 찾아내는 방법을 사용합니다.

2-1. Initialization
먼저 랜덤한 모델의 집합 을 정의합니다. 각 모델은 비트의 binary string으로 표현되어 있습니다. 각 비트의 값은 베르누이 분포를 따라 독립적으로 샘플됩니다.
2-2. Selection
베르누이 분포를 따라서 초기화된 랜덤한 모델의 집합 을 세대를 거듭하며 발전, 진화 시키는 것이 유전 알고리즘의 핵심 방법입니다. 이를 위해서 먼저 이전 세대에서 좋은 성능을 보여주는 모델을 선택해야 합니다. 이전 세대의 모델의 집합 에서 각 모델의 정확도를 라고 했을 때, 다음 세대의 모델을 선택할 확률을 에 비례해서 샘플링 합니다. (는 이전 세대의 모델중 가장 낮은 정확도를 보인 모델을 뜻합니다.) 이렇게 하면 성능이 좋은 모델은 높은 확률로 샘플링 되게 되고, 가장 낮은 확률을 보여준 모델들은 제거되기 때문입니다. 위의 사항들을 적용하여 Roulette process를 사용해 샘플링을 진행합니다. 여기서 다음 세대 의 값은 유지합니다. 샘플링 과정에서 같은 모델이 여러번 샘플링 될 수 있습니다.
2-3. Mutation and Crossover
새롭게 뽑힌 -세대 모델 을 Crossover와 Mutation 과정을 통해 진화시킵니다. crossover 과정은 두 모델을 가져와 특정 부분을 치환하여 새로운 모델을 만들어 내는 방법입니다. 각 Stage별로(Stage별로 bit의 수가 같아야 하기 때문에) 치환확률 에 따라 Crossover를 진행합니다. 이때, 는 낮은 확률을 사용합니다. 낮은 확률을 사용하는 이유는 이전 세대에서 selection되어 뽑힌 지금의 세대의 모델들은 성능이 좋은 모델들인데 이 모델들을 가지고 다시 높은 비율로 모델을 섞게 되면 좋은 성능의 모델들의 장점이 사라질 수 있기 때문입니다.
마찬가지로 Mutation또한 낮은 확률 으로 진행합니다. Mutation은 각 모델의 bit들을 1의 값을 가지고 있으면 0, 0의 값을 가지고 있으면 1로 확률 에 따라 변환하는 과정입니다. 알고리즘 1에 따르면 Crossover가 진행되지 않은 각 모델들에 대해서 Mutation을 진행합니다.
2-4. Evaluation
유전 알고리즘을 통해서 진화하게 된 새로운 모델들 에 대해서 각 모델별로 평가하여 fitness function value 값을 구합니다. 사전에 정의된 데이터셋 에 대해서 scratch 부터 각 모델을 훈련하여 결과를 얻어냅니다. 평가 과정에서 기존에 평가했던 동일한 모델이 선택되더라도 평가를 진행하고, 모든 결과들에 대한 평균을 구합니다.
3. Results
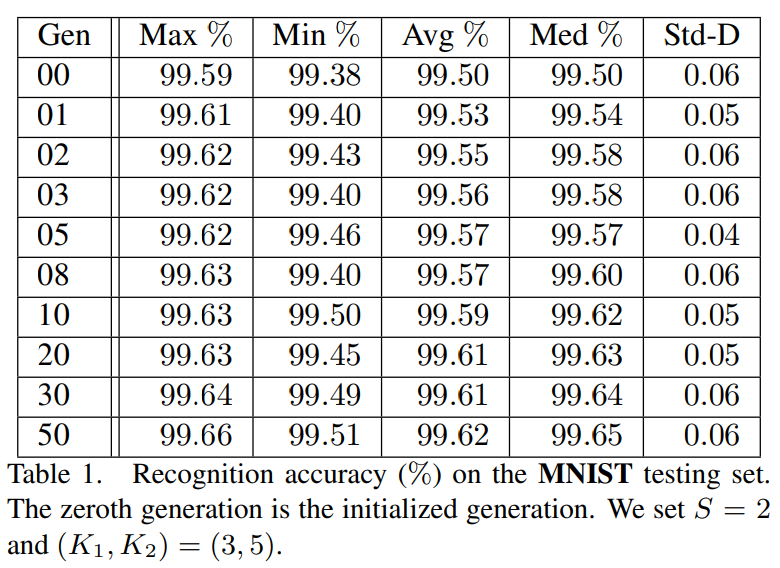
해당 논문에서는 위에서 제시한 Genetic CNN 방법을, LeNet의 구조에서 사용되는 convolutional layer, stride, kernel_size, learning_rate 등의 특징을 가져와 MNIST 데이터셋에 대해서 적용하여 실험을 진행했습니다. 세대를 거듭할 수록 Max, Min, Avg, Med의 정확도가 상승하는 모습을 확인할 수 있습니다.
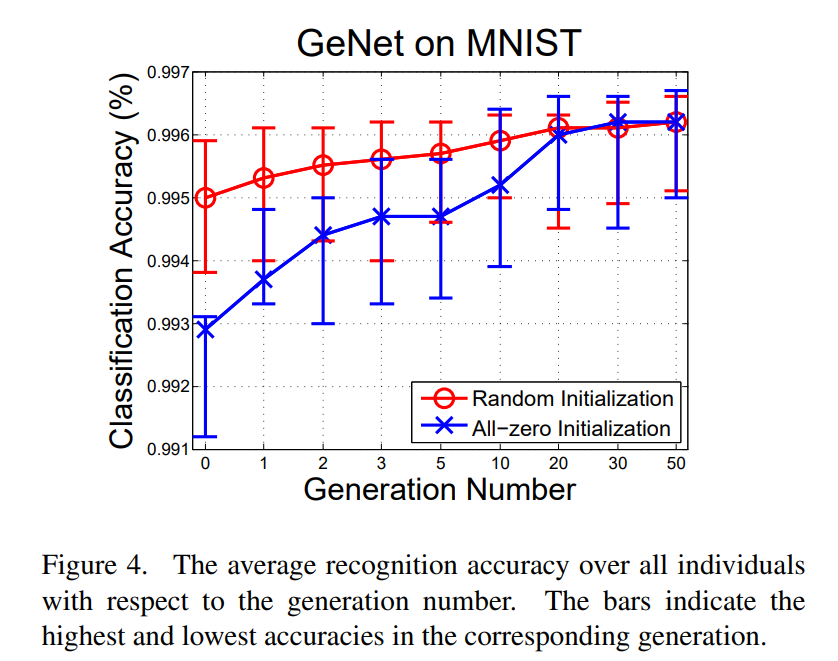
그림 4에서는 세대를 거듭할 수록 성능이 상승하는 모습을 확인할 수 있습니다. 또한 초기화의 과정에서 0으로 모든 값을 초기화 했을 때에도, 몇 세대를 걸치며 결국에는 랜덤 초기화를 진행한 것과 비슷한 성능까지 향상됨을 발견할 수 있었습니다.
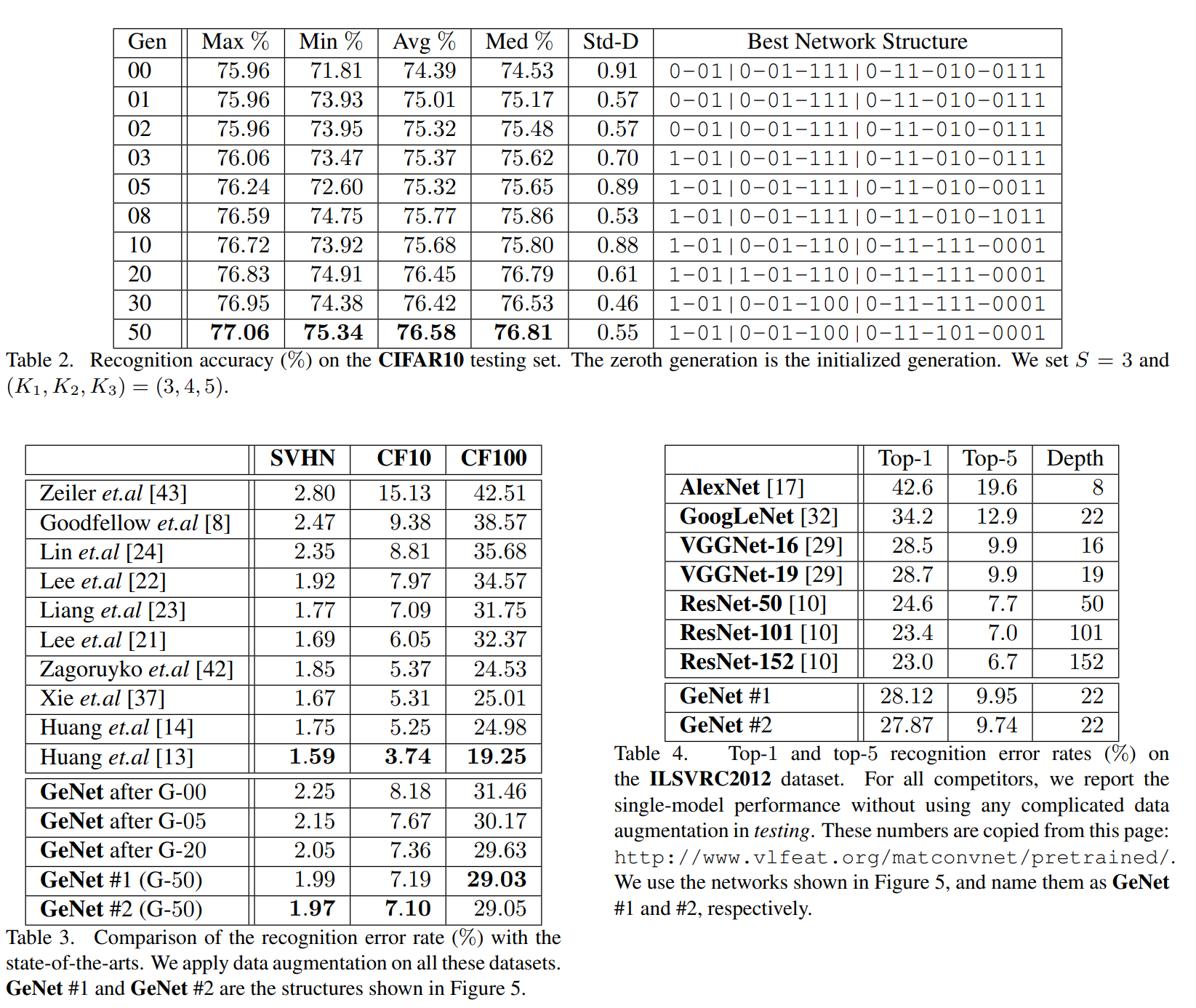
표2에서는 CIFAR-10에 대해서 3-Stage 구조를 가지고 최적의 네트워크를 찾아낸 결과를 확인할 수 있습니다. 표3에서는 GeNet으로 만들어낸 모델이 기존의 모델들과 비교해서 데이터셋별로 어느정도 성능을 보여주는지 비교한 내용들이 정리되어 있습니다. 표4에서는 CIFAR-10에서 훈련된 모델을 ImagNet으로 전이학습하여 나온 결과를 정리해 두었습니다.
4. Conclusion
유전 알고리즘을 CNN의 구조를 찾는데 사용하는 방법은 제법 잘 동작하는것 같습니다. 하지만, 고정된 크기의 convolutional filter를 써야하는 것이나 Maxout 같은 다양한 함수들을 사용할 수 없는 점은 분명한 한계인 것 같습니다. 개인적으로 유전 알고리즘을 적용하기 위한 방법을 고민하다가 네트워크 구조를 Binary String으로 Embedding 한다는 아이디어를 낸 것이 이 논문의 좋은 부분이라고 생각합니다.
논문 출처 : https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8237416
잘못된 내용이 있다면 댓글로 남겨주세요. 감사합니다 :)
