1) 도서 쪽수를 찾아서
code
import requests
# url = "http://www.yes24.com/SearchCorner/Search?domain=BOOK&query=ISBN"
url = "http://www.yes24.com/SearchCorner/Search?domain=BOOK&query=9791162243664"
url_result = requests.get(url)
# HTML로 변환하여 상세 페이지로 연결되는 링크 URL 찾기
print(url_result.text)
# 도서 상세 페이지 url로 다시 requests.get() 하여 도서 상세 페이지 가져오기
# 도서 상세 페이지에서 쪽수 추출- 웹 스크래핑 or 웹 크롤링
- web scraping, web crawling
- 프로그램으로 웹사이트의 페이지를 옮겨 가면서 데이터를 추출하는 작업
2) 검색 결과 페이지 가져오기
- gdown 패키지로 20대가 가장 좋아하는 도서 목록 불러오기
code
import gdown
gdown.download('https://bit.ly/3q9SZix', '20s_best_books.json', quiet=False)
import pandas as pd
books_df = pd.read_json('20s_best_books.json')
books_df.head()
books = books_df[['no', 'ranking', 'bookname', 'authors', 'publisher', 'publication_year', 'isbn13']]
books.head()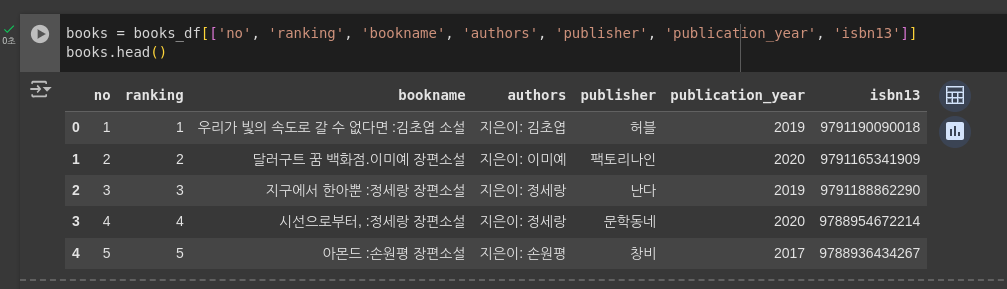
데이터프레임 행과 열 선택하기: loc 메서드
- loc는 메서드이지만 대괄호를 사용하여 행의 목록과 열의 목록을 받음.
- iloc 메서드는 인덱스의 위치 사용 (ex.
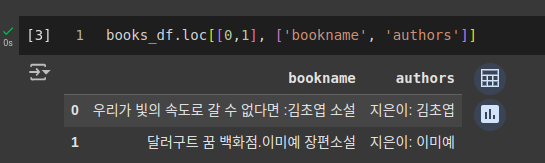
books_df.iloc[[0, 1], [2,3]])
codebooks_df.loc[[0,1], ['bookname', 'authors']]
- loc는 리스트 대신 슬라이스 연산자를 쓸 수도 있음.
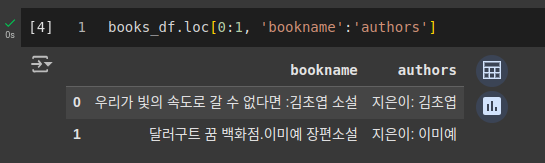
codebooks_df.loc[0:1, 'bookname':'authors']
- 시작과 끝을 지정하지 않고 슬라이스 연산자를 사용하면 전체를 의미
codebooks = books_df.loc[:, 'no':'isbn13'] books.head()
- 파이썬 슬라이스처럼 스텝도 지정할 수 있음. (ex.
books_df.loc[::2, 'no':'isbn13'].head())
검색 결과 페이지 HTML 가져오기: requests.get() 함수
- 첫 번째 도서의 ISBN과 Yes24 검색 결과 페이지 URL을 위한 변수를 정의
- requests.get() 함수를 호출할 때 파이썬 문자열의 format() 메서드를 사용해 isbn 변수에 저장된 값을 url 변수에 전달
- 다음과 같은 결과를 얻을 수 있음.
codeimport requests isbn = 9791190090018 # '우리가 빛의 속도로 갈 수 없다면'의 ISBN url = 'http://www.yes24.com/Product/Search?domain=BOOK&query={}' r = requests.get(url.format(isbn)) print(r.text)
3) HTML에서 데이터 추출하기: 뷰티플수프
- 뷰티플수프(Beautiful Soup): HTML 안에 있는 내용을 찾을 때 사용하는 패키지
- 스프래피(Scrapy): requests와 뷰티플수프를 합쳐 놓은 것 같은 패키지
크롬 개발자 도구로 HTML 태그 중 도서 제목 찾기
- 해당 페이지 - 마우스 우클릭 - Inspect
https://www.yes24.com/Product/Search?domain=BOOK&query=9791190090018- 개발자도구(F12)
- 세 개의 점(DevTools 맞춤 설정 및 제어) - 개발자 도구 창을 아래로 옮기기
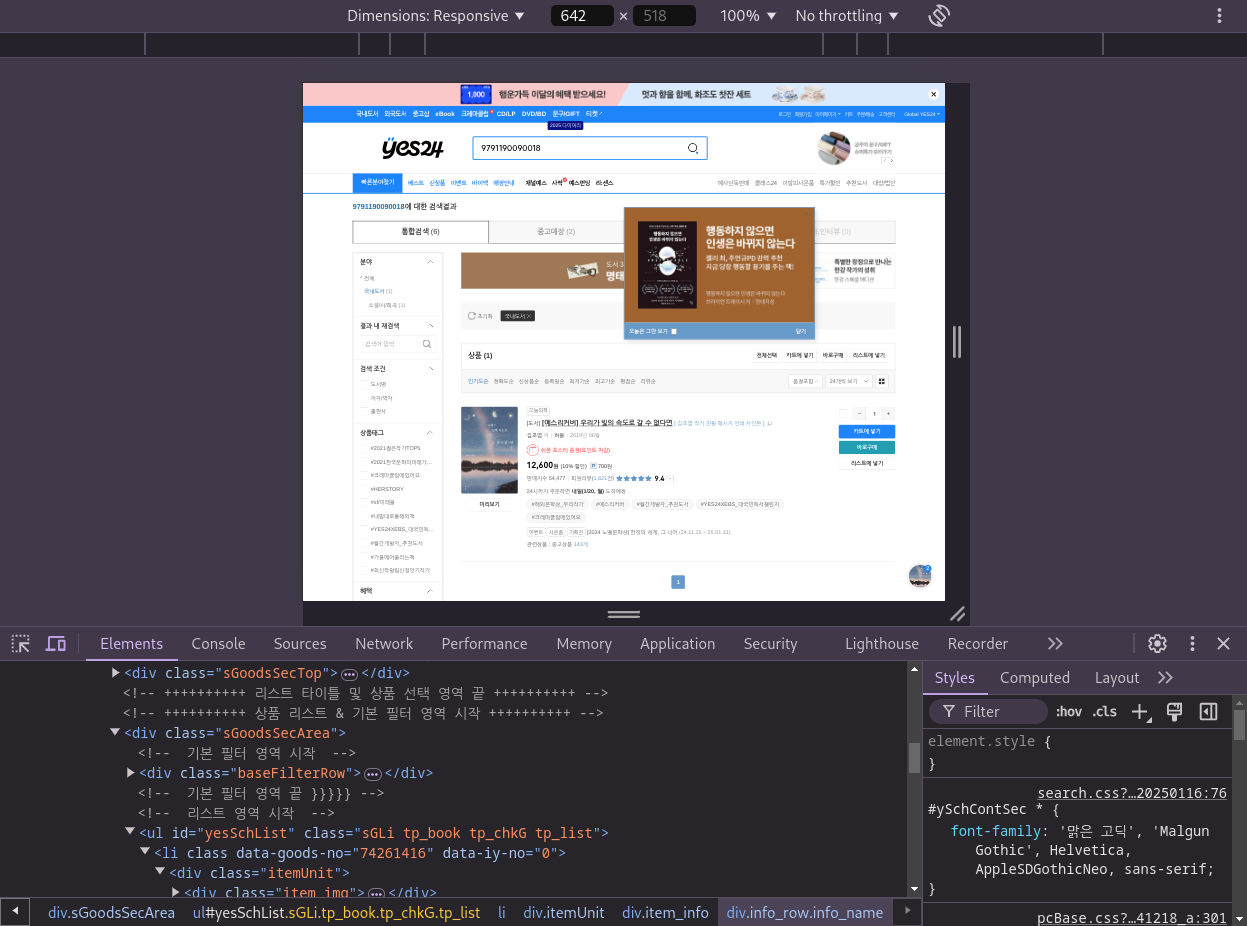
- 개발자 도구 창 메뉴바에서 Select 아이콘 클릭 - 이름 위에 마우스 커서를 올리기
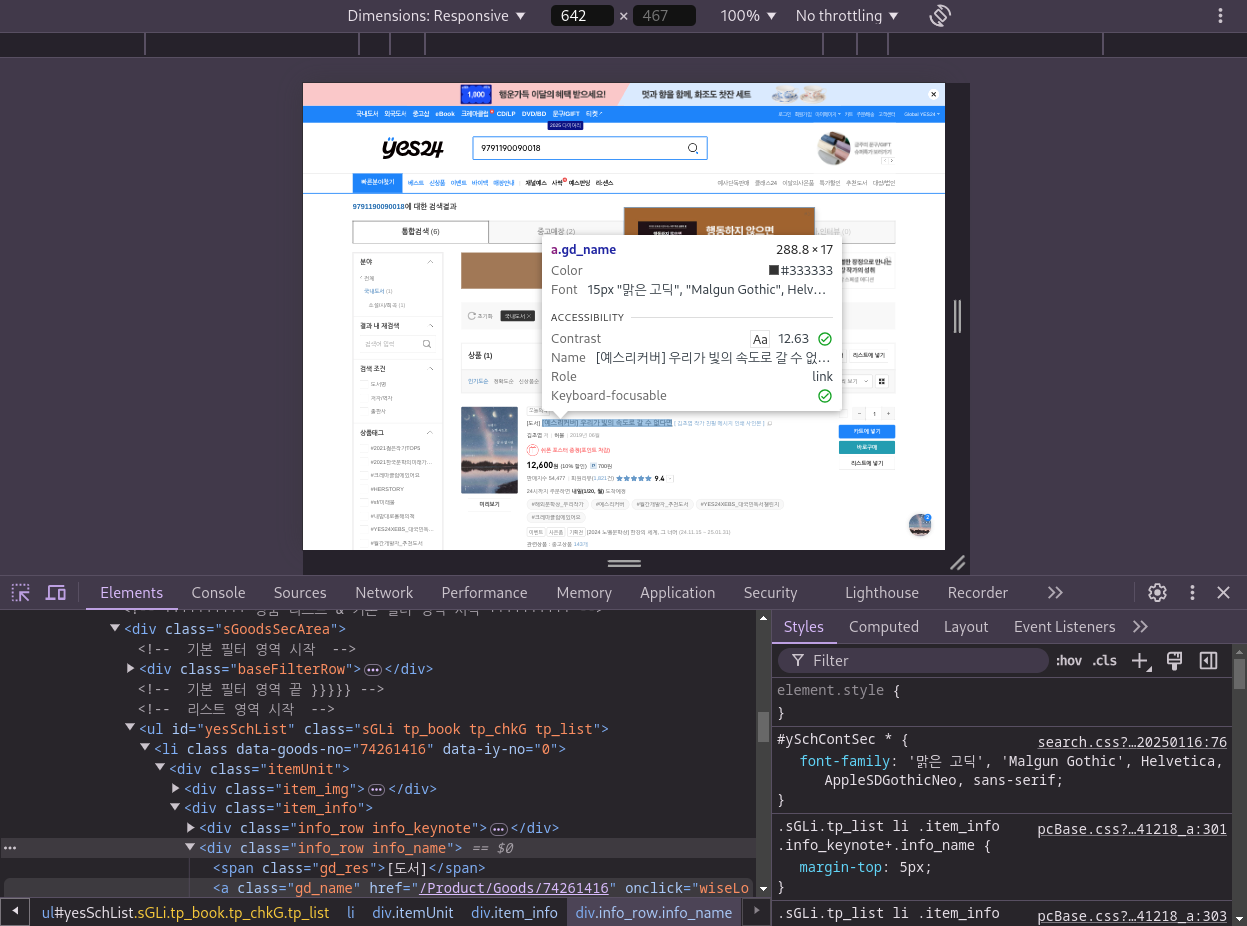
뷰티플수프를 사용해서 데이터 추출하기
- 객체 생성 시 매개변수는 파싱할 HTML 문서와 파서
- 파서: 입력 데이터를 받아 데이터 구조를 만드는 소프트웨어 라이브러리
code
from bs4 import BeautifulSoup
soup = BeautifulSoup(r.text, 'html.parser')
- find() 메서드: 태그 위치 찾기
- 매개변수는 찾을 태그 이름과 attrs로 찾으려는 태그 속성을 딕셔너리로 지정
codeprd_link = soup.find('a', attrs={'class': 'gd_name'}) print(prd_link) print(prd_link['href'])

도서 상세 페이지 HTML 가져오기
code# '우리가 빛의 속도로 갈 수 없다면'의 상세 페이지 가져오기 url = 'http://www.yes24.com'+prd_link['href'] r = requests.get(url)도서 상세 페이지에서 쪽수 정보 가져오기
- 쪽수가 담긴 HTML 위치 찾기
- 해당 페이지 - 마우스 우클릭 - Inspect
https://www.yes24.com/Product/Goods/74261416- Select 아이콘 클릭 - 쪽수 정보 위에 마우스 커서를 올리기
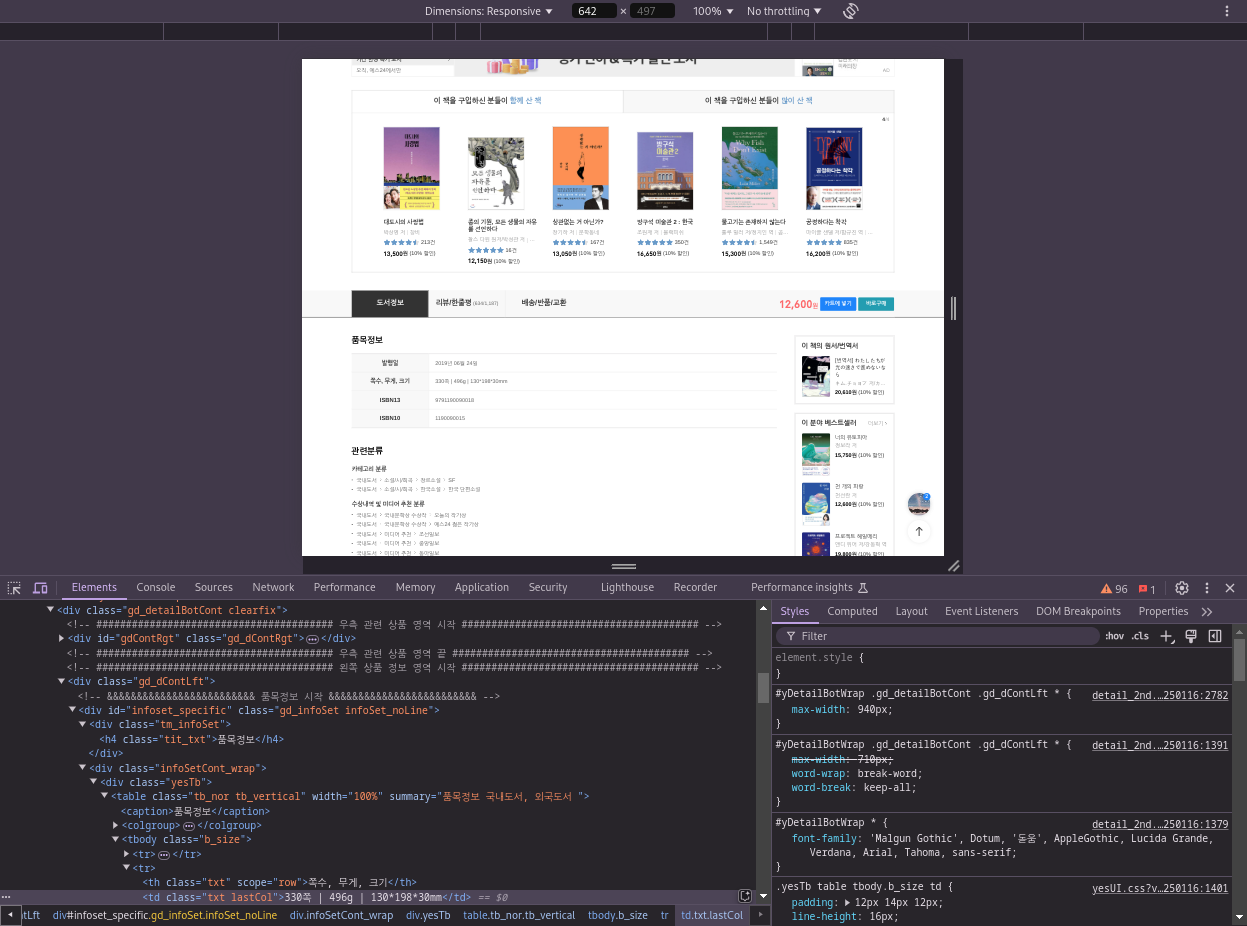
뷰티플수프를 사용해서 데이터 추출하기
codesoup = BeautifulSoup(r.text, 'html.parser') prd_detail = soup.find('div', attrs={'id':'infoset_specific'}) print(prd_detail)prd_detail2 = soup.find('table', attrs={'class':'tb_nor tb_vertical'}) print(prd_detail2)
테이블 태그를 리스트로 가져오기: find_all() 메서드
- 품목 정보 테이블 행을 하나씩 검사해서 '쪽수, 무게, 크기'에 해당하는 < tr > 태그를 찾아야 함.
- find_all() 메서드: 특정 HTML 태그를 모두 찾아서 리스트로 반환
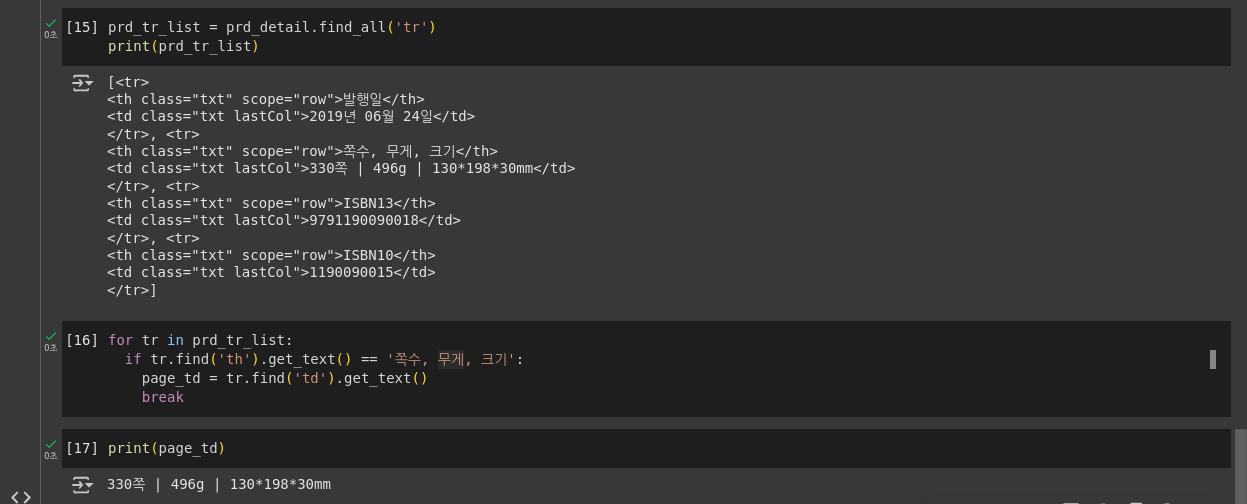
codeprd_tr_list = prd_detail.find_all('tr') print(prd_tr_list)
태그 안의 텍스트 가져오기: get_text() 메서드
- for 문으로 객체를 순회하면서 태그 안의 텍스트가 찾는 정보에 해당하는지 검사
codefor tr in prd_tr_list: if tr.find('th').get_text() == '쪽수, 무게, 크기': page_td = tr.find('td').get_text() break print(page_td)
- split(): 공백을 기준으로 문자열을 나누어 리스트로 반환
codeprint(page_td.split()[0])
4) 전체 도서의 쪽수 구하기
1) 온라인 서점의 검색 결과 페이지 URL을 만듭니다.
2) requests.get() 함수로 검색 결과 페이지의 HTML을 가져옵니다.
3) 뷰티플수프로 HTML을 파싱합니다.
4) 뷰티플수프의 find() 메서드로 < a > 태그를 찾아 상세 페이지 URL을 추출합니다.
5) requests.get() 함수로 다시 도서 상세 페에지의 HTML을 가져옵니다.
6) 뷰티플수프로 HTML을 파싱합니다.
7) 뷰티플수프의 find() 메서드로 '품목정보' < div > 태그를 찾습니다.
8) 뷰티플수프의 find_all() 메서드로 '쪽수'가 들어있는 < tr > 태그를 찾습니다.
9) 앞에서 찾은 테이블의 행에서 get_text() 메서드로 < td > 태그에 들어 있는 '쪽수'를 가져옵니다.
code
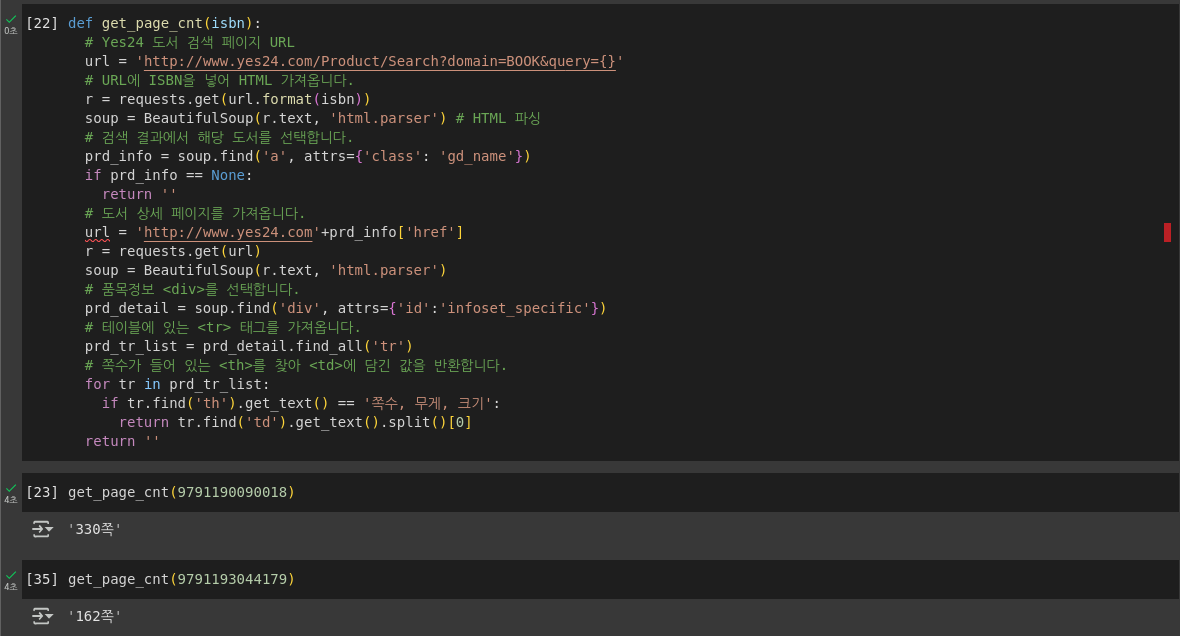
def get_page_cnt(isbn):
# Yes24 도서 검색 페이지 URL
url = 'http://www.yes24.com/Product/Search?domain=BOOK&query={}'
# URL에 ISBN을 넣어 HTML 가져옵니다.
r = requests.get(url.format(isbn))
soup = BeautifulSoup(r.text, 'html.parser') # HTML 파싱
# 검색 결과에서 해당 도서를 선택합니다.
prd_info = soup.find('a', attrs={'class': 'gd_name'})
if prd_info == None:
return ''
# 도서 상세 페이지를 가져옵니다.
url = 'http://www.yes24.com'+prd_info['href']
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
# 품목정보 <div>를 선택합니다.
prd_detail = soup.find('div', attrs={'id':'infoset_specific'})
# 테이블에 있는 <tr> 태그를 가져옵니다.
prd_tr_list = prd_detail.find_all('tr')
# 쪽수가 들어 있는 <th>를 찾아 <td>에 담긴 값을 반환합니다.
for tr in prd_tr_list:
if tr.find('th').get_text() == '쪽수, 무게, 크기':
return tr.find('td').get_text().split()[0]
return ''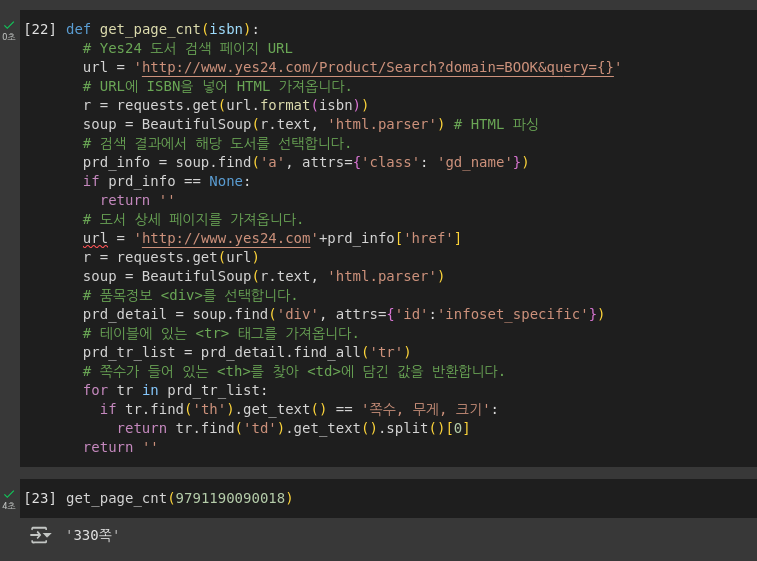
데이터프레임 행 혹은 열에 함수 적용하기: apply() 메서드
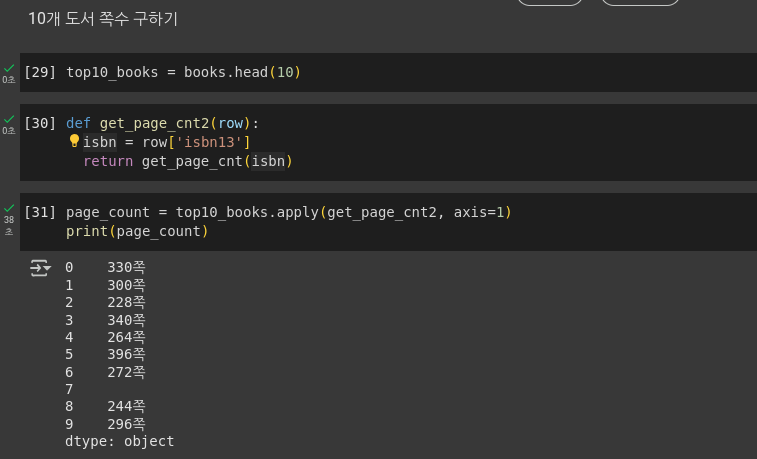
- books_df 데이터프레임에서 가장 있기 있는 10권의 도서 쪽수를 구해보자.
codeimport gdown gdown.download('https://bit.ly/3q9SZix', '20s_best_books.json', quiet=False) import pandas as pd books_df = pd.read_json('20s_best_books.json') books = books_df[['no', 'ranking', 'bookname', 'authors', 'publisher', 'publication_year', 'isbn13']] # 상위 10권 추출 top10_books = books.head(10)
- apply() 메서드의 매개변수는 실행할 함수, axis가 1인 경우 행에, 0인 경우 열에 적용
- get_page_cnt2() 함수를 사용하여 10개 도서 쪽수를 한 번에 구하기
codedef get_page_cnt2(row): isbn = row['isbn13'] return get_page_cnt(isbn) page_count = top10_books.apply(get_page_cnt2, axis=1) print(page_count)
람다 함수
- 함수 이름 없이 한 줄로 쓰는 함수
codepage_count = top10_books.apply(lambda row: get_page_cnt(row['isbn13']), axis=1) print(page_count)
some_df.apply(lambda 매개변수: some_func(column), axis=0)
데이터프레임과 시리즈 합치기: merge() 함수
- name 속성을 사용해서 열의 이름을 지정
codepage_count.name = 'page_count' print(page_count)
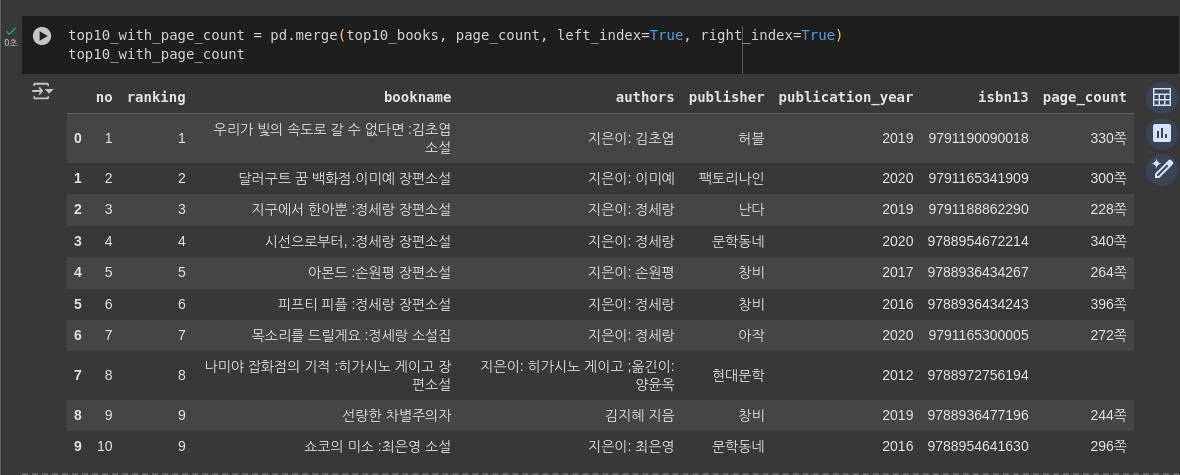
- 시리즈 객체를 데이터프레임의 열로 합치기
codetop10_with_page_count = pd.merge(top10_books, page_count, left_index=True, right_index=True) top10_with_page_count
5) 웹 스크래핑할 때 주의할 점
1) 웹사이트에서 스크래핑을 허락하였는지 확인
사이트url/robots.txt 파일 확인
접근해도 좋은 페이지와 그렇지 않은 페이지 명시2) HTML 태그를 특정할 수 있는지 확인
자바스크립트 등을 사용한 코드는 셀레니움 등을 사용해야 웹 스크래핑 가능
웹 페이지는 언제 어떻게 바뀔지 모르기 때문에 스크래핑 프로그램의 유지보수가 힘듦.
6) merge() 함수의 매개변수
on 매개변수
- 합칠 때 기준이 되는 열을 지정
- on 매개변수에 적은 값이 같은 행끼리 합침.
how 매개변수
- left, right: 기준으로 할 데이터프레임 지정
- outer: 두 데이터프레임의 모든 행을 유지하면서 합침.
- inner: 두 데이터프레임의 값이 같은 행만 유지하면서 합침.
left_on과 right_on 매개변수
- 합칠 기준이 되는 열의 이름이 서로 다를 경우 각기 지정 가능
left_index와 right_index 매개변수
합칠 기준이 열이 아니라 인덱스인 경우
두 데이터프레임에 동일한 이름의 열이 존재할 경우: 첫 번째 데이터프레임의 열 이름에는 _x 접미사가, 두 번째 데이터프레임의 열 이름에는 _y 접미사가 붙음.
7) 정리

[기본숙제]
p.150의 확인 문제 1번
답) 4번
loc 메서드에 대한 문제였다. loc 메서드는 파이썬처럼 슬라이스 연산자를 사용할 수 있는데, 이때의 슬라이스 연산자는 마지막 항목도 포함한다. 주어진 보기 중에서 스텝을 지정하여 2만큼 건너뛰면서 선택하는 4번만 다른 결과를 가진다.

[추가숙제]
p. 137~138 손코딩 실습으로 원하는 도서의 페이지 수를 추출하고 화면 캡처하기
- 김초엽의 '아무튼, SF 게임' 도서의 isbn = 9791193044179