Abstract
트랜스포머 구조는 NLP(Natural Language Processing)에서는 표준으로 사용되어 왔지만, Computer Vision에서는 여전히 제한적으로 사용되고 있다. Vision 영역에서 Attention은 Convolutional Network와 같이 쓰이거나, network의 일부분을 대체하고 전체 구조는 유지하는 방식으로 사용되었지만, 이 논문에서는 트랜스포머 형태를 그대로 Vision에 적용하는 방법을 제시한다. 전통적인 CNN의 방법을 사용하지 않고도 대량의 데이터를 사용한 학습과 전이학습(Transfer Learning)에서 VIT(Vision Transformer)는 좋은 결과(SotA)를 보여준다.
Introduction
트랜스포머에서 사용되는 Self-attention 기법은 NLP 영역에서는 가장 범용적인 방법이 되었다. 트랜스포머는 주로 큰 corpus(자연어 훈련 데이터뭉치) 모델에 대해서 pre-train된 모델을 작은 task-specific dataset에 fine tuning해서 사용하는 방식으로 사용되고 있다. 또한 트랜스포머의 계산효율과 확장성 덕분에 거대한 사이즈(파라미터가 1000억이 넘는)의 모델의 훈련도 가능해졌다.
그러나 Vision 영역에서는 여전히 Convolutional 구조가 지배적이다. NLP에서의 트랜스포머의 성공을 보고 Vision 영역에서도 self-attention을 적용하려는 많은 시도들이 있었다. 그중 가장 나중에 나온 모델들은 이론적으로는 효율적이었으나, 하드웨어 가속을 사용하는데는 attention pattern으로 인해 어려움이 있었다. 그래서 여전히 SotA(State-of-the-Art) 모델은 여전히 CNN을 기반으로 하는 ResNet 기반의 모델이다.
이 논문의 저자는 트랜스포머의 확장성과 효율성의 특성을 그대로 사용하기 위해서 가능한 최소한의 수정을 통해 트랜스포머를 Computer Vision에 적용하려고 노력했다. 이 논문에서는 이미지를 패치(Paches)라는 사이즈로 잘게 잘라서 그것을 선형적으로 임베딩(Linear embedings) 한 다음 트랜스포머의 입력으로 주는 방법을 사용한다. 여기서 패치는 NLP에서의 토큰과 같이 여겨진다.
실험 결과 ImageNet과 같은 mid-size 데이터셋에 대해서는 VIT모델의 성능이 ResNet모델들보다 성능이 낮게 나왔다. 이를 통해 트랜스포머는 CNN이 구조상으로 가지게되는 translation equivalance와 locality등의 inductive bias가 부족해서 충분하지 않은 데이터에 대해서는 기존 CNN모델보다 성능이 낮게 나온다는 사실을 알 수 있다.
여기서 inductive bias란 CNN에서 convolution filter를 사용함으로써 얻게 되는 지역성(인접한 픽셀끼리의 연관성)이나 convolution 특성상 픽셀의 위치가 이동해도 결과가 달라지지 않는 Translation invariance 그리고 RNN에서 순차적으로 시퀀스가 들어오면서 얻게되는 순차성 등을 의미한다.
반면에 JFT-300M dataset과 같이 거대한 데이터셋을 사용하거나, 충분히 큰 모델로 pre-train된 모델을 전이해서 small dataset에 사용하는 Transfer learning에서 SotA의 성능을 보여주었다.
Related Work
트랜스포머는 NLP영역에서는 표준으로 자리잡아 이후에 BERT와 GPT등으로 발전하게 되었다.
self-attention을 이미지에 적용하는 가장 순수한 방법은 모든 픽셀마다 전체의 픽셀을 attention 하는 방법이다. 하지만 이 방법은 전체 픽셀의 수에 quadratic한 계산량을 발생시키고 실제 이미지를 적용해서 사용하기엔 현실적이지 않다. 그래서 몇가지 비슷한 접근 방법으로 이를 해결하려고 시도했다. image Transformer는 전체 픽셀에 대해서 attention을 하는 대신 Query Block을 지정하여 근처에 있는 neighborhood한 픽셀에 대해서 attention을 진행하는 방법을 사용한다. 전체에 대해서 attention을 진행하지 않으므로 계산량을 줄일 수 있는 장점이 있다. (출처 : https://arxiv.org/pdf/1802.05751.pdf)
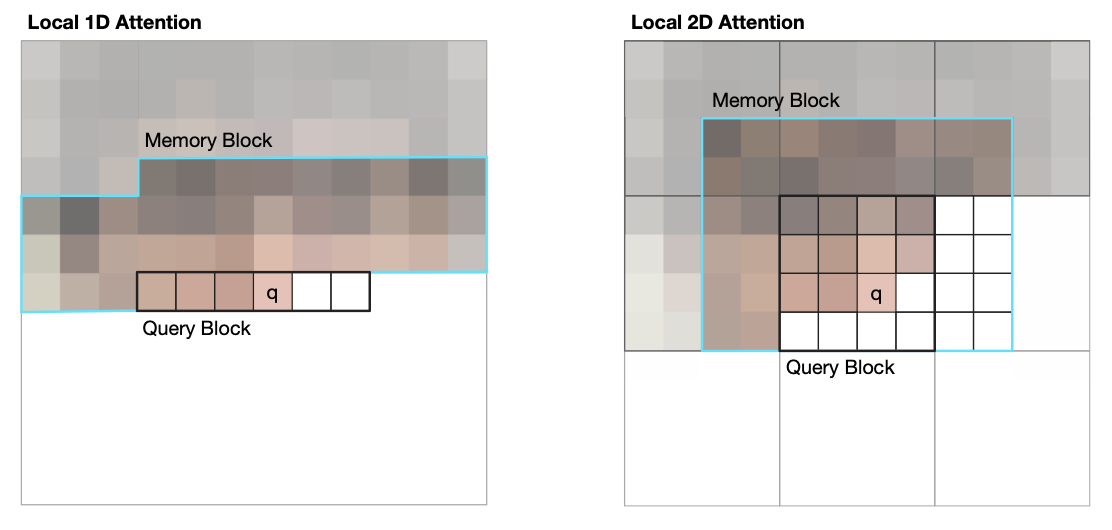
Sparse Transformer는 Global self-attention을 scalable하게 approximation하는 방법으로 계산량을 줄인다. Fully self-attention 대신에 Factorized self-attention을 사용한다. (출처 : https://arxiv.org/pdf/1904.10509.pdf)

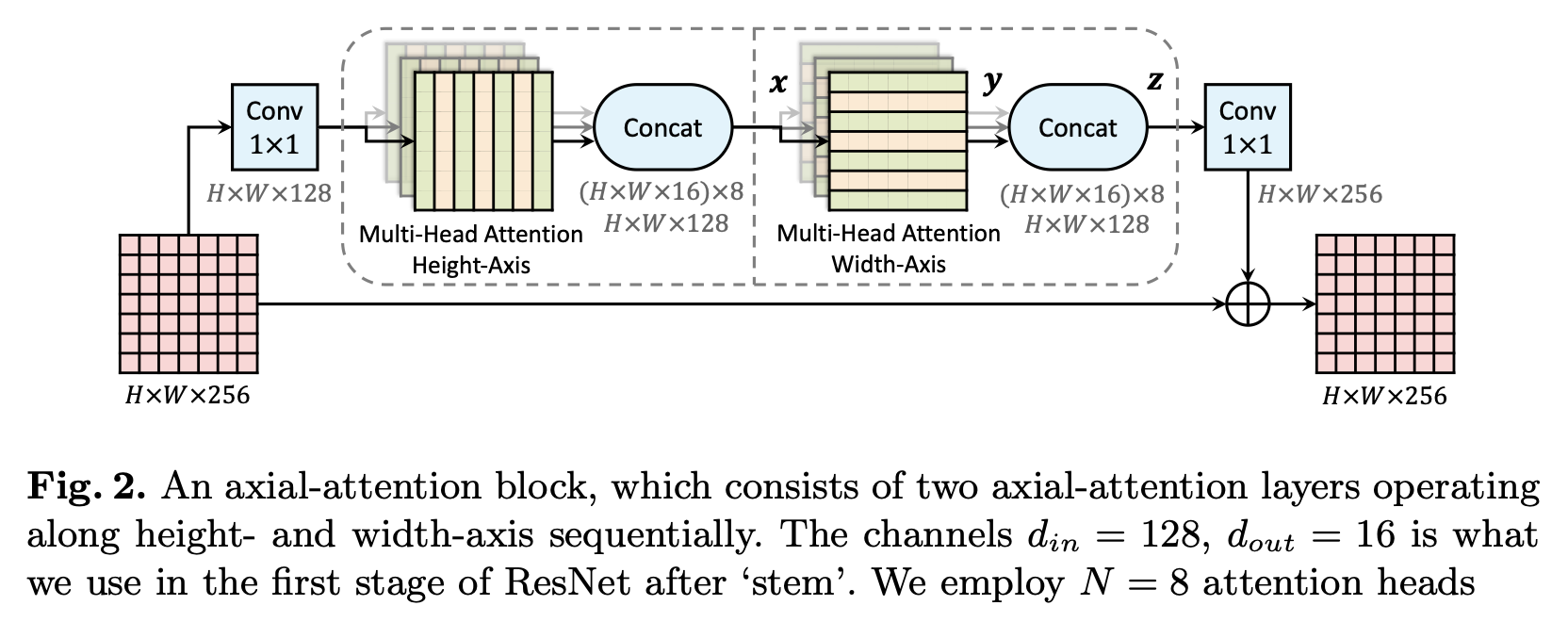
Axial-DeepLab 논문에서는 각 축 별로 self-attention을 취해서 concat하는 방법을 사용하기도 했다. (출처 : https://arxiv.org/pdf/2003.07853.pdf)
위의 여러 접근방법의 시도들에도 불구하고, 위의 방법들은 하드웨어 가속을 위해서 복잡한 엔지니어링이 필요하다.
논문에서 소개할 모델과 가장 비슷한 모델은 iGPT 모델이다. iGPT 모델은 이미지의 크기(해상도)와 color space를 줄인 뒤 트랜스포머에 입력되고, 비지도 방식의 generative model로 훈련된다. 그로부터 얻어진 representation을 사용해 fine-tuning을 하여 분류기로 사용할 수 있고, 이는 ImageNet에서 72%의 최대 정확도를 달성했다. (출처 : https://openai.com/blog/image-gpt/)

Method
논문의 저자는 트랜스포머가 가진 확장성과 효율성을 최대한 사용하기 위하여 의도적으로 NLP의 트랜스포머의 폼을 그대로 사용하려고 노력했다고 한다.
Vision Transformer(VIT)
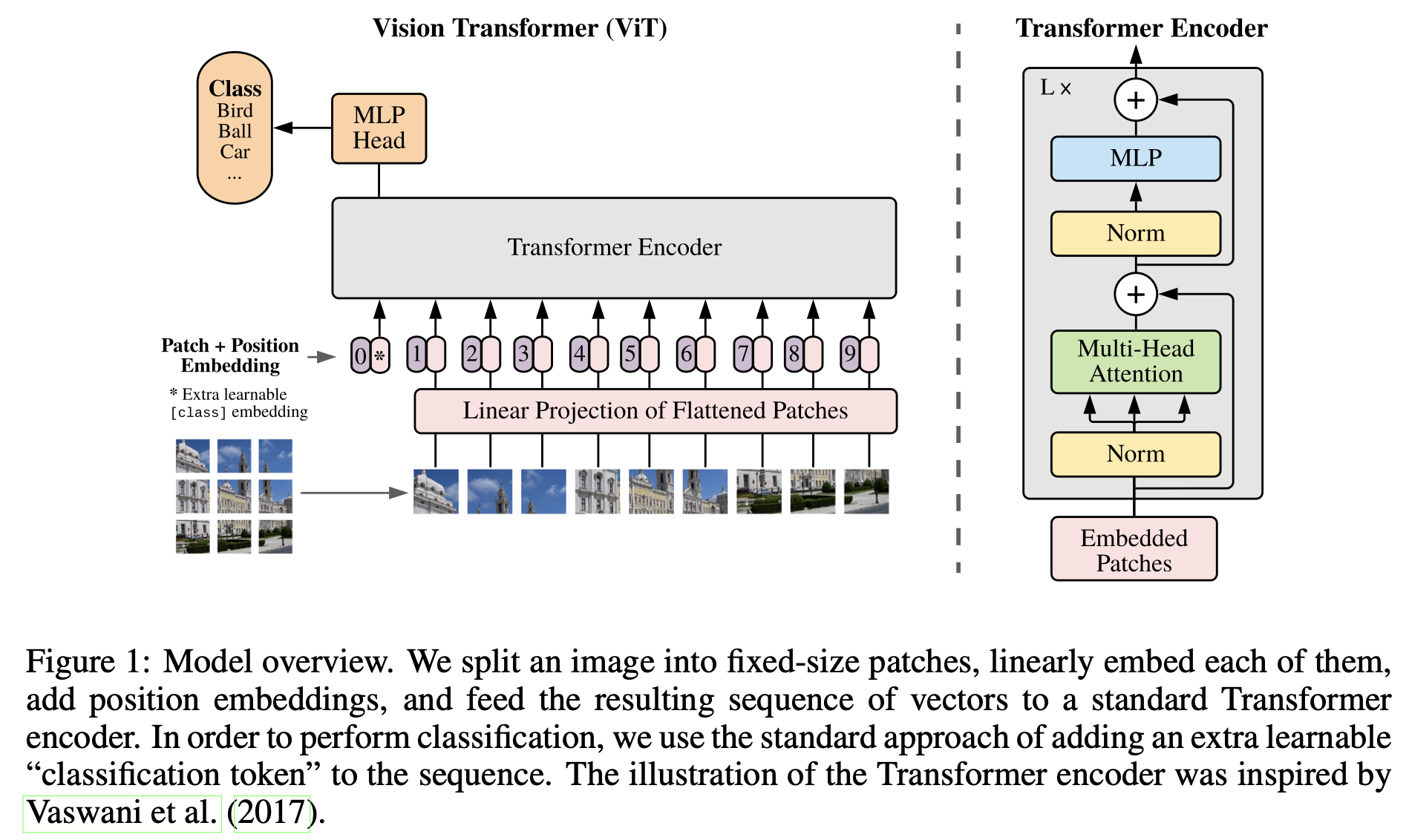
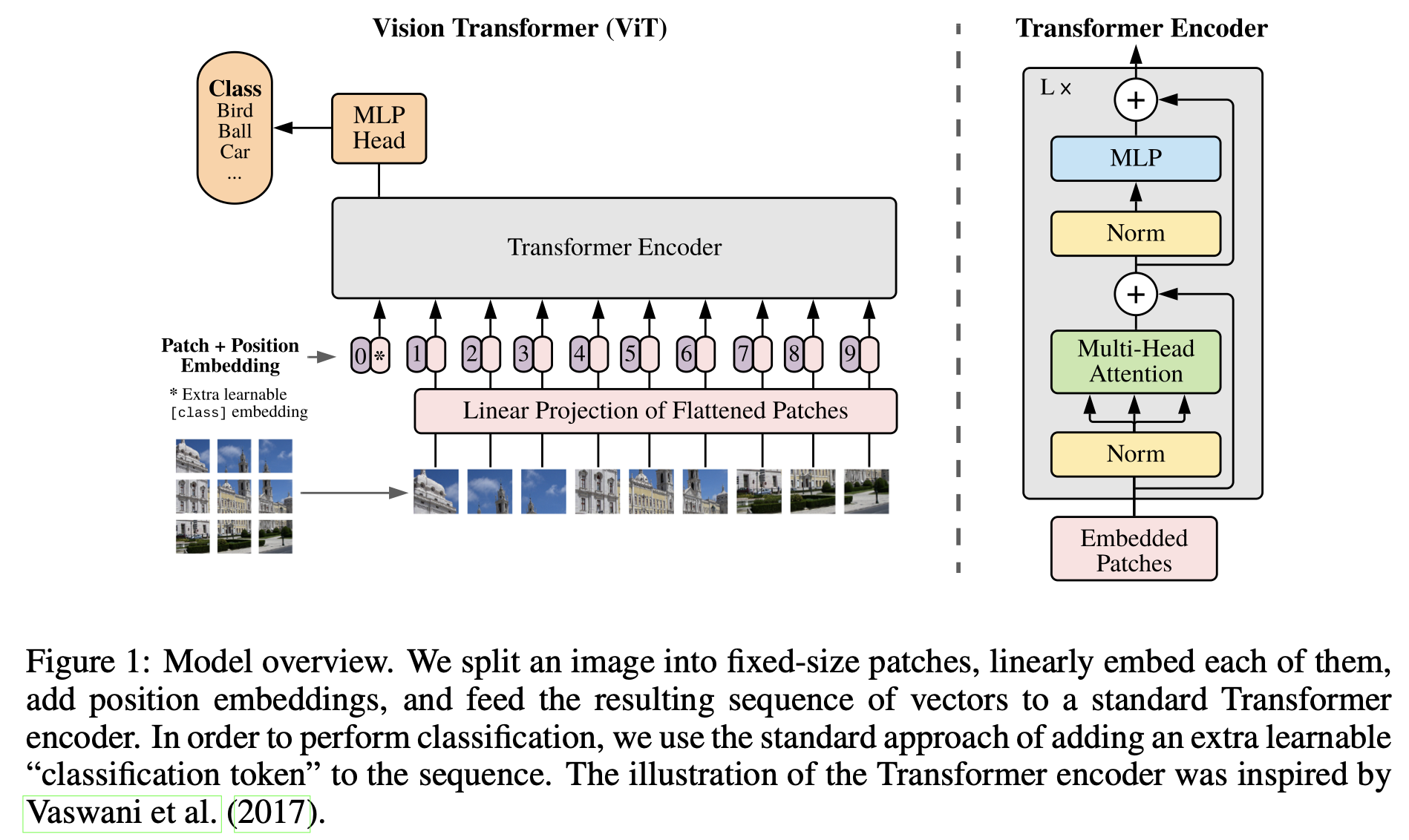
위의 그림 1 에는 전체적인 VIT의 구조가 나와있다. 2차원 이미지를 트랜스포머의 입력으로 넣기 위해서는 먼저 형태를 변형해야한다. 원본 이미지를 작은 패치의 단위로 나눈뒤에 각 패치들에 대해 Linear projection을 진행한다. 그리고 Positional Embedding의 값을 더해 트랜스포머의 입력으로 넣어준다는 것이 전체 프로세스이다. 학습 방식으로는 지도학습 방식을 사용한다.
트랜스포머는 전체적으로 D차원 벡터를 사용하기 때문에, 훈련가능한 Linear projection을 통해 패치들을 D차원으로 맵핑 시켜주는 patch embeddings를 진행한다. 임베딩 된 패치들의 맨 앞에는 학습 가능한 class 토큰 임베딩 벡터를 추가하였는데, 이 임베딩 벡터는 트랜스포머를 거쳐 나왔을 때, 이미지에 대한 1차원 representation vector로써 사용된다(즉 class token은 패치가 아닌 전체 이미지에 대한 Embedding 값을 가짐). 그리고 최종적으로 classification 헤드가 부착된다.
포지션 임베딩 값은 패치 임베딩 값과 합쳐져서 트랜스포머에 위치 정보를 전달하는 역할을 한다. 위 논문에서는 1D 포지션 임베딩을 한 결과와 2D 포지션 임베딩을 한 결과의 성능의 차이가 유의미하지 않아서 1D 포지션 임베딩법을 사용했다.
트랜스포머 인코더는 MultiHeaded Self-Attention(MSA)와 Multi Layer Perceptron(MLP)블럭으로 구성되어 있다. Layernorm(LN)과 Residual Connections이 매 블럭마다 적용되어 있어서 깊은 레이어에서도 학습이 잘 되도록 했다.

Hybrid Architecture는 raw image patches를 대신하여 CNN을 거쳐서 나온 feature map을 Sequence input으로 사용하는 방법이다. 이 경우 식에서 나온 E는 feature map을 projection한다.
Fine-tuning and Higher Resolution
전형적으로 VIT는 큰 데이터셋에 대해서 pre-train을 진행한 뒤 작은 downstream task에 fine-tuning 해서 사용하는데, 그러기 위해서는 pre-trained prediction head를 제거하고 그 자리에 0으로 초기화된 D X K(K = downstream class) feedforward layer를 추가한다. fine-tuning시 pre-training 데이터보다 더 높은 해상도의 데이터를 사용하면 종종 더 좋은 결과를 얻을 수 있다. 높은 해상도의 데이터를 전송할 때, 패치 사이즈는 유지하고 input Sequence의 길이 N을 늘리는 방향으로 실험했다. 그러나, 이 결과로 pre-train 된 position embedding이 의미없어 지는데, 이를 해결하고자 2D interpolation을 적용한다. 해상도 조절과 2D interpolation을 쓰는 과정은 image의 2D 구조에 대한 inductive bias가 적용되는 유일한 지점이다(VIT 에서).
Experiment
위 논문에서는 각 ResNet, VIT, hybrid 모델에 대해서 표현 학습 수용력을 평가했다. 결과적으로 VIT 모델이 기존의 SotA recognition benchmarks 모델들에 비해 적은 computational resource를 사용하면서 더 높은 성능을 달성했다.
Setup
모델의 확장성을 검증하기 위해서, ImageNet 1k class(1.3M images), ImageNet 21k(14M images), JFT(303M images)같은 이미지 수가 가각 다른 데이터셋으로 pre-train을 진행 하였다. 그런 다음 downstream task에 대해서 얼마나 잘 전이하여 학습하는지 benchmark 하기 위해 ImageNet, ImageNet-ReaL, CIFAR-10/100, Oxford-IIIT Pets, Oxford Flowers-102 같은 데이터셋을 사용하였다.
또한 19-task VTAB classification suite에 대해서도 평가했는데, VTAB은 각 task당 1000개의 training examples를 사용하여 적은 데이터를 다양한 task에 전이한 성능을 평가하는 방법이다. 각 task는 크게 Natural, Specialized, Structured의 세 그룹으로 나뉘어 있다. Natural은 흔히 접할 수 있는 데이터 imagNet, Cifar등의 데이터이다. Specialized는 의학, 위성사진 등의 특수 분야의 데이터이다. Structured는 최적화를 위한 위치정보의 데이터 같은 구조에 대한 데이터로 이루어져 있다.
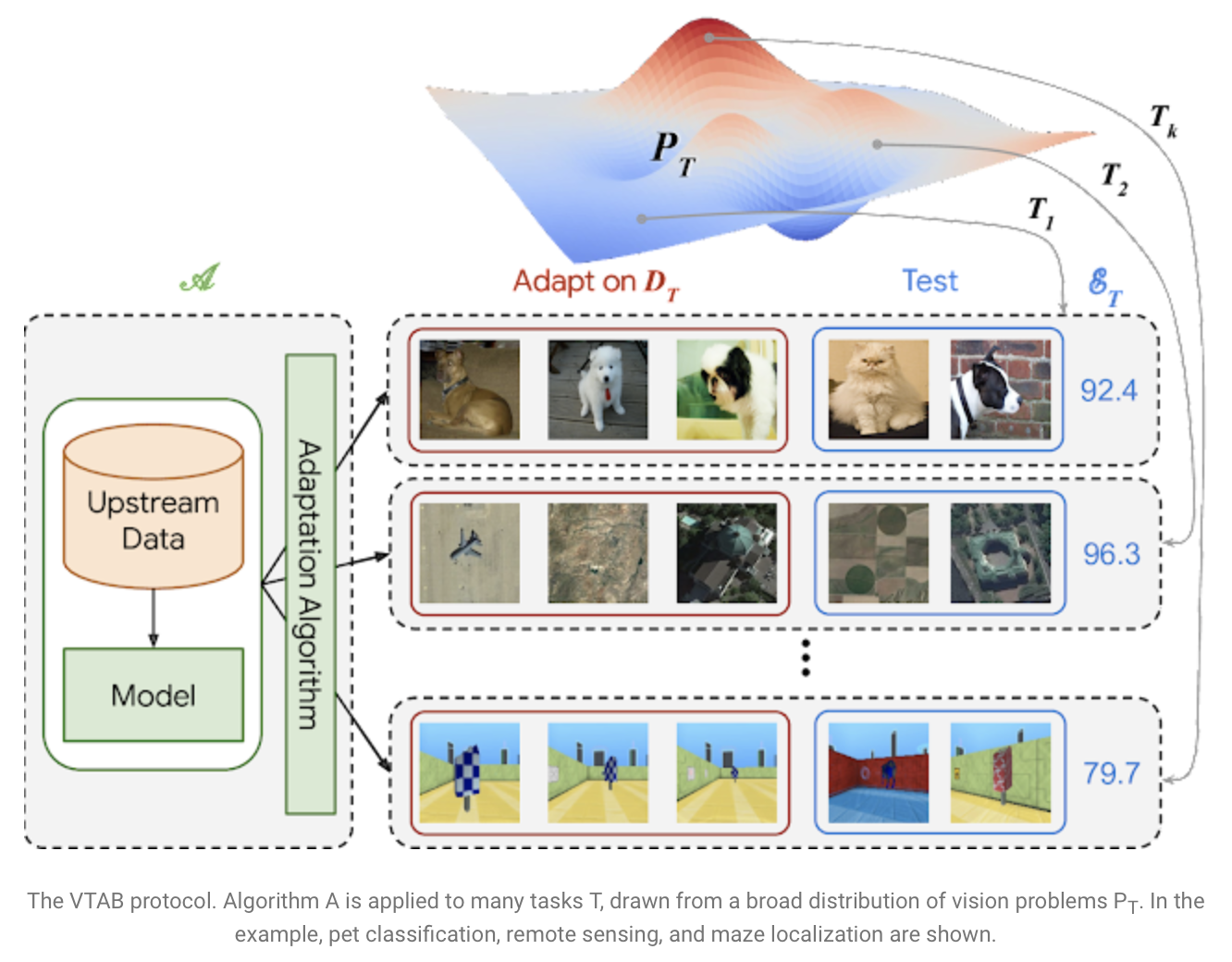
(출처 : https://ai.googleblog.com/2019/11/the-visual-task-adaptation-benchmark.html)
Model Variants

ViT-L/16 은 16*16 패치를 사용하는 Large 모델이라는 뜻이다. 트랜스포머의 시퀀스 길이는 패치 사이즈의 제곱에 반비례 하므로, 패치 사이즈가 작은 모델일 수록 계산량이 많아진다.
CNN구조의 베이스 라인으로는 Batch Normalization layer를 Group Normalization으로 바꾼 ResNet 모델을 사용한다. 이 변형은 전이학습을 더 잘 이루어지게 해준다. 논문에서는 이 수정된 모델을 "ResNet(BiT)"로 표기한다. 하이브리드 모델에서는 CNN의 중간지점에서의 feature maps을 ViT의 패치로 넣어준다.
Training & Fine-tuning
훈련시 옵티마이저로는 Adam(𝞫1=0.9, 𝞫2=0.999)을 사용했다. 배치 사이즈는 4096으로 두었고, weight decay(0.1)을 적용하면 전이학습에 도움을 주는것을 발견했다. pre-train시 Adam이 SGD보다 나은 성능을 보여서 Adam을 사용하였고, fine-tuning시에는 SGD with momentum을 사용하였다. Linear learning rate warmup and decay 방법도 같이 사용하였다.
Metrics
논문에서는 downstream dataset에 대한 결과를 fine-tuning accuracy와 few-shot accuracy로 평가했다. 대부분의 경우에 fine-tuning accuracy로 평가했고, fine-tuning acc를 구하는 것이 시간이 오래 걸리거나, Computational Resource를 많이 사용할 때 비교적 간단히 구할 수 있는 few-shot acc를 사용했다.
few-shot learning 이란? 데이터 수가 매우 적은 문제를 해결하는 방법이다. 데이터셋을 훈련에 사용하는 서포트 데이터(support data)와 테스트에 사용하는 쿼리 데이터(query data)로 구성된다. 이런 퓨샷 러닝 테스크를 'N-way K-shot 문제' 라고 부른다. N은 범주의 수, K는 범주별 서포트 데이터의 수를 의미한다.
few-shot accuracy는 few-shot learning과 구체적인 내용은 다르지만, 적은 데이터를 사용해서 결과를 예측한다는 측면에서 비슷한 의미를 가진다.
(출처: https://www.kakaobrain.com/blog/106)

Comparison to State of the Art
논문에서는 Vit-H/14, Vit-L/16 모델과 비교할 대상으로 Big Transfer(BiT)와 Noisy Student 모델을 삼았다. BiT 모델은 지도 전이학습 방식으로 훈련된 큰 ResNet 모델이다. Noisy Student는 큰 EfficientNet을 imageNet과 JFT-300M에 대해서 준 지도 학습 방식으로 훈련한 모델이다. 위 두 모델은 논문이 나올 당시의 SotA 모델이다.

표의 결과를 보면, ViT-H/14 모델이 기존의 SotA 모델들에 비해 적은 computational resource를 사용하면서도 더 높은 정확도를 보여줌을 확인할 수 있다. 특별히 더 도전적인 데이터셋(CIFAR-100, ImageNet, VTAB suite)에 대해서 좋은 결과를 내었음을 확인할 수 있다. 또한 논문의 저자는 pre-train의 효율성이 데이터 구조의 선택 뿐만이 아니라 파라미터와 트레이닝 스케쥴, 옵티마이저, weight decay등에도 영향을 받는다고 기록했다.

Pre-training Data Requirement
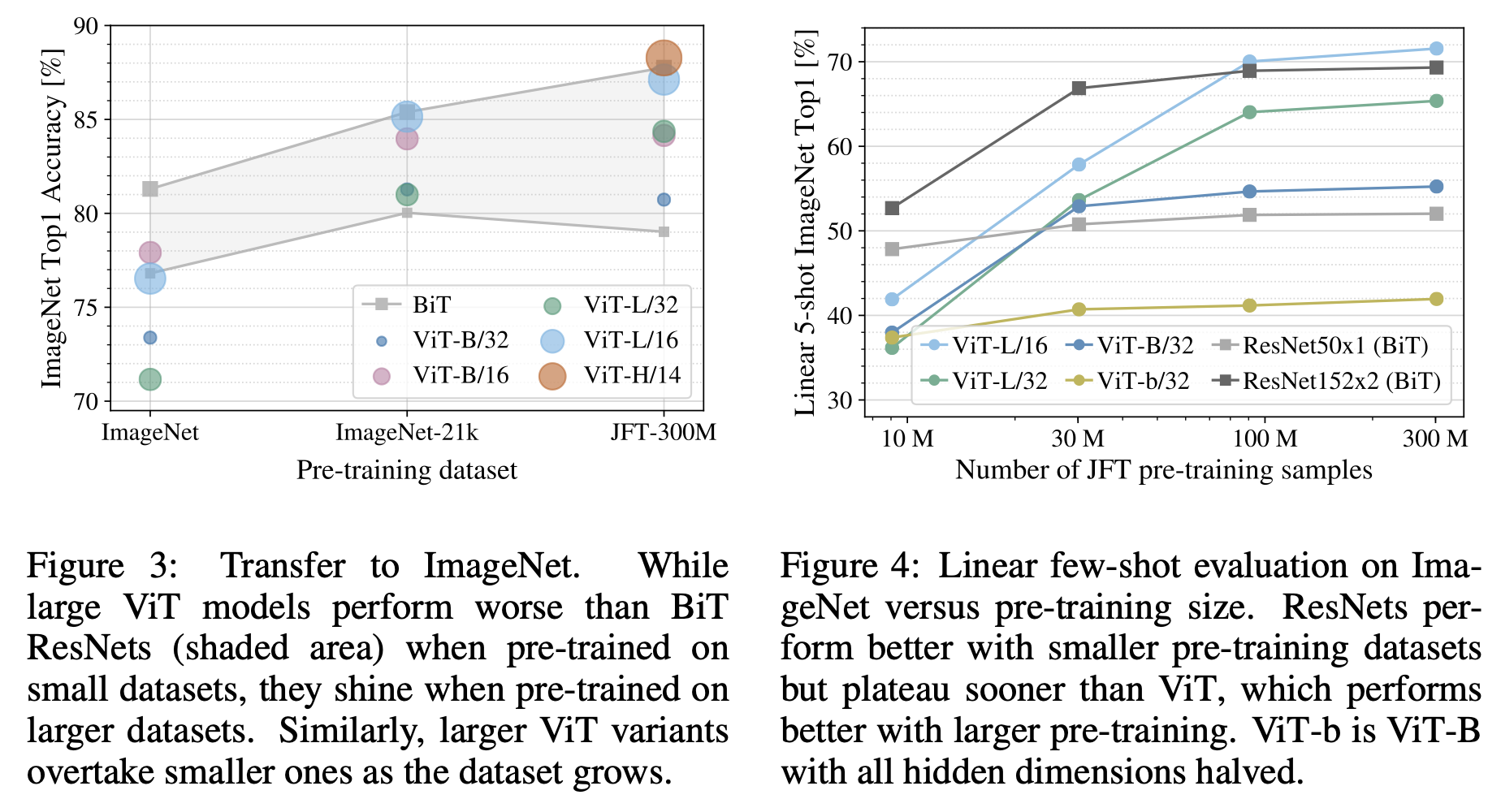
ViT는 JFT-300M 데이터셋과 같이 큰 데이터셋에 대해서는 inductive bias가 있는 ResNet기반 CNN모델보다 성능이 잘 나옴을 확인했다. 데이터셋의 크기가 미치는 영향을 알아보기 위해 실험을 진행했다.
imageNet -> imageNet-21k -> JFT300M 순으로 데이터 크기를 늘려가면 결과를 측정한 내용이 그림 3에 나와있다. JFT-300M에 이전에는 ResNet기반의 BiT 모델이 성능이 더 잘 나오는 것을 확인할 수 있다.
JFT-300M 데이터셋에서 각각 9M, 30M, 90M만큼의 데이터만 사용해서 학습을 진행한 결과가 그림 4에 정리되어 있다. 마찬가지로 적은 수의 데이터에 대해서는 Bit 모델이 성능이 앞서는 것을 확인할 수 있다. 이 실험에서는 대량의 데이터를 다루므로 계산 효율성과 비용 절감을 위해 few-shot accuracy를 사용했다.
위의 결과들을 통해 알 수 있는 것은, 적은 데이터에 대해서는 CNN기반의 구조에서 사용하는 inductive bias가 유용하지만, 충분히 거대한 데이터에 대해서는 적절한 패턴 학습만으로 더 뛰어난 성능을 낼 수 있다는 점이다.
Scaling Study
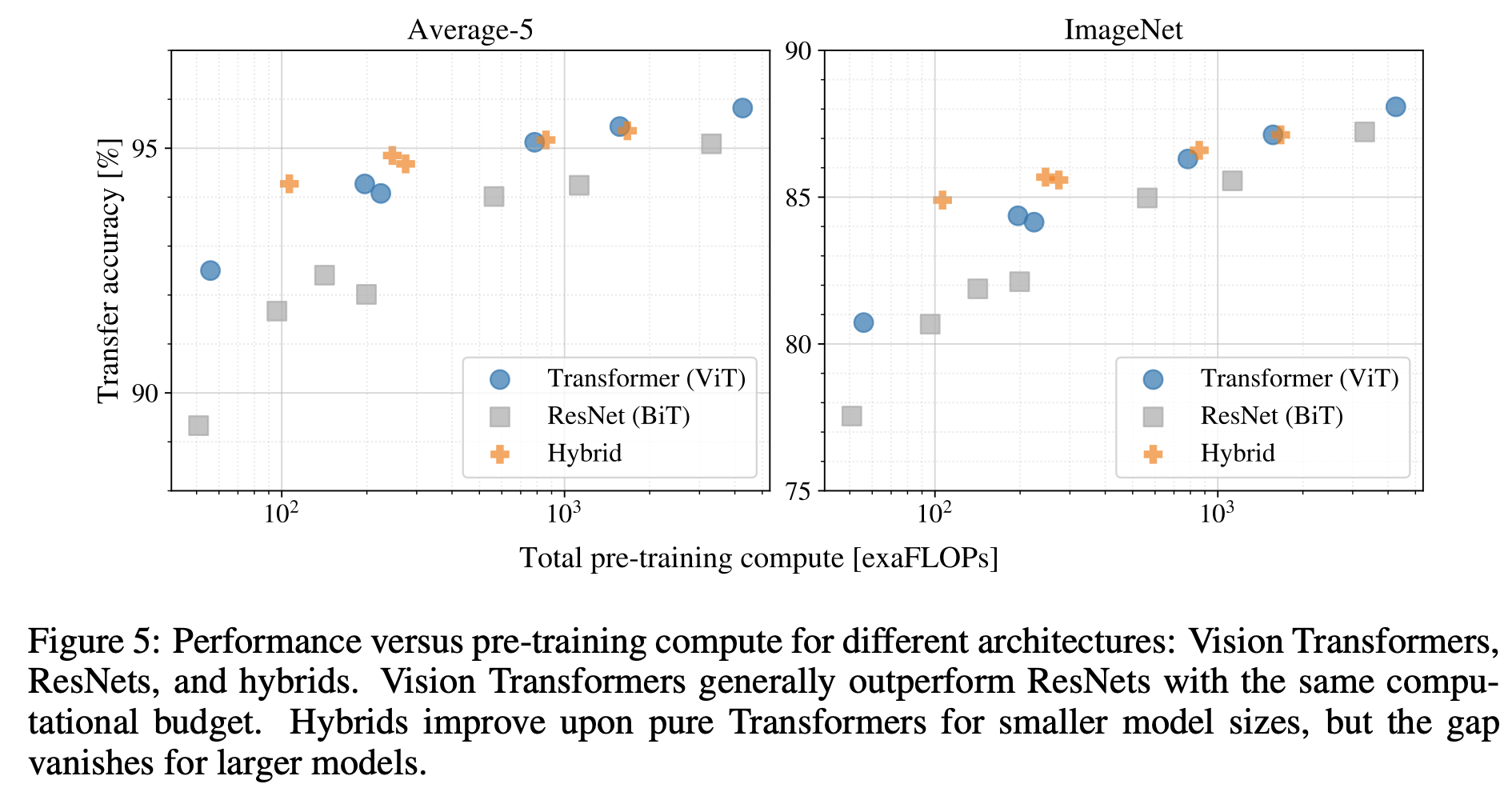
각 모델의 성능-비용을 알아보기 위해 ResNet 7개와 ViT 6개 그리고 하이브리드 모델 5개를 사용해서 계산량당 정확도를 평가하였다. 그림 5에서 그 결과를 확인할 수 있는데, ViT 모델이 성능-비용 지표에서 ResNet 모델보다 잘 나왔다. 추가로 계산량이 적은 영역에서는 하이브리드 모델이 ViT 모델보다 더 좋은 성능이 나온 것을 확인할 수 있는데, 이는 convolutional local feature processing이 ViT의 성능 향상에 도움을 줌을 알 수 있다.
Inspecting Vision Transformer

ViT가 데이터를 어떻게 처리하는지 이해하기 위해 내부의 representations을 표현하였다. ViT는 선형 투영되어 평평해진 패치들을 저차원 공간에 넣는다. 그림 7의 첫 번째 그림은 임베딩 필터들의 성분을 보여준다. 위 성분들은 CNN에서 표현된 representation들과 비슷하게 보인다.
(출처 : https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf)

다음으로는 학습된 위치 임베딩 값을 패치 representations에 더해준다. 그림 7의 두 번째 그림은 학습된 위치 임베딩 값이 실제 본인의 위치를 얼마나 유사하게 찾아내는지 유사도를 구한 그림이다. 그림에서 확인할 수 있듯이 각 패치들이 원본에서의 위치를 잘 기억하고 있는 모습을 볼 수 있다. 추가로 위치 임베딩을 할 때에 1D 포지션 임베딩법과 2D 포지션 임베딩법의 성능차이가 크지 않아서 1D 포지션 임베딩 방법을 사용했다고 한다.
self-attention은 ViT로 하여금 낮은 층에서도 전체 이미지에 대한 정보를 모으는 것이 가능하게 해준다. 그림 7의 세 번째 그림은 네트워크 깊이에 따른 attention거리를 나타낸다. 층이 깊어질 수록 어텐션 거리가 증가하는 경향을 발견할 수 있다. 그리고 얕은 레이어에서도 대부분의 이미지 픽셀에 대해 attentoin 하고 있는 모습을 확인할 수 있다. 이는 모델이 global 하게 integrate하는 능력이 있음을 보여준다.

그림 6에서 볼 수 있듯이 ViT는 분류에 필요한 부분을 attention 한다는 것을 Visualization 해서 확인할 수 있다.
Conclusion
위 논문의 저자들은 트랜스포머를 이미지 인식에 직접 적용하는 방법을 사용했다. 다른 연구들과 같이 inductive bias를 사용하지 않고, 이미지를 패치로 나눠서 시퀀스하게 Encoder로 입력하는 NLP 표준 트랜스포머의 형식을 사용했다. ViT는 큰 데이터 셋을 pre-train해서 사용할 때, 기존의 방법들에 비해 효율적인 SotA의 성능을 달성했다. 그러나 아직 Object Detection이나 Segmentation등의 분야의 적용과 같은 도전적인 과제들이 남아있다.
(내용 출처 : https://arxiv.org/pdf/2010.11929.pdf)
(참고 자료 출처 : https://velog.io/@changdaeoh/Vision-Transformer-Review)
(참고 자료 출처 : https://www.youtube.com/watch?v=D72_Cn-XV1g)
틀린 내용이 있거나 수정할 사항이 있으면 댓글로 알려주시면 감사하겠습니다.
