Chapter 03. 데이터 정제하기
학습 목표
- 데이터프레임에서 불필요한 행과 열을 삭제하거나 데이터값을 바꾸는 방법을 배웁니다.
- 정규 표현식을 사용해 잘못된 값을 고치거나 누락된 값이 있는 경우 웹 스크래핑하여 얻은 값으로 채웁니다.
03-1 불필요한 데이터 삭제하기
- 데이터 정제: 데이터에서 손상되거나 부정확한 부분을 수정하고, 불필요한 데이터를 삭제하거나 불완전한 값을 교체하는 등의 작업
- 데이터 랭글링, 데이터 먼징
1) 열 삭제하기
- 마지막 열 'Unnamed: 13'은 CSV 파일 각 라인의 끝에 콤마가 있어서 판다스가 자동으로 추가한 것
- 불필요한 열이므로 삭제하는 것이 좋다.
code
import gdown
gdown.download('https://bit.ly/3RhoNho', 'ns_202104.csv', quiet=False)
import pandas as pd
ns_df = pd.read_csv('ns_202104.csv', low_memory=False)
ns_df.head()
- '번호' 열부터 '등록일자' 열까지 선택하여 새로운 데이터프레임을 만든다.
code
ns_book = ns_df.loc[:, '번호': '등록일자']
ns_book.head()
loc 메서드와 불리언 배열
- 중간에 있는 열을 제외하기 위해서는 슬라이싱을 사용하지 않고, 불리언 배열을 사용한다.
- 데이터프레임 열 이름이 저장된 columns 속성을 확인한다.
codeprint(ns_df.columns) # result Index(['번호', '도서명', '저자', '출판사', '발행년도', 'ISBN', '세트 ISBN', '부가기호', '권', '주제분류번호', '도서권수', '대출건수', '등록일자', 'Unnamed: 13'], dtype='object')
- columns 속성은 Index 클래스 객체이다.
- 해당 객체의 원소는 숫자 인덱스로 참조할 수 있다
codeprint(ns_df.columns)
원소별 비교
- element-wise comparison
- ["혼공", "분석", "파이썬"] == "분석"
- [False, True, False]
- 넘파이 배열로 반환 결과를 볼 수 있다.
codens_df.columns != 'Unnamed: 13' # result array([ True, True, True, True, True, True, True, True, True, True, True, True, True, False])
codeselected_columns = ns_df.columns != 'Unnamed: 13' ns_book = ns_df.loc[:, selected_columns] ns_book.head()
codeselected_columns = ns_df.columns != '부가기호' ns_book = ns_df.loc[:, selected_columns] ns_book.head()

drop() 메서드
- 판다스에서 데이터프레임의 행이나 열을 삭제하는 drop() 메서드 제공
- 첫 번째 매개변수에 삭제하려는 열 이름을 전달하고 axis 매개변수를 1로 지정
- axis 매개변수가 0이면 행을 삭제함.
codens_book = ns_df.drop('Unnamed: 13', axis=1) ns_book.head()
- 중간에 있는 열도 삭제할 수 있음.
codens_book = ns_df.drop(['부가기호', 'Unnamed: 13'], axis=1) ns_book.head()
- inplace 매개변수를 사용하면 현재 선택한 프레임을 바로 수정할 수 있음.
- 다만 ns_book 변수에 연결된 객체가 수정되는 것이 아니라 내부적으로 수정된 새로운 객체를 만든 후 ns_book 변수에 연결하는 것이라서 성능상의 이득은 없음.
codens_book.drop(['주제분류번호'], axis=1, inplace=True) ns_book.head()
dropna() 메서드
- 기본적으로 NaN이 하나 이상 포함된 행이나 열을 삭제
codens_book = ns_df.dropna(axis=1) ns_book.head()
- 모든 값이 NaN인 열을 삭제하려면 how 매개변수를 all로 지정
codens_book = ns_df.dropna(axis=1, how='all') ns_book.head()
2) 행 삭제하기
drop() 메서드
- axis 매개변수를 0으로 지정하면 행을 삭제할 수 있으나, 기본값이라서 생략해도 괜찮음.
- 행을 삭제할 때는 숫자로 된 행 인덱스를 직접 지정하는 일이 흔치 않음.
codens_book2 = ns_book.drop([0,1]) ns_book2.head()
[ ] 연산자와 슬라이싱
- [ ] 연산자에 슬라이싱이나 불리언 배열을 전달하면 행을 선택
codens_book2 = ns_book[2:] ns_book2.head()
codens_book2 = ns_book[0:2] ns_book2.head()

[ ] 연산자와 불리언 배열
- 불리언 배열을 사용해 행을 선택하는 방식이 가장 즐겨 사용하는 방법이다.
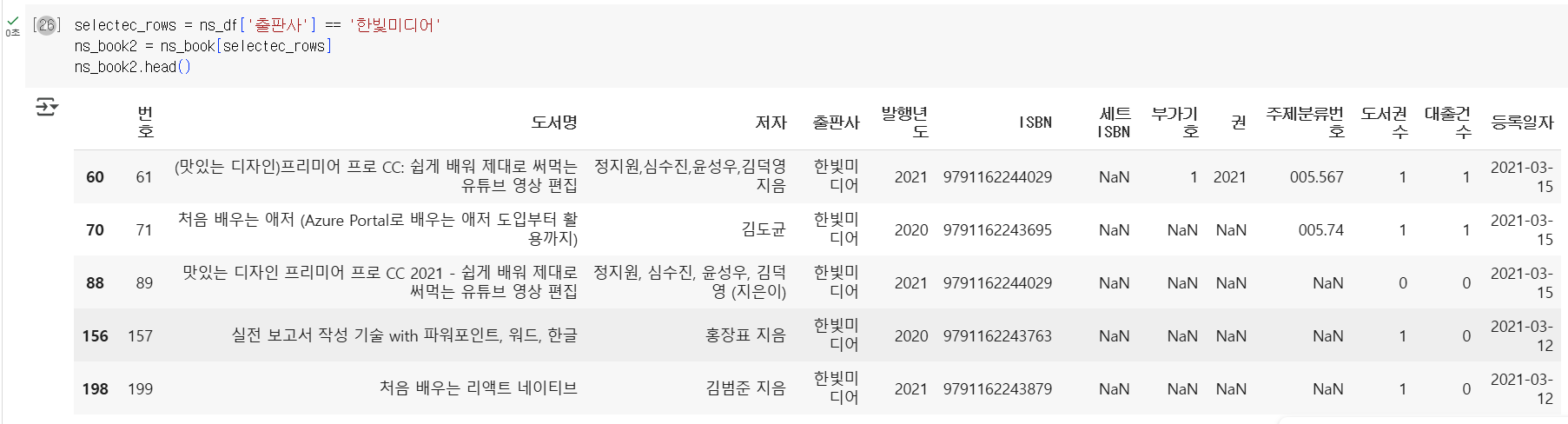
codeselectec_rows = ns_df['출판사'] == '한빛미디어' ns_book2 = ns_book[selectec_rows] ns_book2.head()
- 불리언 배열은 loc 메서드에서도 사용할 수 있다.
codens_book2 = ns_book.loc[selectec_rows] ns_book2.head()
- 불리언 배열을 만드는 조건을 [ ] 연산자에 바로 넣어서 사용할 수도 있다.
codens_book2 = ns_book[ns_book['대출건수'] > 1000] ns_book2.head()

3) 중복된 행 찾기
duplicated() 메서드
- 중복된 행 중에서 처음 행을 제외한 나머지 행: True
- 그 외에 중복되지 않은 나머지 모든 행: False
- sum() 함수를 함께 사용하면 True를 1로 인식 -> 중복된 행의 개수를 셀 수 있음.
codesum(ns_book.duplicated()) # result 0
- 이 데이터프레임의 모든 행은 '번호' 열에 고유한 값을 가지고 있기 때문에 중복된 행이 나올 수 없음.
- 특정 열을 기준으로 중복된 행이 있는지 확인해야 확실하다.
- subset 매개변수에 열 이름을 지정
codesum(ns_book.duplicated(subset=['도서명', '저자', 'ISBN'])) # result 22096
- keep 매개변수를 False로 설정하면, 중복된 행을 모두 True로 표시한 불리언 배열을 반환
codedup_rows = ns_book.duplicated(subset=['도서명', '저자', 'ISBN'], keep=False) ns_book3 = ns_book[dup_rows] ns_book3.head()
- '파친코'는 두 권짜리 도서
- '보건교사 안은영'은 같은 도서가 두 권 등록

4) 그룹별로 모으기
groupby() 메서드
- 같은 도서의 대출건수는 하나로 합친다.
- by 매개변수에 행을 합칠 때 기준이 되는 열을 지정
- by 매개변수에 지정된 열에 NaN이 포함되어 있으면 해당 행을 삭제
- 이를 막기 위해서는 dropna 매개변수를 False로 지정해야 함.
codecount_df = ns_book[['도서명', '저자', 'ISBN', '권', '대출건수']] group_df = count_df.groupby(by=['도서명', '저자', 'ISBN', '권'], dropna=False) loan_count = group_df.sum() # loan_count = count_df.groupby(by=['도서명', '저자', 'ISBN', '권'], dropna=False).sum() loan_count.head()

drop_duplicates() 메서드
- 중복된 행을 삭제
- subset, keep, inplace 매개변수
5) 원본 데이터 업데이트하기
- 원본 데이터에는 중복된 데이터가 있기 때문에 더해진 대출건수를 업데이트하기 전에 다음과 같은 과정이 필요하다.
- duplicated() 메서드로 중복된 행을 True로 표시한 불리언 배열을 생성
- 불리언 배열을 판다스의 ~ 연산자를 사용하여 반전시켜서 중복되지 않은 고유한 행을 True로 표시
- 불리언 배열을 사용해 원본 배열에서 고유한 행만 선택한 후 copy() 메서드로 데이터프레임을 생성
code
dup_rows = ns_book.duplicated(subset=['도서명', '저자', 'ISBN', '권'])
unique_rows = ~dup_rows
ns_book3 = ns_book[unique_rows].copy()
# check
sum(ns_book3.duplicated(subset=['도서명', '저자', 'ISBN', '권']))
# result
0원본 데이터프레임 인덱스 설정하기
- set_index() 메서드: 지정한 열을 인덱스로 설정할 때 사용
- ns_book3의 인덱스를 loan_count 데이터프레임의 인덱스와 동일하게 만듦.
- inlace 매개변수 true로 지정해 ns_book3 데이터프레임 수정
codens_book3.set_index(['도서명', '저자', 'ISBN', '권'], inplace=True) ns_book3.head()
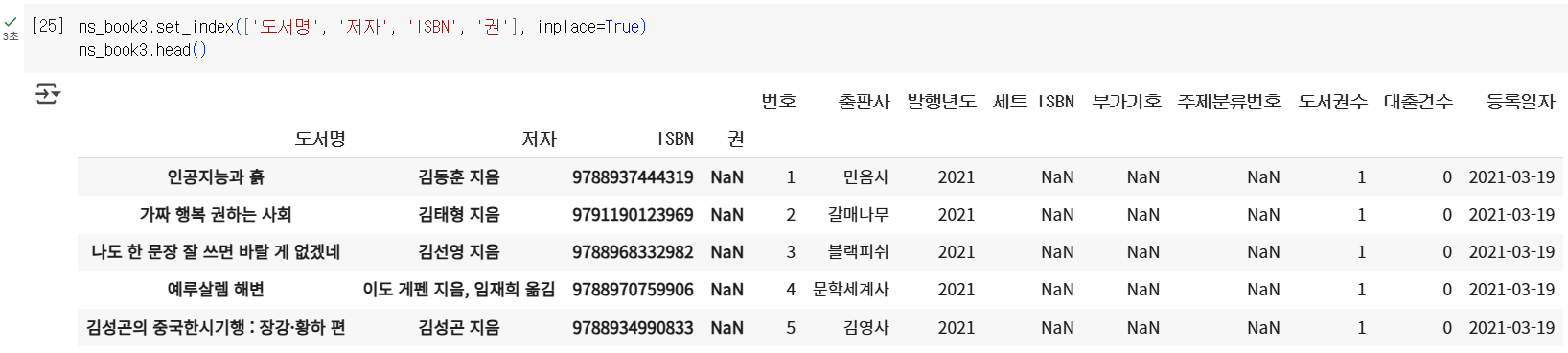
업데이트하기: update() 메서드
- 다른 데이터프레임을 사용해 원본 데이터프레임의 값을 업데이트
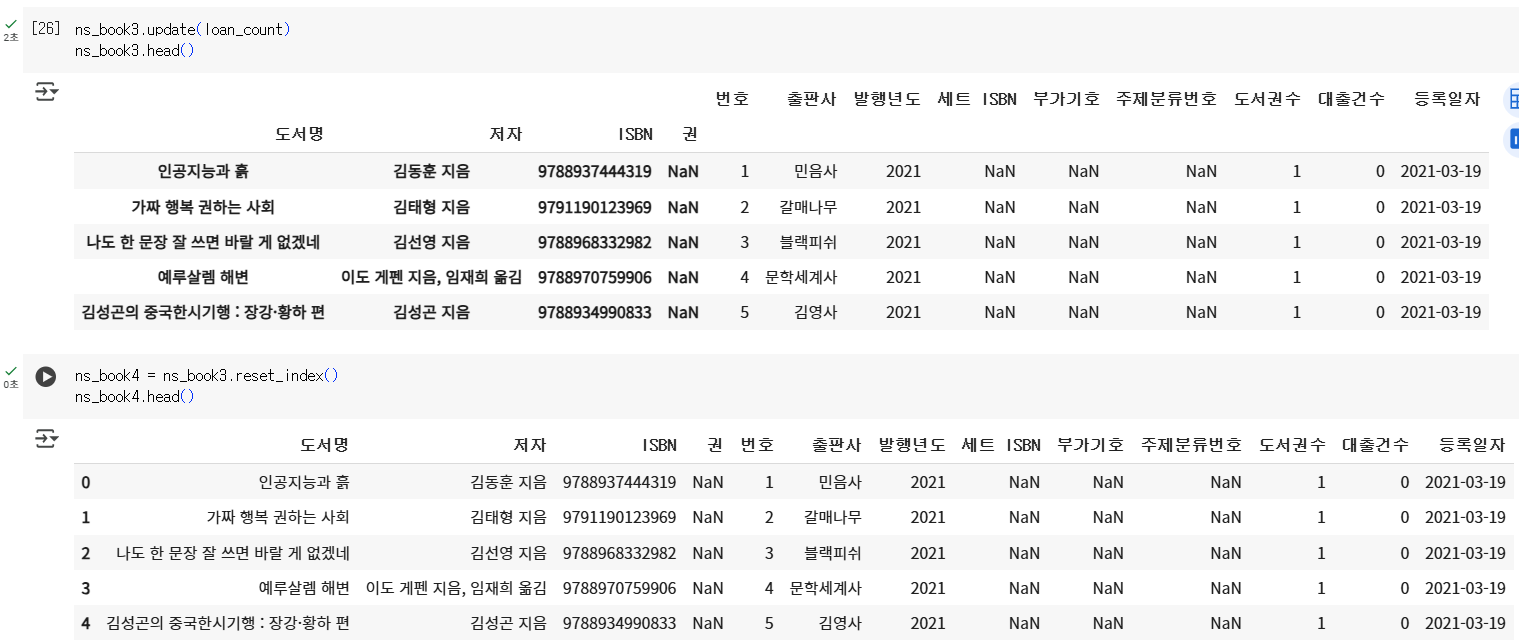
codens_book3.update(loan_count) ns_book3.head()
- reset_index() 메서드: 데이터프레임 인덱스를 재설정
codens_book4 = ns_book3.reset_index() ns_book4.head()
- 대출건수가 잘 합쳐졌는지 확인
codesum(ns_book['대출건수'] > 100) # result 2311
- 새로 만든 데이터프레임의 대출건수도 확인 (중복된 도서 합침)
codesum(ns_book4['대출건수'] > 100) # result 2550
- 열의 순서를 초기 데이터프레임의 순서와 동일하게 맞추기
- [ ] 연산자를 사용해서 원하는 열 이름을 순서대로 전달
codens_book4 = ns_book4[ns_book.columns] ns_book4.head()
- ns_book4 데이터프레임을 저장
codens_book4.to_csv('ns_book4.csv', index=False)

6) 일괄 처리 함수 만들기
code
def data_cleaning(filename):
"""
남산 도서관 장서 CSV 데이터 전처리 함수
: param filename: CSV 파일 이름
"""
# 파일을 데이터프레임으로 읽습니다.
ns_df = pd.read_csv('ns_202104.csv', low_memory=False)
# NaN인 열을 삭제합니다.
ns_book = ns_df.dropna(axis=1, how='all')
# 대출건수를 합치기 위해 필요한 행만 추출하여 count_df 데이터프레임을 만듭니다.
count_df = ns_book[['도서명', '저자', 'ISBN', '권', '대출건수']]
# 도서명, 저자, ISBN, 권을 기준으로 대출건수를 groupby 합니다.
loan_count = count_df.groupby(by=['도서명', '저자', 'ISBN', '권'],
dropna=False).sum()
# 원본 데이터프레임에서 중복된 행을 제외하고 고유한 행만 추출하여 복사합니다.
dup_rows = ns_book.duplicated(subset=['도서명', '저자', 'ISBN', '권'])
unique_rows = ~dup_rows
ns_book3 = ns_book[unique_rows].copy()
# 도서명, 저자, ISBN, 권을 인덱스로 설정합니다.
ns_book3.set_index(['도서명', '저자', 'ISBN', '권'], inplace=True)
# loan_count에 저장된 누적 대출건수를 업데이트합니다.
ns_book3.update(loan_count)
# 인덱스를 재설정합니다.
ns_book4 = ns_book3.reset_index()
# 원본 데이터프레임의 열 순서를 변경합니다.
ns_book4 = ns_book4[ns_book.columns]
return ns_book4
- 위 함수에 원본 데이터를 전달하여 새로운 데이터프레임을 만든 후
- 위에서 만든 데이터프레임과 동일한지 확인
codenew_ns_book4 = data_cleaning('ns_202104.csv') ns_book4.equals(new_ns_book4) # result True
[기본숙제]
p. 182 확인 문제 2번
1번 문제의 df1 데이터프레임에서 'col1' 열의 합을 계산하는 명령으로 올바르지 않은 것은 무엇인가요?
열의 합을 계산하기 의해서는 loc이나 [ ]를 사용하여 특정 열을 지정한 뒤,
sum 메소드를 사용해야한다.답은 4번이다.

[추가숙제]
p. 219 확인 문제 5번
df 데이터프레임에서 df.replace(r'ba.*', 'new', regex=Ture)의 결과는 무엇인가요?ba가 앞에 들어있는 문자를 모두 new로 replace한 결과이므로 답은 1번이다.

42 Gyeongsan Learner